DeNA データプラットフォームは、アナリスト(データ分析担当者)から企画、経営層まで幅広く利用され、データ分析にもとづいた施策や意思決定が行われています。
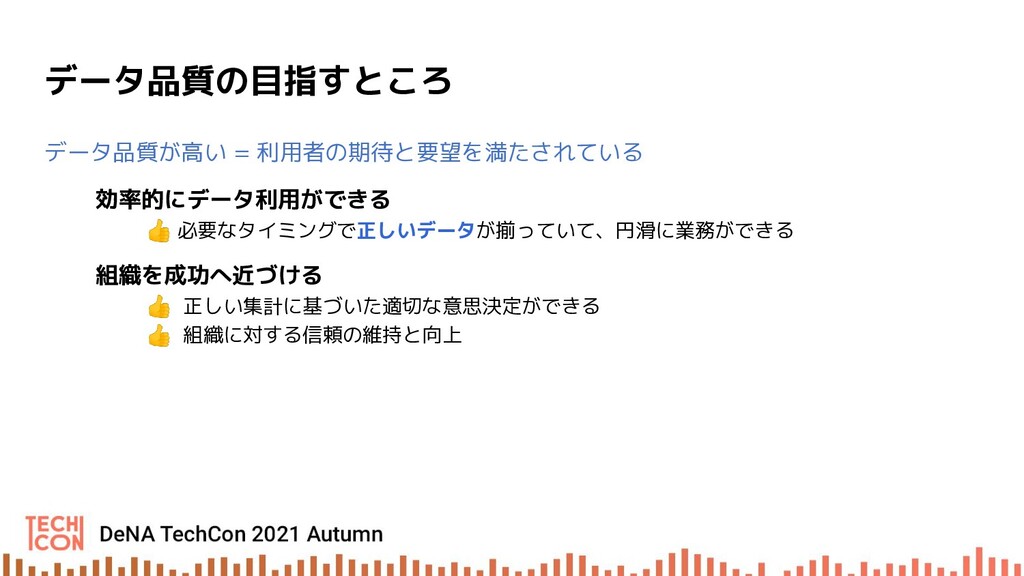
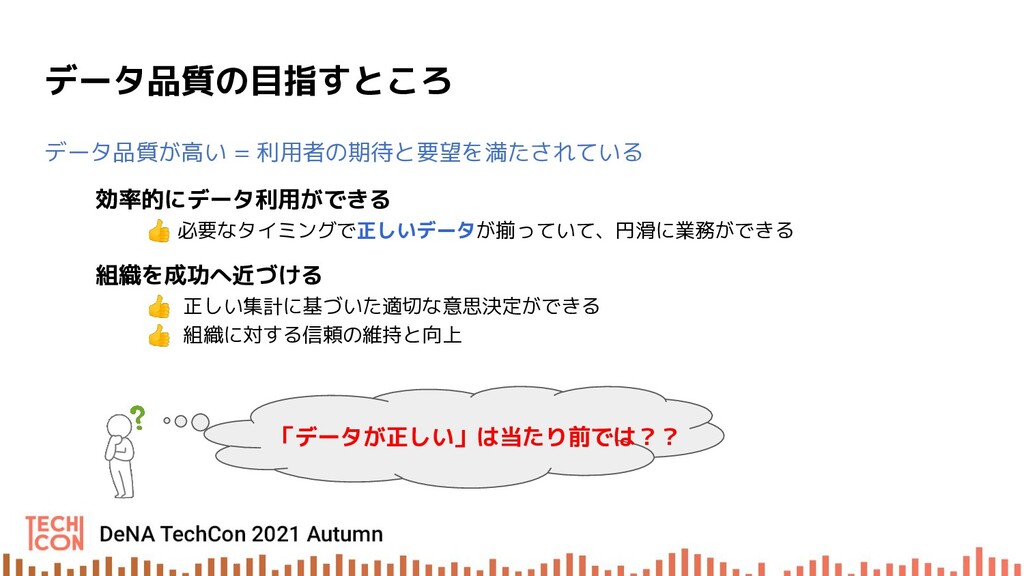
データプラットフォームにおけるデータ品質の低下は、データ利用者の業務の