Leaman et al., published the first work in 2010. They crawled drug discussion forums and used a sliding window to detect positive reports. Currently state-of-the-art models rely on pretrained transformers In SMM4H 2019 shared task, Chen et al., used pretrained BERT and were ranked 1st. (F1=0.645) In SMM4H 2020 shared task, Wang et al., used pretrained RoBERTa and were ranked 1st. (F1=0.640) In SMM4H 2021 shared task, Ramesh et al., used pretrained RoBERTa and were ranked 1st. (F1=0.610) Related Studies
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
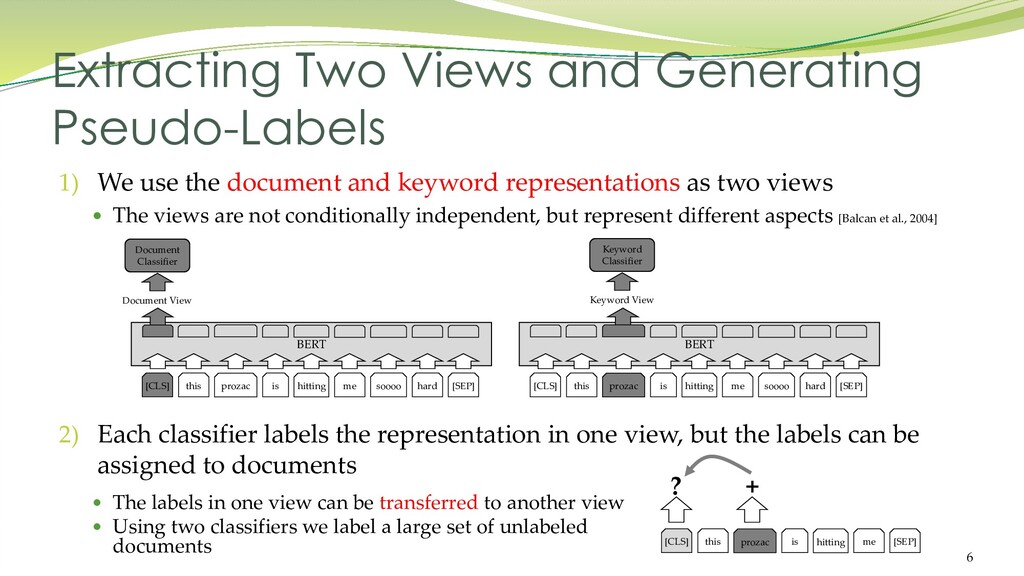{kind=link}
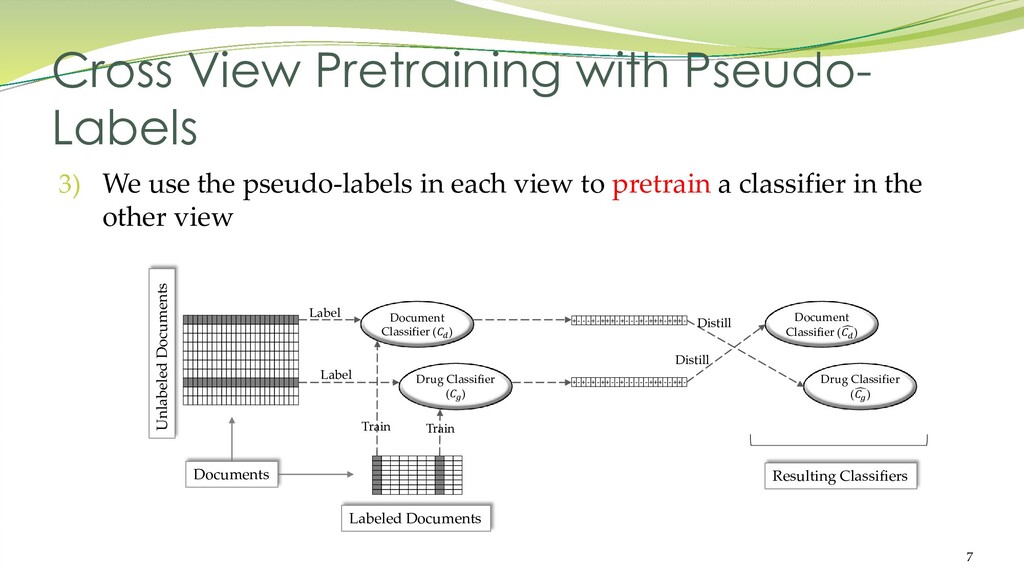{kind=link}
{kind=link}
{kind=link}
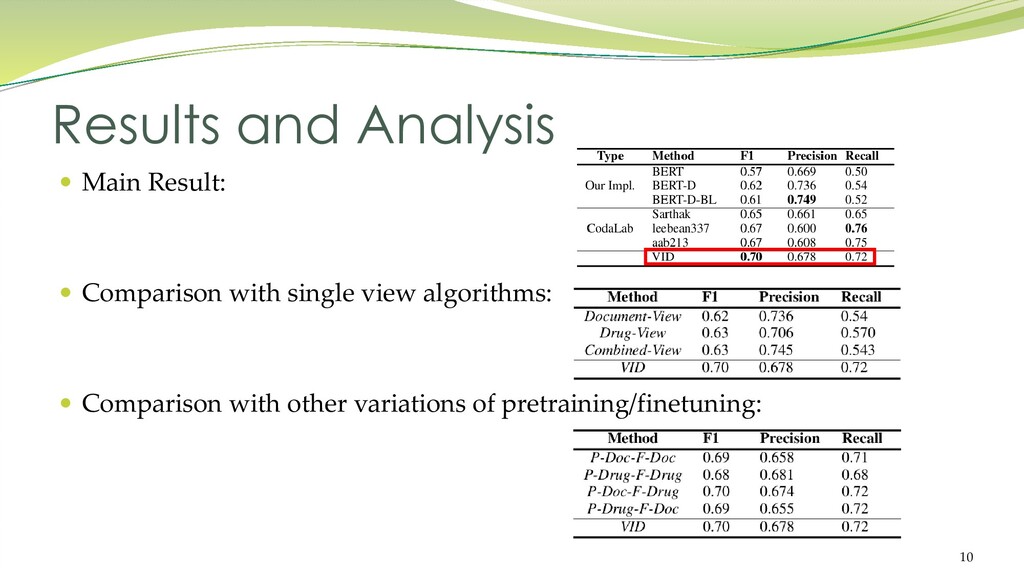{kind=link}
{kind=link}