Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第0回ディープラーニング勉強会
Search
EngineerCafe
February 05, 2022
Technology
100
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第0回ディープラーニング勉強会
EngineerCafe
February 05, 2022
More Decks by EngineerCafe
See All by EngineerCafe
台湾デジタルフェス2026参加報告
engineercafe
0
12
Hacktivation2025_イントロダクション_ブロックチェーンことはじめ
engineercafe
0
290
エンジニアカフェ台湾ツアー2025
engineercafe
0
140
台湾視察報告レポート_2024
engineercafe
1
170
インド・バンガロール視察報告会
engineercafe
0
160
イベントレポート_Hacktivation 続:生成AI時代におけるブロックチェーンの可能性
engineercafe
0
140
Docker はじめの一歩 #1 Dockerコンテナを動かしてみよう
engineercafe
0
110
git勉強会 (基本的なコマンドを覚えよう)
engineercafe
0
190
エンジニアのための論文ゆる輪読会 #1【 #ゆるりん 】
engineercafe
0
200
Other Decks in Technology
See All in Technology
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
150
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
320
AICoEでAIネイティブ組織への進化
yukiogawa
0
170
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
3
1.7k
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
130
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.2k
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
300
依頼文化をやめる日 EM視点で語るPlatform EngineeringとInclusive SRE / Discussing Platform Engineering and Inclusive SRE from an EM's Perspective
shin1988
4
5.5k
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
680
知らん間に、回ってる
ming_ayami
0
590
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
580
Featured
See All Featured
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
190
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Everyday Curiosity
cassininazir
0
250
Designing Experiences People Love
moore
143
24k
Between Models and Reality
mayunak
4
370
We Have a Design System, Now What?
morganepeng
