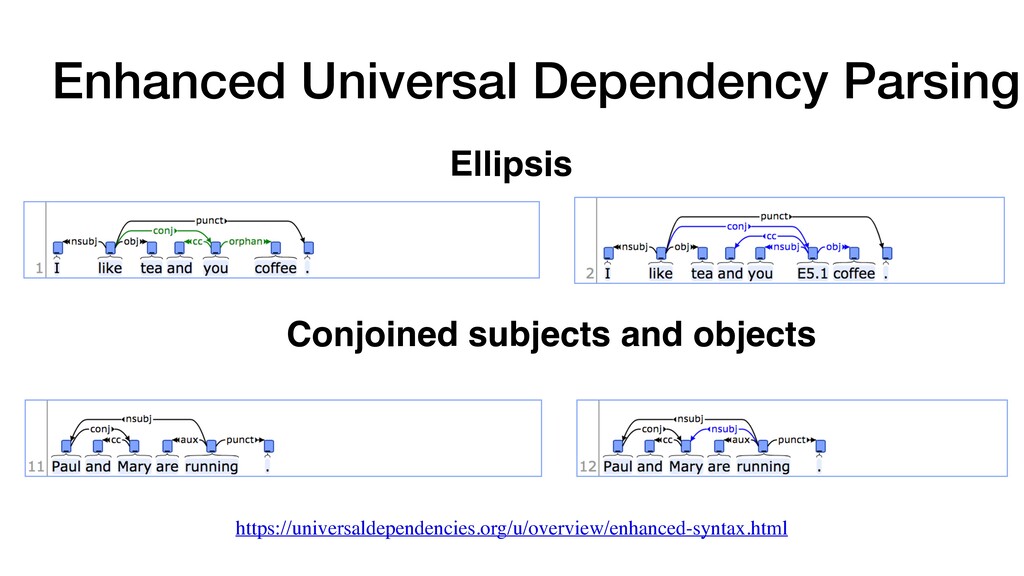
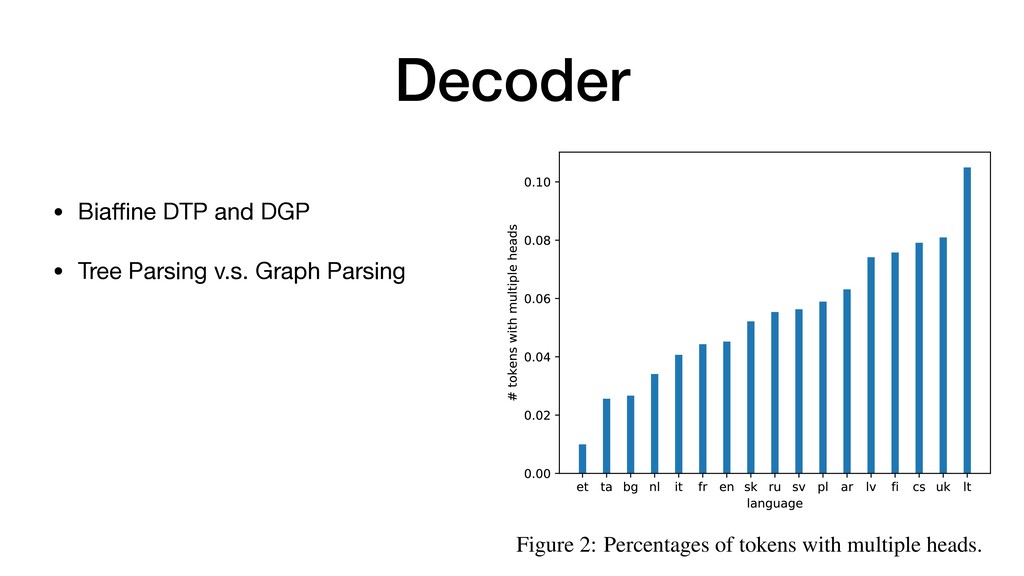
Dependency Tree & Graph Parsing The arc score matrix S (arc) and the label score ten- sor S(rel) generated by the bilinear and biaffine clas- sifiers can be used for both dependency tree parsing (DTP) and graph parsing (DGP). For DTP, which takes only the primary dependencies to learn tree structures during training, the Chu-Liu-Edmond’s Maximum Spanning Tree (MST) algorithm is ap- plied to S (arc) for the arc prediction, then the label with largest score in S(rel) corresponding to the arc is taken for the label prediction (ADTP: the list of predicted arcs, LDTP: the labels predicted for ADTP, I: the indices of ADTP in S(rel)): ADTP = MST(S (arc)) LDTP = argmax(S(rel)[I(ADTP)]) For DGP, which takes the primary as well as the secondary dependencies in the enhanced types to learn graph structures during training, the sigmoid function is applied to S (arc) instead of the softmax function (Figure 1) so that zero to many heads can be predicted per node by measuring the pairwise losses. Then, the same logic can be used to predict the labels for those arcs as follows: ADGP = SIGMOID(S (arc)) LDGP = argmax(S(rel)[I(ADGP)]) the output of the DGP model is NP-hard (Schluter, 2014). Thus, we design an ensemble approach that computes approximate MSDAGs using a greedy al- gorithm. Given the score matrices S (arc) DTP and S (arc) DGP from the DTP and DGP models respectively and the label score tensor S(rel) DGP from the DGP model, Algorithm 1 is applied to find the MSDAG: Algorithm 1: Ensemble parsing algorithm Input: S (arc) DTP , S (arc) DGP , and S(rel) DGP Output: G, that is an approximate MSDAG 1 r root index(ADTP) 2 S(rel) DGP [root, :, :] 1 3 S(rel) DGP [root, r, r] +1 4 R argmax(S(rel) DGP )) 2 Rn⇥n 5 ADTP MST(S (arc) DTP ) 6 G ; 7 foreach arc (d, h) 2 A DTP do 8 G G [ {(d, h, R[d, h]} 9 end 10 ADGP sorted descend(SIGMOID(S (arc) DGP )) 11 foreach arc (d, h) 2 A DGP do 12 G (d,h) G [ {(d, h, R[d, h]} 13 if is acyclic(G (d,h)) then 14 G G (d,h) 15 end 16 end • DTP (Tree) + DGP (Graph)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}