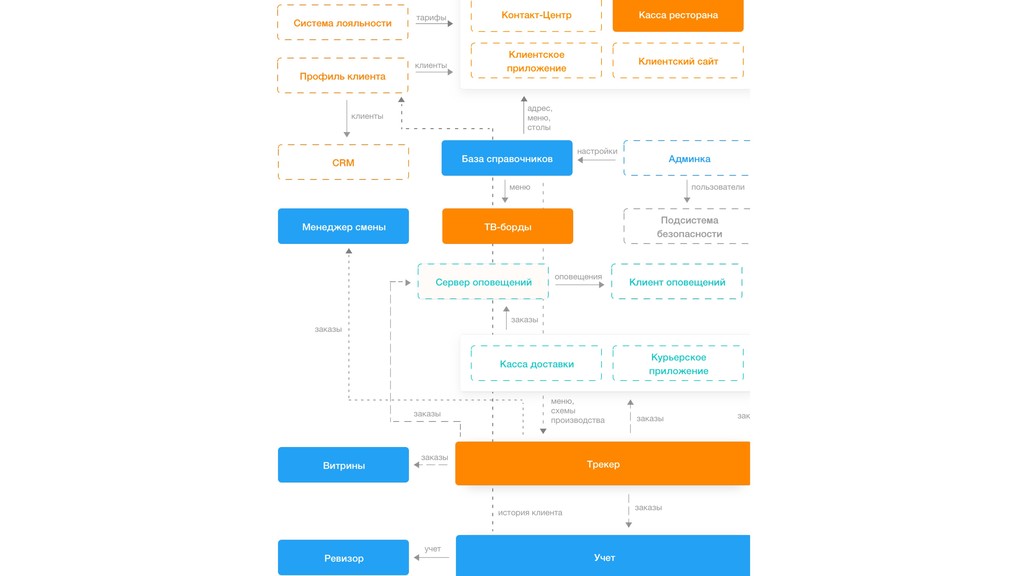
Все мы участвуем в проектировании систем. Сознательно или нет. Иногда делая десятки UML диаграмм, а иногда на салфетке или просто в уме.
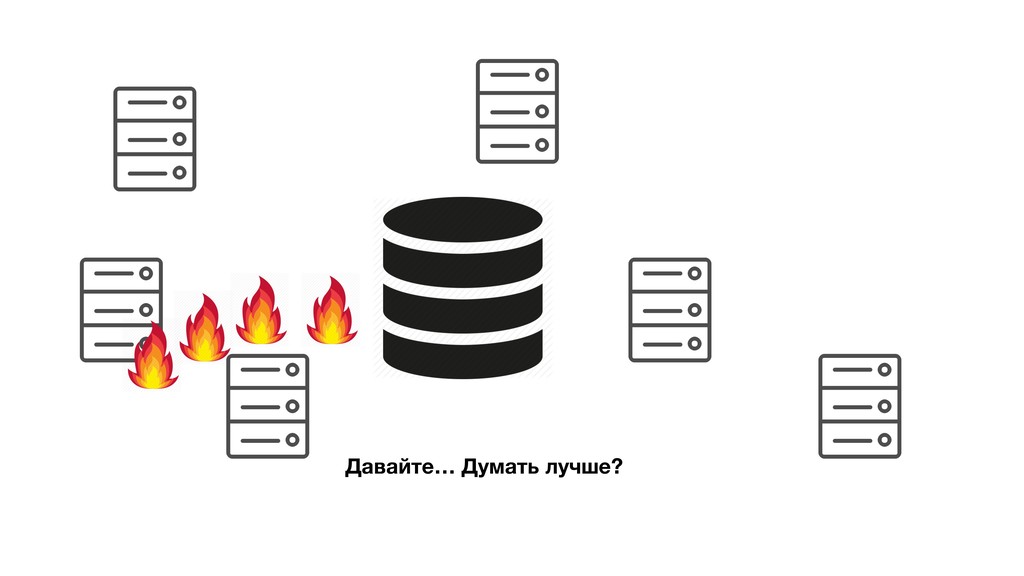
Но когда дело доходит до реализации, всплывают необдуманные моменты, которые могут заставить переделать всё. Особенно остро это сказывается на распределённых системах. И чем больше пользователей, тем острее.
