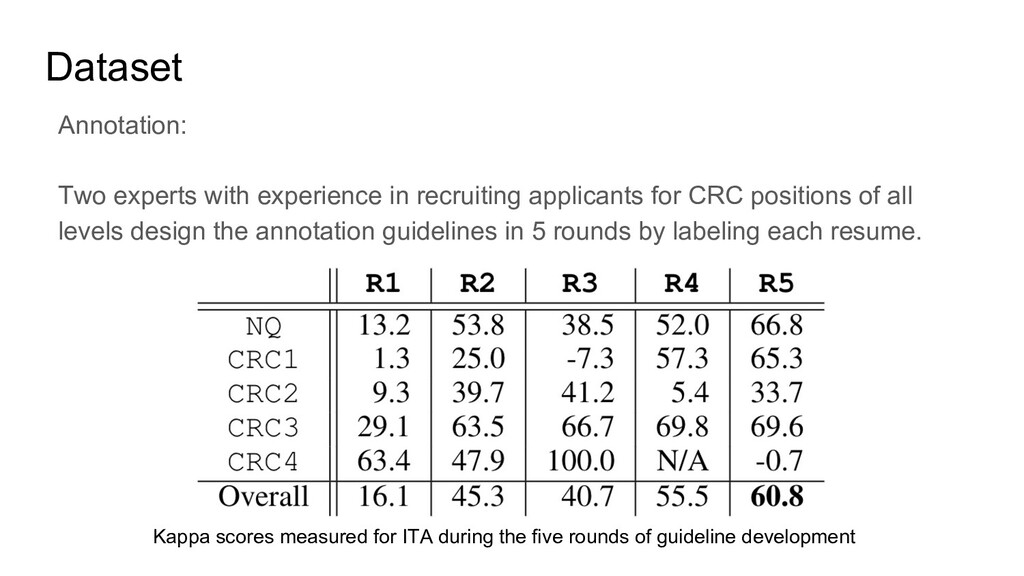
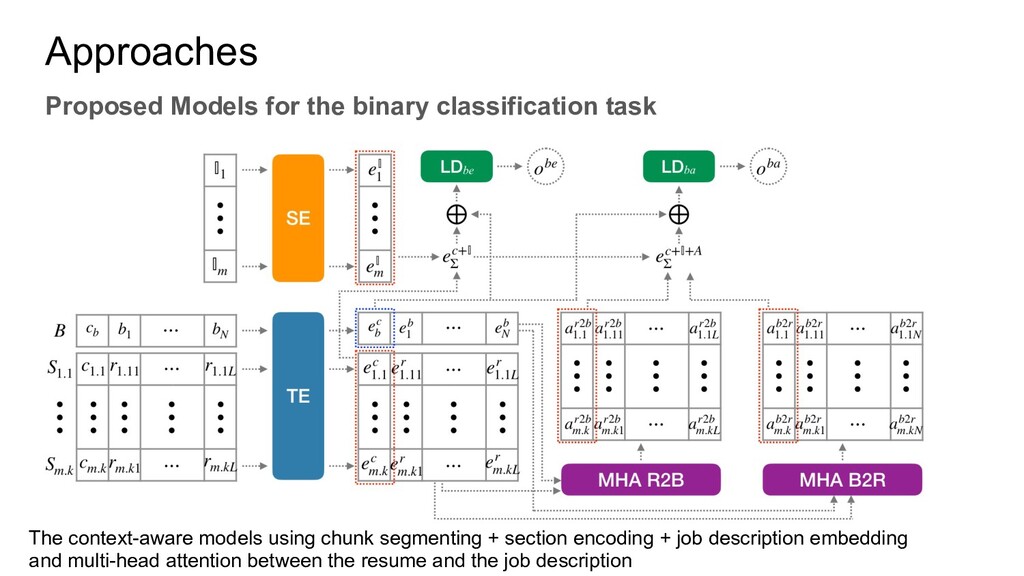
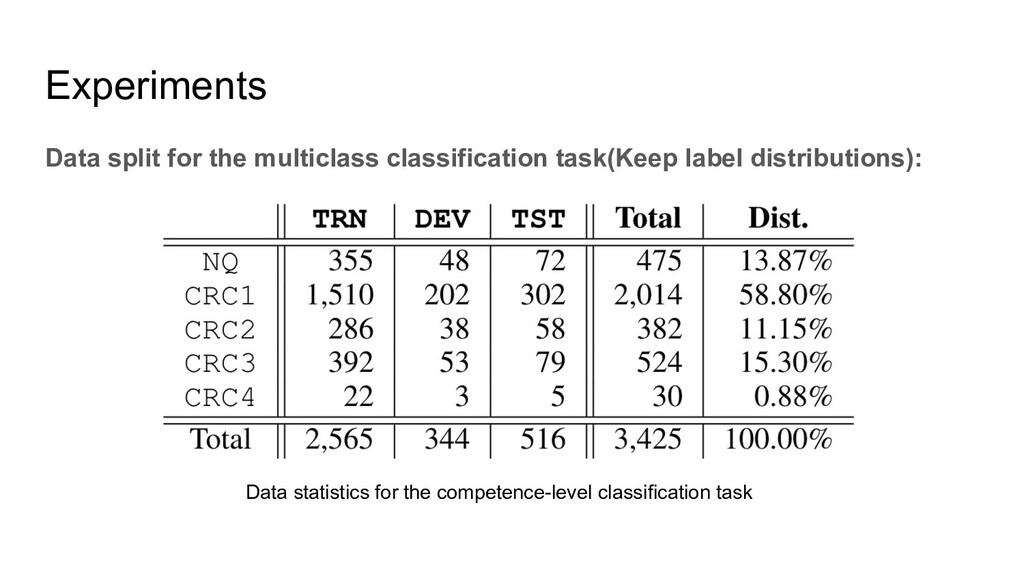
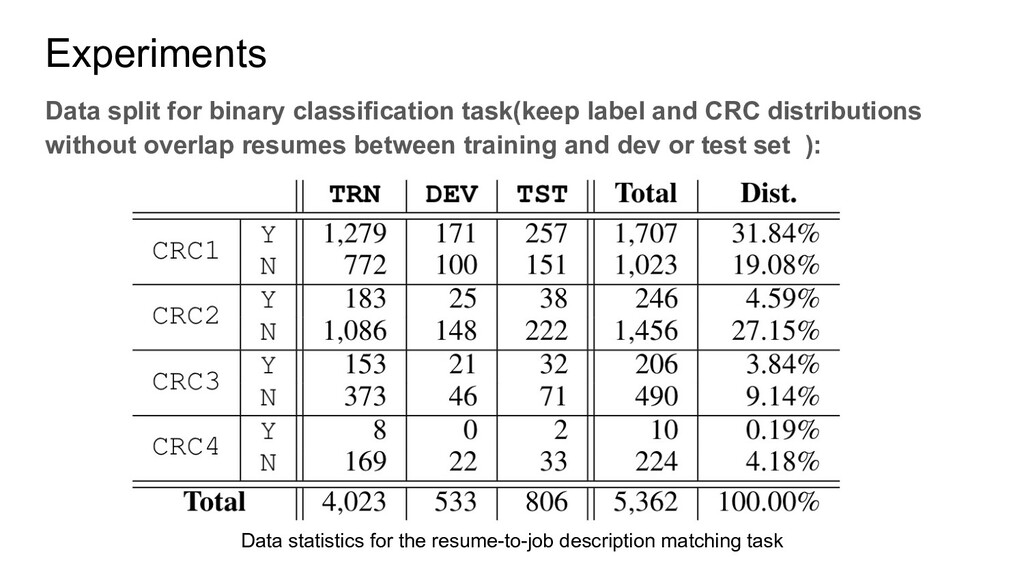
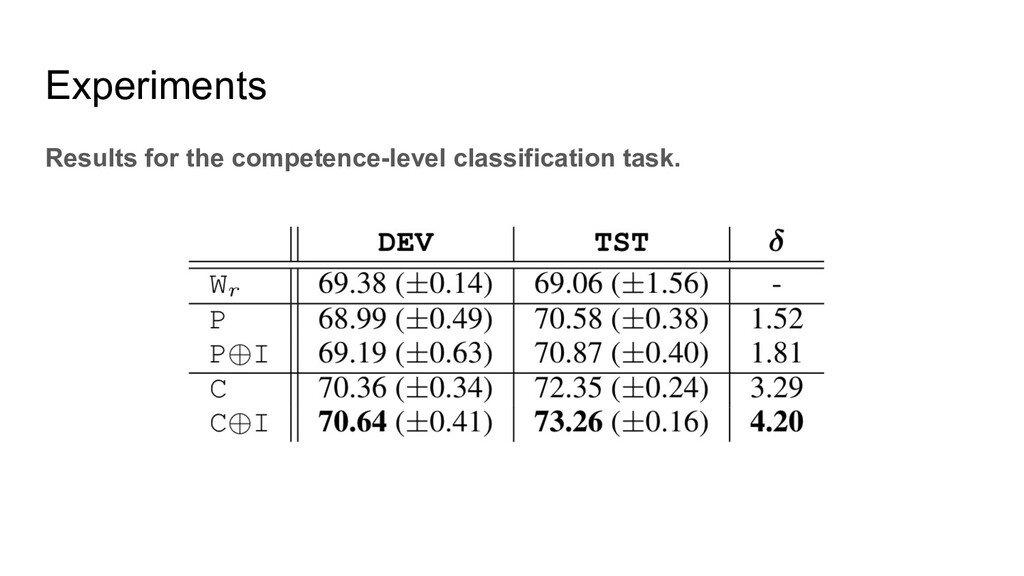
