Emir Muñoz Fujitsu (Ireland) Limited National University of Ireland Galway Joint work with A. Hogan and A. Mileo WSDM 2014 @ New York City, February 24-28
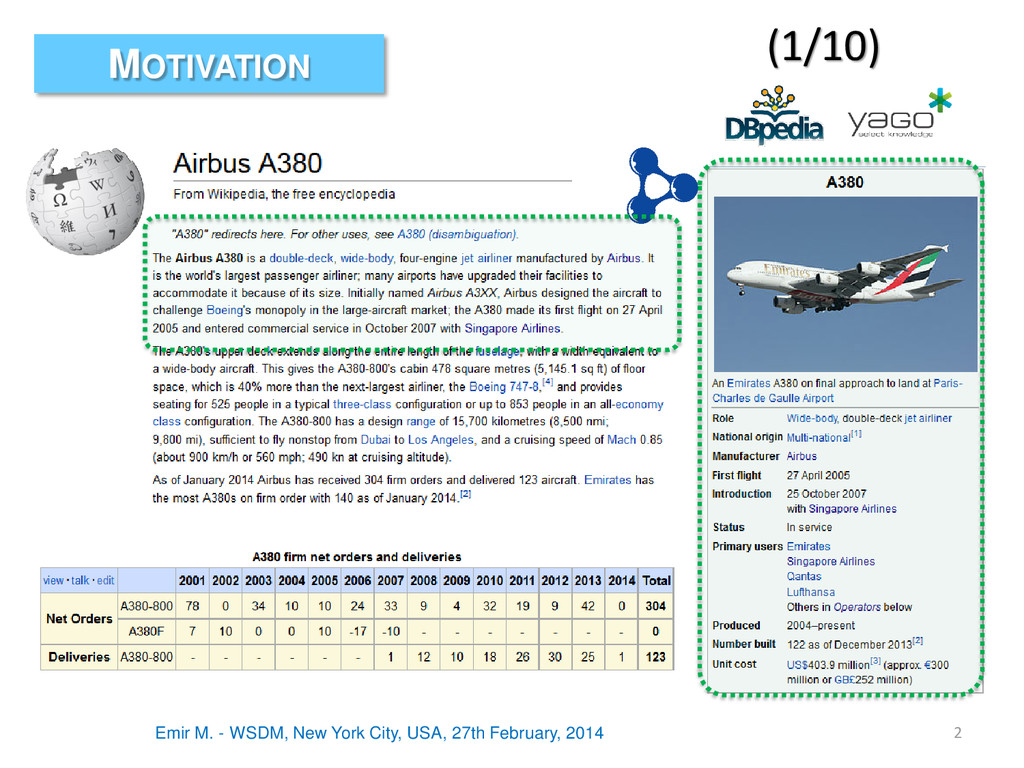
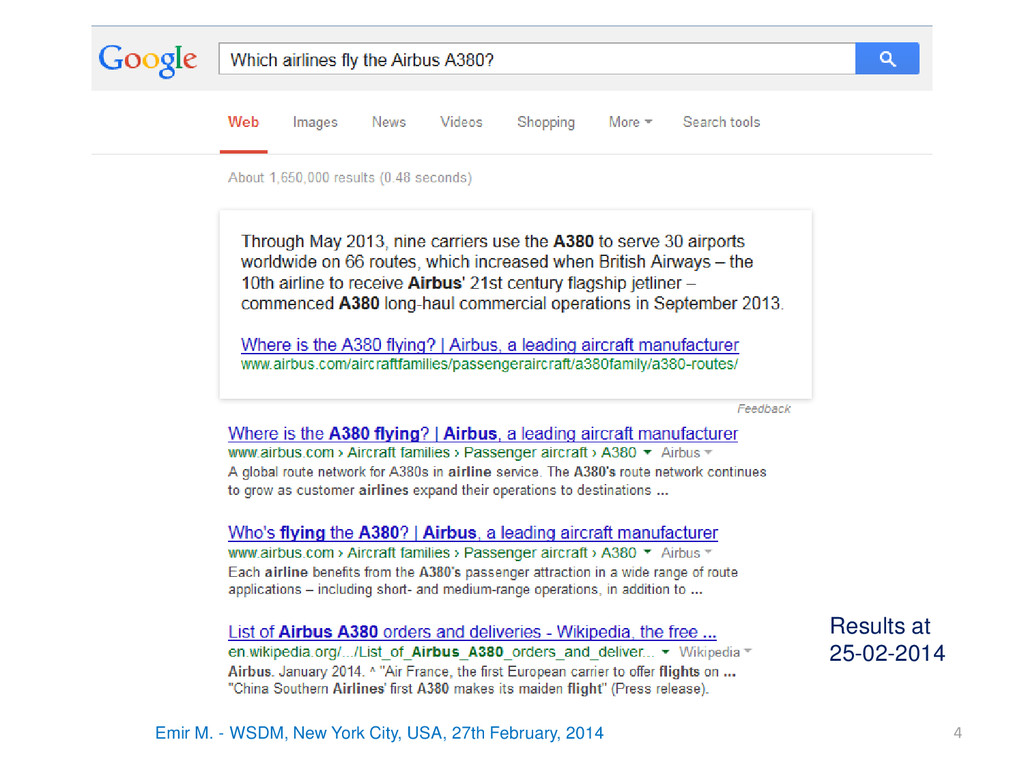
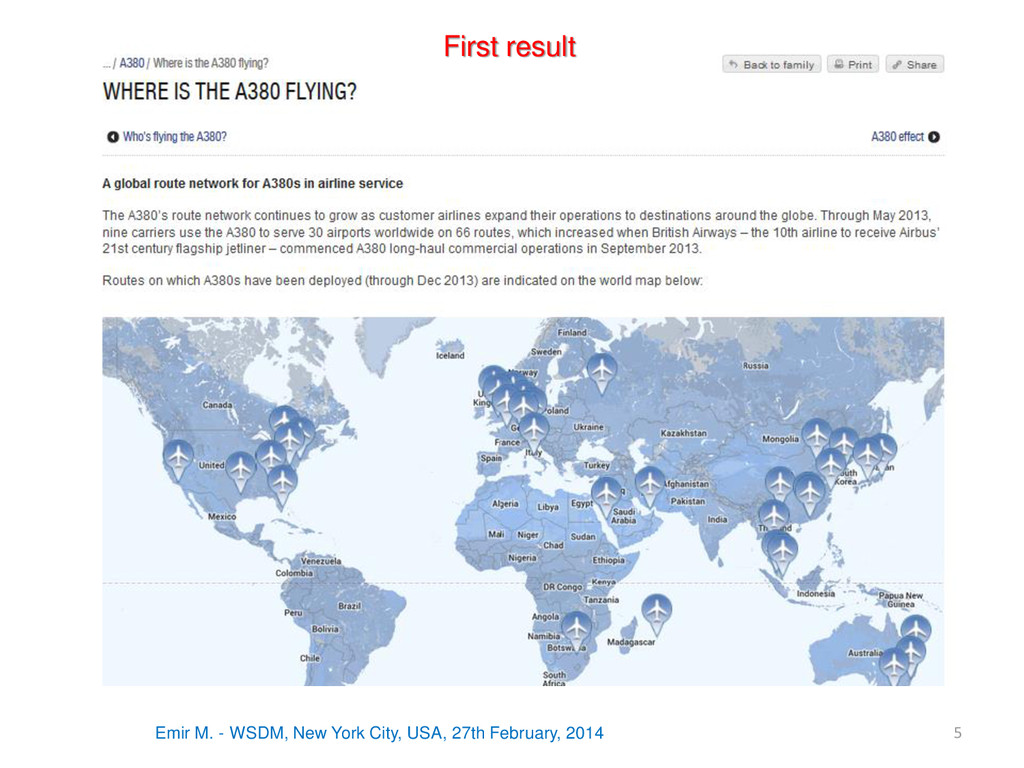
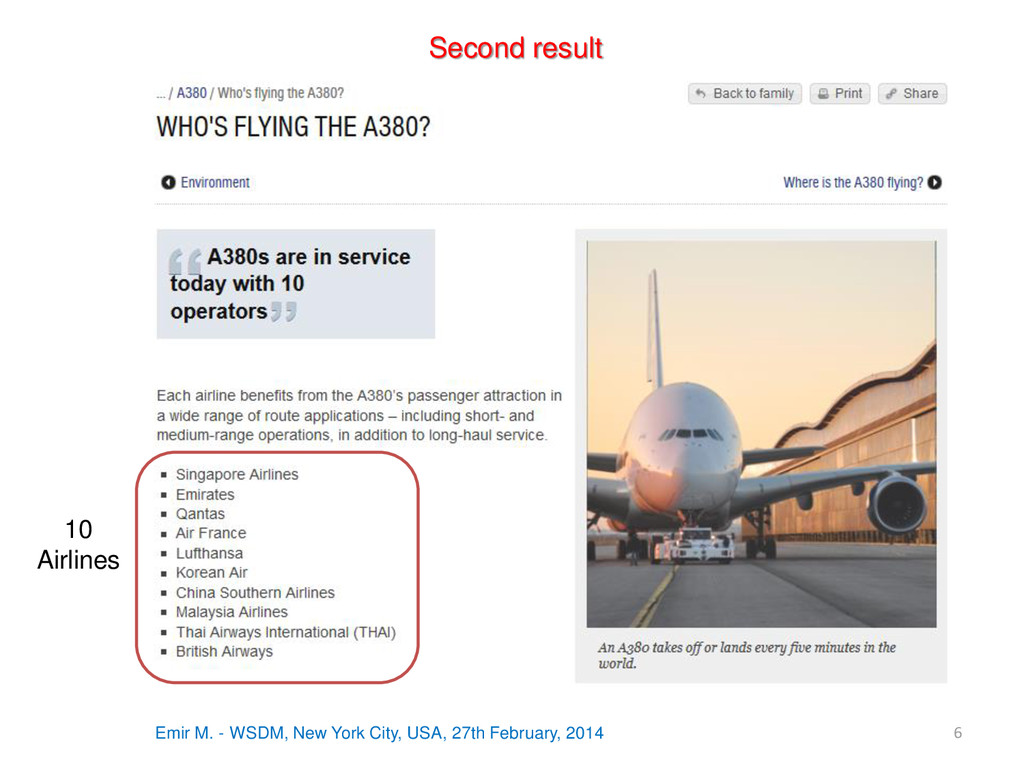
2014 3 MOTIVATION The tables embedded in Wikipedia articles contain rich, semi-structured encyclopaedic content … BUT we cannot query all that content… A query example: (2/10) Wikipedia tables or tables in the body are ignored [Borrowed from Entity Linking tutorial]
using KBs MOTIVATION Emir M. - WSDM, New York City, USA, 27th February, 2014 11 Linking Open Data cloud diagram, by Richard Cyganiak and Anja Jentzsch. http://lod-cloud.net/ (10/10)
tables in article’s body – Mainly focused on info-boxes • Languages such as R2RML can express custom mappings from relational database tables to RDF – Each row as a subject, each column as a predicate and each cell as an object – Needs a mapping definition Emir M. - WSDM, New York City, USA, 27th February, 2014 12 EXTRACTING RDF FROM TABLES (1/4)
