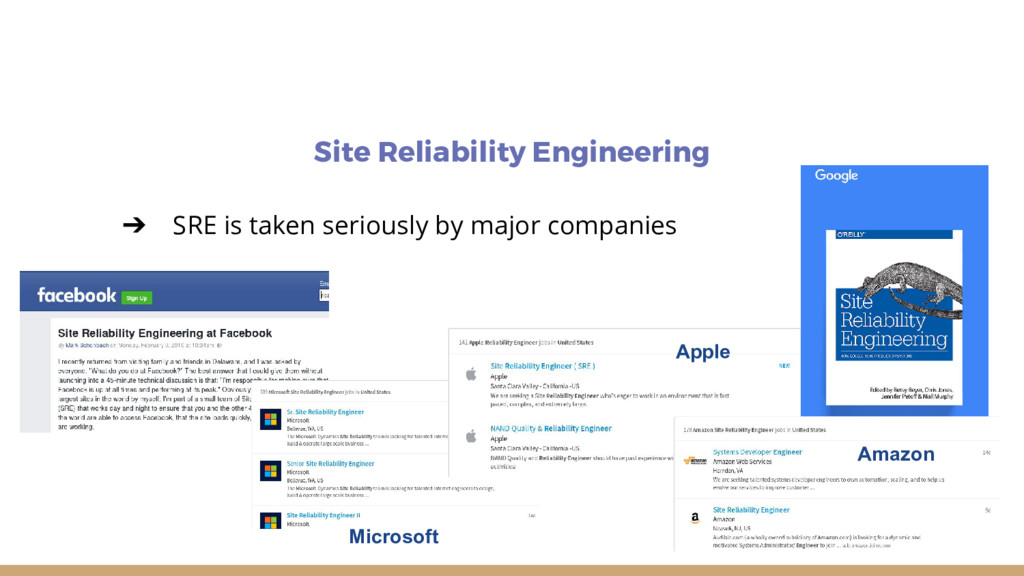
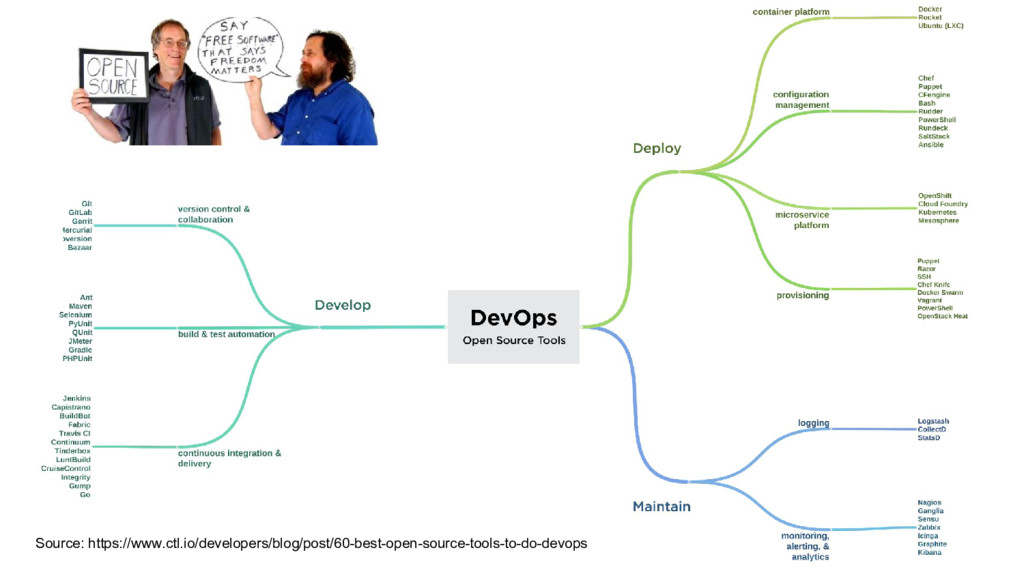
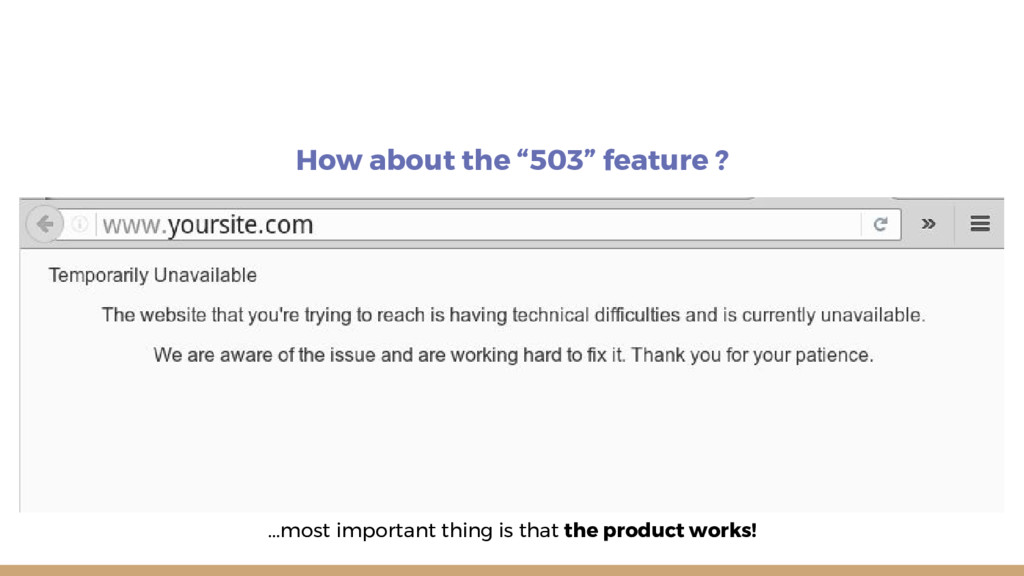
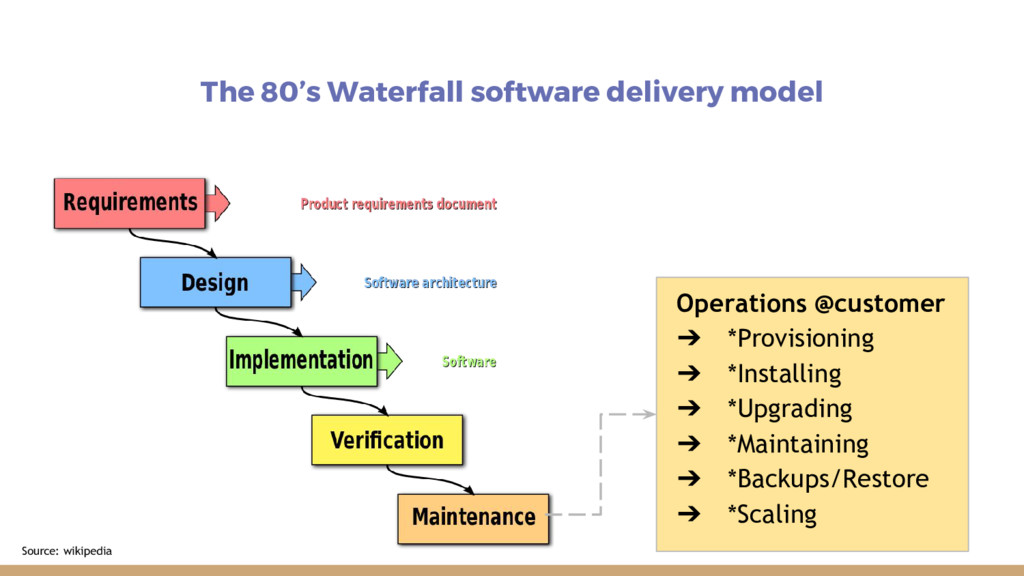
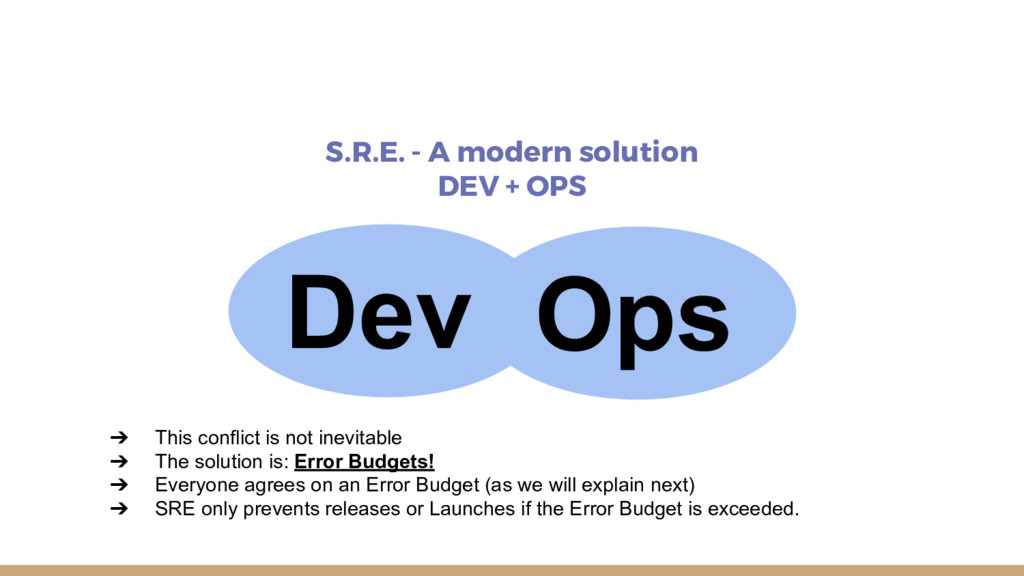
Site Reliability Engineering enables agility and stability. SREs use Software Engineering to automate themselves out of the Job. My advice, if you want to implement this change in your company is to start with action items, alter your training and hiring, implement error budgets, do blameless postmortems and reduce toil.
Ricardo Amaro is currently an SRE in one of the largest companies related to the world of free software.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![QUESTIONS! Site Reliability Engineering [email protected]](https://files.speakerdeck.com/presentations/1520f8f1300446b1b4593c34498c8902/slide_48.jpg){kind=link}
![Thank you Site Reliability Engineering [email protected]](https://files.speakerdeck.com/presentations/1520f8f1300446b1b4593c34498c8902/slide_49.jpg){kind=link}