Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20190418_データ活用よろず相談#01(at G's BASE FUKUOKA)~ひ...
Search
NobuakiOshiro
PRO
April 18, 2019
Business
280
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20190418_データ活用よろず相談#01(at G's BASE FUKUOKA)~ひとまずこの10年くらいの流れを振り返ってみるの巻~
https://nobdata.connpass.com/event/126918/
NobuakiOshiro
PRO
April 18, 2019
More Decks by NobuakiOshiro
See All by NobuakiOshiro
20260610_中東情勢_物流資源ショック_統合分析19枚_v3
doradora09
PRO
0
1
20260604_福岡女子大_講義後小レポート分析スライド_NOBDATA
doradora09
PRO
0
20
20260601_中東情勢1週間差分update
doradora09
PRO
0
33
20260602_中東情勢と物流_3か月振り返り_10枚圧縮版_最新版
doradora09
PRO
0
40
伊藤さん_発表スライド_全業種x各国_20260602
doradora09
PRO
1
34
20260528_生成AIを専属DSに_Howの次にすべきことを考える
doradora09
PRO
0
290
20260527_準悲観シナリオ_v2_価格高騰見込み
doradora09
PRO
0
59
20260527_ホルムズ制約長期化シナリオ(準悲観シナリオ)
doradora09
PRO
0
60
20260527_先週差分_今後調査予定_サマリ
doradora09
PRO
0
52
Other Decks in Business
See All in Business
株式会社Beer and Tech/HitoHana(ひとはな) 採用資料 2026.06 .09
beerandtech_recruiter
1
47k
AIを意識した経営・執行の設計と実行
kan
4
4k
“使われているハーネス/使われていないハーネス”を可視化するところから始めた話
sugamoto
0
210
紹介パートナー様向け 紹介手数料プランとご登録手順のご案内(マルコポーロ)
kimete
0
230
インターセクト会社説明資料
intersect
0
270
【結果報告】Claude×Linearで会社のタスク管理をAIにまかせて1ヶ月。業務効率150%向上したが、AIネイティブカンパニーを目指すならもっと「加速への狂気」が必要
nagatsu
0
390
AWTTの歩き方〜Tableau編〜
leafyoh
0
230
Mercari-Fact-book_en
mercari_inc
2
35k
Sotas Company Deck / 会社紹介資料
sotas
0
380
エンジニアのためのコミュニケーション術
zashii
1
430
CompanyDeck_v6.5.pdf
xid
3
27k
HumanDriven 会社紹介資料 / HumanDriven Company Profile
humandriven
0
520
Featured
See All Featured
