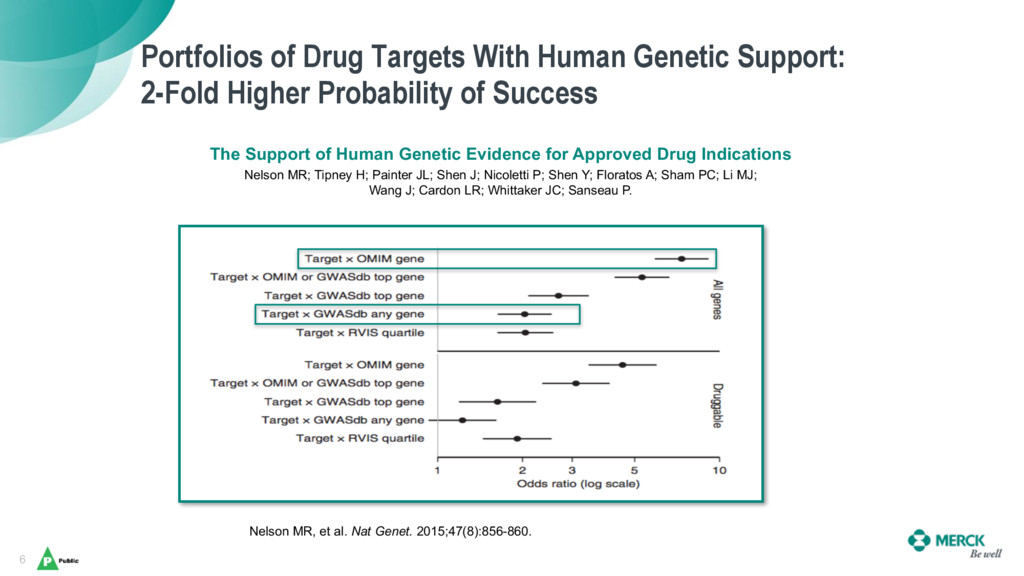
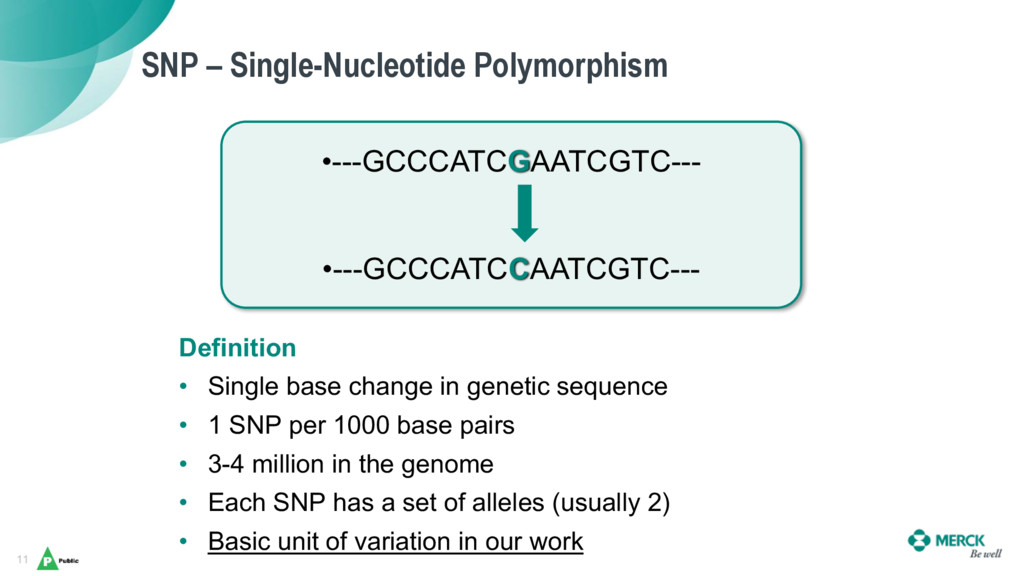
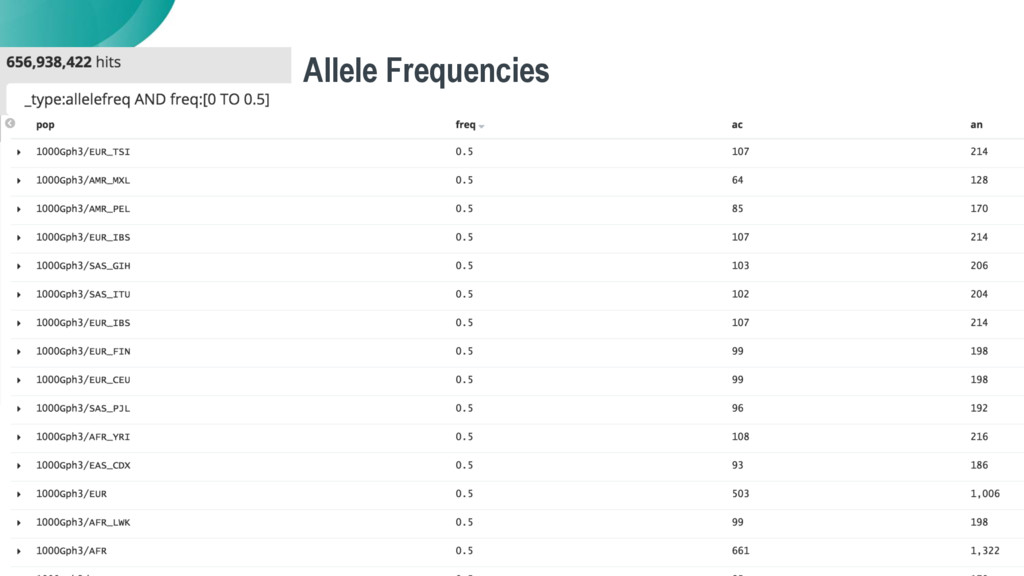
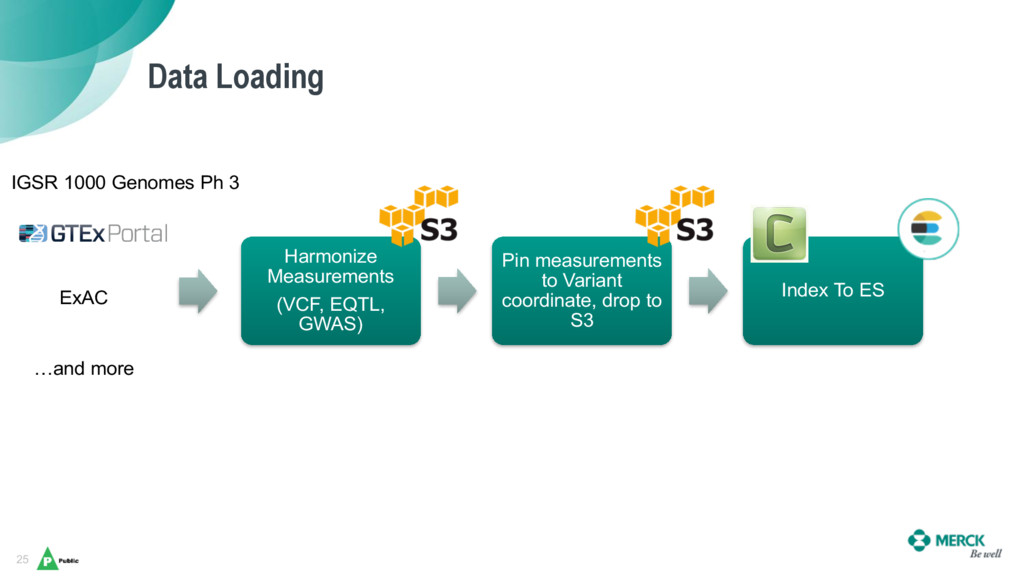
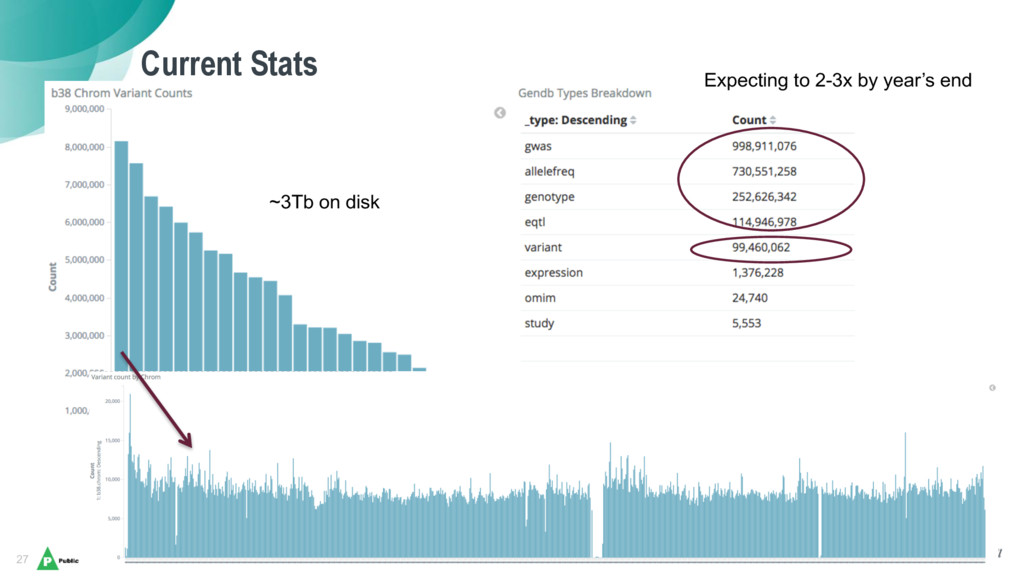
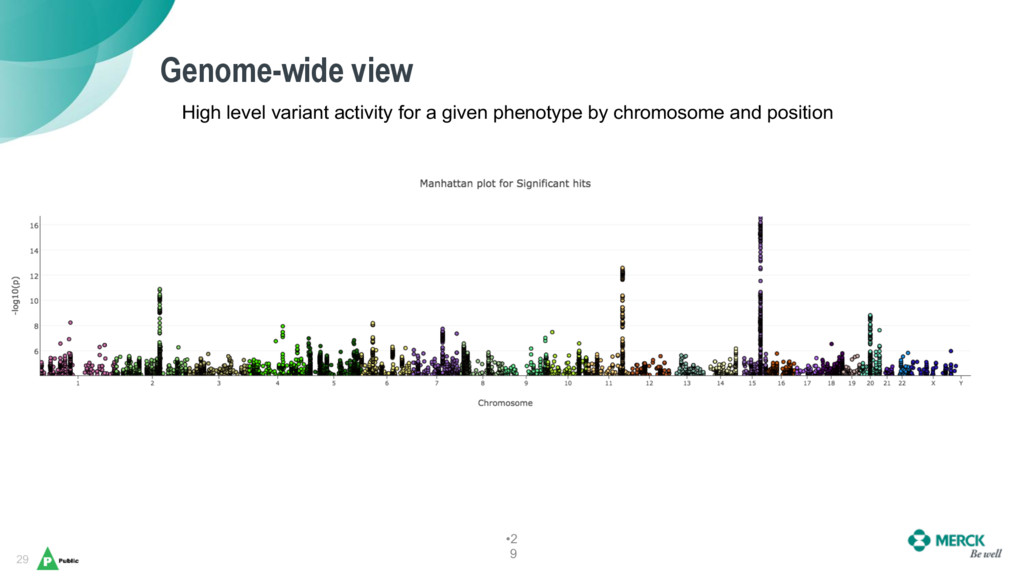
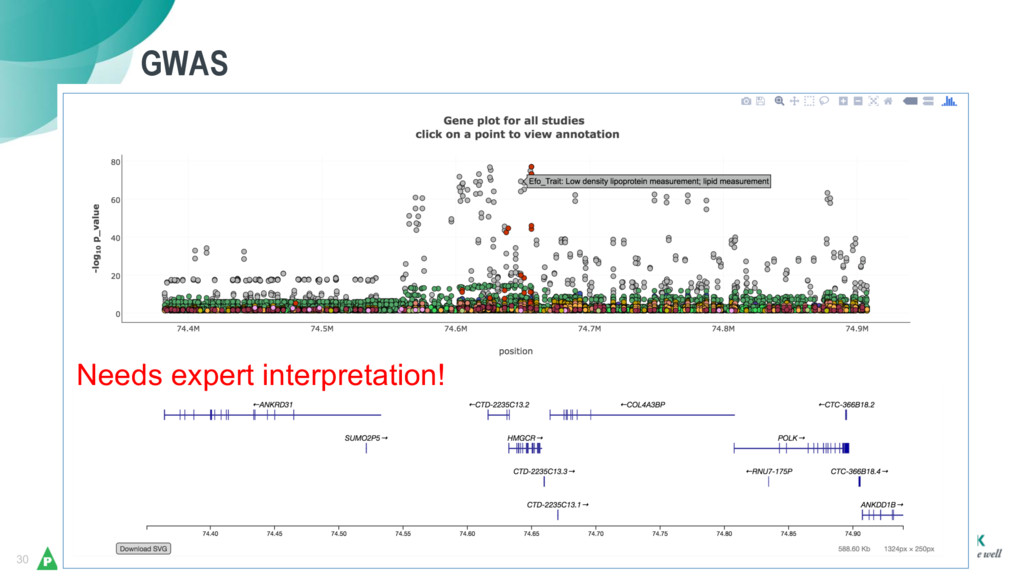
As genome sequencing’s costs have dramatically fallen, scientists