55
8.2k
Amusing Abliteration
ianozsvald
1
220
RailsConf 2023
tenderlove
30
1.5k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
890
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Transcript
〜画像処理編〜
§ 自己紹介 § 本の紹介 § 1.1機械学習と深層学習 § 1.2ニューラルネットワークの学習 § 1.3畳み込みニューラルネットワーク(CNN)
§ 1.4タスクとモデル ※1.4は内容が約16ページと膨大だったので説明はざっくりしてます。詳しい説明は次 回以降やりたいと思います。 1
§ 岩永拓也 § 九州工業大学 情報工学部 4年 § 藤原研究室 アルゴリズム §
趣味:ゲーム、読書、ボードゲーム、アマプラで映画 § エディタ:Atom 2
§ 即戦力になるための ディープラーニング開発実践ハンズオン § [著]井上大樹、佐藤峻 § 価格:3280円(税抜) § リンク: https://gihyo.jp/book/2021/978-4-297-11942-3
3
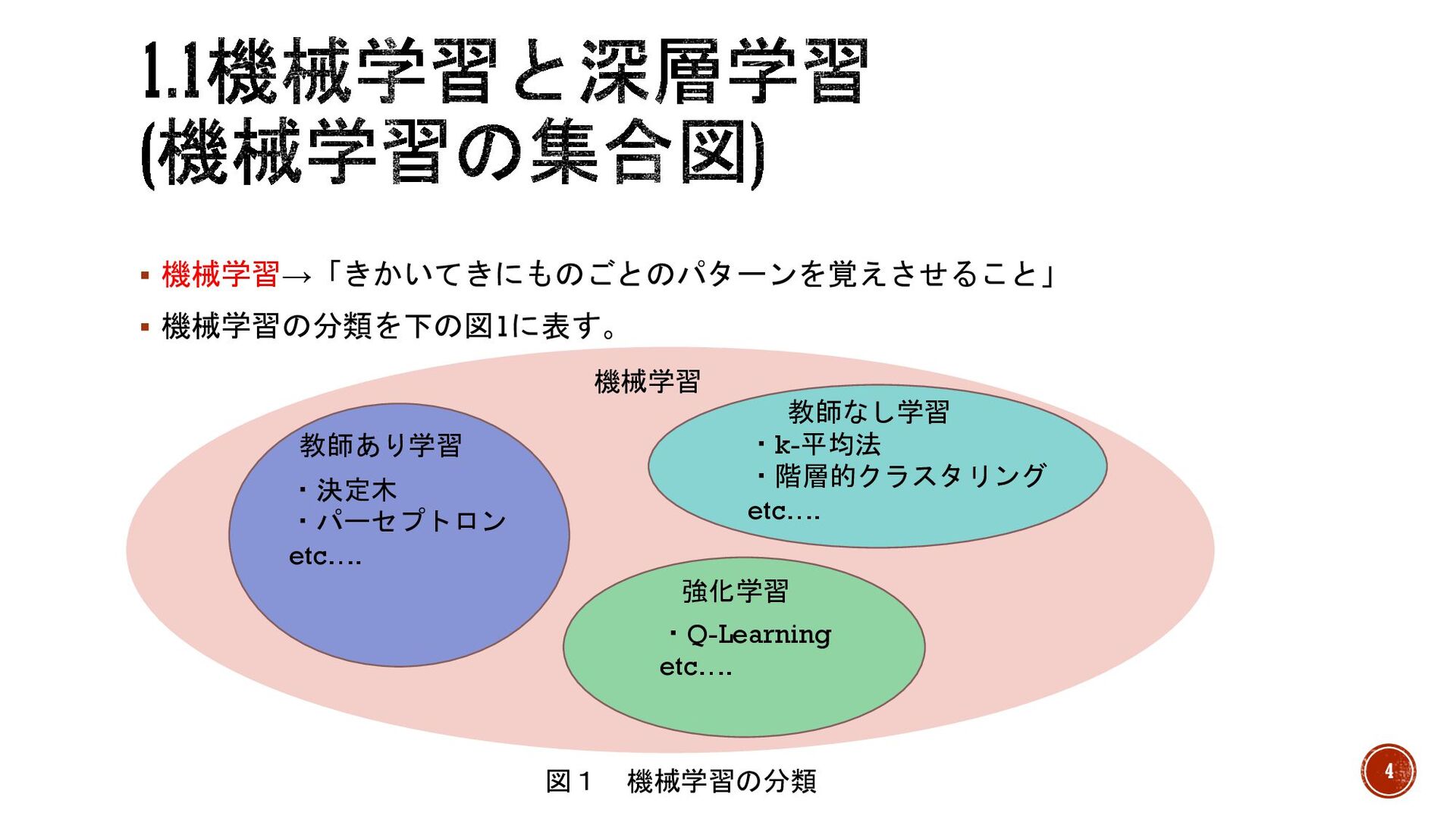
§ 機械学習→「きかいてきにものごとのパターンを覚えさせること」 § 機械学習の分類を下の図1に表す。 機械学習 教師あり学習 教師なし学習 強化学習 ・決定木 ・パーセプトロン
etc…. ・Q-Learning etc…. ・k-平均法 ・階層的クラスタリング etc…. 図1 機械学習の分類 4
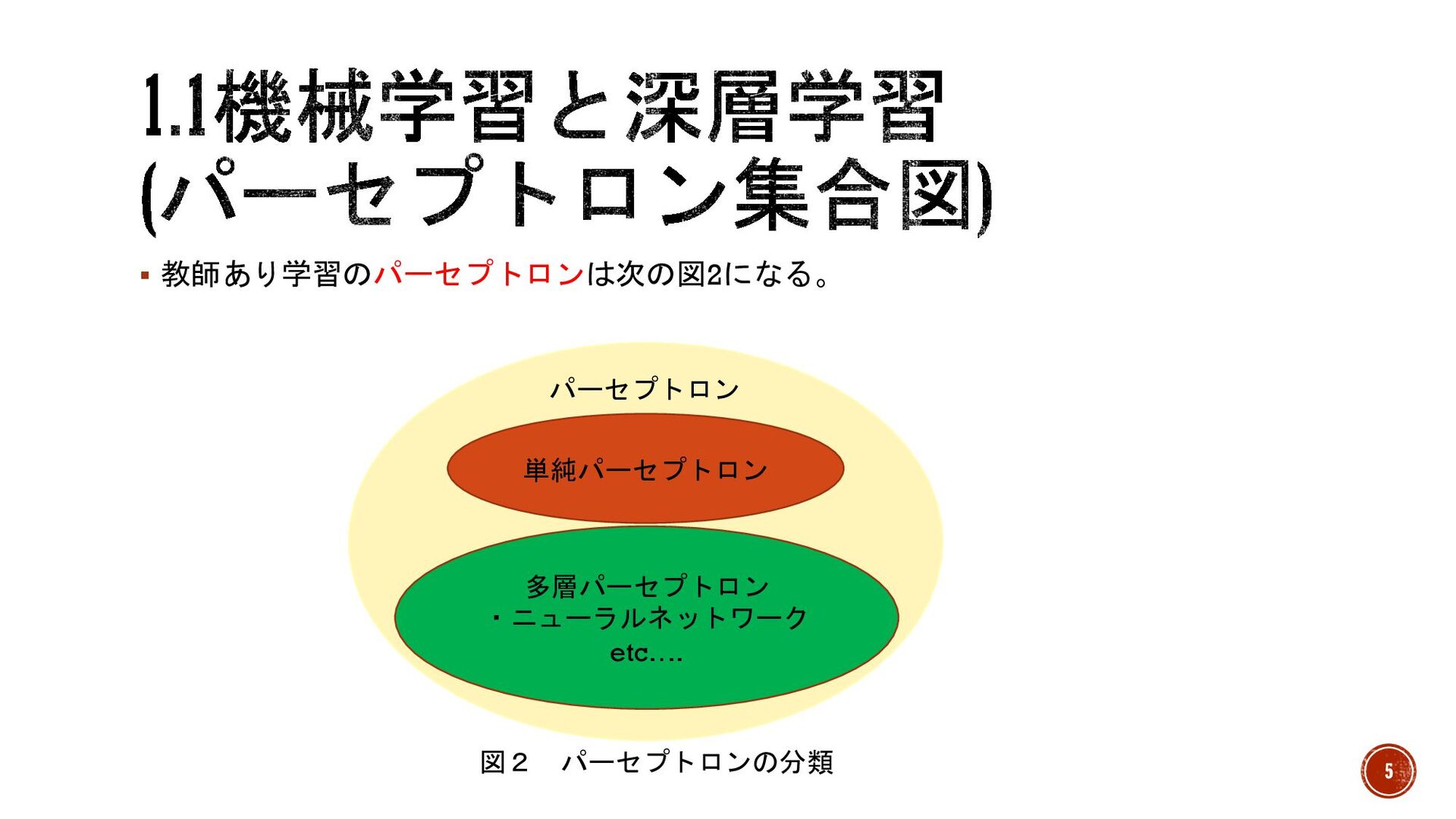
§ 教師あり学習のパーセプトロンは次の図2になる。 パーセプトロン 単純パーセプトロン 多層パーセプトロン ・ニューラルネットワーク etc…. 図2 パーセプトロンの分類 5
§ 図1より機械学習には様々な手法があり、主に「教師あり」「教師なし」「強化学習」に 分かれる。 § 教師あり学習 →正解データ(教師データ)を与えて学習。主に分類や回帰の問題に使用。有名な手法は決定 木、パーセプトロン、サポートベクターマシンなどがある。 § 教師なし学習 →教師データを与えず学習。主にクラスタリングで使用。有名な手法はk-平均法などかあ
る。 § 強化学習 →環境を観測し、その中での最適化を学んでいき、環境に合わせて進化していくもの。有 名な手法はQ-Learningなどがある。 6
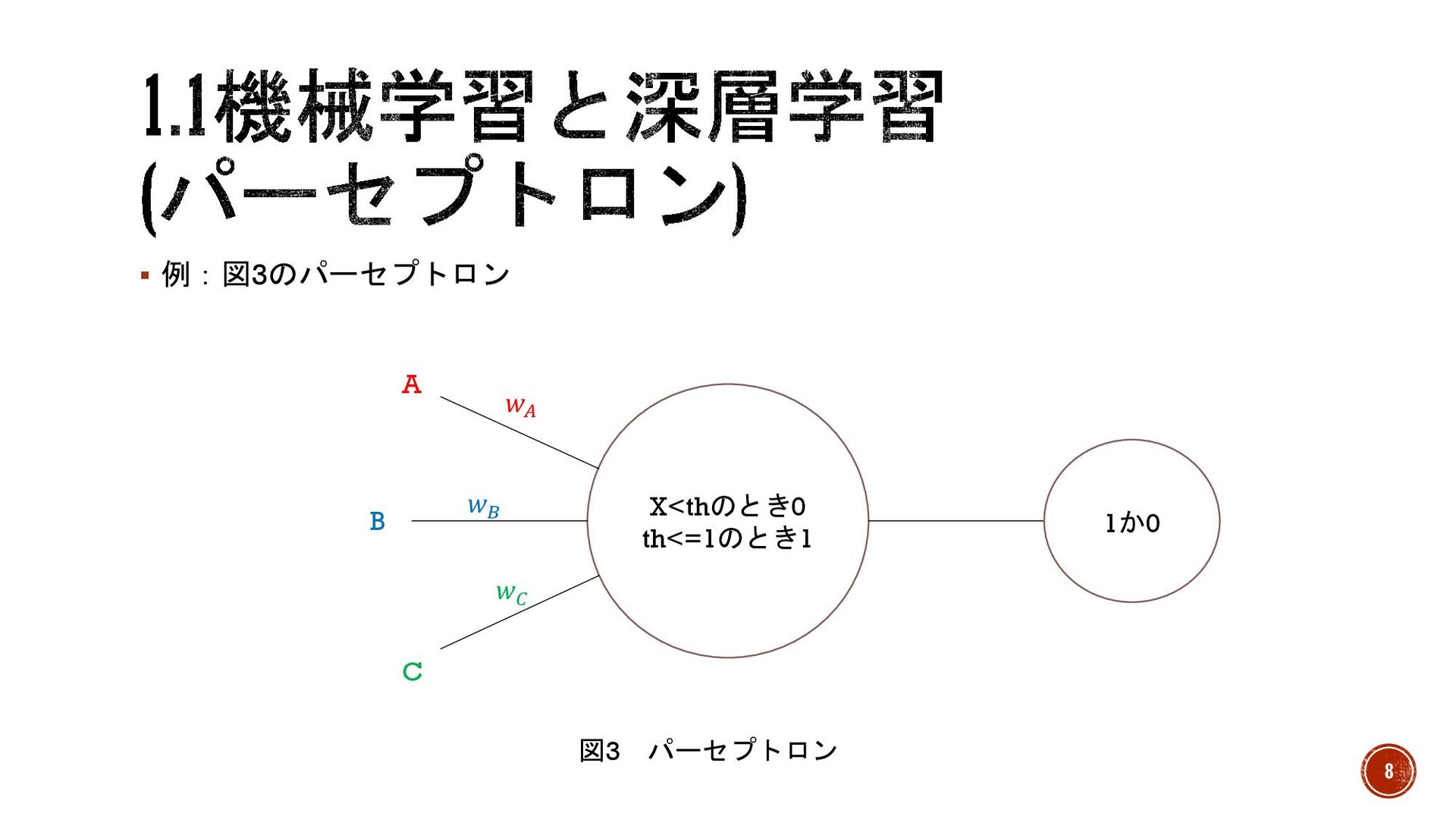
§ 深層学習(ディープラーニング) →手法はパーセプトロン系統の進化であるディープニューラルネットワークをしたも の。教師ありに分類。 § パーセプトロン →視覚と脳の機能を数式化したもの。外部からの刺激を入力とし、その合計が一定の 値(閾値)を上回ったら反応(活性化)する。 7
X<thのとき0 th<=1のとき1 1か0 A B C 𝑤! 𝑤" 𝑤# 図3
パーセプトロン § 例:図3のパーセプトロン 8
図にある文字の説明 § A,B,C →外からの刺激(入力)。 § X →入力を合計した値。 § 𝑤! ,
𝑤" , 𝑤# →重み(weight)。入力は全て重要度が平等ではないため、それぞれの入力を足し合わせるときに重要度合いである重みを掛 け算して調整。 図3の場合:X= 𝐴𝑤! + 𝐵𝑤" + 𝐶𝑤# となる。 § th →閾値(しきいち)。これを超えた場合活性化が起こり1を返す。超えなかった場合は0を返す。 9
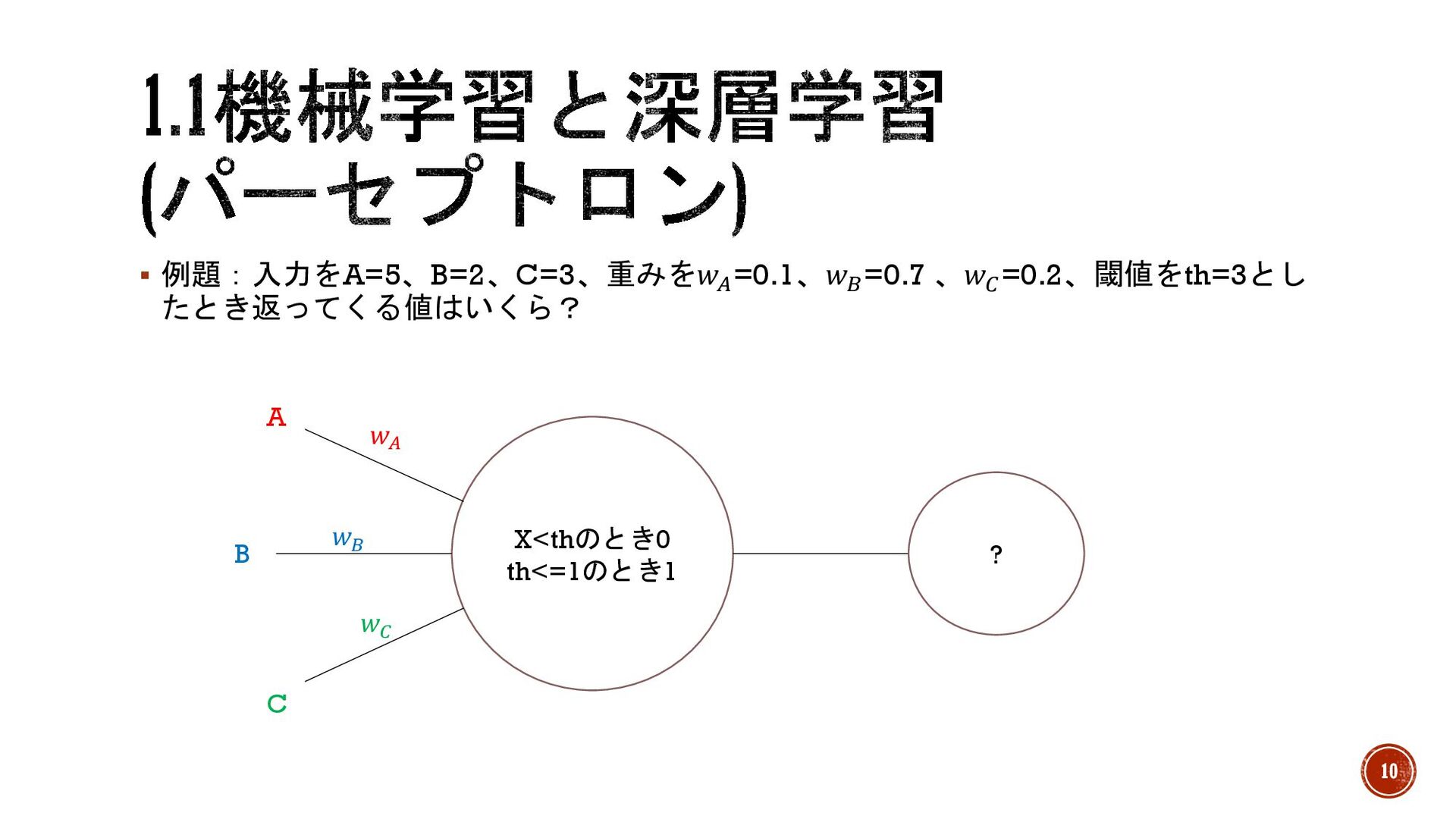
§ 例題:入力をA=5、B=2、C=3、重みを𝑤! =0.1、𝑤" =0.7 、𝑤# =0.2、閾値をth=3とし たとき返ってくる値はいくら? X<thのとき0 th<=1のとき1 ?