approaches using a in-house KB and small datasets for validation – Entity recognition/disambiguation – Determine types for each column – Determine relationships between columns • We focus on Wikipedia tables, running our algorithms over the entire corpus with “row-centric” features for Machine Learning models Emir M. - WSDM, New York City, USA, 27th February, 2014 13 EXTRACTING RDF FROM TABLES (2/4)
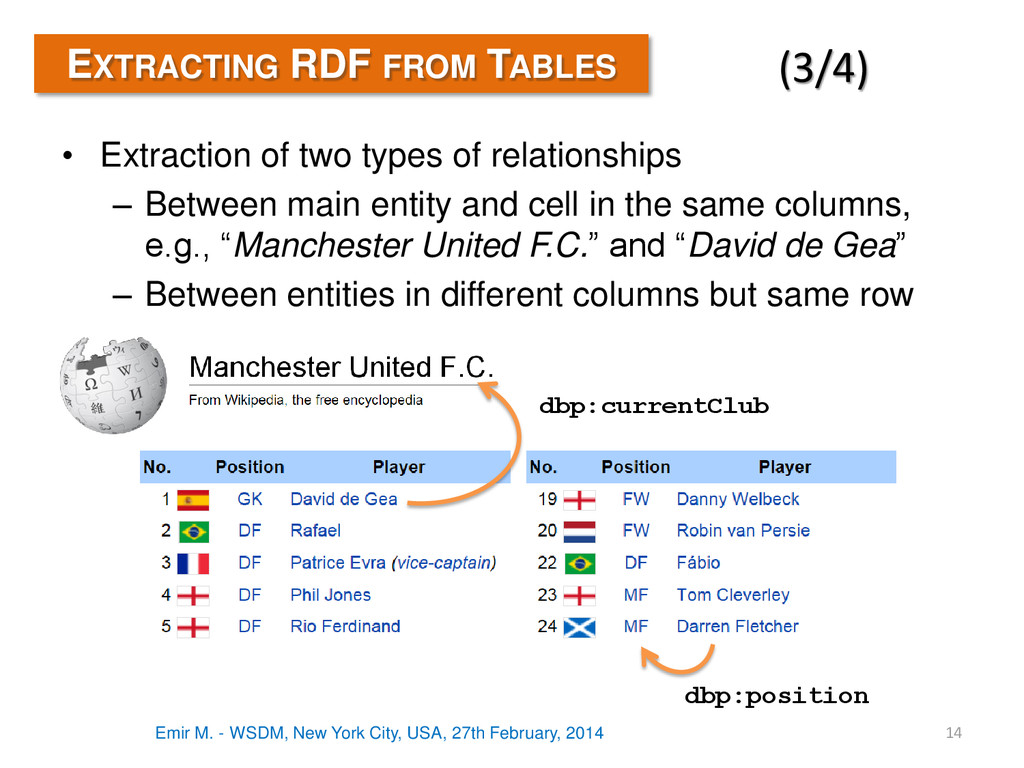
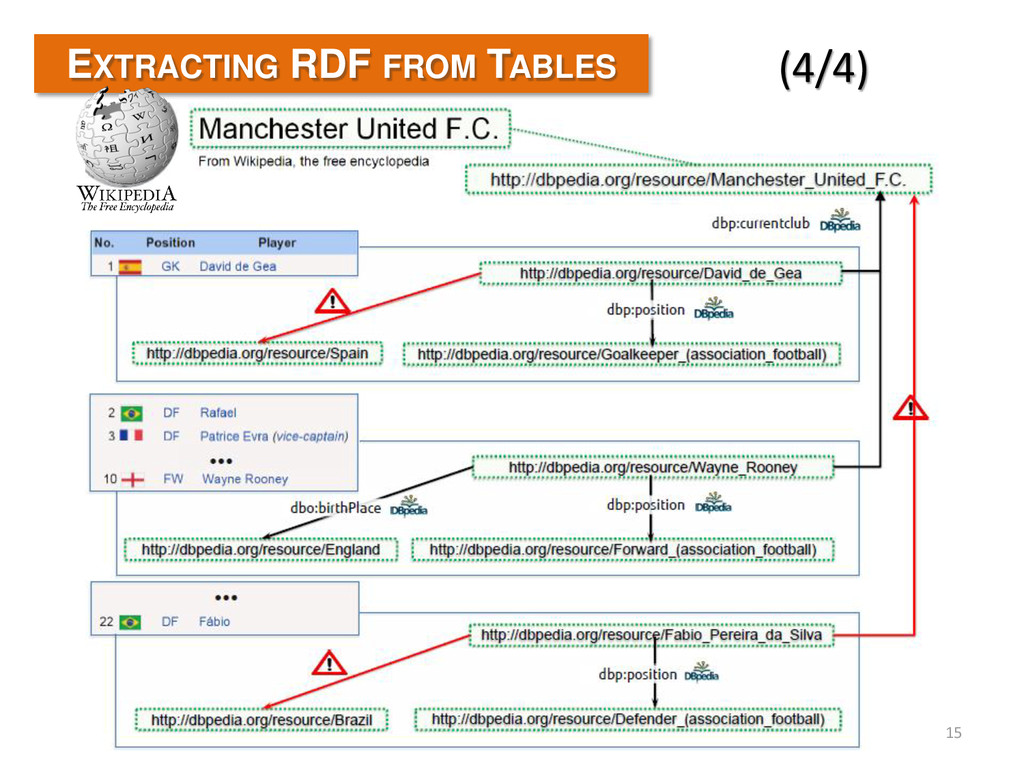
2014 14 EXTRACTING RDF FROM TABLES • Extraction of two types of relationships – Between main entity and cell in the same columns, e.g., “Manchester United F.C.” and “David de Gea” – Between entities in different columns but same row (3/4) dbp:currentClub dbp:position