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
1
150
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
830
Prompt Engineering for Job Search
mfonobong
0
330
Art, The Web, and Tiny UX
lynnandtonic
304
22k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
140
Chasing Engaging Ingredients in Design
codingconduct
0
210
Odyssey Design
rkendrick25
PRO
2
690
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Principles of Awesome APIs and How to Build Them.
keavy
128
17k
Transcript
データ活用よろず相談 #01 (at G's BASE FUKUOKA) ~ひとまずこの10年くらいの流れを 振り返ってみるの巻~ NOB DATA株式会社
大城
自己紹介 • NOB DATA株式会社 代表取締役 • 大城 信晃 • データサイエンティスト
• 沖縄 -> 東京(7年) -> 福岡(2年) • ヤフー -> DATUM STUDIO -> LINE Fukuoka -> NOB DATA(株) 設立 (2018/9) • 言語 • R : 初心者 • Python : 勉強中 • 分析コミュニティ運営(後述) • のべ2200名規模 • Tokyo.R, fukuoka.R, 意思決定のためのデータ分析勉強会, PyData.Fukuoka https://nobdata.co.jp/ 2
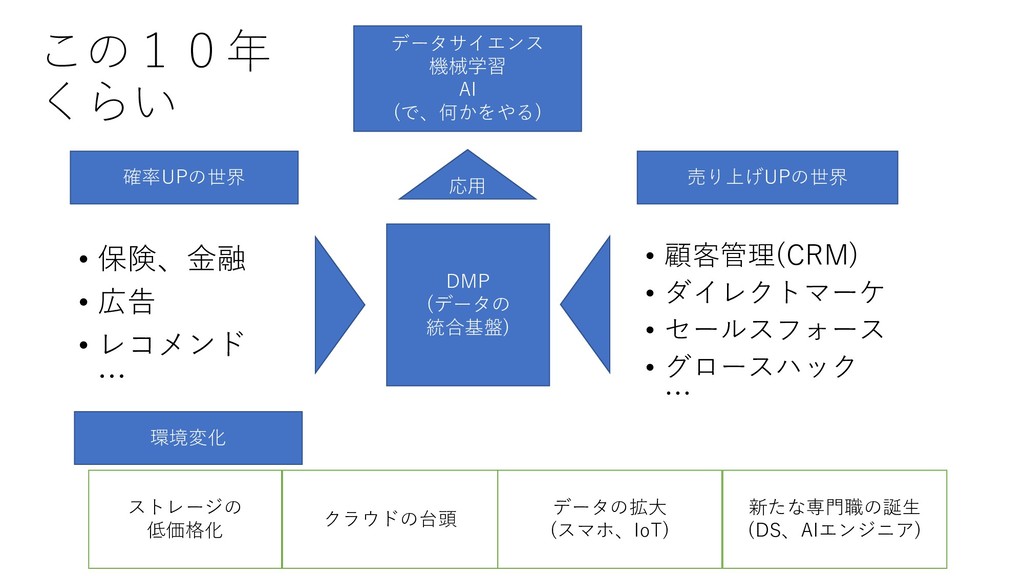
この10年 くらい • 保険、金融 • 広告 • レコメンド … •
顧客管理(CRM) • ダイレクトマーケ • セールスフォース • グロースハック … 確率UPの世界 売り上げUPの世界 DMP (データの 統合基盤) クラウドの台頭 ストレージの 低価格化 データの拡大 (スマホ、IoT) 応用 データサイエンス 機械学習 AI (で、何かをやる) 新たな専門職の誕生 (DS、AIエンジニア) 環境変化
データ活用のパターンと実現可能性 • コストカット系 • 堅い分野。だが限界あり • 改善系 • 売り上げUPのための投資 •
新規事業系 • 当たればでかいがほぼ外れる(実験) • 単純作業置き換え • 自動化、(RPA) • 意思決定支援 • 解釈可能な分析 • モデリング • 精度が上がれば ブラックボックスでもOK
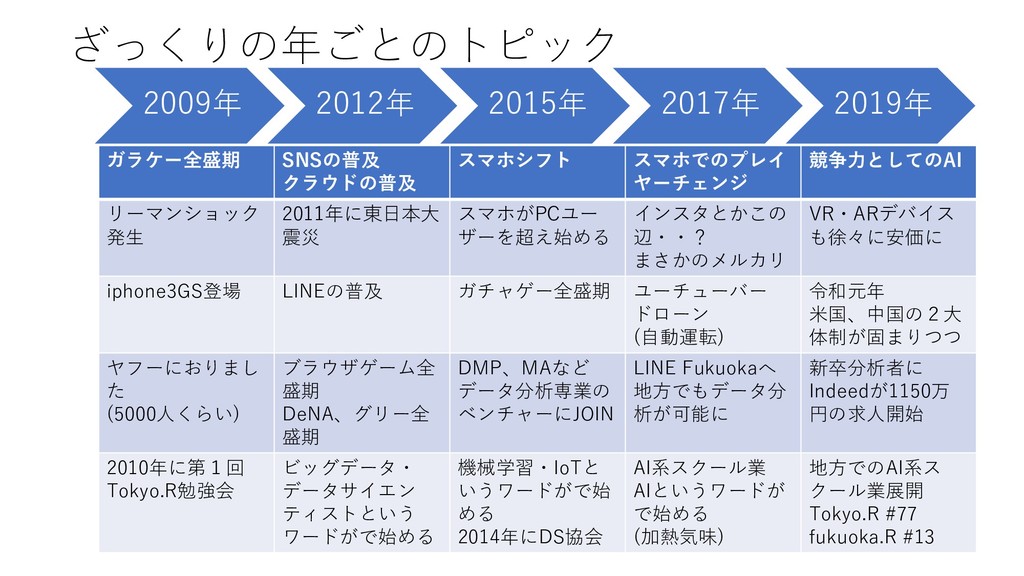
ざっくりの年ごとのトピック 2009年 2012年 2015年 2017年 2019年 ガラケー全盛期 SNSの普及 クラウドの普及 スマホシフト
