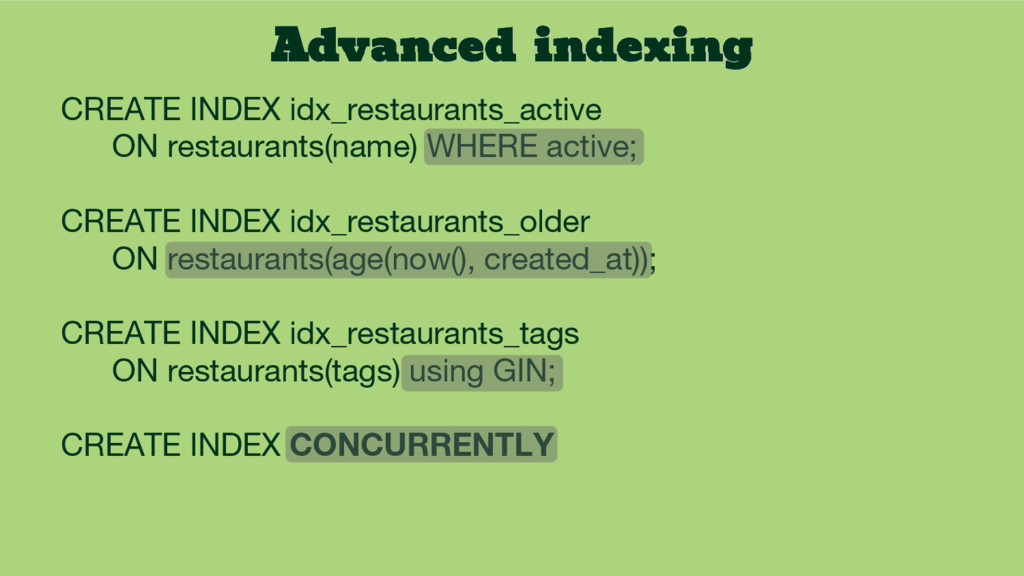
INDEX idx_restaurants_older ON restaurants(age(now(), created_at)); CREATE INDEX idx_restaurants_tags ON restaurants(tags) using GIN; CREATE INDEX CONCURRENTLY
FROM sales ORDER BY 1 $$, $$ SELECT m FROM generate_series(1,4) m $$ ) AS ( year int, "Q1" int, "Q2" int, "Q3" int, "Q4" int); YEAR │ Q1 │ Q2 │ Q3 │ Q4 2015 │ x │ 16 │ x │ 30 2016 │ 15 │ 912 │ 34 │ 1
from invoices group by day order by day ASC; Day │ total 2016-08-01 00:00:00 │ 3 2016-08-02 00:00:00 │ 157 2016-08-03 00:00:00 │ 480 2016-08-04 00:00:00 │ 783 2016-08-05 00:00:00 │ 625 2016-08-06 00:00:00 │ 442 2016-08-07 00:00:00 │ 444
as title, to_tsvector(body) as body, created_at from post where active=True; create index on active_posts using gist(title, body); refresh materialized view active_posts;
of success, but rather try to become a man of value'); select to_tsvector('It''s kind of fun to do the impossible') @@ to_tsquery('impossible'); More info on rachbelaid.com blog 'becom':4,13 'man':6,15 'rather':10 'success':8 'tri':1,11 'valu':17
tasks, array_agg(name) as task_list FROM tasks GROUP BY username,project), top_projects_tasks AS ( SELECT project, count(*) as tasks FROM tasks GROUP BY project ORDER by tasks DESC)
Total Cost) Rows: Rows returned => explain ANALYZE select * from city where name='Vigo'; Seq Scan on city (cost=0.00..82.99 rows=1 width=31) (actualtime=0.114..0.676 rows=1 loops=1) Filter: (name = 'Vigo'::text) Rows Removed by Filter: 4078 Planning time: 0.079 ms Execution time: 0.702 ms
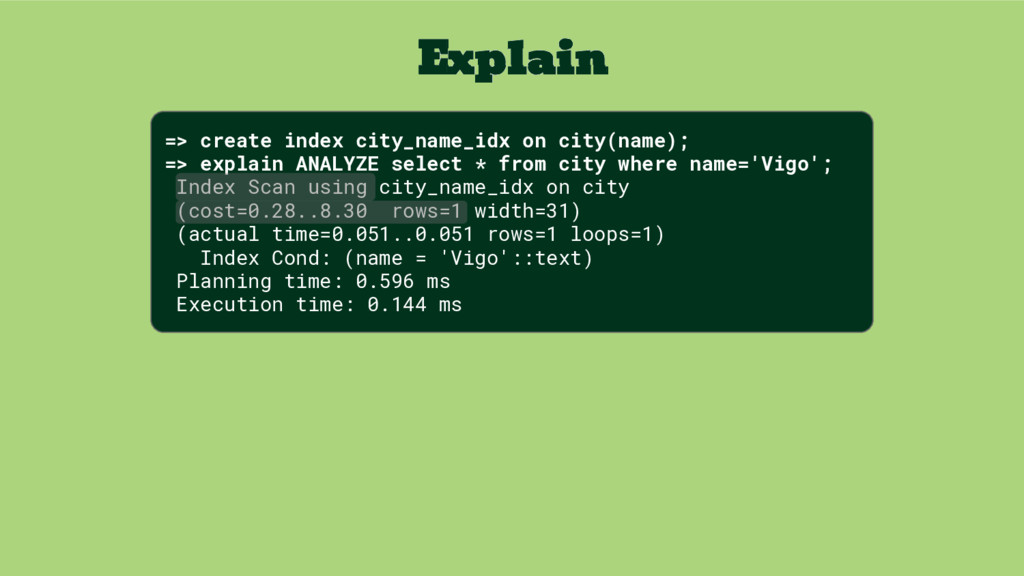
select * from city where name='Vigo'; Index Scan using city_name_idx on city (cost=0.28..8.30 rows=1 width=31) (actual time=0.051..0.051 rows=1 loops=1) Index Cond: (name = 'Vigo'::text) Planning time: 0.596 ms Execution time: 0.144 ms
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Arrays CREATE TABLE restaurants ( name text, typical_dishes varchar(255)[] );](https://files.speakerdeck.com/presentations/0909c5cdb8224c25a3f88ef113968609/slide_5.jpg){kind=link}
![select name, typical_dishes[1] from restaurants; select * from restaurants where](https://files.speakerdeck.com/presentations/0909c5cdb8224c25a3f88ef113968609/slide_6.jpg){kind=link}
![Filter options select * from restaurants where .. typical_dishes[1] ==](https://files.speakerdeck.com/presentations/0909c5cdb8224c25a3f88ef113968609/slide_7.jpg){kind=link}
![Functions Function Result array_append(ARRAY[1,2], 3) {1,2,3} array_cat(ARRAY[1], ARRAY[4,5]) {1,4,5} array_length(array[1,2,3],](https://files.speakerdeck.com/presentations/0909c5cdb8224c25a3f88ef113968609/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Email: [email protected] Blog: http://acalustra.com Twitter: @eloycoto Graciñas!](https://files.speakerdeck.com/presentations/0909c5cdb8224c25a3f88ef113968609/slide_52.jpg){kind=link}