В докладе будут рассмотрены примеры использования ORM Dapper и некоторых фич современных СУБД для создания приложений с быстрой обработкой большого количества данных и сложной бизнес-логикой. Какие конструкции и шаблоны упрощают жизнь в подобных проектах.
{kind=link}
{kind=link}
{kind=link}
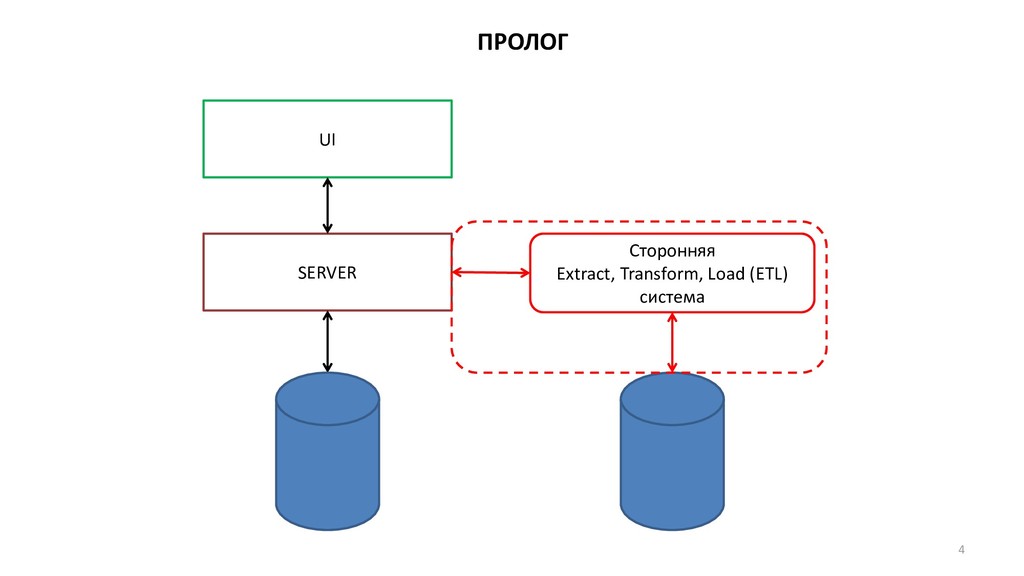{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
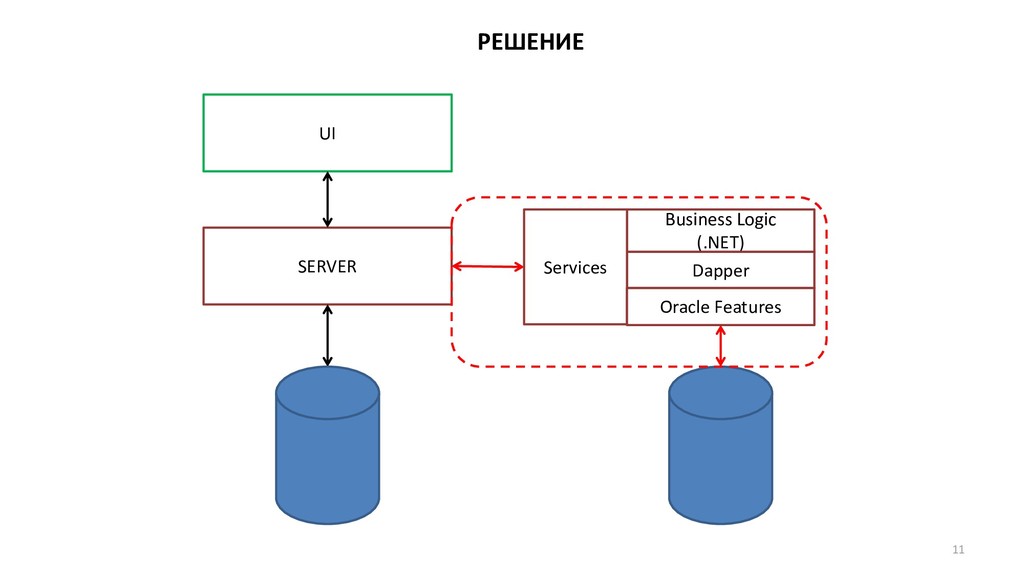{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Теперь можно делать так public Dictionary<IdOf<Client>, IdOf<Order>[]> GetPairs() => InConnection(connection](https://files.speakerdeck.com/presentations/f8601bc7e7ad4ae1ba65aa0e969a40fc/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
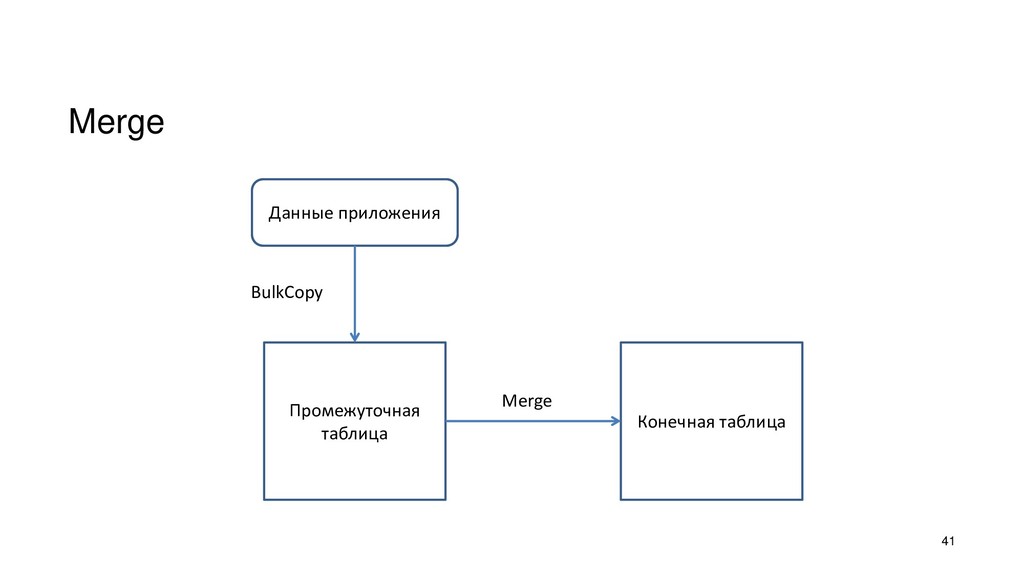{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо! Вопросы? 46 Орлов Юрий [email protected]](https://files.speakerdeck.com/presentations/f8601bc7e7ad4ae1ba65aa0e969a40fc/slide_45.jpg){kind=link}