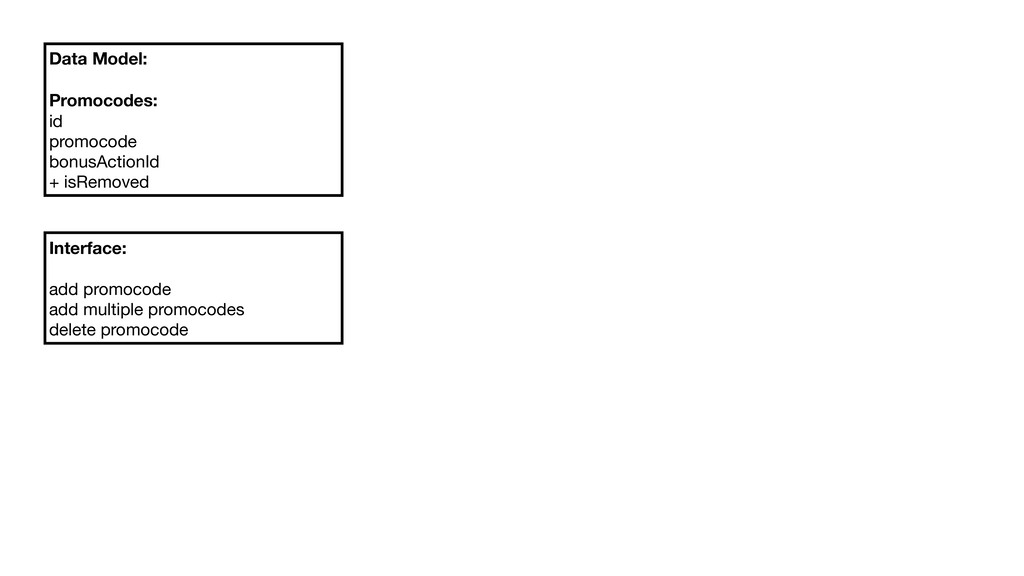
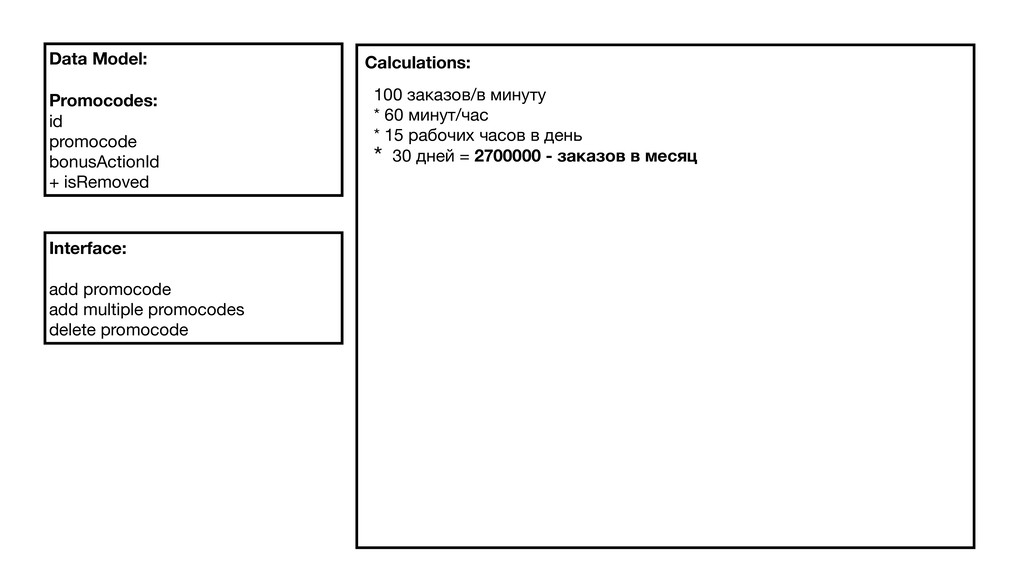
Гугл предлагает инженерный подход для решения вопроса: Non Abstract Large Scale System Design. Это набор инженерных