効率低下を始め、誤集計に基づいた正しくない意思決定による機会損失や信頼の低下による事業損失など様々な弊害を招きます。
DeNA のデータエンジニアは、このようなリスクを低減させ、データ活用ができる環境を整えるべくデータ品質向上に取り組んでいます。
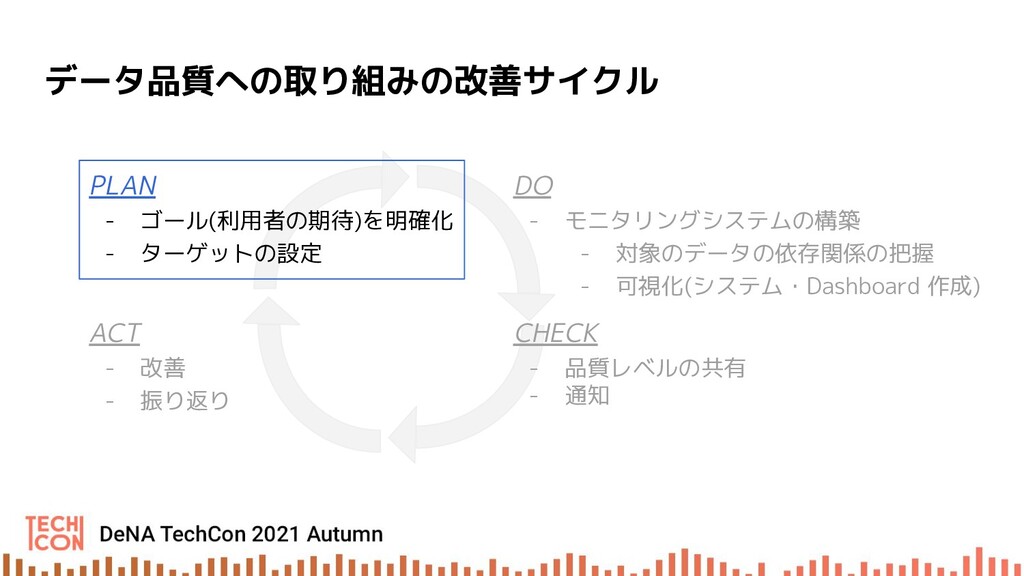
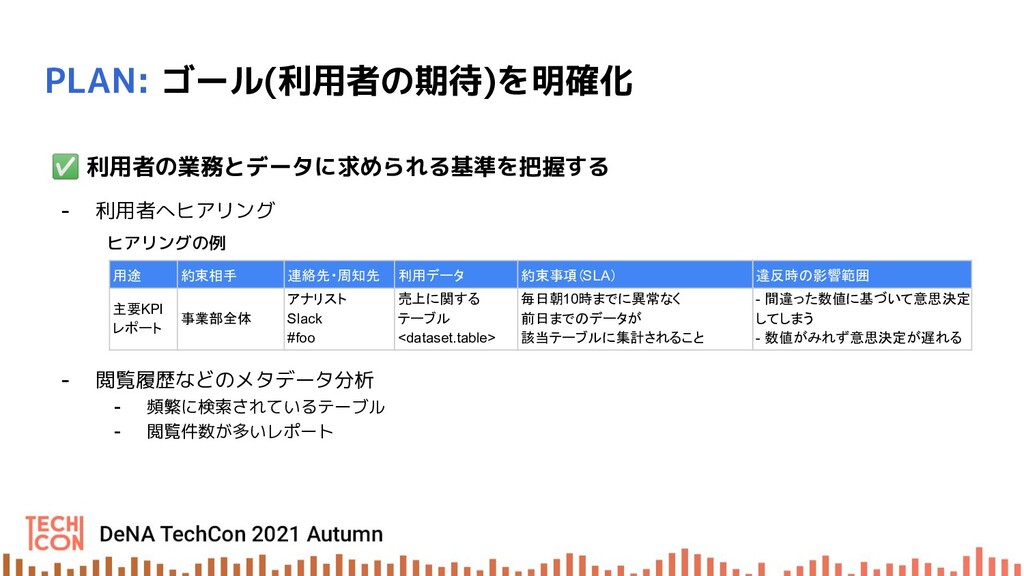
