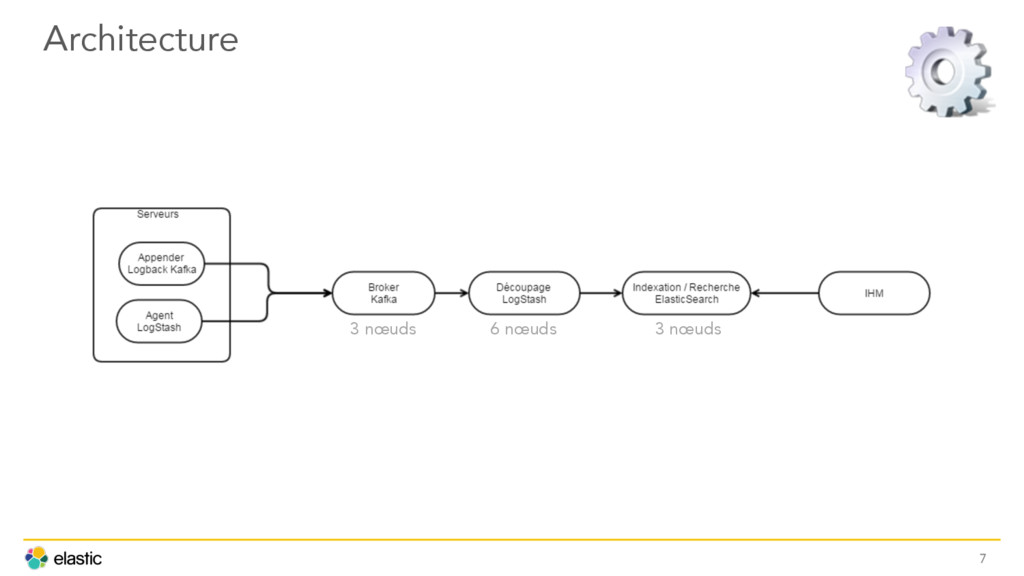
Avant 2011, ERDF disposait de nombreux serveurs qui généraient de grands volumes de logs corrélés entre eux mais non centralisés. Après estimation des solutions disponibles, ERDF a finalement construit une architecture combinant Logstash et Elasticsearch afin de centraliser et surveiller ses logs. La présenation offre également un retour d'expérience sur les différentes solutions de l'architecture d'ERDF.
Vladislav Pernin | Elastic{ON} Tour | Paris, France
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}