スマホでのプレイ ヤーチェンジ 競争力としてのAI リーマンショック 発生 2011年に東日本大 震災 スマホがPCユー ザーを超え始める インスタとかこの 辺・・? まさかのメルカリ VR・ARデバイス も徐々に安価に iphone3GS登場 LINEの普及 ガチャゲー全盛期 ユーチューバー ドローン (自動運転) 令和元年 米国、中国の2大 体制が固まりつつ ヤフーにおりまし た (5000人くらい) ブラウザゲーム全 盛期 DeNA、グリー全 盛期 DMP、MAなど データ分析専業の ベンチャーにJOIN LINE Fukuokaへ 地方でもデータ分 析が可能に 新卒分析者に Indeedが1150万 円の求人開始 2010年に第1回 Tokyo.R勉強会 ビッグデータ・ データサイエン ティストという ワードがで始める 機械学習・IoTと いうワードがで始 める 2014年にDS協会 AI系スクール業 AIというワードが で始める (加熱気味) 地方でのAI系ス クール業展開 Tokyo.R #77 fukuoka.R #13
ヤフー時代(2009-2015) 主な関わりのあるサービス • ヤフーショッピング • ヤフオク • 製品DB • Yahoo
DMPの設計・開発 • 広告主向けのデータ分析 https://japan.zdnet.com/article/35059965/2/ 2012年ごろから「マルチ」ビッグデータホルダーとして Web企業では国内最大規模のデータ活用を推進
DATUM STUDIO時代(2015-2016) 主な関わりのあるサービス • 不動産 • 人材派遣 • 自動車 •
ゲーム • 広告 • アクセス解析 8番目の社員として1年半で80名まで企業成長を牽引。 なお2018年10月にはKDDIグループのSupership社にバイアウト完了
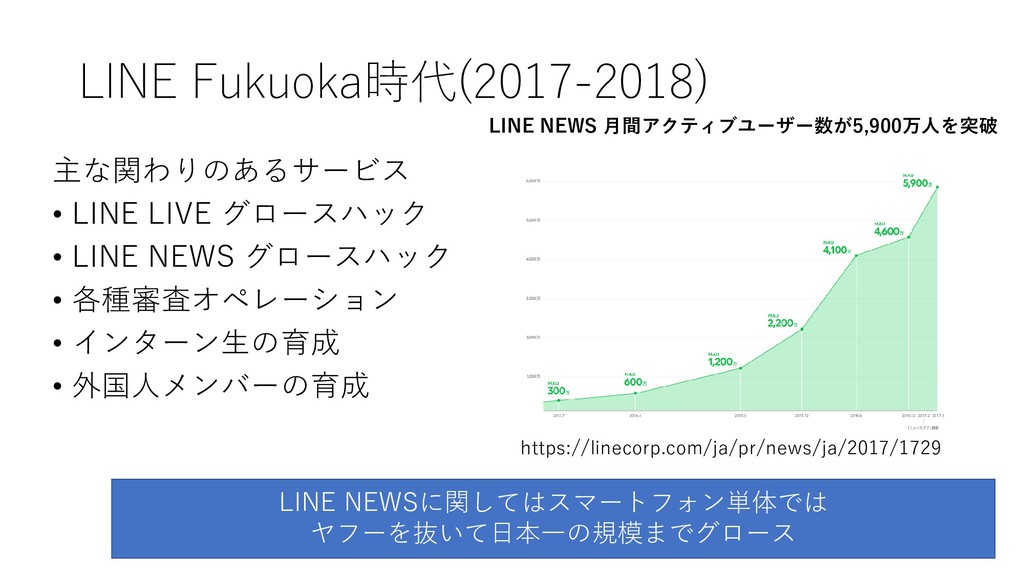
LINE Fukuoka時代(2017-2018) 主な関わりのあるサービス • LINE LIVE グロースハック • LINE NEWS
グロースハック • 各種審査オペレーション • インターン生の育成 • 外国人メンバーの育成 LINE NEWSに関してはスマートフォン単体では ヤフーを抜いて日本一の規模までグロース https://linecorp.com/ja/pr/news/ja/2017/1729 LINE NEWS 月間アクティブユーザー数が5,900万人を突破
AI技術活用が競争力となる時代 • インドの格安ホテル「OYO(オヨ)」が2018年度内に日本進 出、ITを駆使した運営で急成長 • https://www.hotelier.jp/inboundnews/other/20181022.html • 同社の高速成長のカギは、ITを駆使した運営だ。約8,500人の社 員のうち、700人超がデータ科学・人工知能(AI)・ソフトウ エアなどのIT技術者だという。進出した地域の宿泊需要データ
をAIで常時分析し、すべての空室の料金を個別に常時変化させ ている。また、地域内での需要のミスマッチを最小化すると同 時に、その地域内のホテル全体の稼働率を最大化する。
事前質問
Q.実際に今データが使われている事例 • 大小問わなければ、かなり多い (広すぎるので課題ベースの方が絞りやすいかも?) • リスク予測モデル : 貸し倒れ率計算、保険の料率設定 • マッチング系
: Amazonによるレコメンド、 Web広告、 Indeed • 最適化問題 : Uberによる巡回ルート最適化、ゲームの難易度設定 • 予測で日常的なものだと : 天気予報 • 態度変容を促す意味では最強 • データ視点での拡張 :スポーツ x データ、 人事 x データ、教育xデータ、不動産xデータ、… • 他分野とのクロス : 医療x購買、運動x保険、 • その他 • 意思決定支援、作業自動化、画像解析、音声解析、etc..