A B C 𝑤! 𝑤" 𝑤# 10
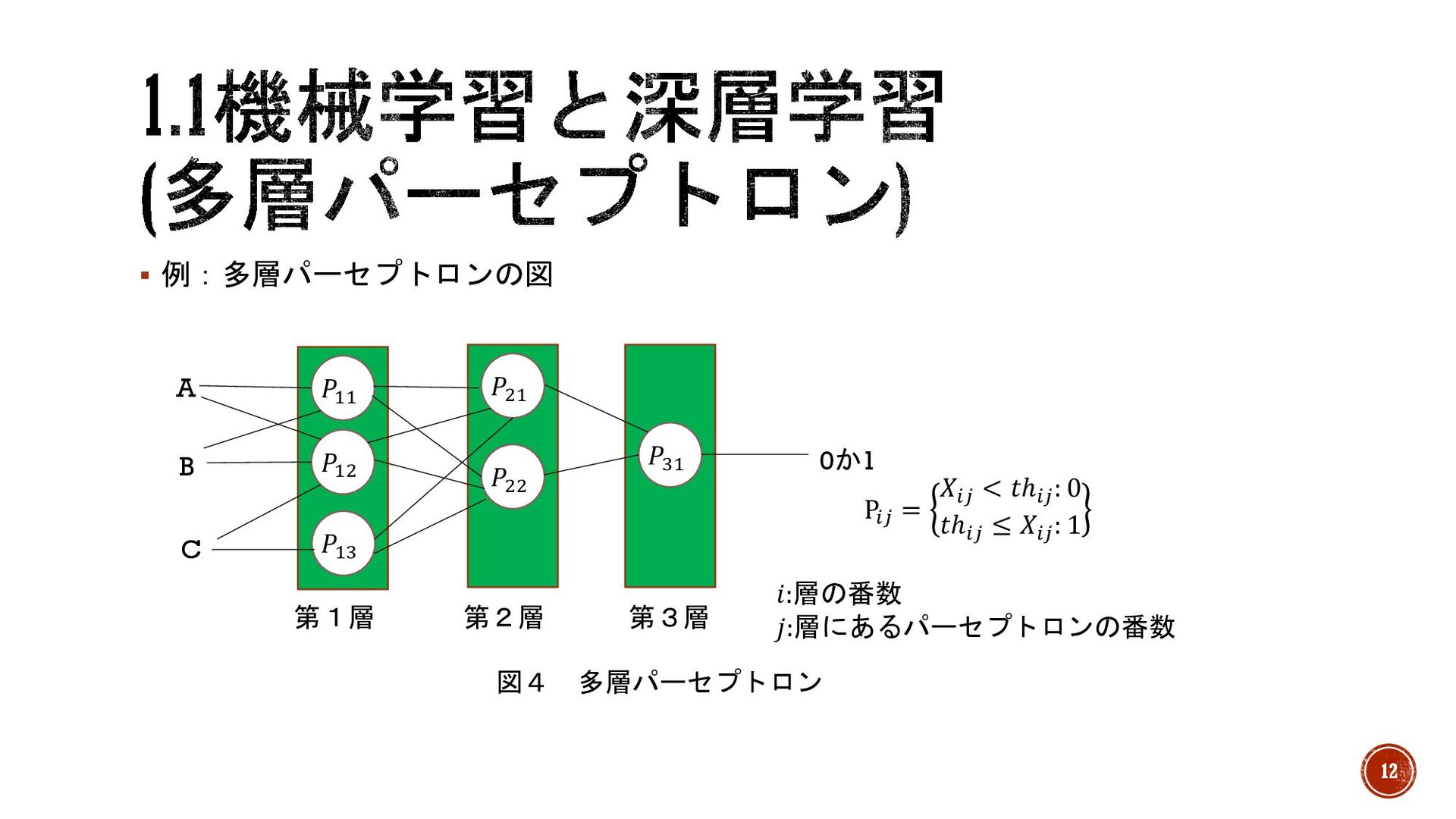
§ 多層パーセプトロン →1つのパーセプトロンを複数繋げる方法。図4のようにいくつかのパーセプトロン が外からの刺激(入力)を受け取り、反応(活性化)を行い、その結果を次の層にが受け取 り、反応するを繰り返していきます。 § 層 →縦に並んだパーセプトロンの1つのまとまり。 11
§ 例:多層パーセプトロンの図 図4 多層パーセプトロン 𝑃$% 𝑃&& 𝑃&% 𝑃%$ 𝑃%& 𝑃%%
A B C 0か1 P'( = 𝑋'( < 𝑡ℎ'( : 0 𝑡ℎ'( ≤ 𝑋'( : 1 𝑖:層の番数 𝑗:層にあるパーセプトロンの番数 第1層 第2層 第3層 12
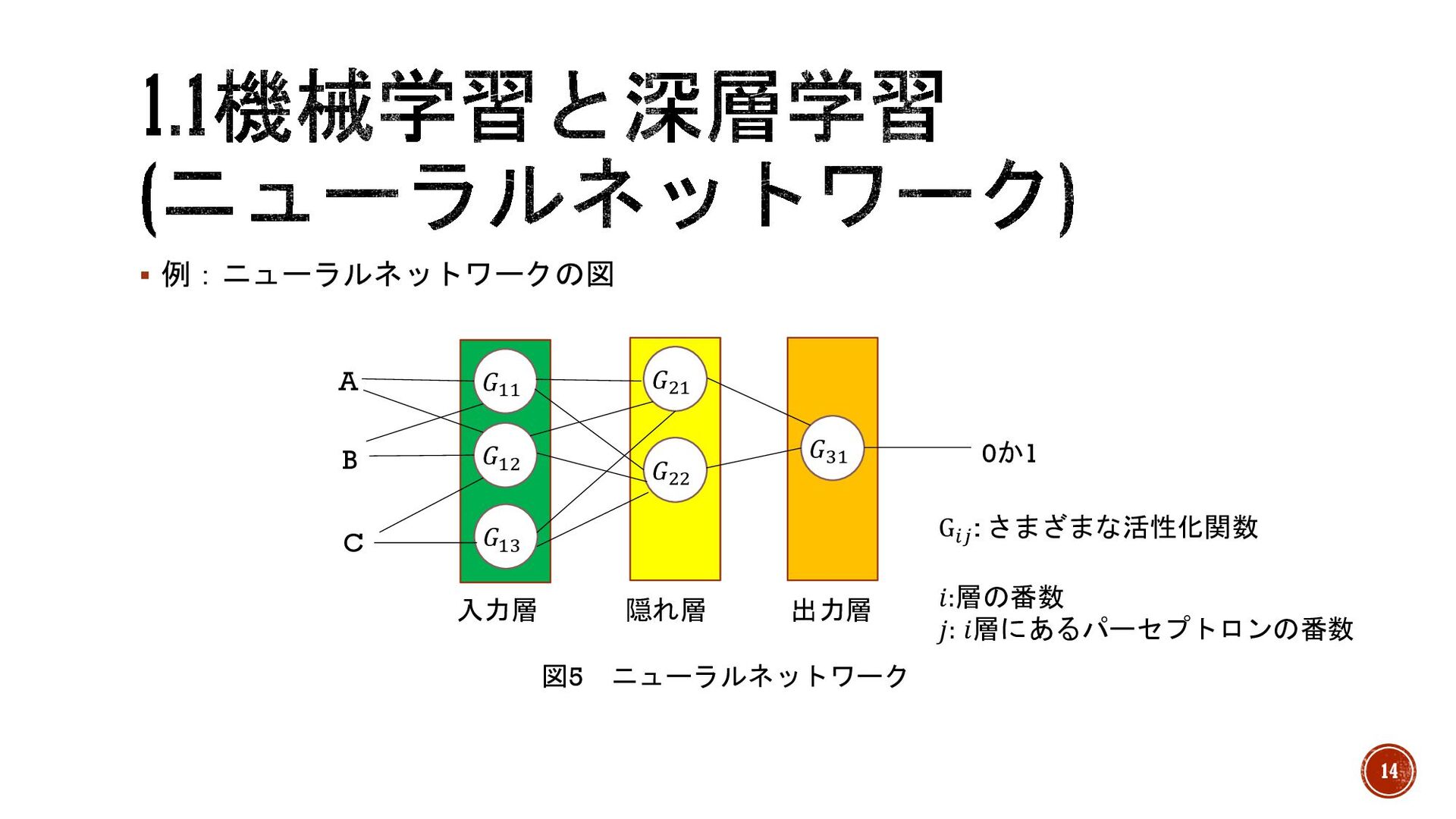
§ ニューラルネットワーク →反応として活性化、活性化していないという極端な2択でなく、出力する値の度合いで 測れるようにしたもの。 § 活性化関数 →0,1で出力していたところを0~1,-1~1などの一定の範囲の値で出力するように制御する関 数。 § 入力層
→ニューラルネットワークで外から刺激(入力)を受ける。 § 出力層 →最後に反応(活性化)を行う層。 § 隠れ層(中間層) →入力層と出力層の間で隠れている層。 13
§ 例:ニューラルネットワークの図 図5 ニューラルネットワーク 𝐺$% 𝐺&& 𝐺&% 𝐺%$ 𝐺%& 𝐺%%
A B C 0か1 入力層 隠れ層 出力層 G'( : さまざまな活性化関数 𝑖:層の番数 𝑗: 𝑖層にあるパーセプトロンの番数 14
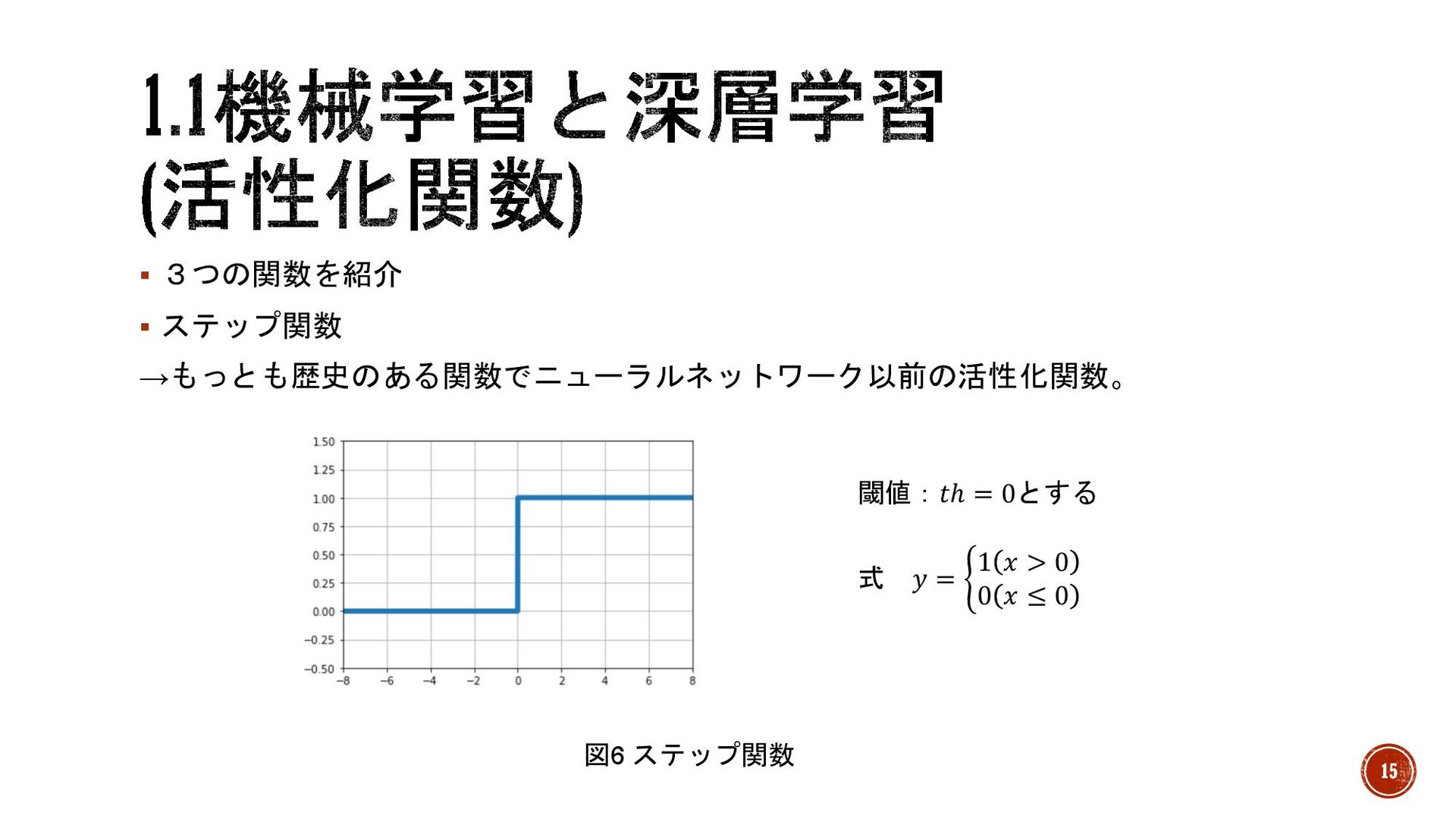