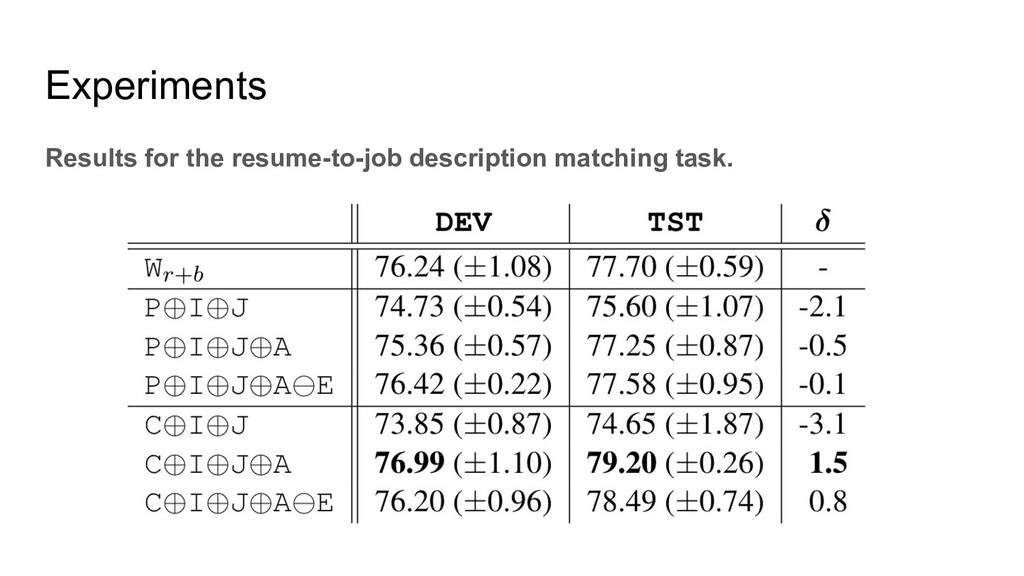
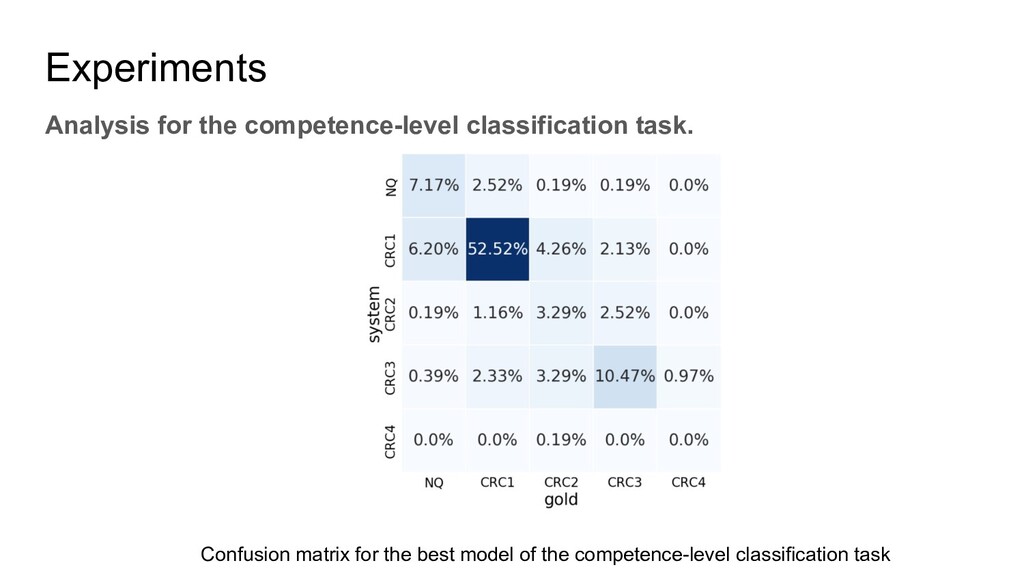
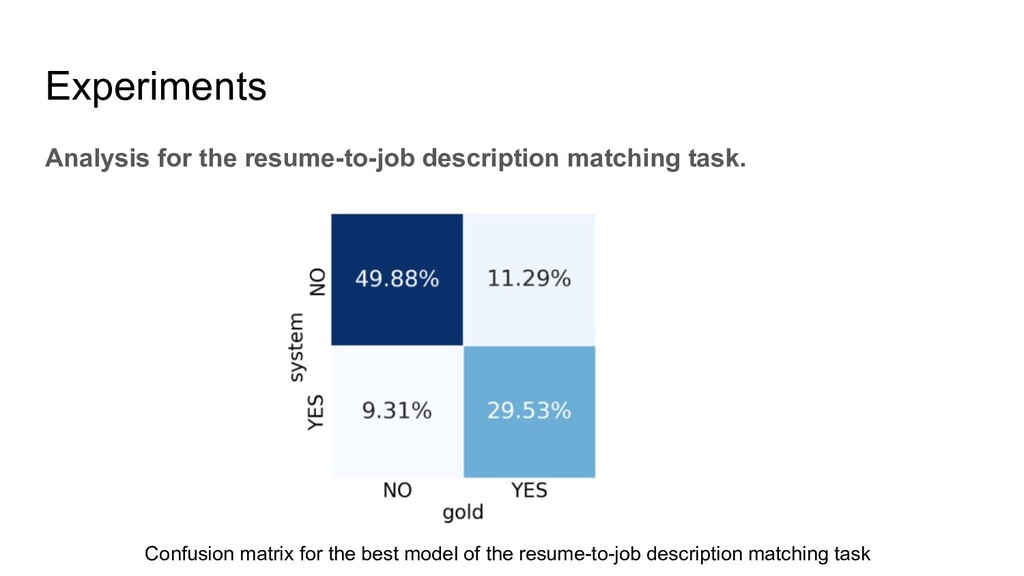
two kinds of annotations: 1. The levels they applied(an applicant can apply multiple levels). 2. The level they should be qualified. This is annotated by human experts with some annotation agreements. There are four levels, CRC1, CRC2, CRC3, CRC4. For the annotation, if the resume cannot match any level it will be annotated with Not Qualified(NQ) Besides, there is a job description for each level.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}