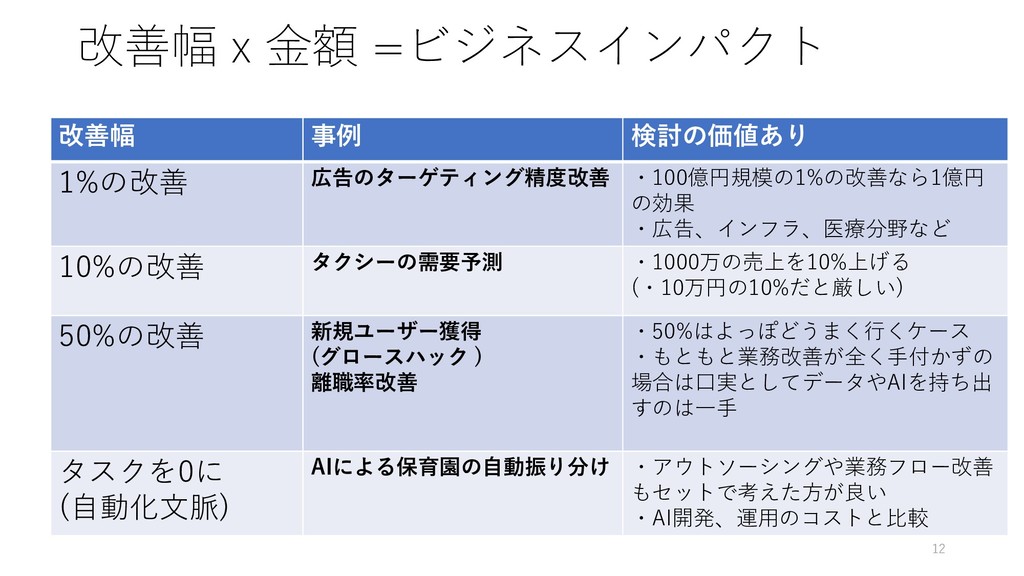
改善幅 x 金額 =ビジネスインパクト 改善幅 事例 検討の価値あり 1%の改善 広告のターゲティング精度改善 ・100億円規模の1%の改善なら1億円
の効果 ・広告、インフラ、医療分野など 10%の改善 タクシーの需要予測 ・1000万の売上を10%上げる (・10万円の10%だと厳しい) 50%の改善 新規ユーザー獲得 (グロースハック ) 離職率改善 ・50%はよっぽどうまく行くケース ・もともと業務改善が全く手付かずの 場合は口実としてデータやAIを持ち出 すのは一手 タスクを0に (自動化文脈) AIによる保育園の自動振り分け ・アウトソーシングや業務フロー改善 もセットで考えた方が良い ・AI開発、運用のコストと比較 12
Q. 検索・閲覧履歴からユーザーの嗜好に近い作品 をオススメする精度を高める方法を知りたい • 古典的な方法 • ターゲティング .. ユーザー属性等を利用 •
リターゲティング .. 前に見たものを再度出す • 機械学習を使う方法 • 教師あり学習モデル • 正解データに近い動きをした人を狙う(ランダムフォレストとか) • 行動ログ、閲覧ログ、広告clickログ、etc.. • 教師なしモデル • クラスタリングで近いものを分類(k-meansとか) • 属性、興味関心推定 • アンケートと組み合わせて行動パターンの近いユーザーの属性や興味関心をラベリング
Q.分析するデータをどうやって集めているのか • 自社データ • 業務用DB • 紙の情報を電子化 • 他社データ •
リサーチ業者から購入 • 他社サイトをクロール & スクレイピング • リサーチデータ • アンケート • 国の統計情報 • オープンデータ • Webサイト • サーバサイドのアクセスログ • Cookie情報、ログイン情報 • その他ロギングした情報 • ゲーム • ゲーム基盤DB • 行動ログ • ロガーを仕込んで発火 • JSのビーコン等 • 動画 • カメラ映像の解析