§ 3つの関数を紹介 § ステップ関数 →もっとも歴史のある関数でニューラルネットワーク以前の活性化関数。 図6 ステップ関数 閾値:𝑡ℎ = 0とする
式 𝑦 = 2 1 𝑥 > 0 0 𝑥 ≤ 0 15
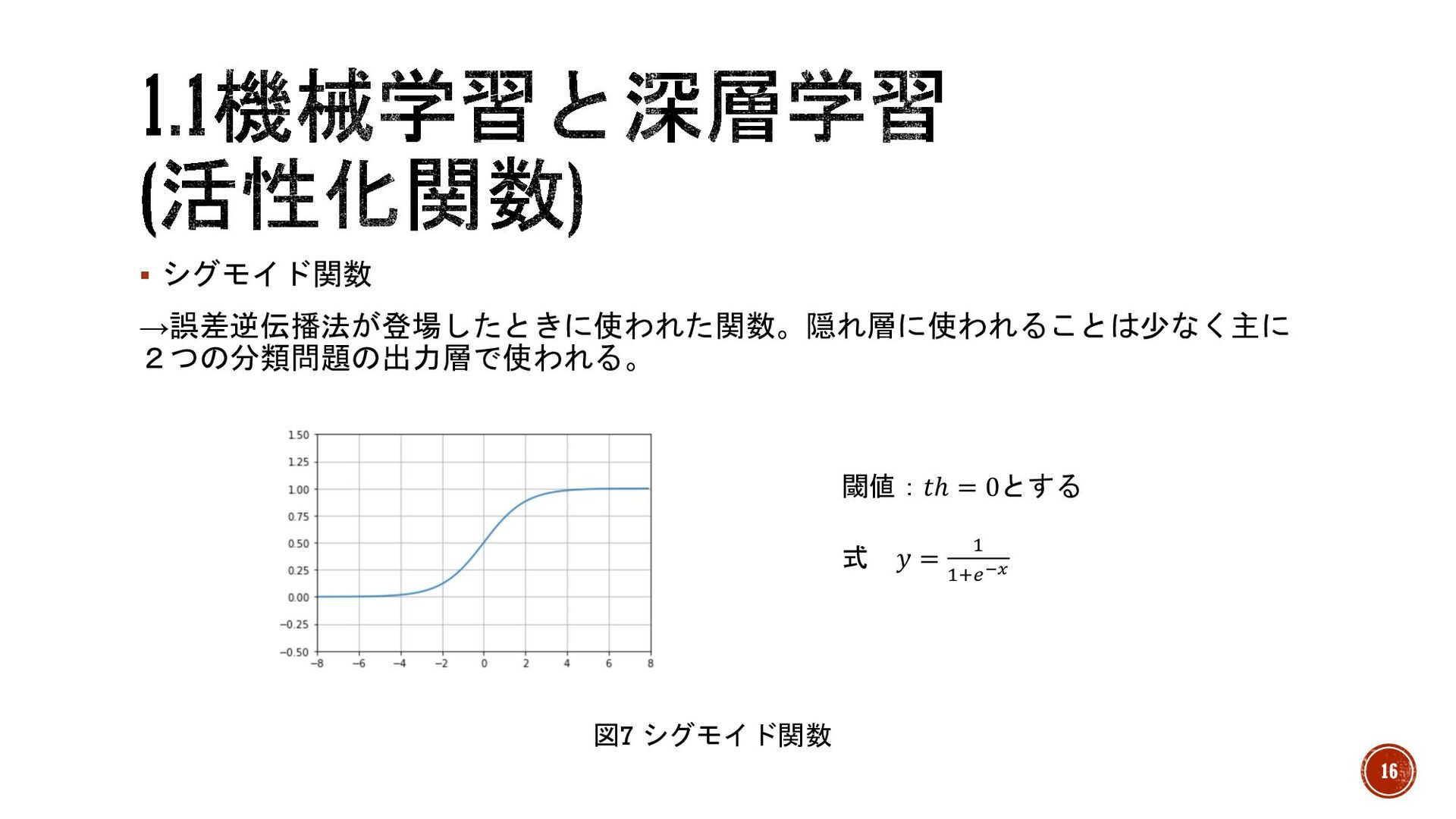
§ シグモイド関数 →誤差逆伝播法が登場したときに使われた関数。隠れ層に使われることは少なく主に 2つの分類問題の出力層で使われる。 図7 シグモイド関数 閾値:𝑡ℎ = 0とする 式
𝑦 = % %)*!" 16
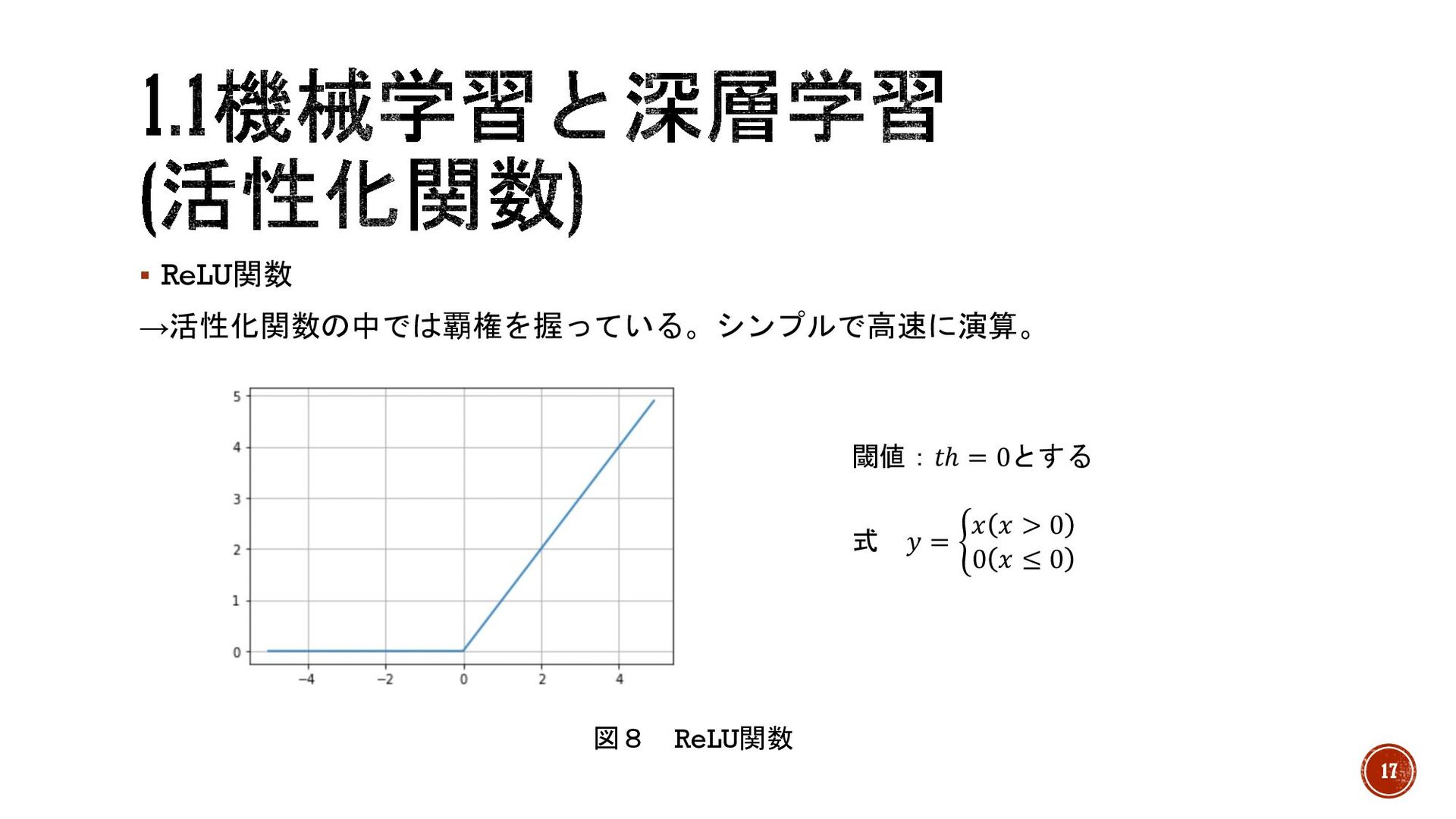
§ ReLU関数 →活性化関数の中では覇権を握っている。シンプルで高速に演算。 図8 ReLU関数 閾値:𝑡ℎ = 0とする 式 𝑦
= 2 𝑥 𝑥 > 0 0 𝑥 ≤ 0 17
§ ディープニューラルネットワーク →ニューラルネットワークの活性化関数の変更で表現が上がり、より複雑な反応がで きるように進化したもの。隠れ層が多く、3層以上あります。一般的にはニューラル ネットワークとの区別が明確でないためニューラルネットワークと呼んでいる。 § ディープラーニング →ディープニューラルネットワークを学習すること。 18
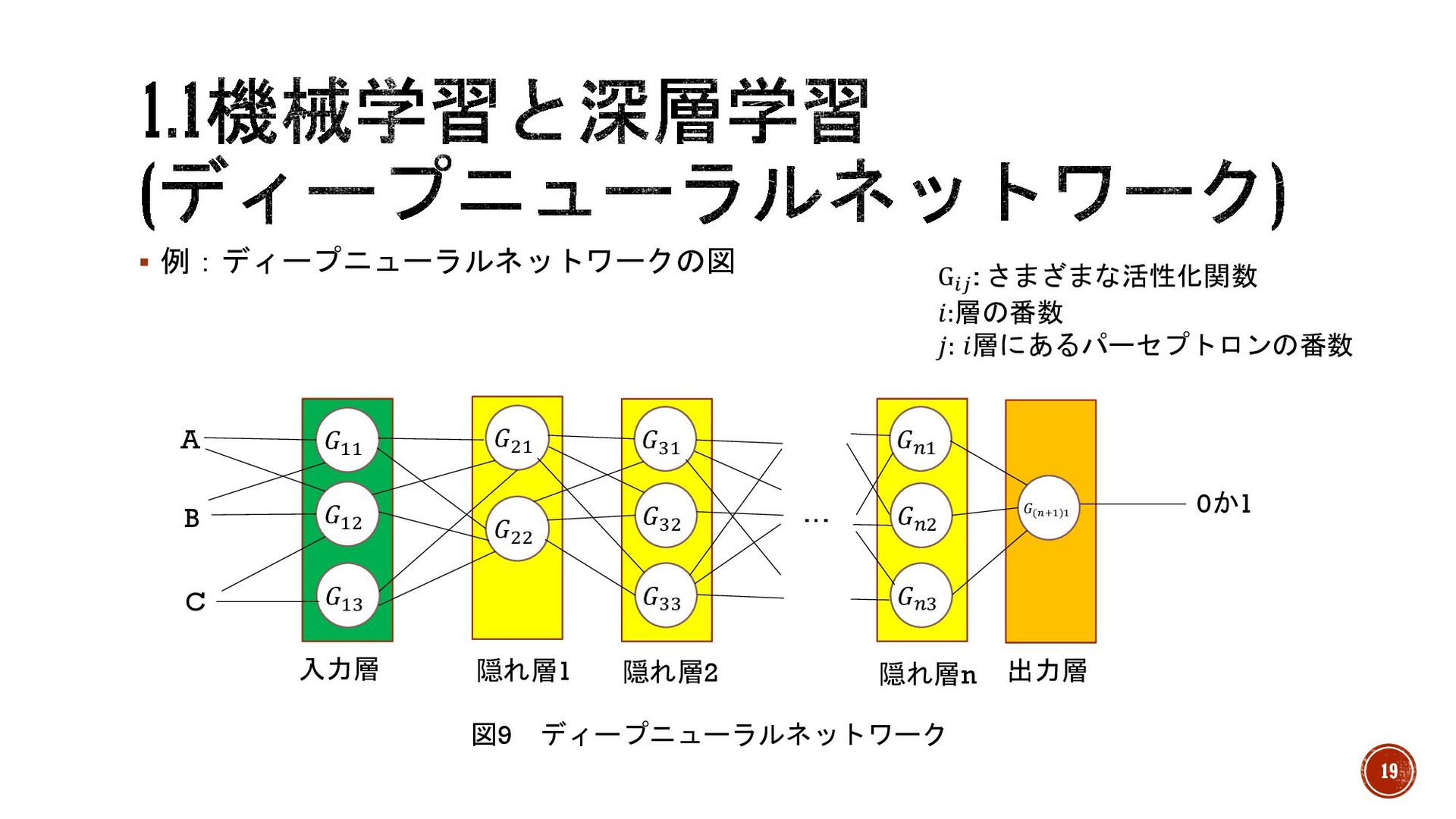
§ 例:ディープニューラルネットワークの図 図9 ディープニューラルネットワーク 𝐺&& 𝐺&% 𝐺%$ 𝐺%& 𝐺%% A
B C 0か1 入力層 隠れ層1 出力層 𝐺$% 𝐺$& 𝐺$$ 𝐺("#$)$ 𝐺+% 𝐺+& 𝐺+$ … 隠れ層n 隠れ層2 G'( : さまざまな活性化関数 𝑖:層の番数 𝑗: 𝑖層にあるパーセプトロンの番数 19