практик при проектировании сервиса, которые позволяют меньше ошибаться. Я расскажу о том, как их применять.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
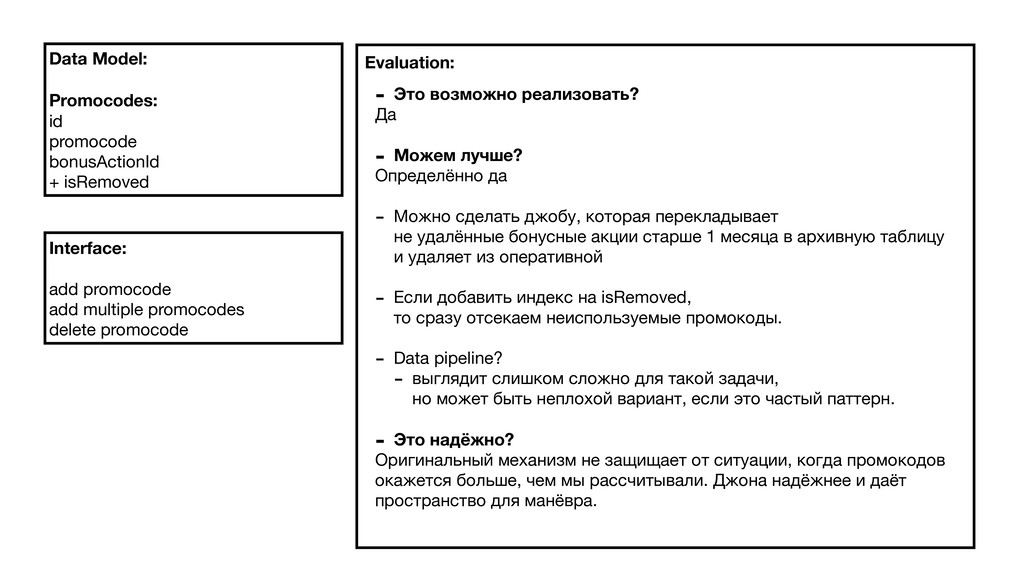{kind=link}