問い: ちなみにこの辺知ってますか? • ブラウザのリファラー情報 • URLのパラメータ • Webサーバーのアクセスログ
Q.医療業界で、 ①個人情報を扱う際の注意点、 ②実際に今データが扱われている事例 (新しい切り口での解析があれば) (医療業界専門ではありませんが) ・個人情報を扱う際の注意点 ・個人情報保護法を守る、情報漏洩対策、データの利用許諾 ・特に既往歴等の病気関連のデータはセンシティブなので注意 ・利用の際は個人情報のマスクやN匿名化など ・データ活用の事例
・画像解析との組み合わせ(内視鏡や細胞診など) ・睡眠治療のためのアプリを処方(サスメド社) ・あとは遺伝子検査系が海外だと流行ってそうな印象
国の動向に は注意(規制 したがり) https://www.nikkei.com/artic le/DGXMZO43867770X10C1 9A4MM8000/
注意
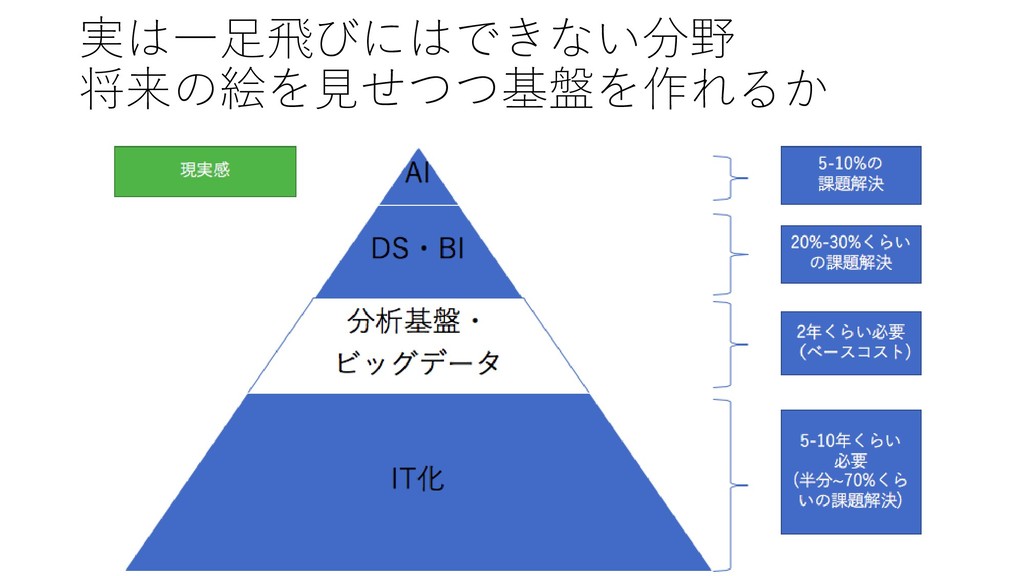
実は一足飛びにはできない分野 将来の絵を見せつつ基盤を作れるか
10年来のプレーヤーは もともとデータは目的ではない • ヤフーの場合 • 検索(ディレクトリ)サービス • 空いた枠に広告枠、という発明 • 広告の請求のためデータ基盤整備
• データを使った広告の精度UP、というループ • CCCの場合 • ビデオやDVDレンタルのための顧客情報整備 • Tポイントという形で様々な業種にアプローチ • 購買データなどを活用したマーケティング利用 本業の 副産物としての データ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}