The Internet Archive’s Wayback Machine has collections that range in size from billions of archived web pages, to millions of scanned books, down to 10,000 quite-popular Grateful Dead concert recordings. See how Elasticsearch glues everything together and hear some lessons learned along the way.
{kind=link}
{kind=link}
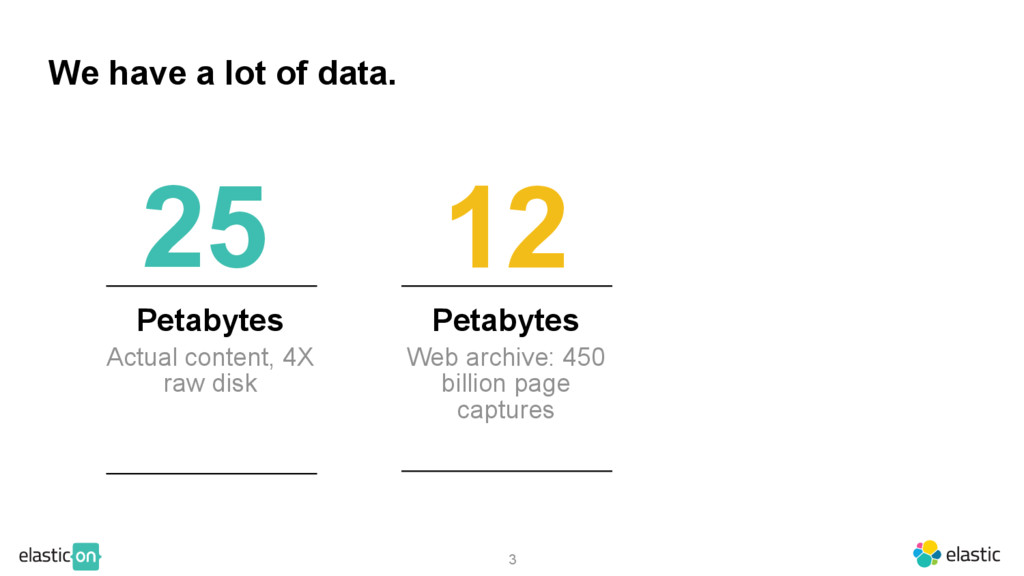{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}