本セッションでは、データ利活用において担保すべき品質基準、モニタリング指標、運用などデータ品質向上の取り組みの具体例をもとにお話します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
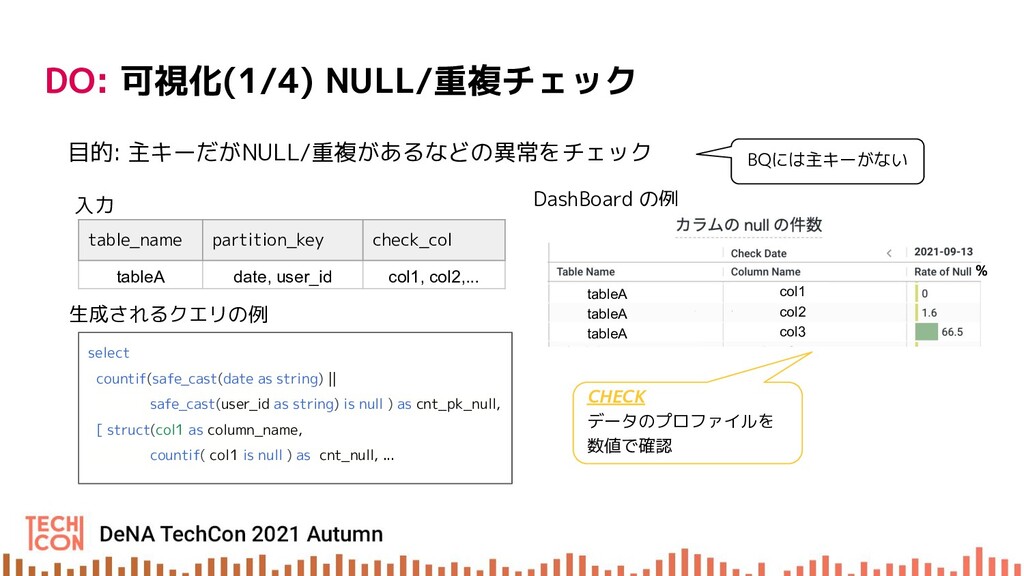{kind=link}
