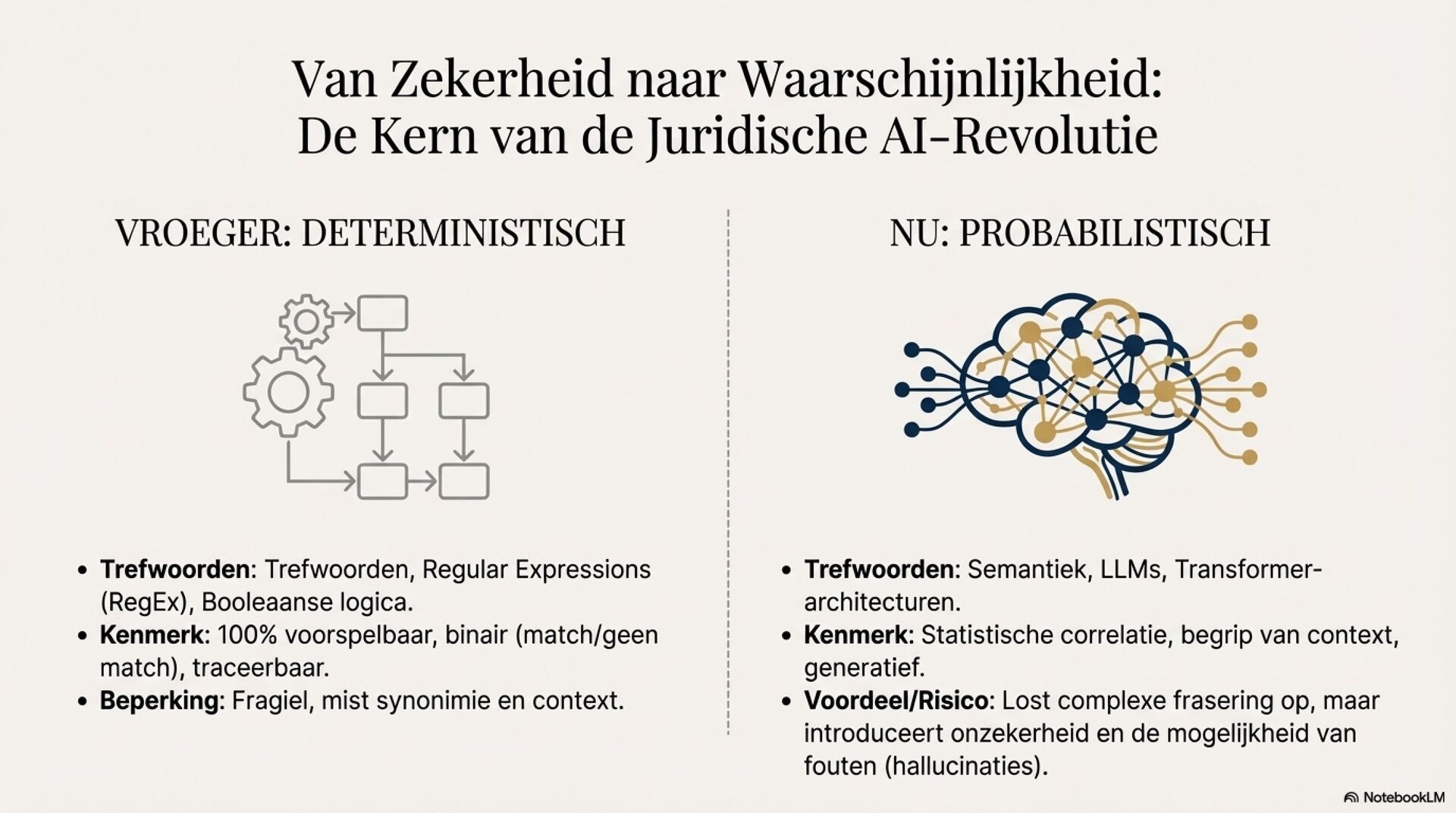
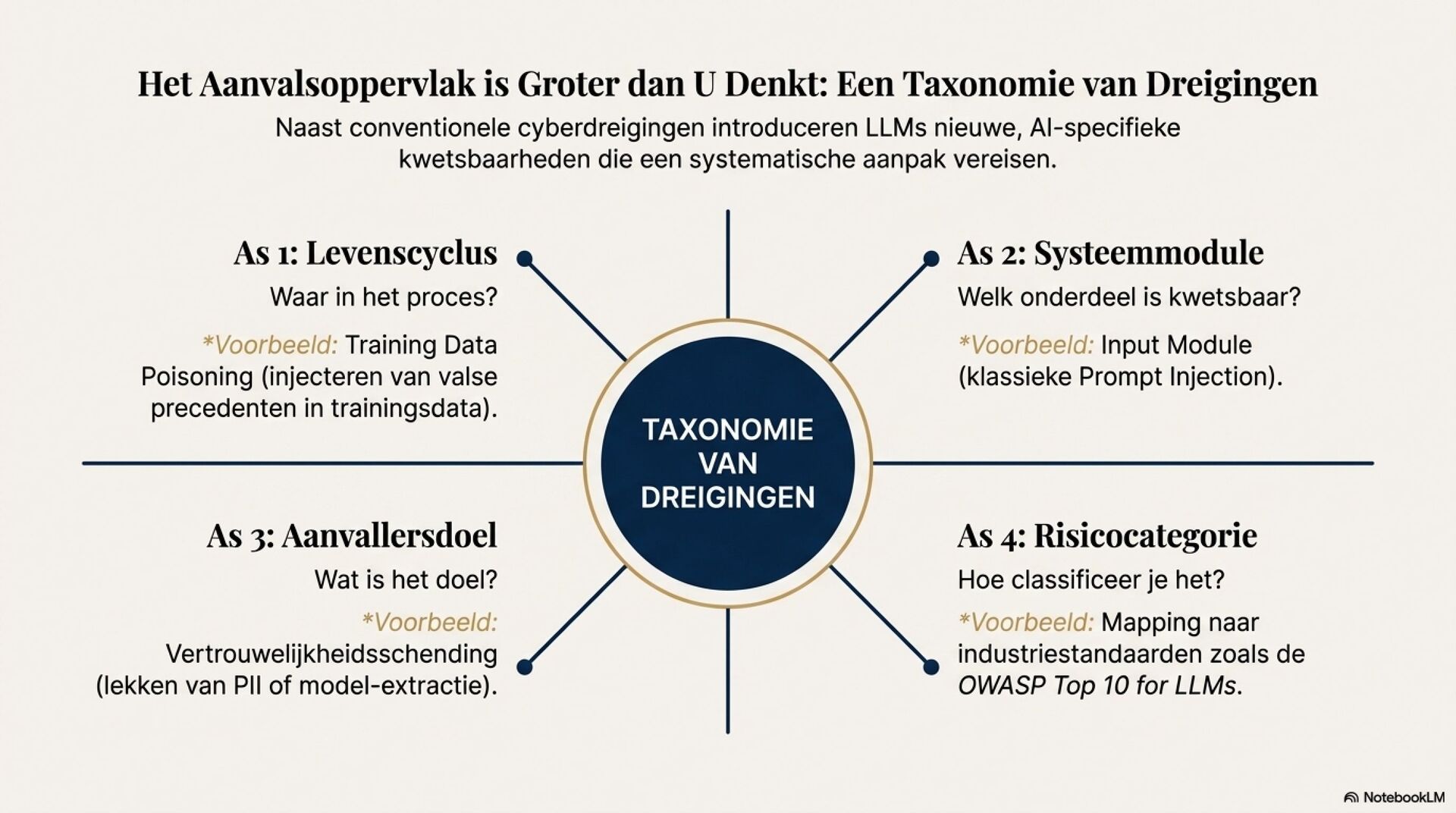
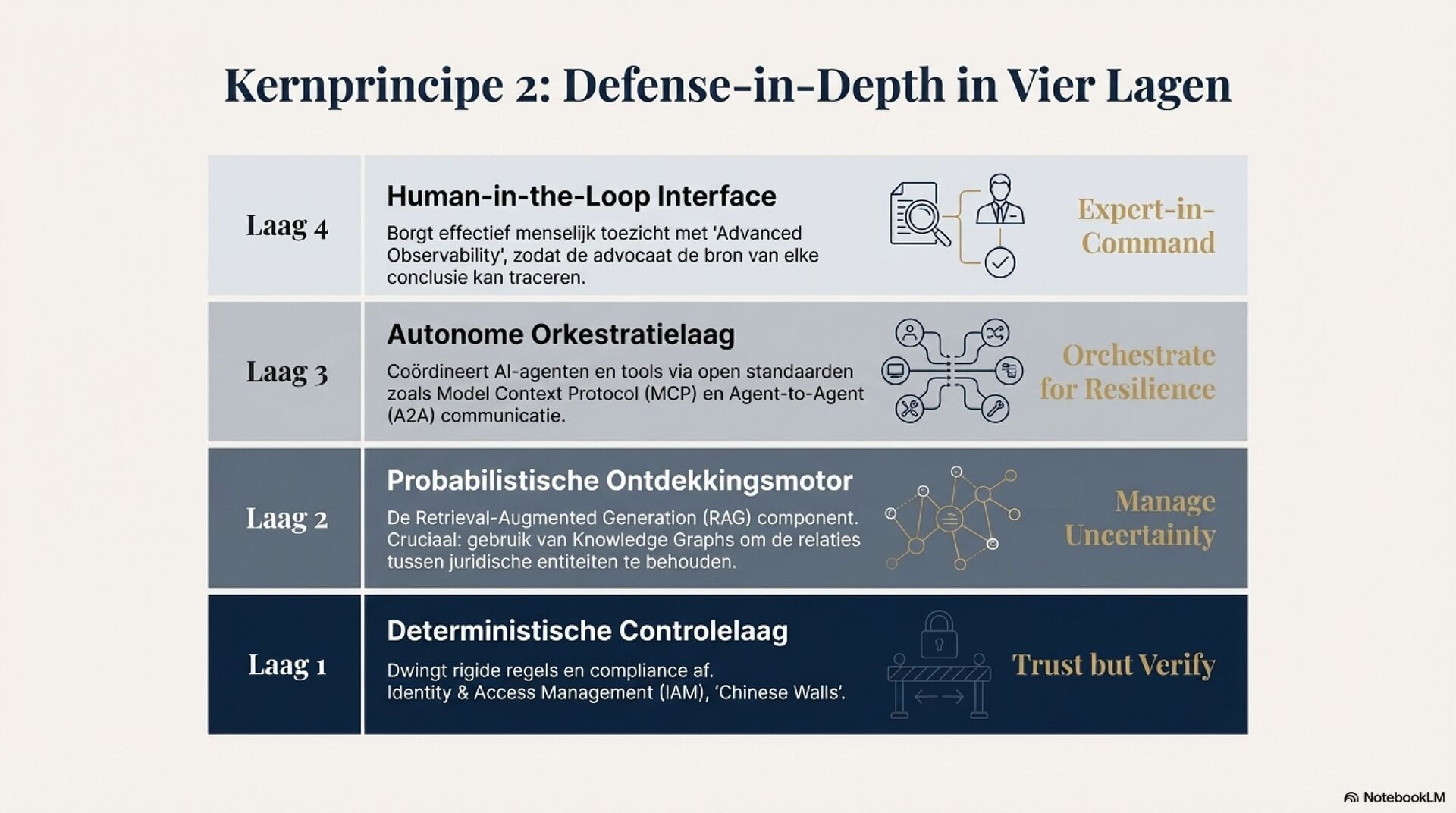
