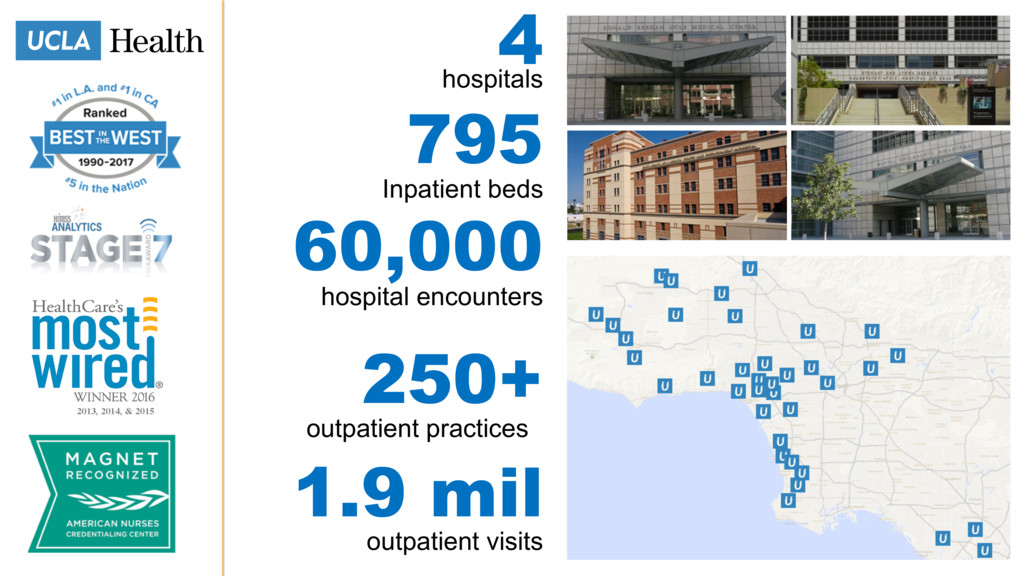
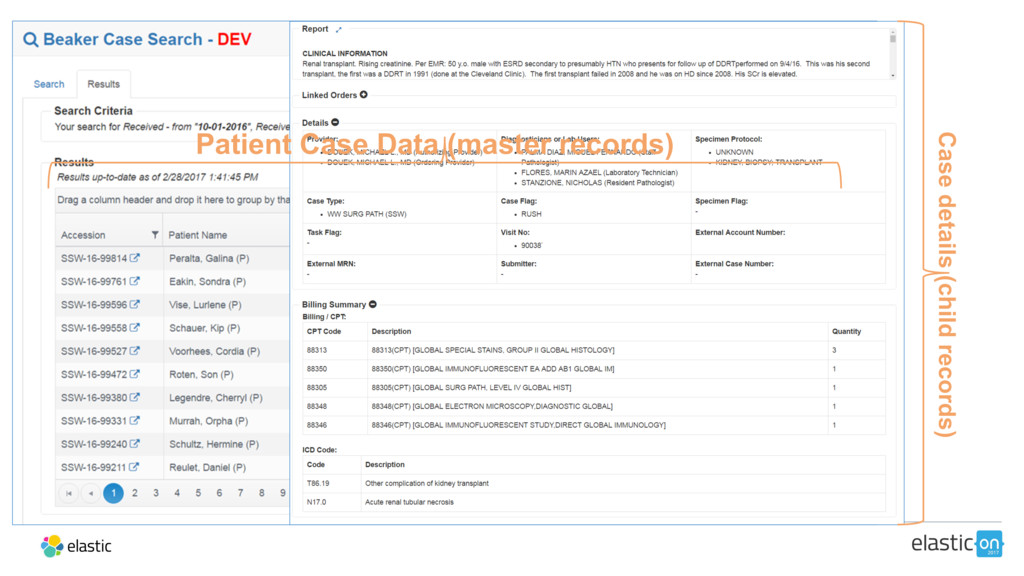
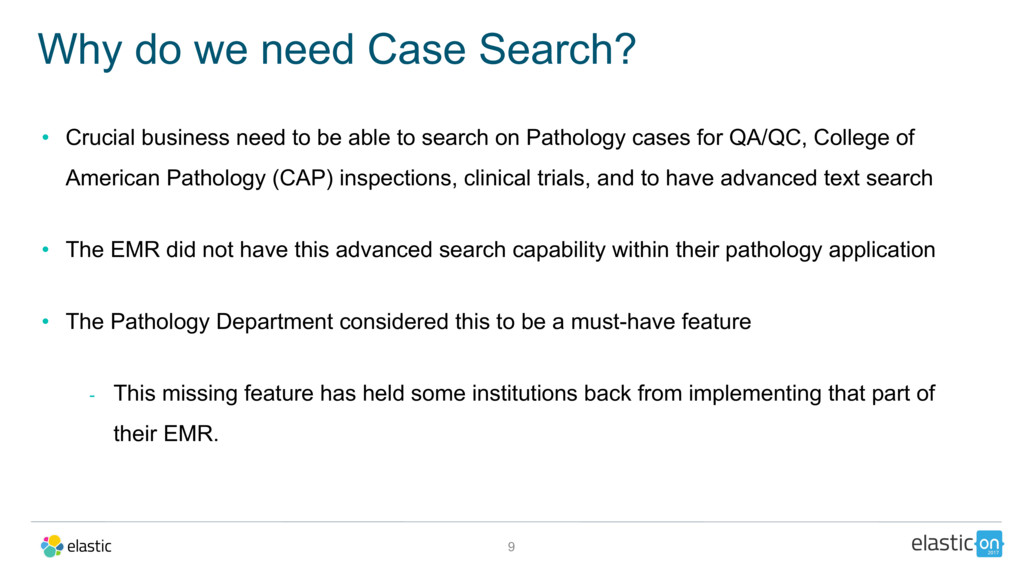
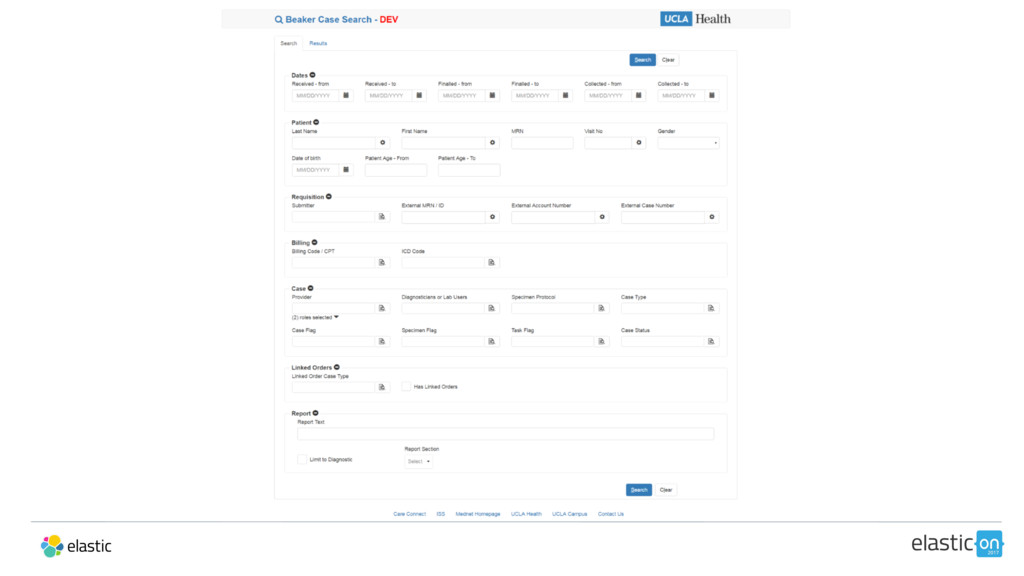
As healthcare institutions generate more data, they need a way to search through electronic health records (EHR) and find meaningful insights. UCLA Health has chosen Elasticsearch as its tool of choice to index, search, and produce more thorough, actionable results for clinicians and researchers.
Vivek Katakwar l Analytics Application Developer l UCLA Health
Shehzad Sheikh l Manager, Analytical Solutions l UCLA Health
Paul Tung l Solutions Architect l UCLA Health
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![41 Questions? Shehzad Sheikh Manager, Analytic Solutions – [email protected] Vivek](https://files.speakerdeck.com/presentations/1c16c7927c78410aace26557cff8e876/slide_40.jpg){kind=link}
{kind=link}