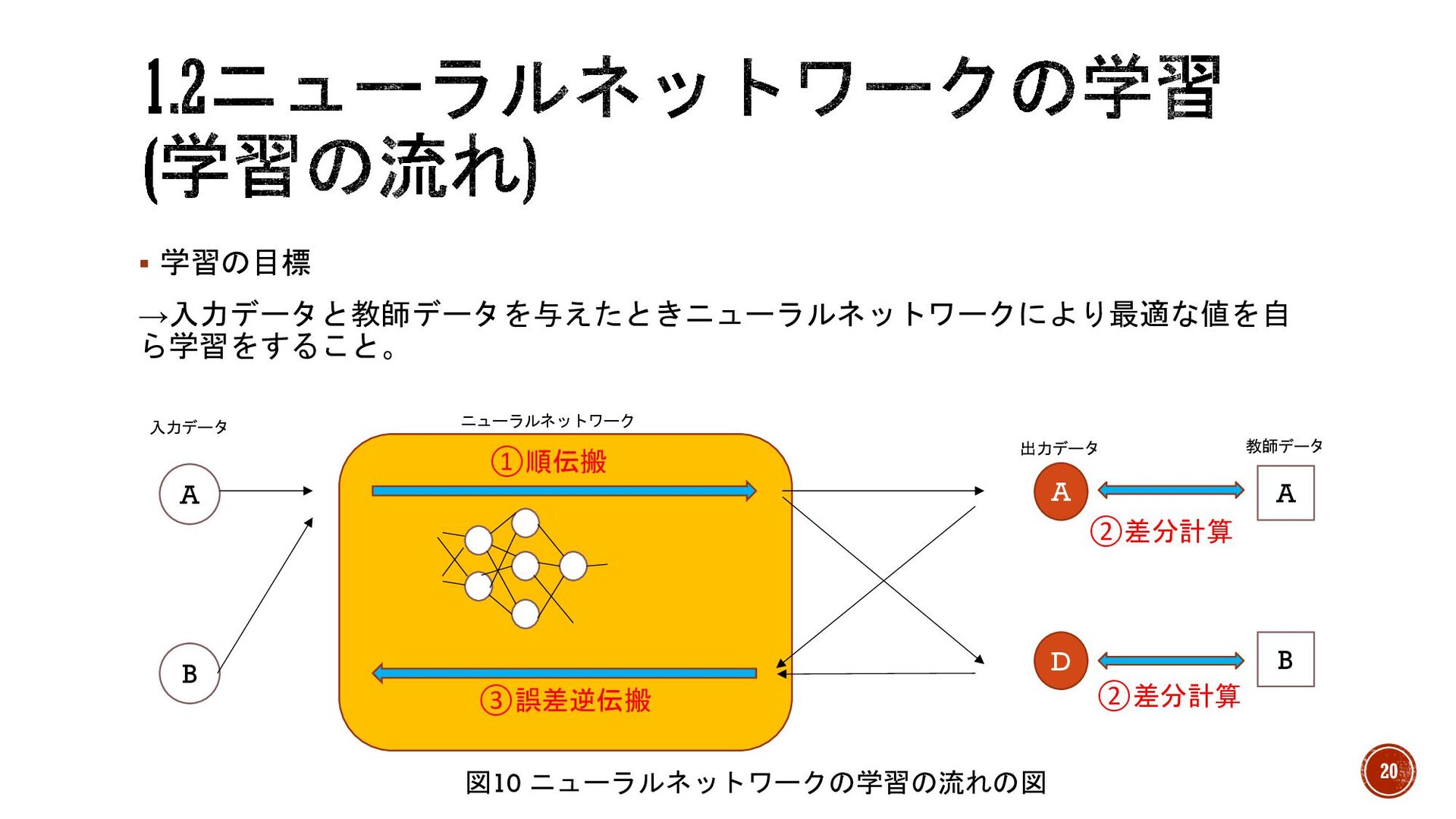
§ 学習の目標 →入力データと教師データを与えたときニューラルネットワークにより最適な値を自 ら学習をすること。 A B ニューラルネットワーク ①順伝搬 ③誤差逆伝搬 教師データ
出力データ A D A B ②差分計算 ②差分計算 図10 ニューラルネットワークの学習の流れの図 入力データ 20
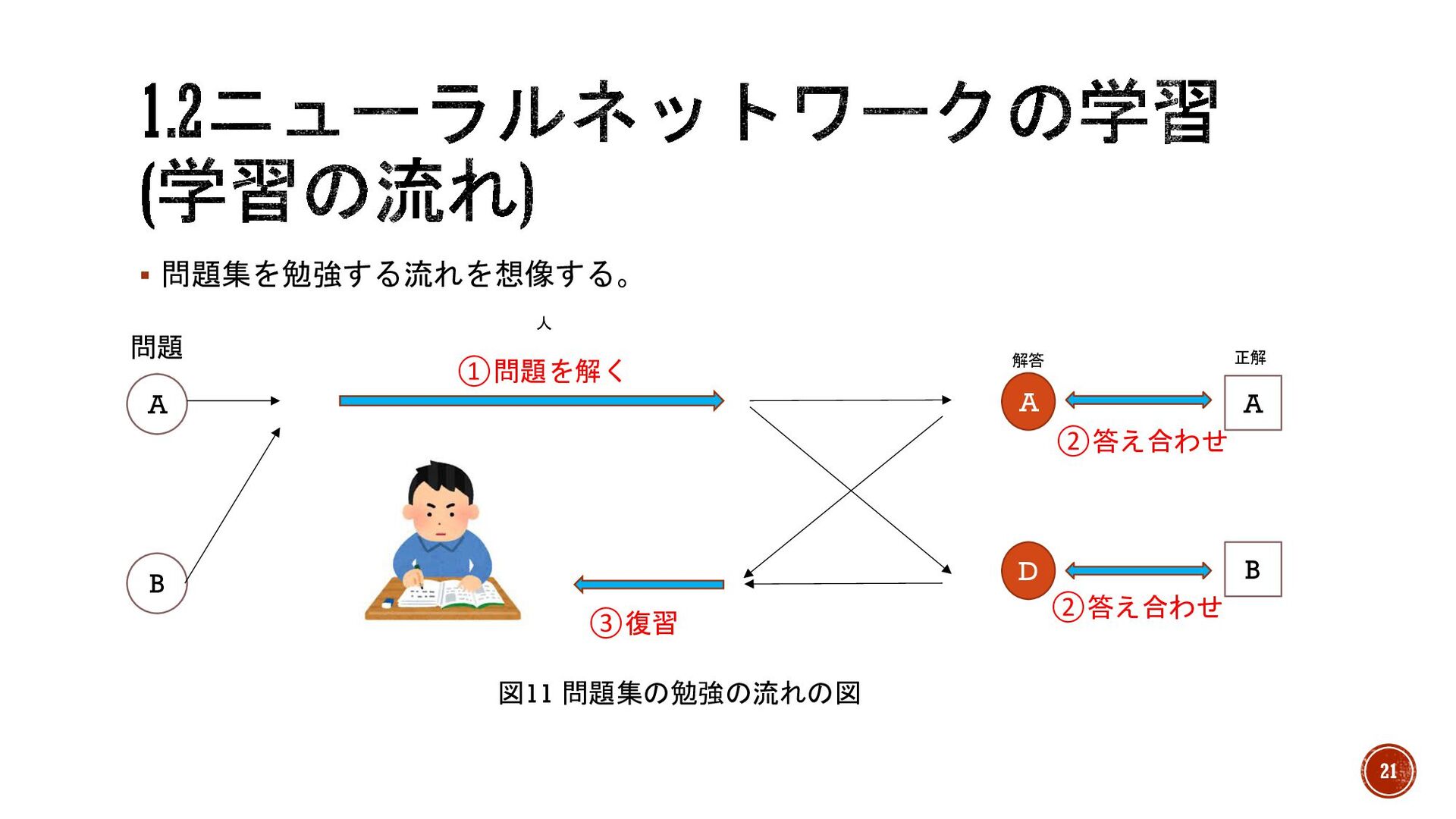
§ 問題集を勉強する流れを想像する。 A B 人 ①問題を解く ③復習 正解 解答 A
D A B ②答え合わせ ②答え合わせ 図11 問題集の勉強の流れの図 問題 21
§ 順伝搬 →入力側から出力側にデータを流すこと。図11で言う「問題を解く」。これにより出 力データを得られるが、そのデータはランダムな重みによって適当に出された。 § 差分計算 →出力データと教師データを比べてどれだけかけ離れているかを計算すること。図11 で言う「答え合わせ」。出力データと教師データがかけ離れていることを損失と言い、 この損失を決める関数を損失関数という。 §
誤差逆伝播 →②で出てきた損失(誤差)を出力側から入力側へと逆向きに伝えること。図11で言う 「復習」。そうすることで重みを変更していき、損失を小さくしていく。 22
§ ①順伝搬→②差分計算→③誤差逆伝播の順で入力データ全てに対して学習を行って いく。 →問題集の勉強の例でいくと1回学習するだけで全てを覚えることはほぼ不可能。 (ニューラルネットワークも同様) § 以上から①~③を繰り返し行う。そうすることで損失が下がり、正答率が上昇する。 23