{kind=link}
{kind=link}
{kind=link}
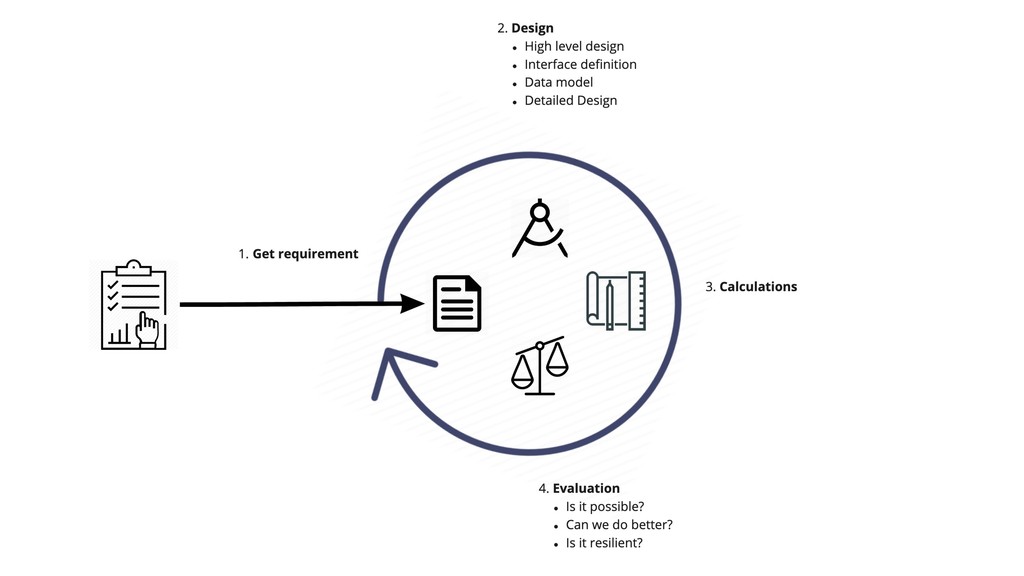{kind=link}
{kind=link}
{kind=link}
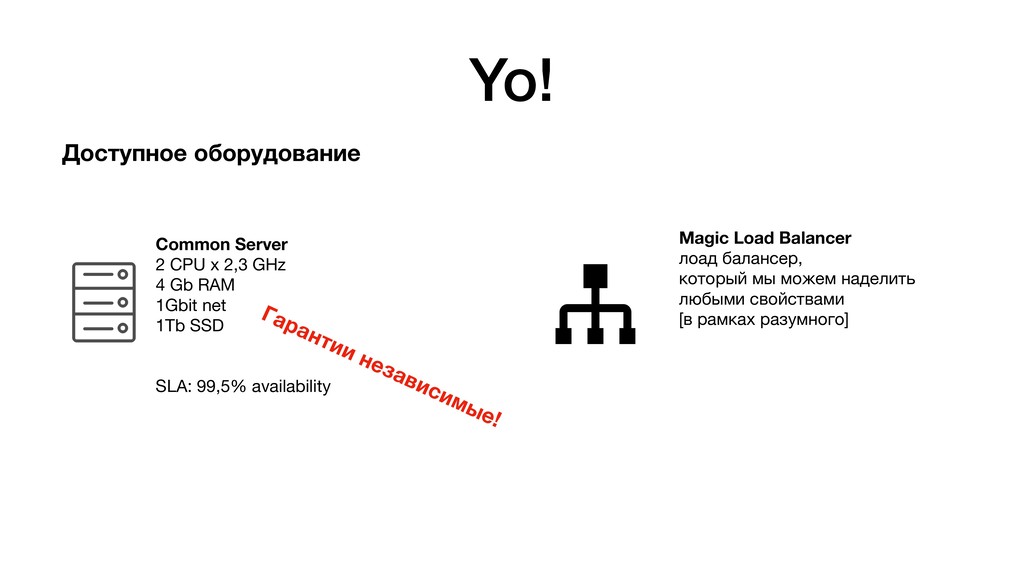{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
