Presented by Britta Weber at the Elasticsearch Switzerland User Group
You can find the scripts that accompany this presentation at
https://gist.github.com/brwe/292681b8e4ab2612633f
Abstract:
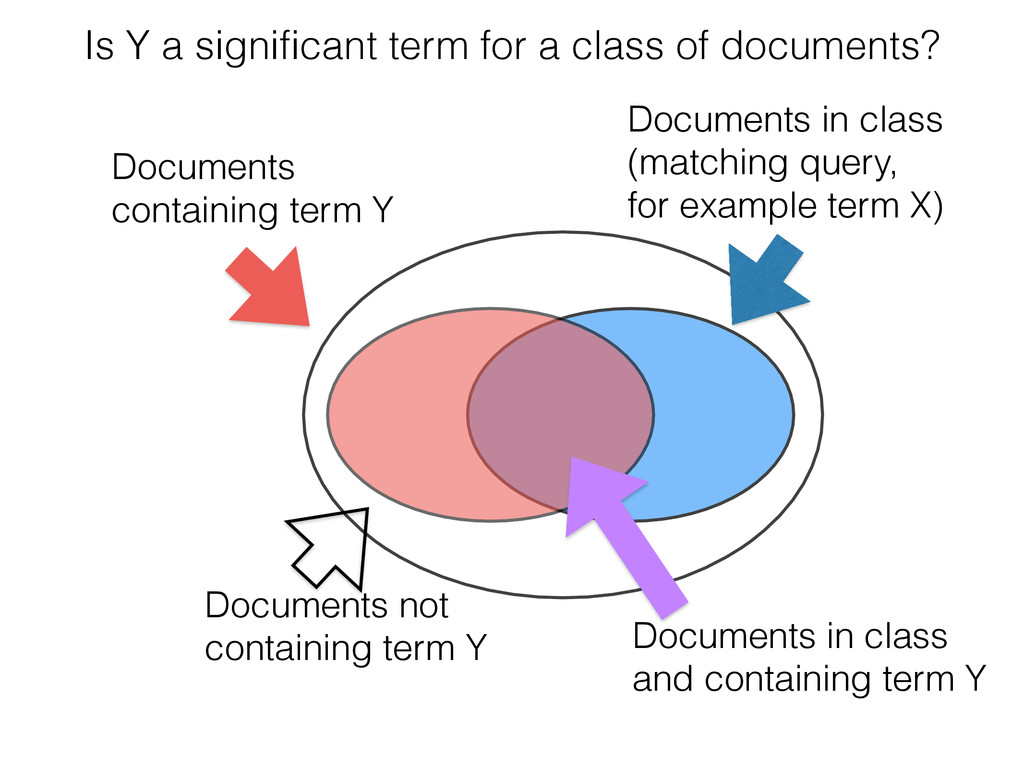
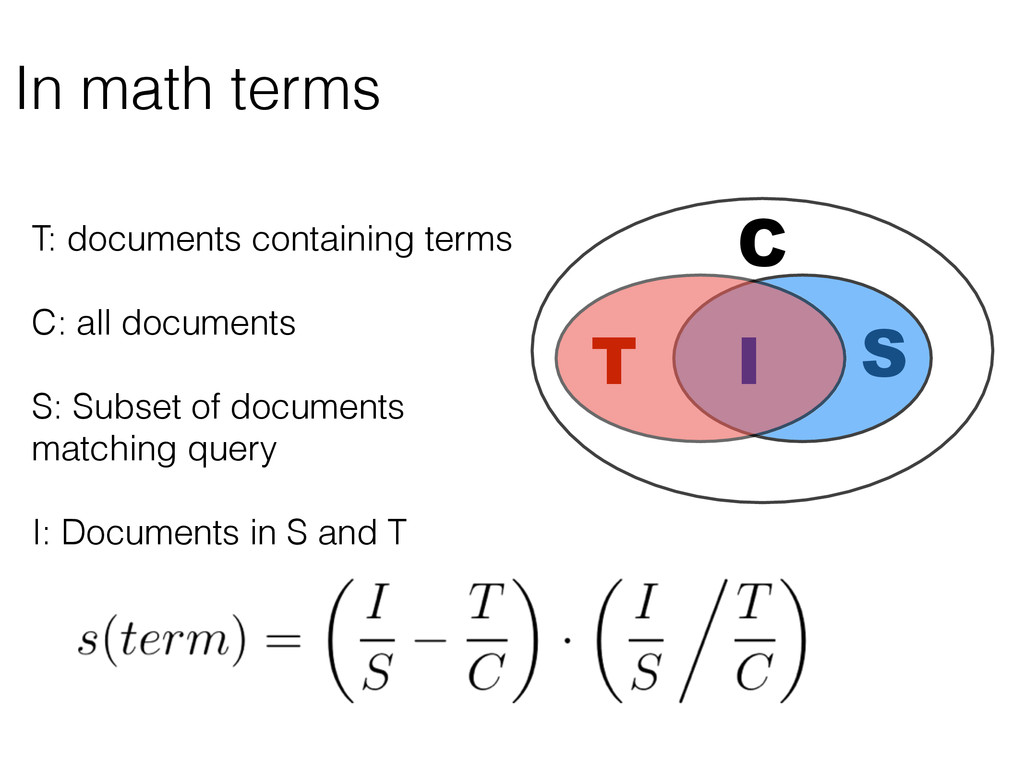
The significant terms aggregation is a feature that allows to users to identify terms that are relevant to a particular set of documents. Relevance here does not only mean how often a term occurs but how much more often a term occurs in the set compared to the whole document collection. In these slides, Britta explains how "significance" is measured here and shows some use cases for this type of aggregation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}