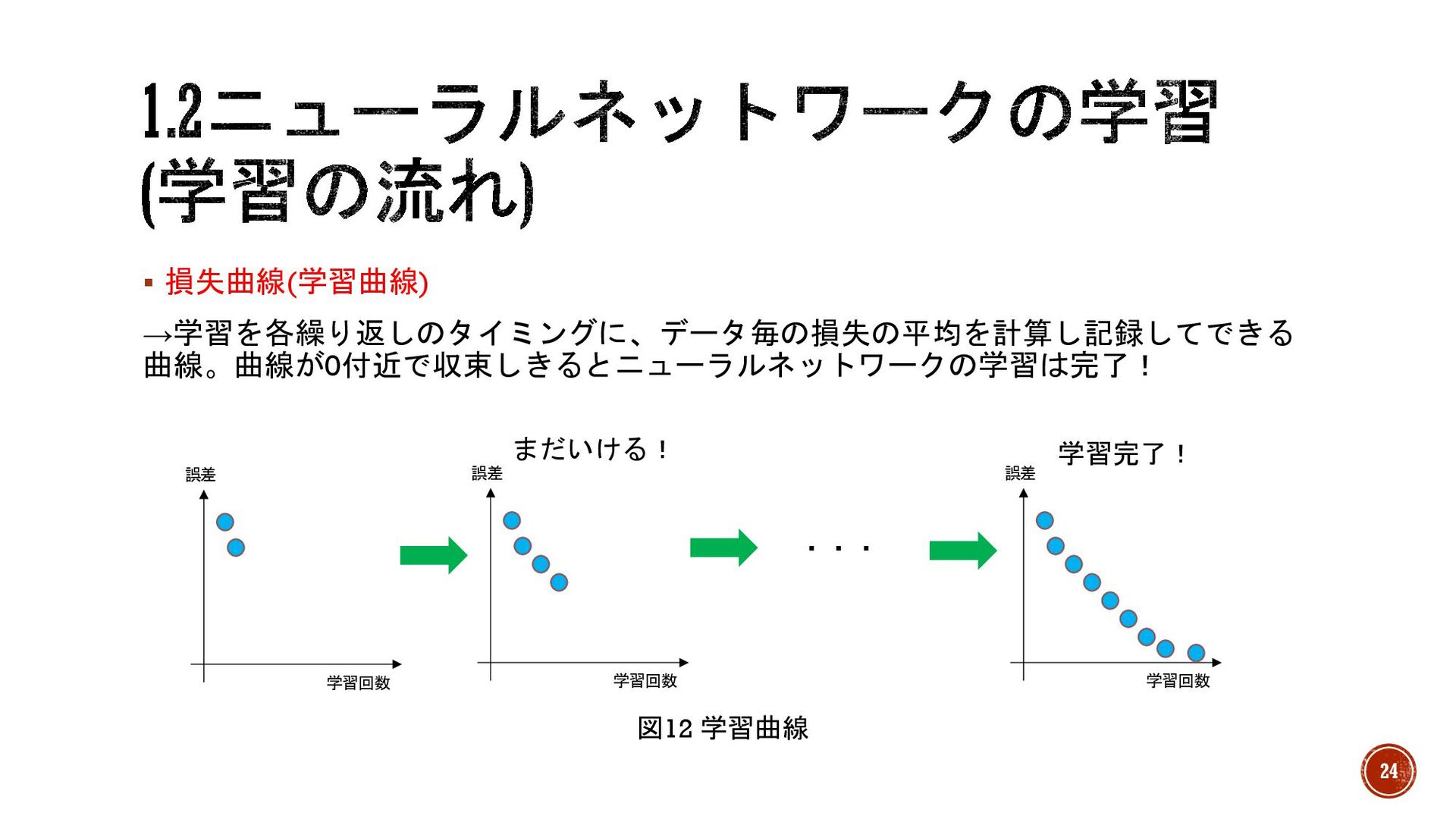
§ 損失曲線(学習曲線) →学習を各繰り返しのタイミングに、データ毎の損失の平均を計算し記録してできる 曲線。曲線が0付近で収束しきるとニューラルネットワークの学習は完了! 誤差 学習回数 誤差 学習回数 誤差 学習回数
学習完了! まだいける! ・・・ 図12 学習曲線 24
§ 過学習 →用意した学習用の入力データに対して完璧に反応できるがそれ以外のデータに対し ては正確な反応が全くできない現象。 § 汎化性能 →完全に学習データの反応みのに固定されるのでなく未知のデータに対しても反応で きるように行う性能。 25
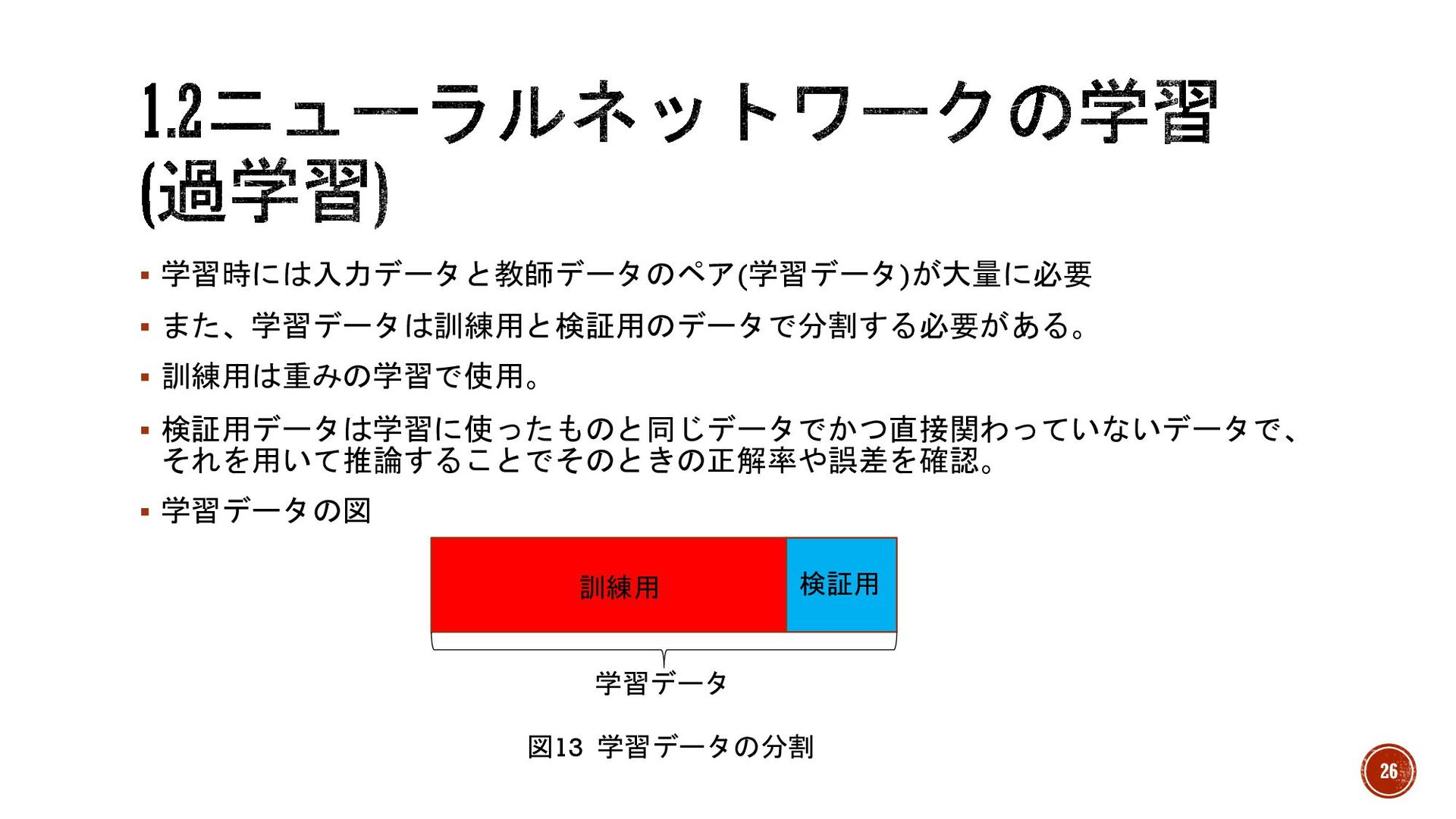
§ 学習時には入力データと教師データのペア(学習データ)が大量に必要 § また、学習データは訓練用と検証用のデータで分割する必要がある。 § 訓練用は重みの学習で使用。 § 検証用データは学習に使ったものと同じデータでかつ直接関わっていないデータで、 それを用いて推論することでそのときの正解率や誤差を確認。 §
学習データの図 学習データ 検証用 訓練用 図13 学習データの分割 26
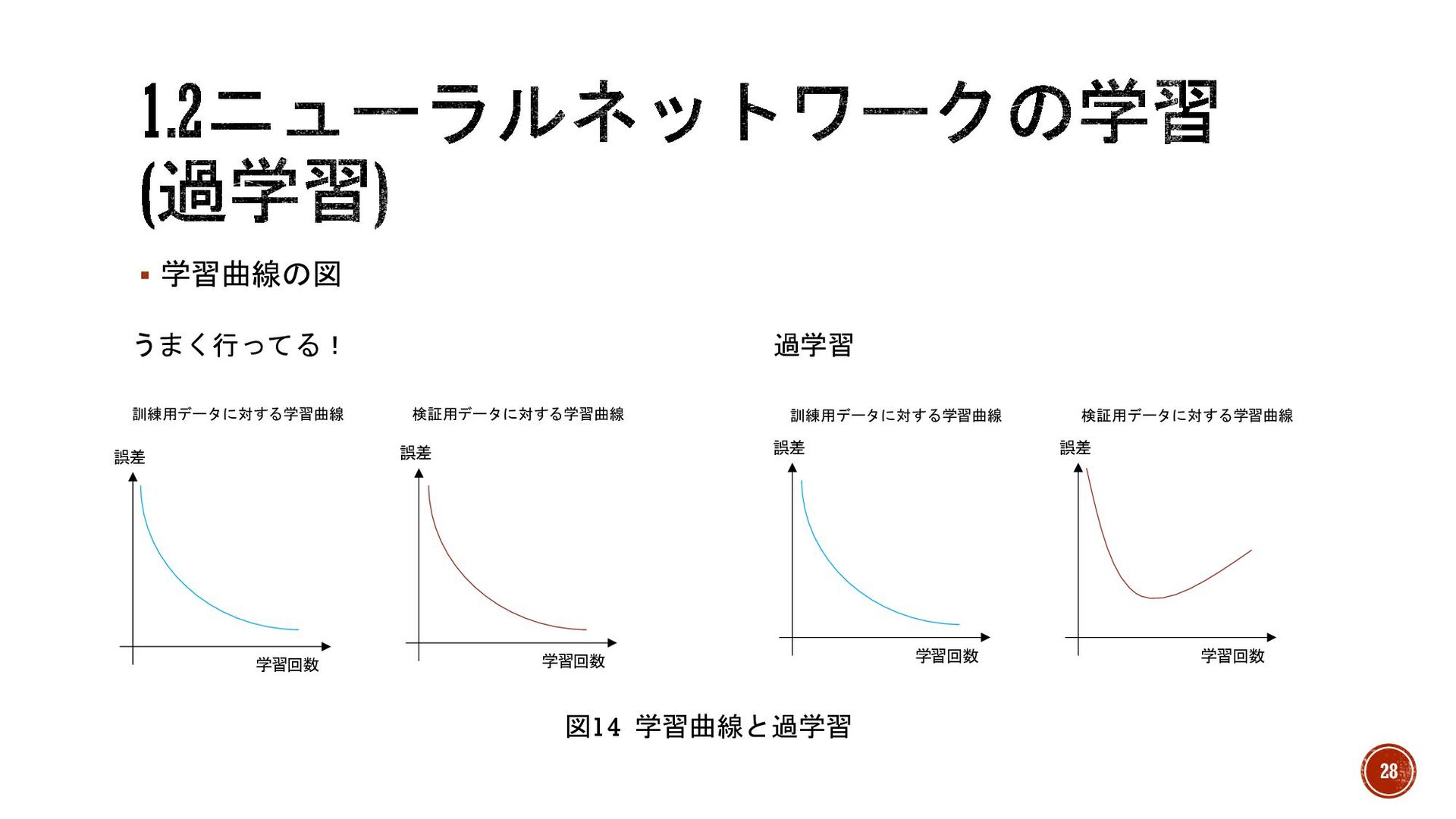
§ 学習時、訓練用データに対する学習曲線と検証用に対する学習曲線を見る必要がある。 § うまくいってる場合は学習曲線は両方とも同じ形になる。 § 過学習に場合、訓練用データに対する学習曲線は下がっていきますが検証用に対する 学習曲線はあるタイミングで上昇します。 27
§ 学習曲線の図 誤差 学習回数 誤差 学習回数 誤差 学習回数 誤差 学習回数