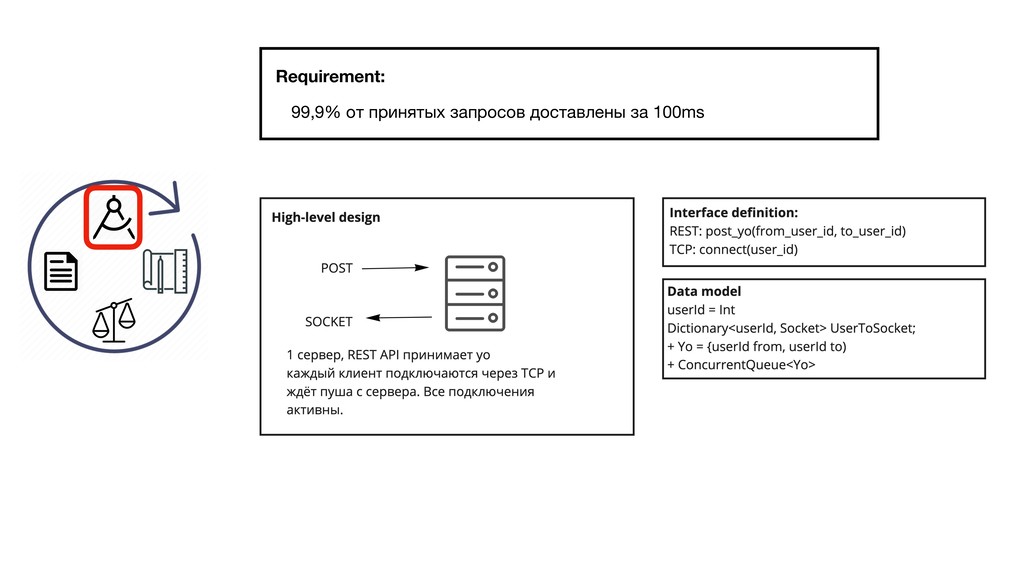{kind=link}
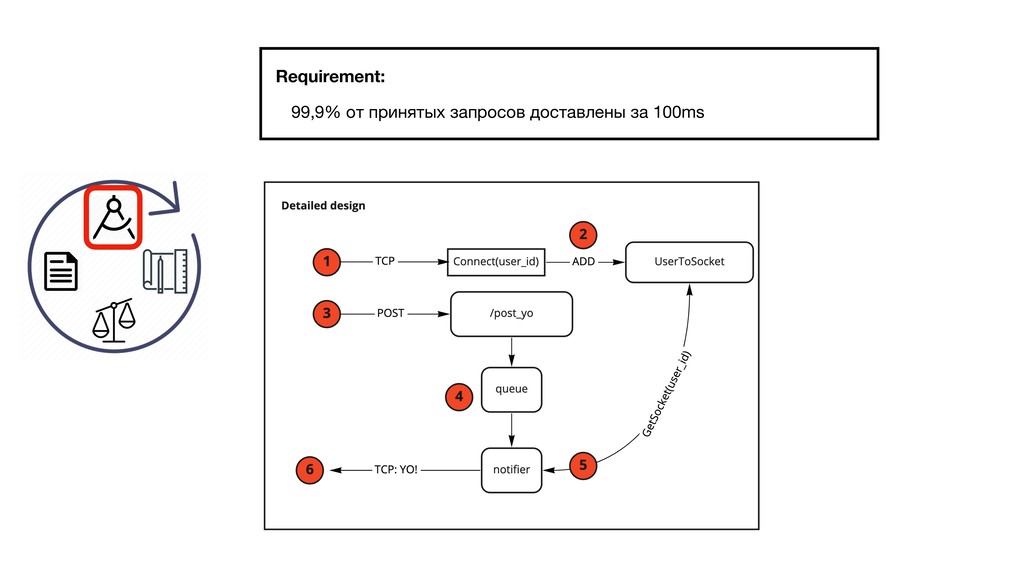{kind=link}
{kind=link}
{kind=link}
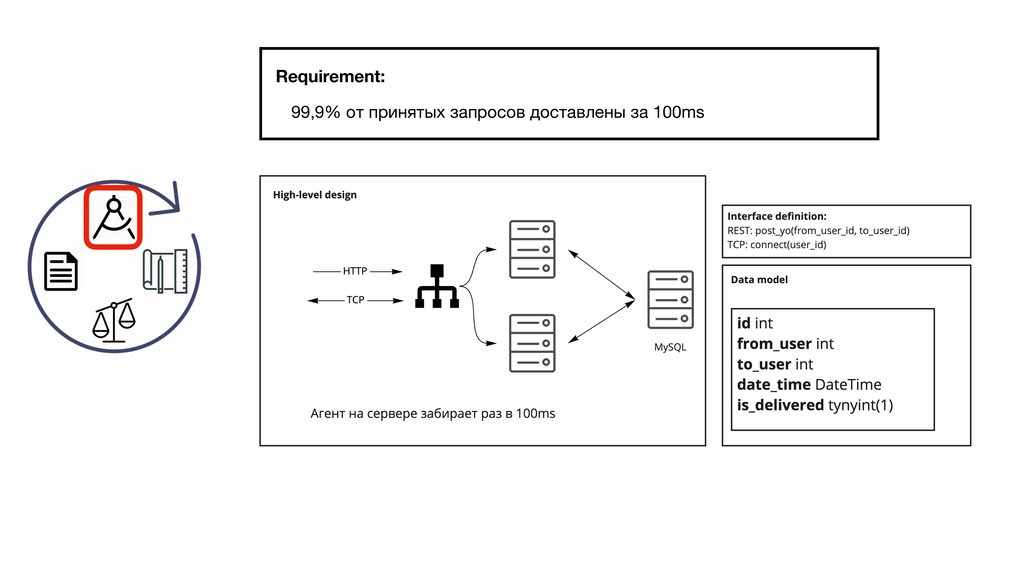{kind=link}
{kind=link}