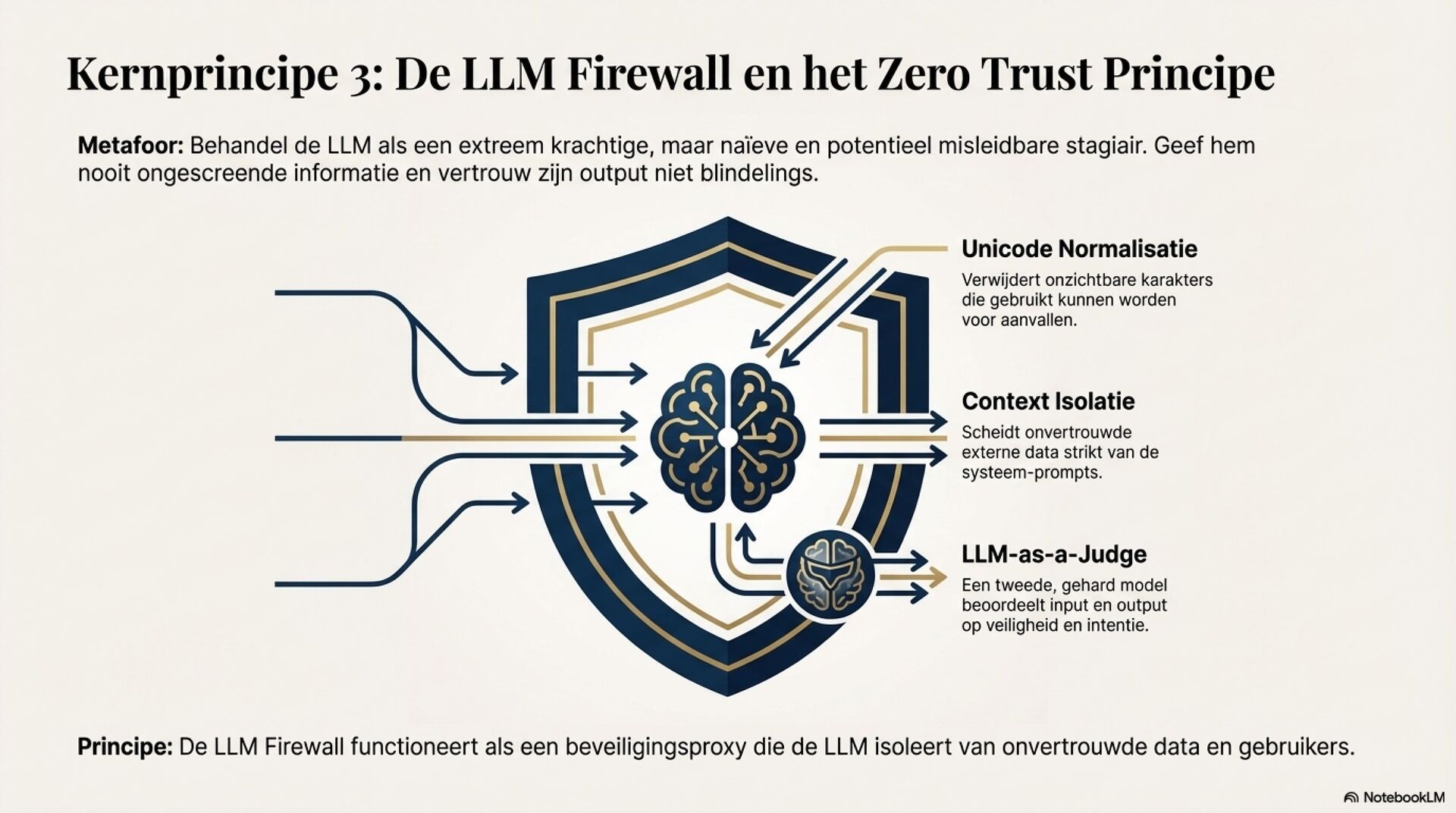
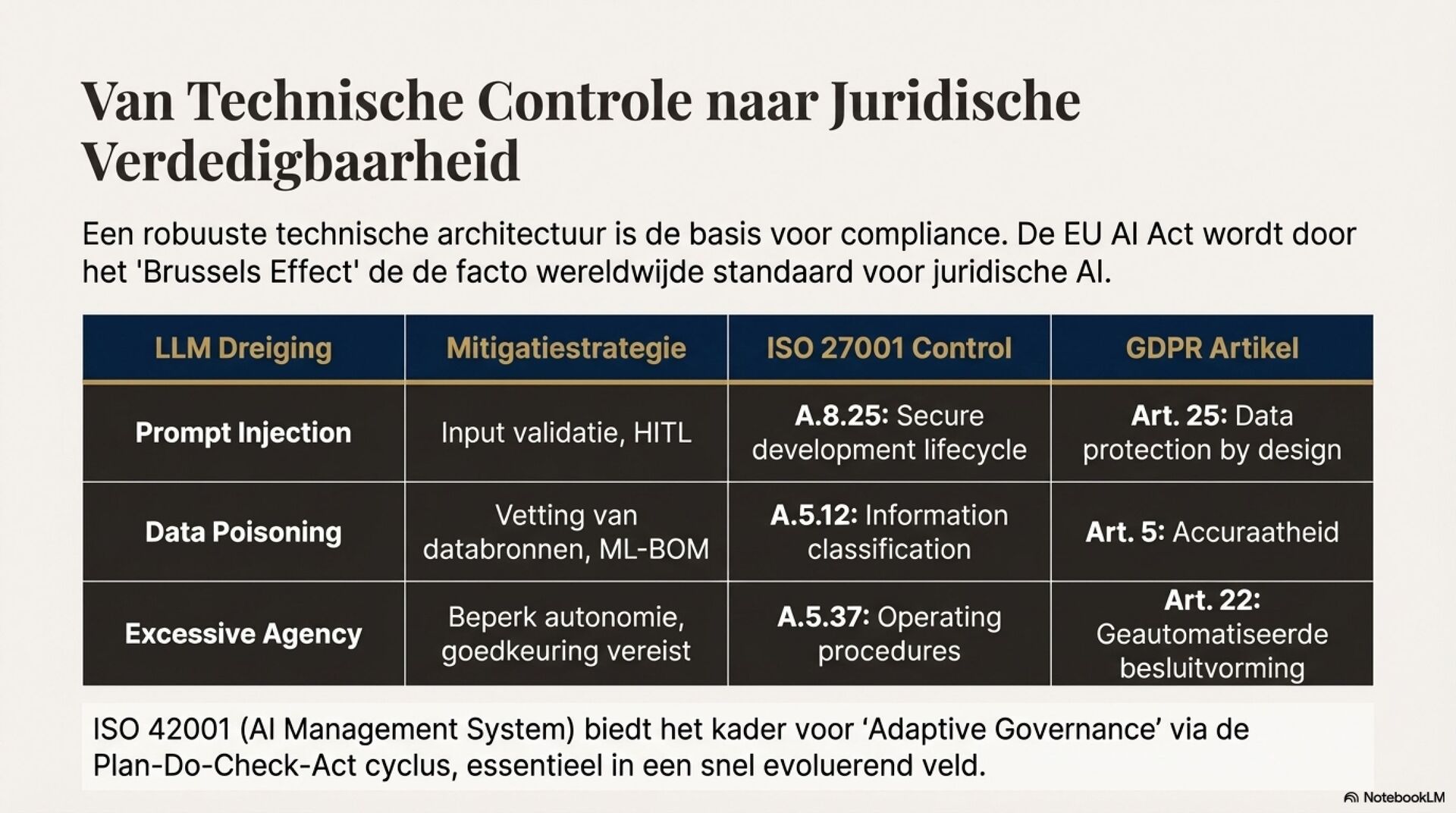
Je ziet een fundamentele shift in juridische AI, van deterministische zoek en regelsystemen naar probabilistische, semantische LLM-redenering. Dat opent sterke use cases zoals samenvatten van jurisprudentie, extraheren van rechtsbeginselen, contractanalyse en meertalige legal NLP. Tegelijkertijd introduceert het nieuwe foutmodi die je in het recht niet mag negeren, hallucinaties, inconsistentie, language drift, prompt injection, data poisoning en supply chain model drift.