過学習 うまく行ってる! 訓練用データに対する学習曲線 訓練用データに対する学習曲線 検証用データに対する学習曲線 検証用データに対する学習曲線 図14 学習曲線と過学習 28
§ ニューラルネットワークの学習方法は主に3つ § オンライン学習(確率的勾配降下法) 用意したデータ1つずつに対して①順伝搬→②差分計算→③誤差逆伝播の順で行っ ていく。 欠点 1. ③でネットワークの重みを更新するがマイナスに働く(損失が大きくなる)ことも あり、学習が不安定になる。
2. 最後の入力データに依存しやすい。 29
§ バッチ学習(最急降下法) 用意したデータ全てに対して①順伝搬、②差分計算を行い、全部の②で計算した損 失を平均して、一括で③誤差逆伝播を行い重みを更新する。 利点 1. 安定して損失が減っていく 2. 他の学習と比べ処理時間が短い 欠点
データ数と使用メモリが比例するため使用メモリが多くなる。 30
§ ミニバッチ学習 最近主流の学習法。メモリの使用量を現実的な量にまとめられ、できる限り一括で学 習する 方法 1. 用意した入力データをいくつかのまとまり(ミニバッチ)に分ける。 ※ミニバッチ内のデータ数をバッチサイズという 2. ミニバッチごとにミニバッチ内の全てのデータに①順伝搬、②差分計算を行う
3. 一括で③誤差逆伝播を行い重みを更新(一回行うことを1ステップ) 4. これを繰り返す ※繰り返す回数をエポック(Epoch)という。 31
§ しかし、ミニバッチはオンライン学習の欠点である学習の安定性は完全には解決して ないことに注意する。 § ミニバッチ内でデータに偏りがある場合、オンライン学習と同様に学習が不安定 →入力データをランダムにシャッフルしてミニバッチに分けたり、ミニバッチ内に全 ての種別が入るように分離したりと工夫が必要 32