{kind=link}
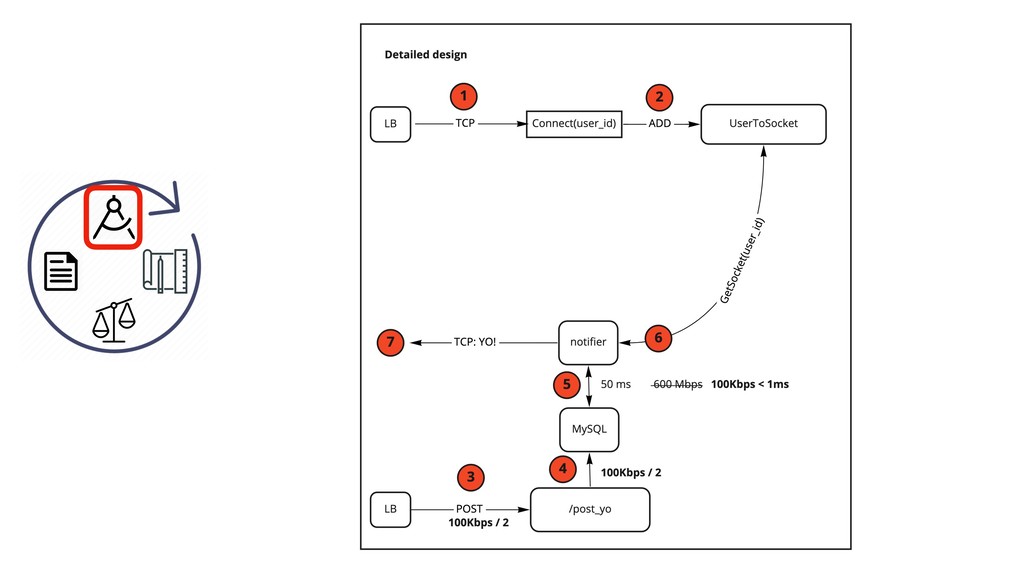{kind=link}
{kind=link}
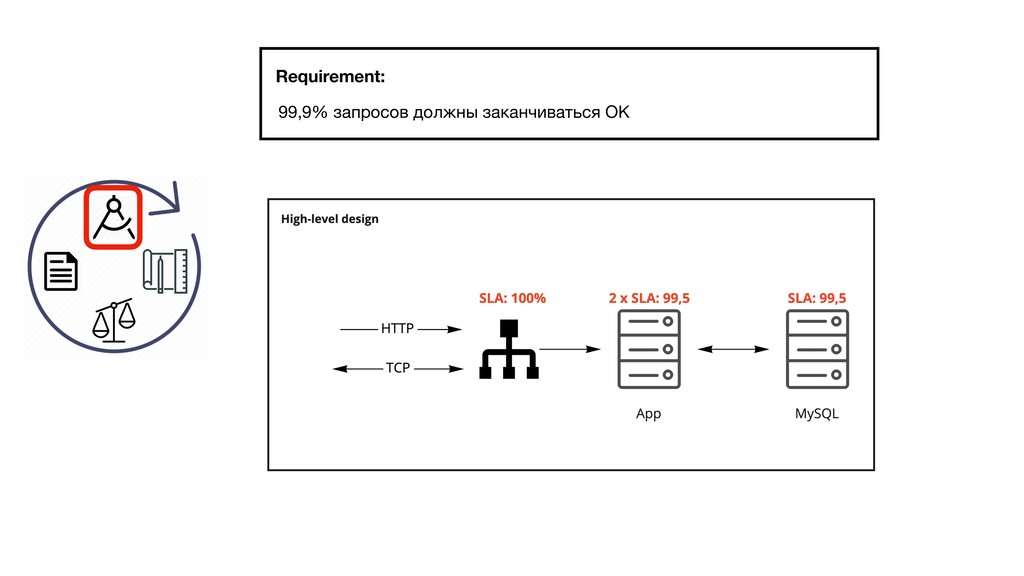{kind=link}
{kind=link}
{kind=link}
{kind=link}
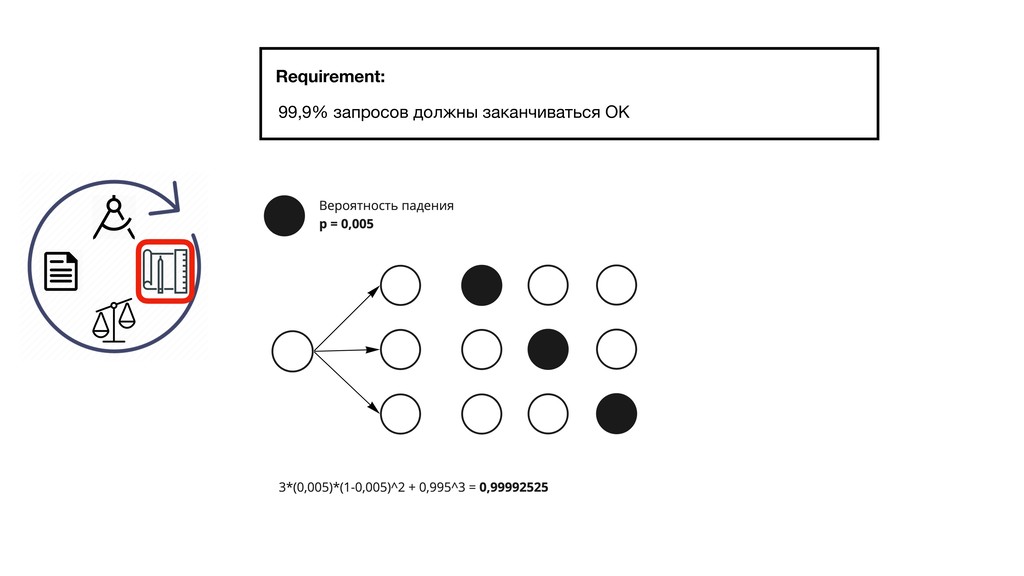{kind=link}
