оно решает? • class SRE implements DevOps • общие подробности про как SRE работает в Гугле ◦ ~10% инженеров ◦ типичный размер: 8 или 6+6 ◦ SWE/SE опыт ◦ не больше 50% Ops
на продакшн-грабли на стадии дизайна ◦ Советуем проверенные и надёжные решения ◦ Помогаем с имплементацией • Пишем код ◦ помогающий нашим пользователям ◦ повышающий надёжность наших сервисов ◦ повышающий производительность наших сервисов ◦ облегчающий поддержку наших сервисов
довести их сервис до поддерживабельного состояния ◦ После чего принимаем ответственность за этот сервис на себя • Дежурим ◦ Следим за SLO ◦ Обычно полтора месяца между дежурствами ◦ Обычно только днём ◦ Чиним проблемы, решения которых пока не автоматизированы ◦ Предотвращаем пожары
• Пример: ◦ SLI: 95% upload latency меньше порогового значения ◦ SLO: SLI выполняется 99% времени ◦ SLA: про контракты и последствия ◦ Нетривиальные подробности про определение ◦ Почему не 100% (дорого, часто невозможно, часто бессмысленно)
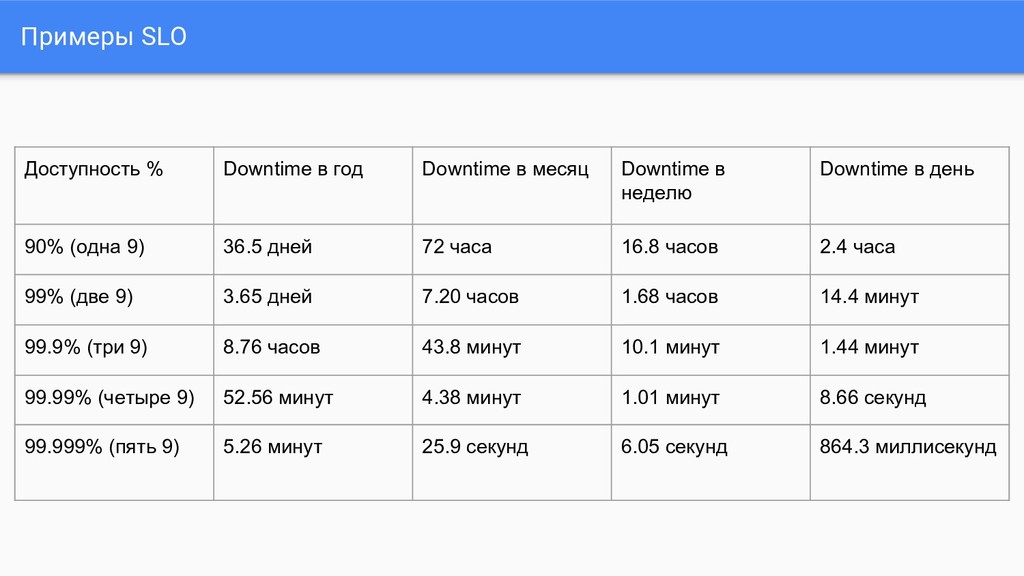
Downtime в неделю Downtime в день 90% (одна 9) 36.5 дней 72 часа 16.8 часов 2.4 часа 99% (две 9) 3.65 дней 7.20 часов 1.68 часов 14.4 минут 99.9% (три 9) 8.76 часов 43.8 минут 10.1 минут 1.44 минут 99.99% (четыре 9) 52.56 минут 4.38 минут 1.01 минут 8.66 секунд 99.999% (пять 9) 5.26 минут 25.9 секунд 6.05 секунд 864.3 миллисекунд
сердца вон” • Разработчики должны представлять, как ведёт себя их сервис • Бессонные ночи помогают приоритизировать баги • В разных обстоятельствах бывают разные варианты сотрудничества
конкретным проектом ◦ ...да и вообще в SRE • Хороший проект приятно поддерживать ◦ ...а от плохого вам отдадут пейджер обратно • Происходит редко, но мотивирует
инциденты всегда будут ◦ Это нормально. Не особо приятно, но нормально. • Две цели при каждом инциденте: ◦ Минимизировать ущерб ◦ Предотвратить повторение
Определить SLO и измерять, насколько они выполняются • Бюджет ошибок как критерий запусков • Общий хедкаунт • 5% Ops-работы достаётся девелоперам • Не больше 50% Ops-работы для SRE (обычно ~30%) • Дежурства: 8 человек, 1-2 инцидента за смену • Тренировки • Конструктивные постмортемы
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}