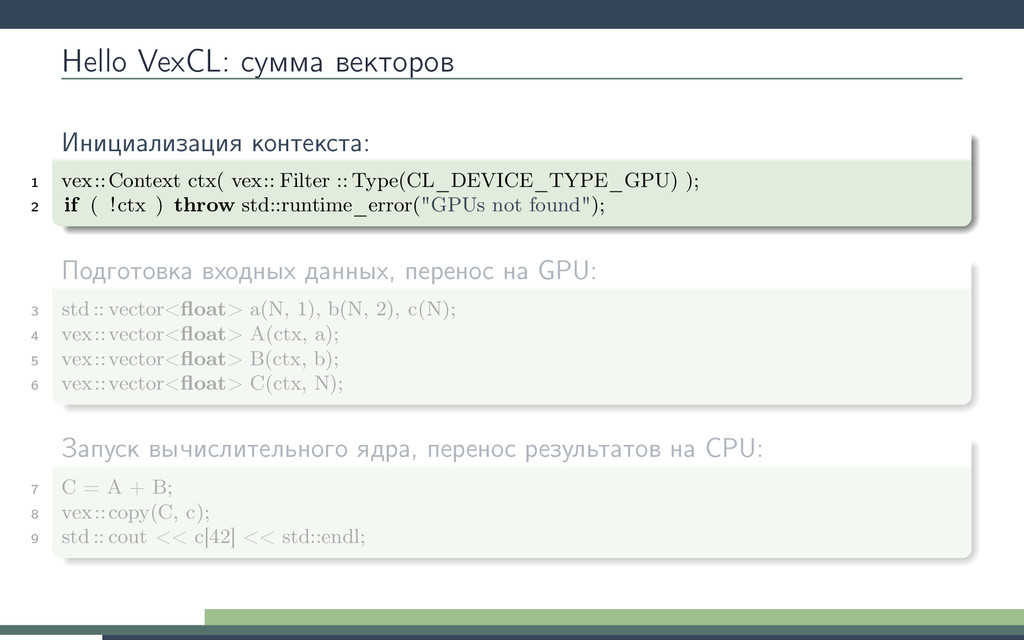
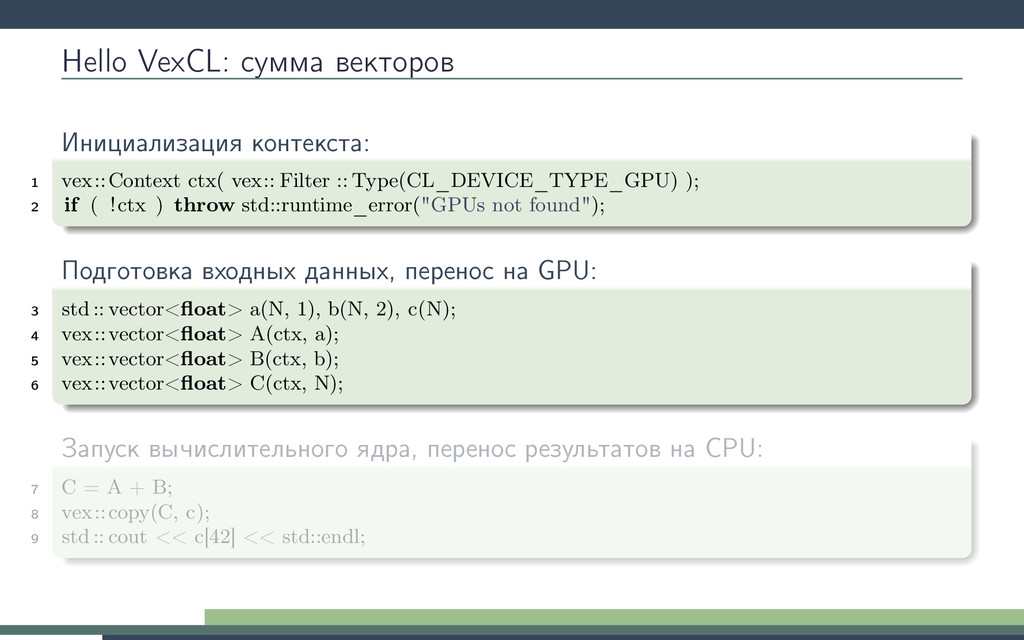
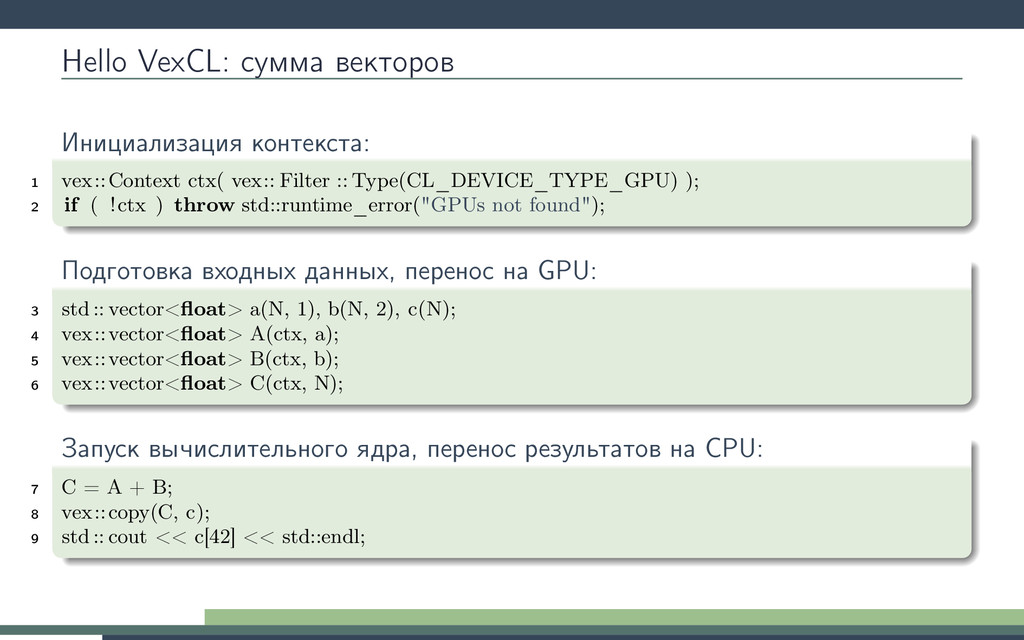
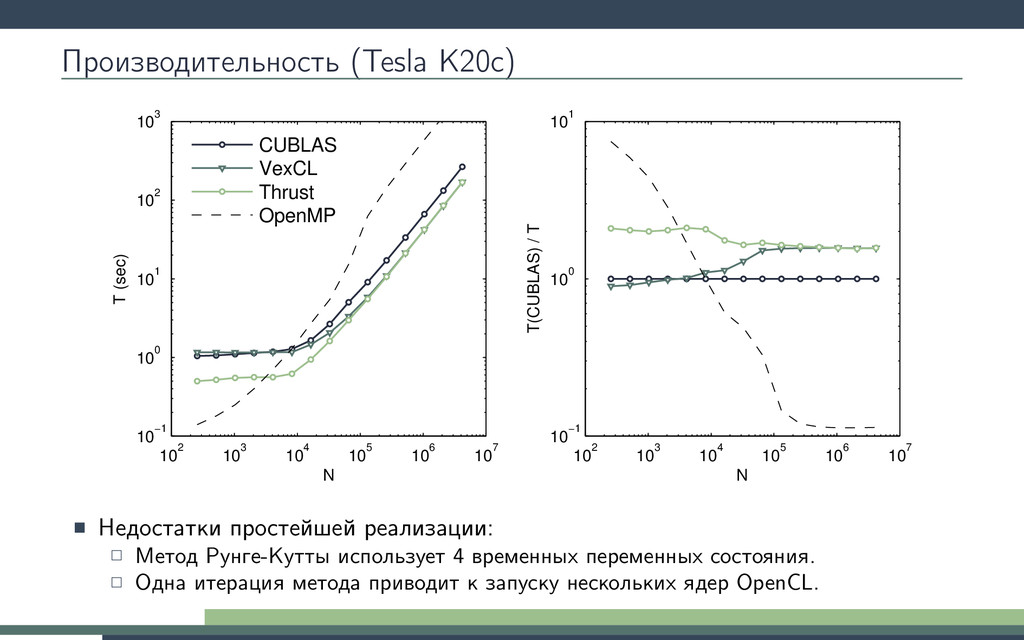
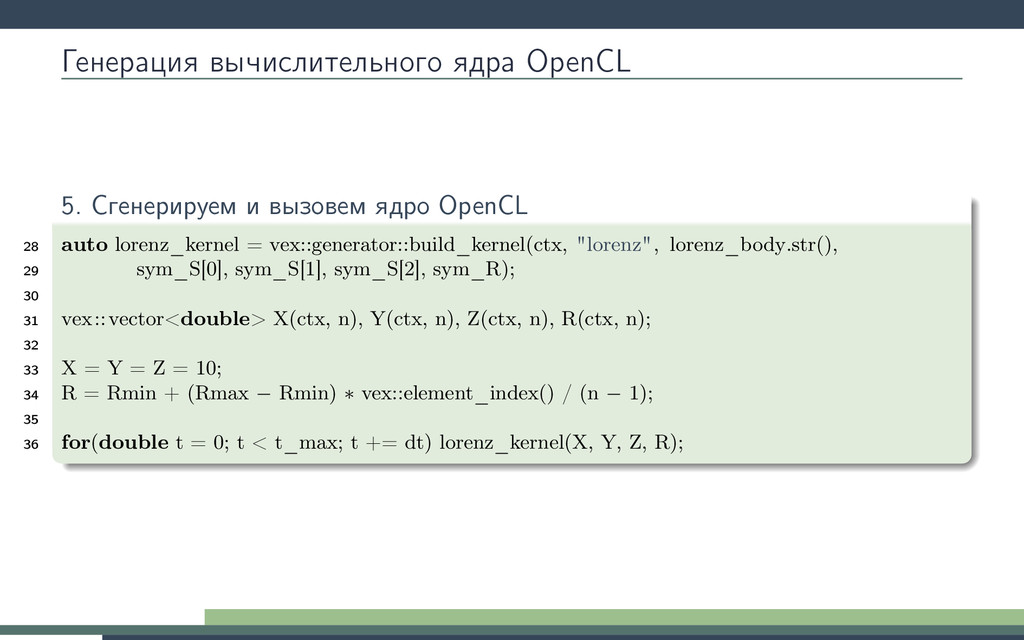
Рунге-Кутты. Будем вызывать ядро в цикле интегрирования. Получим 10-кратное ускорение! Потеряв универсальность odeint. 1 double3 lorenz_system(double r, double sigma, double b, double3 s) { 2 return (double3)( sigma ∗ (s.y − s.x), 3 r ∗ s.x − s.y − s.x ∗ s.z, 4 s.x ∗ s.y − b ∗ s.z); 5 } 6 kernel void lorenz_ensemble( 7 ulong n, double dt, double sigma, double b, 8 const global double ∗R, 9 global double ∗X, 10 global double ∗Y, 11 global double ∗Z 12 ) 13 { 14 for(size_t i = get_global_id(0); i < n; i += get_global_size(0)) { 15 double r = R[i]; 16 double3 s = (double3)(X[i], Y[i ], Z[i ]); 17 double3 k1, k2, k3, k4; 18 19 k1 = dt ∗ lorenz_system(r, sigma, b, s); 20 k2 = dt ∗ lorenz_system(r, sigma, b, s + 0.5 ∗ k1); 21 k3 = dt ∗ lorenz_system(r, sigma, b, s + 0.5 ∗ k2); 22 k4 = dt ∗ lorenz_system(r, sigma, b, s + k3); 23 24 s += (k1 + 2 ∗ k2 + 2 ∗ k3 + k4) / 6; 25 26 X[i] = s.x; Y[i] = s.y; Z[i ] = s.z; 27 } 28 }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}