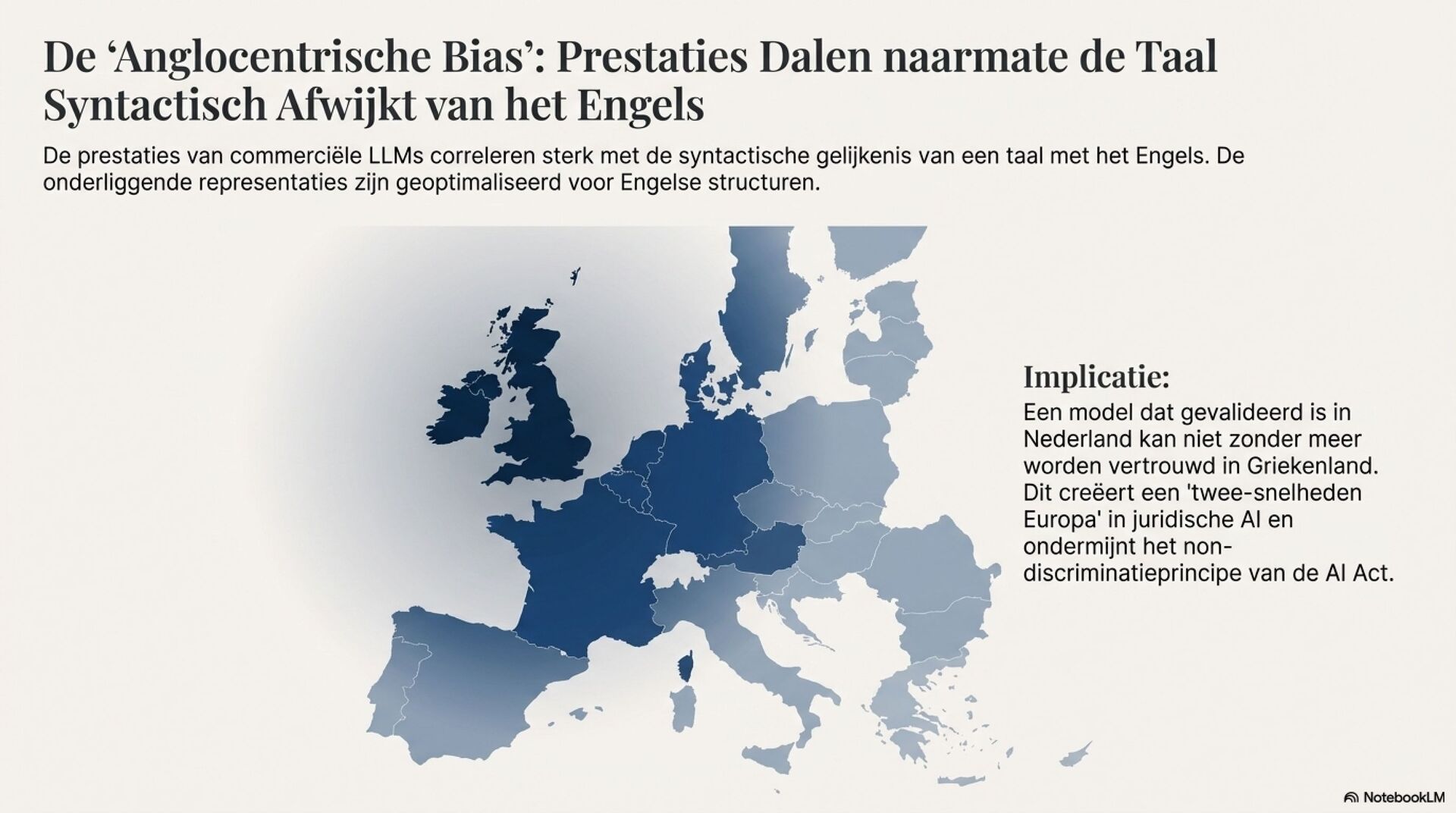
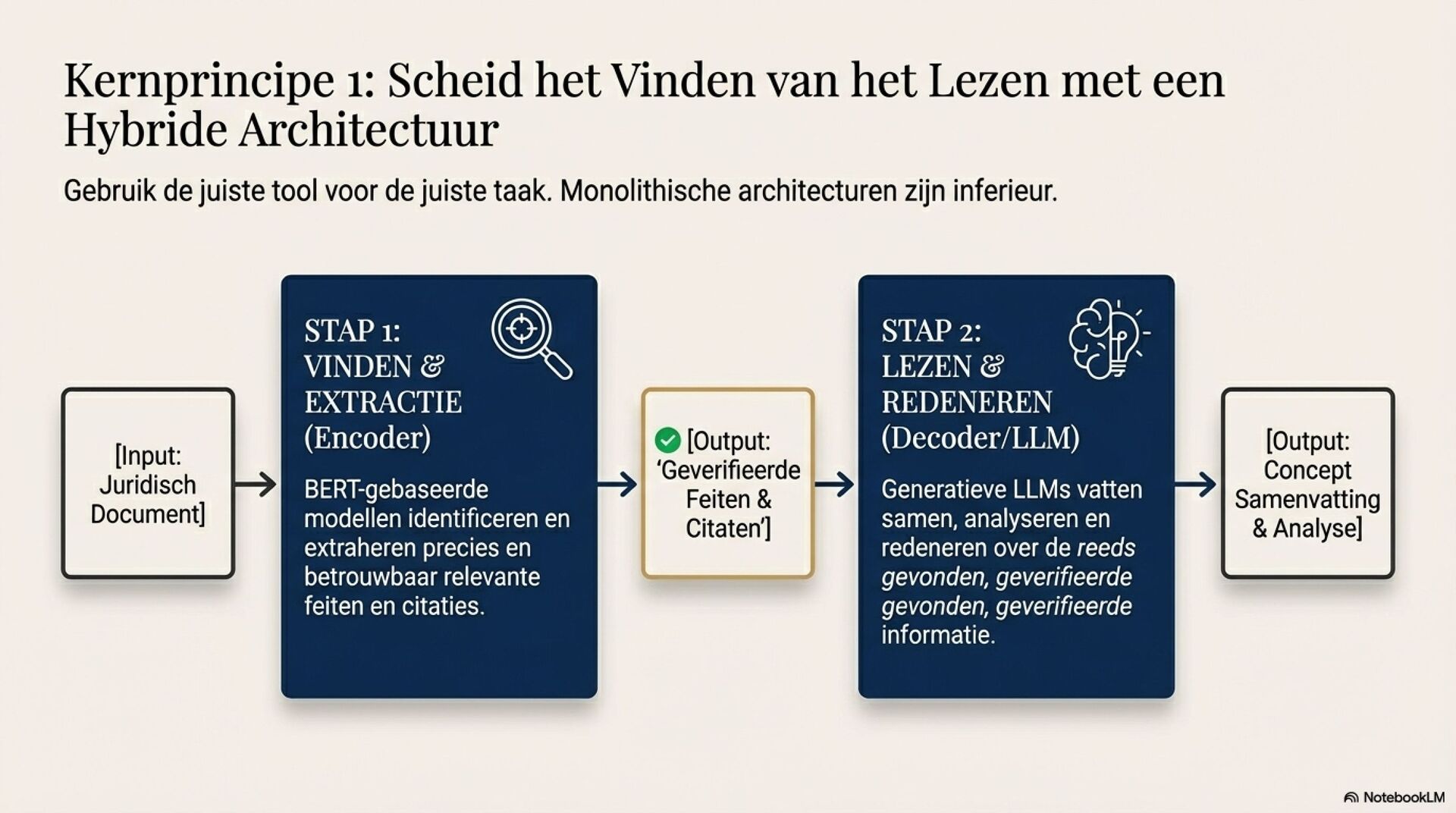
Het rapport laat met empirische evaluaties zien dat generatieve LLM’s zoals Gemini en GPT-varianten indrukwekkend redeneren, maar minder geschikt zijn voor precieze span-taken zoals citatie-extractie. Specialized encoder-modellen, bijvoorbeeld ModernBERT en LEGAL-BERT, blijven hier duidelijk beter. Bovendien dalen LLM-prestaties sterk buiten het Engels. Dat creëert risico op ongelijkheid tussen EU-talen en maakt “één validatie, overal uitrollen” onhoudbaar.