set of tables) • E.g., a Wikipedia article • Each table belongs to is modeled as an matrix • We do normalize the tables and convert each HTML table into a matrix Emir M. - WSDM, New York City, USA, 27th February, 2014 17 WIKITABLES SURVEY (2/2)
reference knowledge base – Version 3.8 Emir M. - WSDM, New York City, USA, 27th February, 2014 18 MINING RDF FROM WIKITABLES Extract links in the cells Mapping links to DBpedia Lookups on DBpedia to find relationships between entities in the same row Candidate relationships Wikipedia table (1/6)
the same row – Relations between entities in the table and the protagonist of the article • Map the links inside the cells to RDF resources • Get candidate relationships from the KB Emir M. - WSDM, New York City, USA, 27th February, 2014 19 MINING RDF FROM WIKITABLES SELECT DISTINCT ?p1 ?p2 WHERE { {<e1>} ?p1 <e2> } UNION { <e2> ?p2 <e1>} } (2/6)
more filtering for relationships Emir M. - WSDM, New York City, USA, 27th February, 2014 20 MINING RDF FROM WIKITABLES dbp:currentClub dbp:youthClubs (3/6)
models • Article features (e.g., # of tables) • Table features (e.g., #rows, #columns, ratios) • Cell features (e.g., # of entities, string length, has format) • Column features (e.g., # of entities, # of unique entities) • Predicate/Column features (e.g., string similarity, # of rows where relation holds) • Predicate features (e.g., triple count, count unique) • Triple features (e.g., is the table from article or body) Emir M. - WSDM, New York City, USA, 27th February, 2014 21 MINING RDF FROM WIKITABLES (4/6)
– DBpedia dump version 3.8 – 8 machines (ca. 2005) with 4GB of RAM, 2.2GHz single-core processors • After 12 days we got 34.9 million unique triples not in DBpedia • We manually annotated a sample of 750 triples to train the ML models Emir M. - WSDM, New York City, USA, 27th February, 2014 22 MINING RDF FROM WIKITABLES (5/6)
semantic of tables using KB’s – Enrich KB’s with new facts mined from tables • With the best model we got 7.9 million unique novel triples • We still don’t – consider literals/string values in the cells – Explode domain/range of predicates – Test other KBs like Freebase and YAGO Emir M. - WSDM, New York City, USA, 27th February, 2014 24 CONCLUSION
such as DBpedia – They can be benefited by new RDF triples extracted from Wikipedia tables • We can use the similarity proposed in Knowledge-based graph document modeling, by Schuhmacher and Ponzetto, to improve the relation extraction • And use the paper Trust, but Verify: Predicting Contribution Quality for Knowledge Base Construction and Curation, Chun How et al, to determine the correctness of the quality of the output triples Emir M. - WSDM, New York City, USA, 27th February, 2014 CONTRAST WITH OTHER PAPERS 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• [Limaye et al. 2010; Mulwad et al. 2010&2013] presented](https://files.speakerdeck.com/presentations/99f8d8e0822a0131d97b1ae9d79fbfac/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}