indications to enable the inquirer to find the passages of the Bible where the words occur. ! The first concordance, completed in 1230, was undertaken under the guidance of Hugo de Saint-Cher (Hugo de Sancto Charo), assisted by fellow Dominicans.
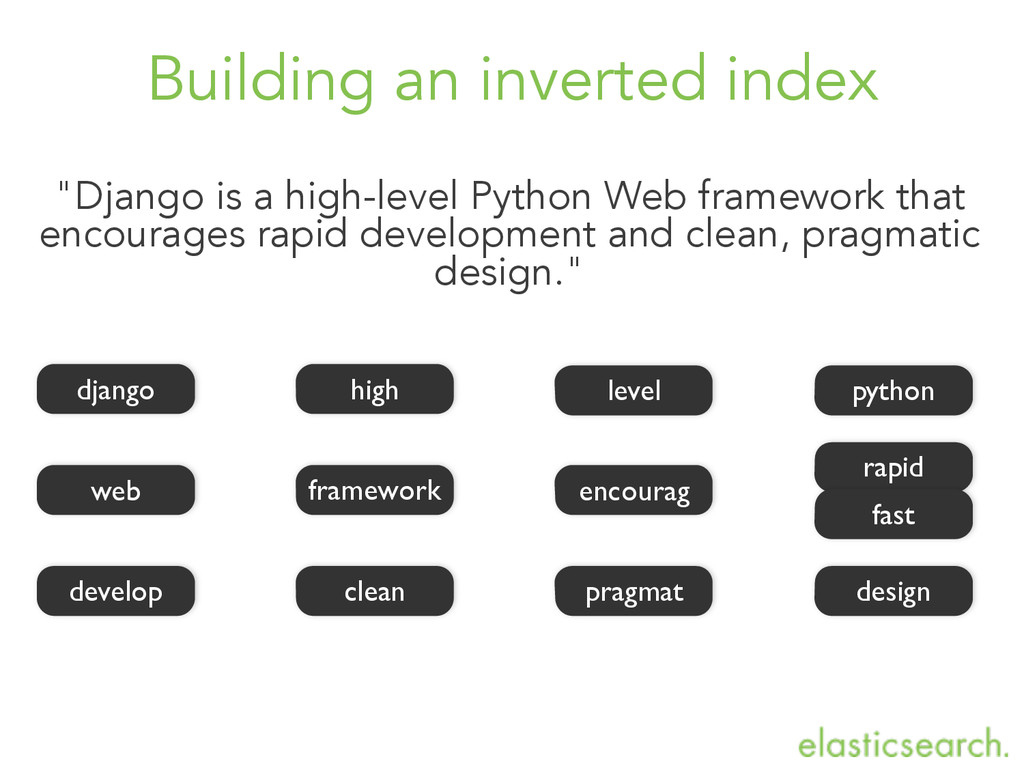
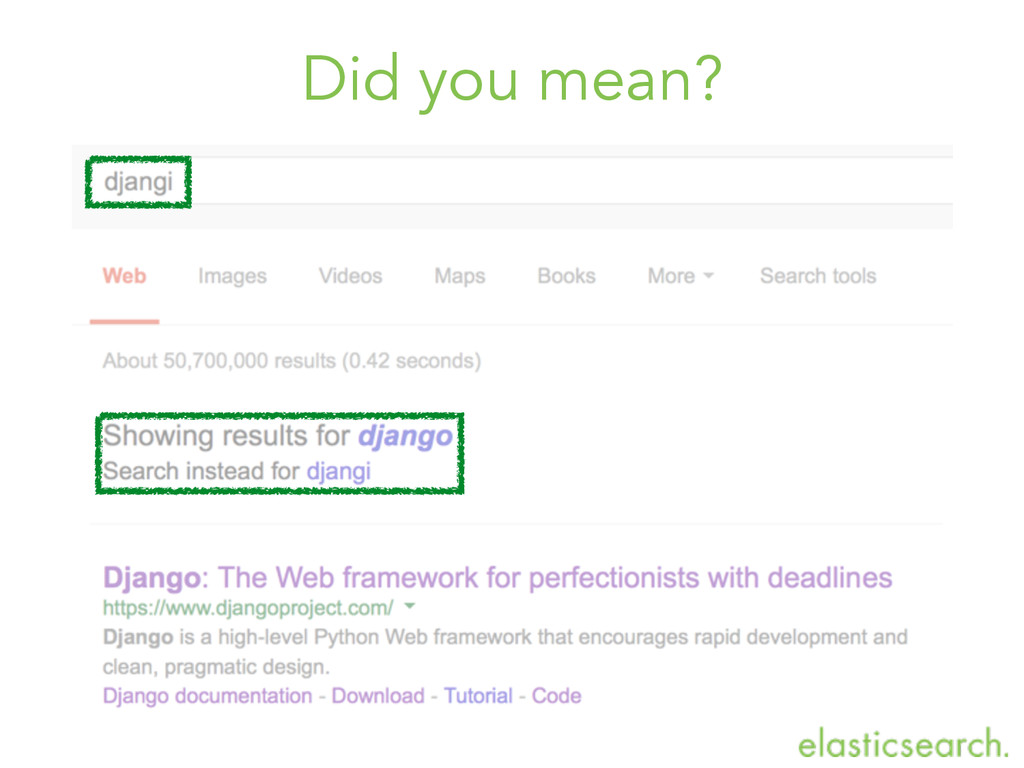
framework that encourages rapid development and clean, pragmatic design." django high level python web framework encourag rapid develop clean pragmat design fast
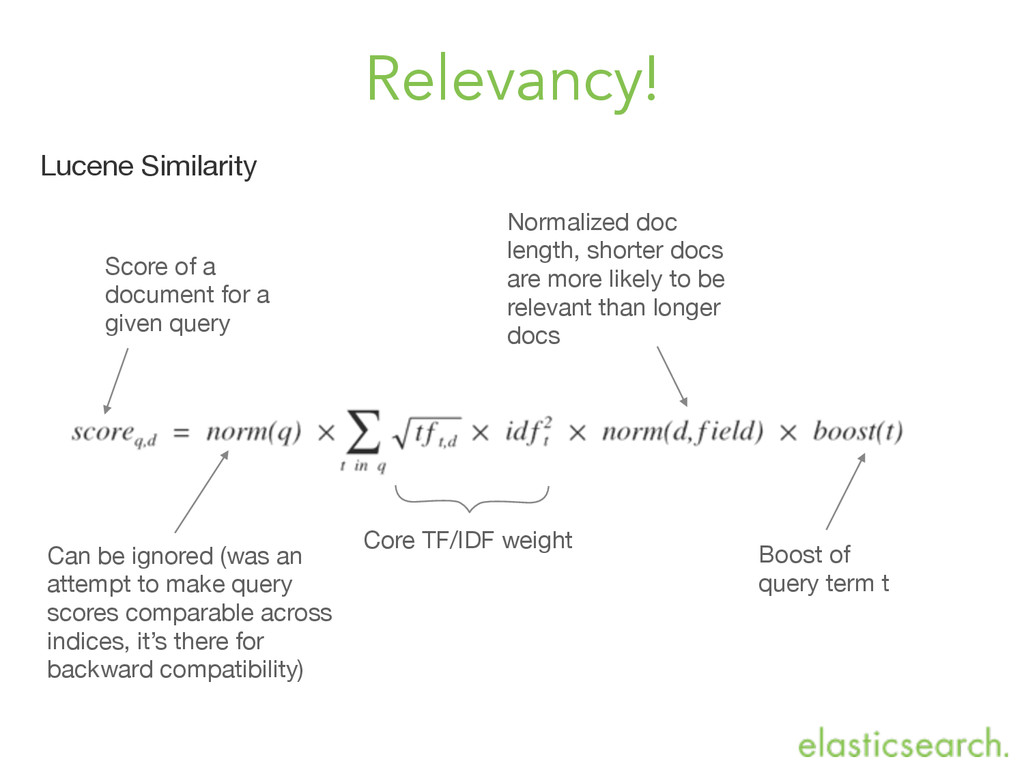
make query scores comparable across indices, it’s there for backward compatibility) Core TF/IDF weight Score of a document for a given query Normalized doc length, shorter docs are more likely to be relevant than longer docs Boost of query term t
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Highlighting encourag encourag [49:59] rapid rapid [60:65] fast [60:65] fast](https://files.speakerdeck.com/presentations/f71a25c0c31a013186c31652ff098141/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![thank you! Honza Král twitter: @honzakral email: [email protected] ! !](https://files.speakerdeck.com/presentations/f71a25c0c31a013186c31652ff098141/slide_39.jpg){kind=link}