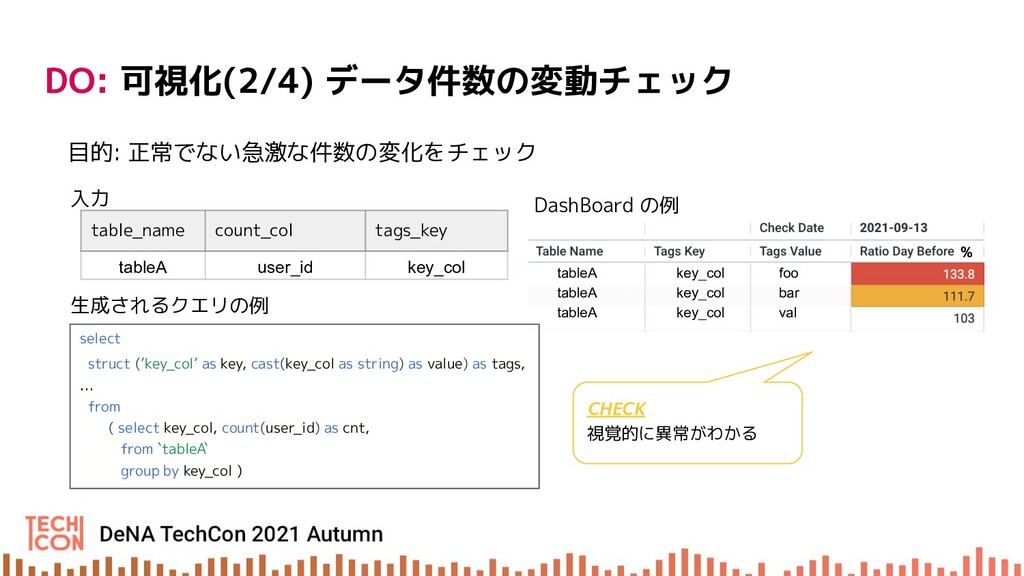{kind=link}
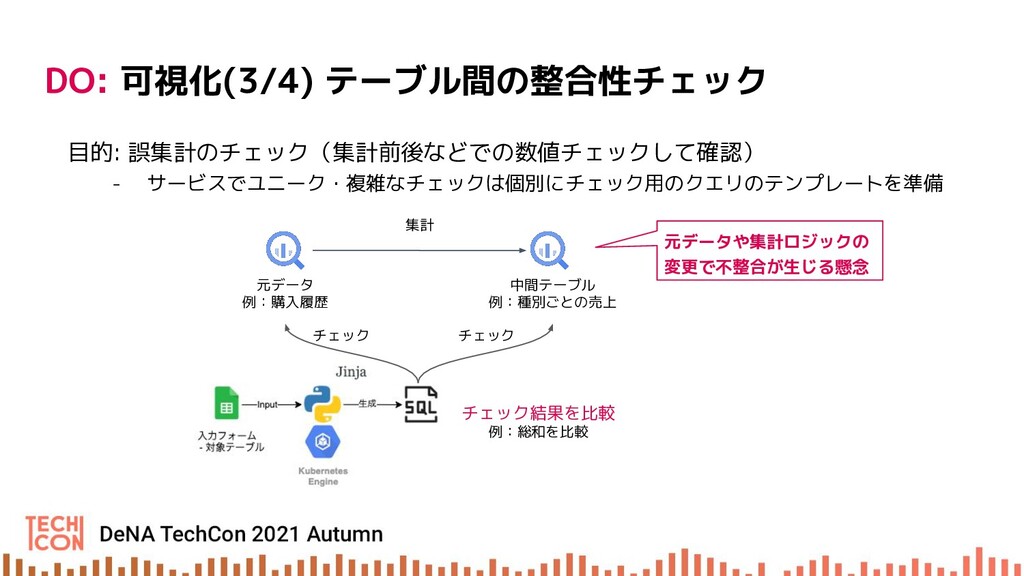{kind=link}
{kind=link}
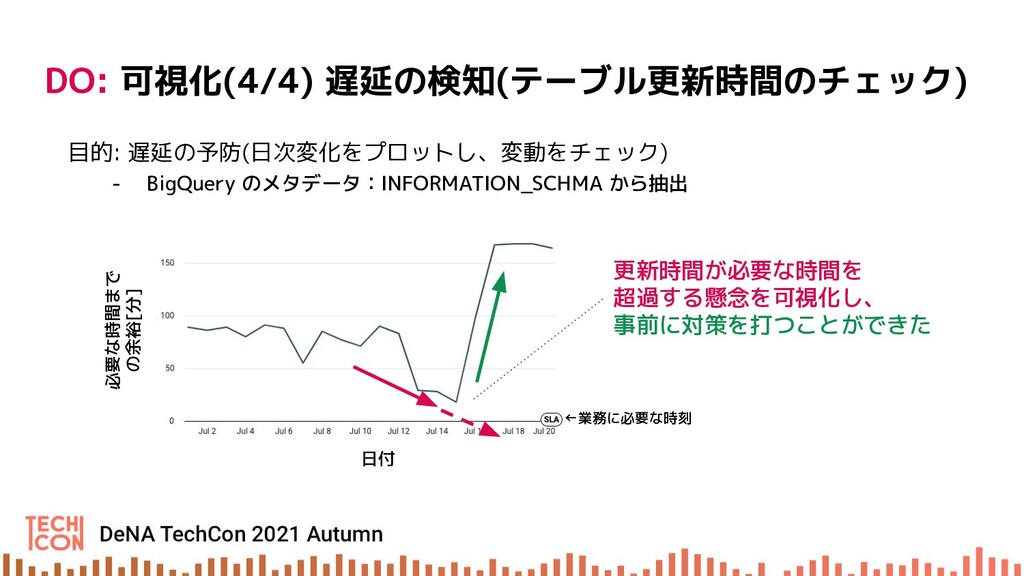{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}