have been awash in genetic data for novel research – but the existing tools and methods for analysis were not scaling well in terms of data size and harmonization, and they are also tedious, manual, and require a significant amount of expert integration.
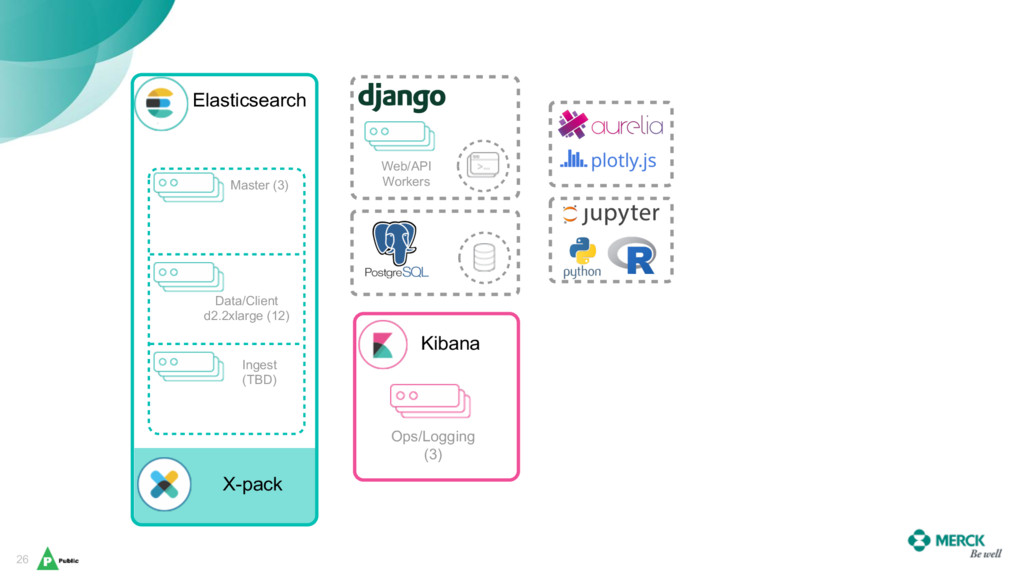
Daniel and Bhasker will share Merck’s journey with Elasticsearch, which has enabled them to harmonize a data ingestion pipeline and create a universal coordinate system for genetic variants as a backbone to help scientists uncover new insights on human genetics across a broad spectrum of diseases (from cancers, alzheimer’s, diabetes), and to aid in the discovery and validation of new therapies.
Bhasker Bokuri l DBA l Merck
Daniel Myung l Sr. Software Engineer/Project Lead l Merck
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![33 Thank You! Daniel Myung ([email protected]) Bhasker Bokuri ([email protected]) Special](https://files.speakerdeck.com/presentations/0eaf522190ac42e497c7859bfb779ceb/slide_32.jpg){kind=link}