{kind=link}
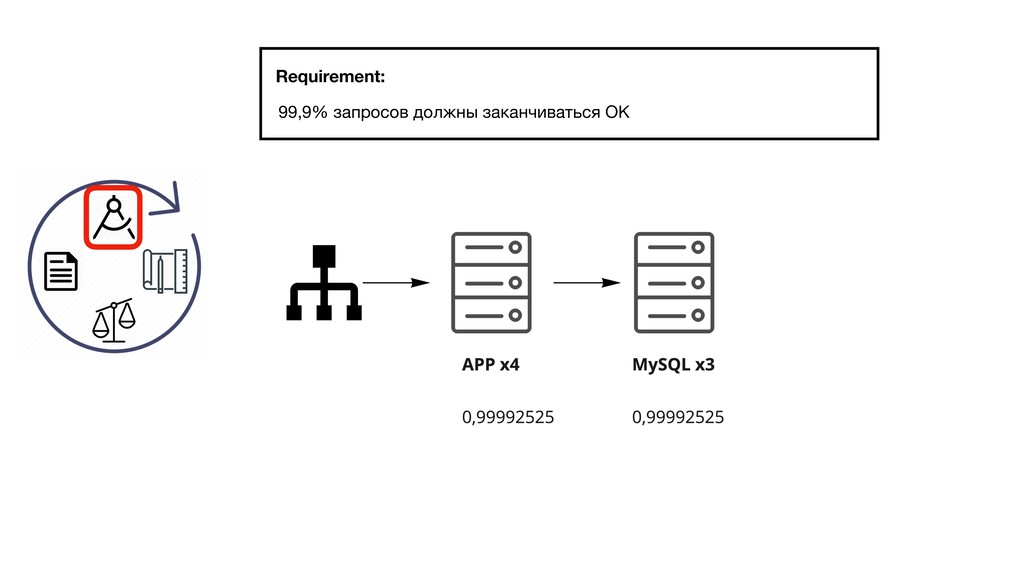{kind=link}
{kind=link}
{kind=link}
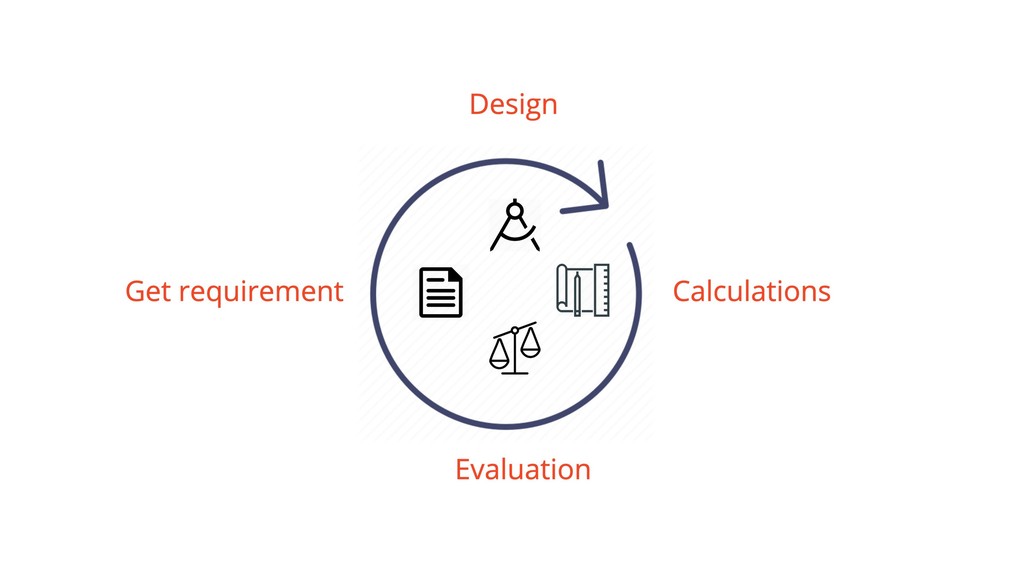{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}