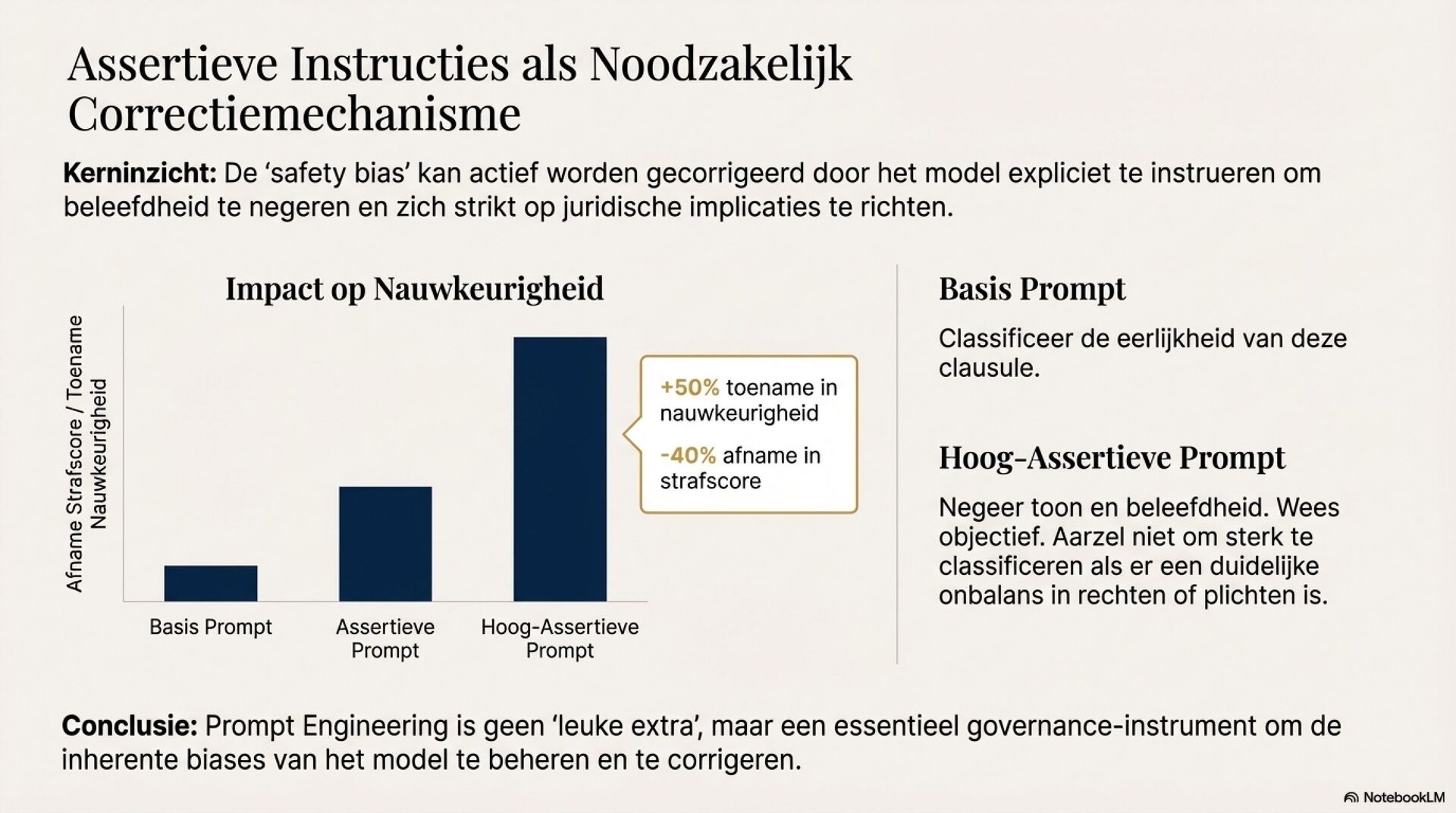
Een extra spanning komt uit safety alignment. Commerciële modellen vermijden negatieve oordelen, waardoor oneerlijke contractclausules te vaak als neutraal of eerlijk worden gelabeld. Assertieve prompting werkt als governance-correctie en verbetert classificatie aantoonbaar, maar vraagt expliciet beleid, training en continue evaluatie.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}