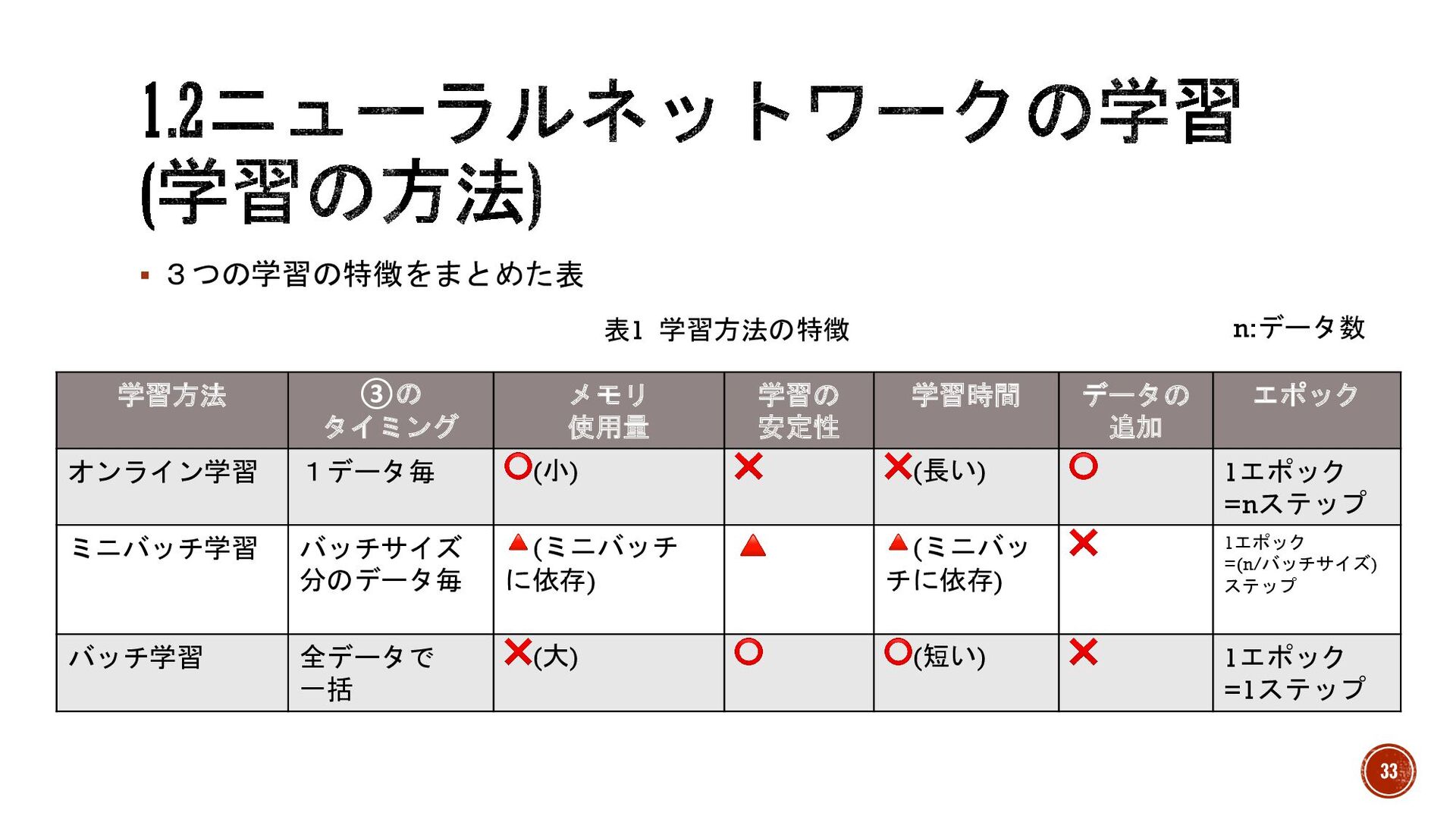
§ 3つの学習の特徴をまとめた表 学習方法 ③の タイミング メモリ 使用量 学習の 安定性 学習時間
データの 追加 エポック オンライン学習 1データ毎 ⭕(小) ❌ ❌(長い) ⭕ 1エポック =nステップ ミニバッチ学習 バッチサイズ 分のデータ毎 🔺(ミニバッチ に依存) 🔺 🔺(ミニバッ チに依存) ❌ 1エポック =(n/バッチサイズ) ステップ バッチ学習 全データで 一括 ❌(大) ⭕ ⭕(短い) ❌ 1エポック =1ステップ 表1 学習方法の特徴 n:データ数 33
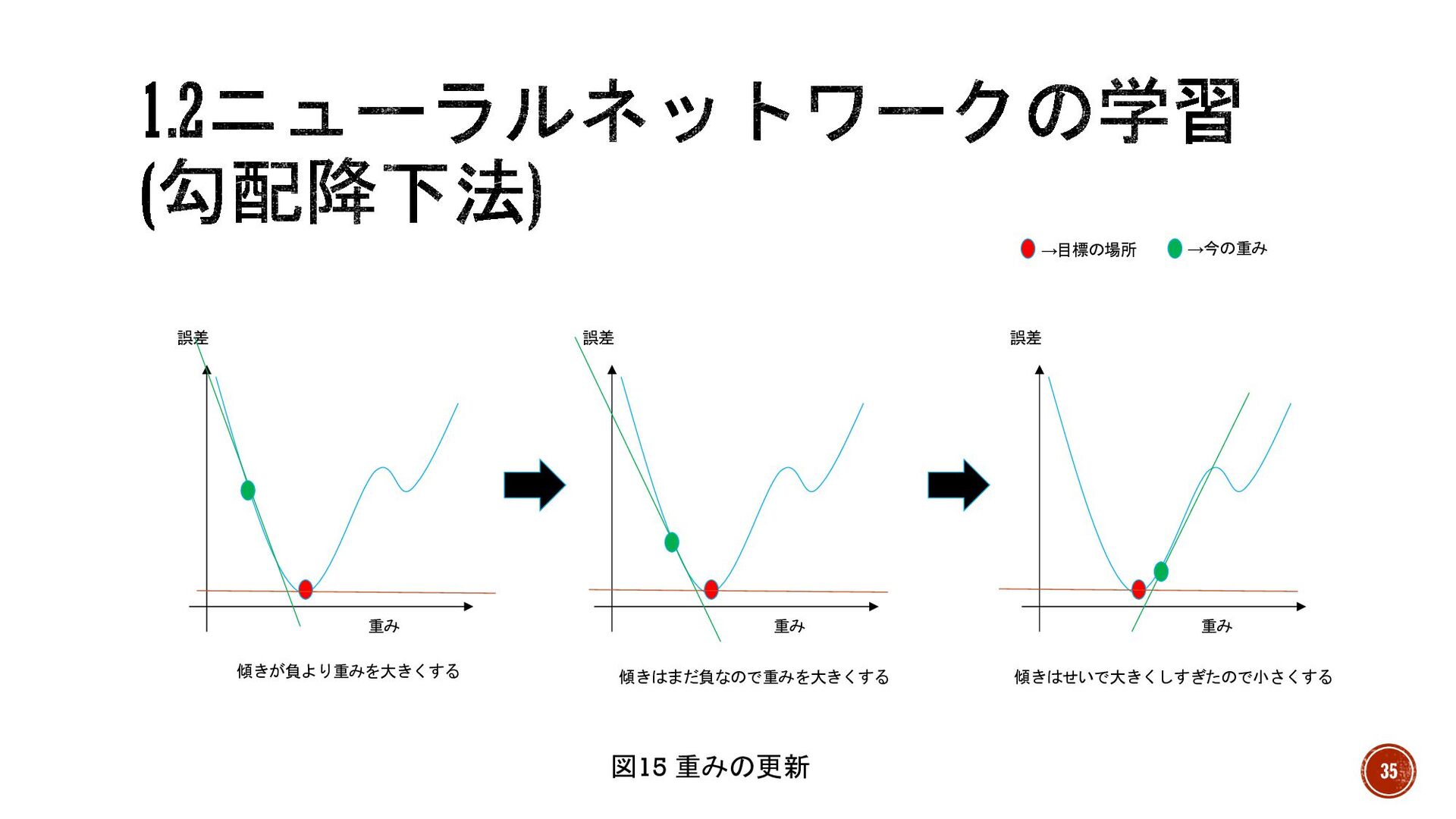
§ 勾配降下法 →③誤差逆伝搬における重みの更新で最適な手法。 § 注目した重みを変数とし、それを用いた損失関数を定義 →このとき関数の形は分からなくても微分で今の重みの点における傾き(勾配)がわかる § 損失は誤差の大きさなので負の値を取らないから損失関数は下に凸 § 目標:勾配を0にする(近づける)
→傾きが正であれば小さく、負であれば大きくする。 34
誤差 重み 誤差 重み 誤差 重み 図15 重みの更新 →目標の場所 →今の重み
傾きが負より重みを大きくする 傾きはまだ負なので重みを大きくする 傾きはせいで大きくしすぎたので小さくする 35
§ 教師なし学習 →学習においてさせる側から見て教師(正解データ)がない。ニューラルネットワーク自 体には教師データが渡されている。代表としてAutoEncoder(第4章)があり、教師デー タとして入力データそのものをニューラルネットワークに渡すことで学習。 36
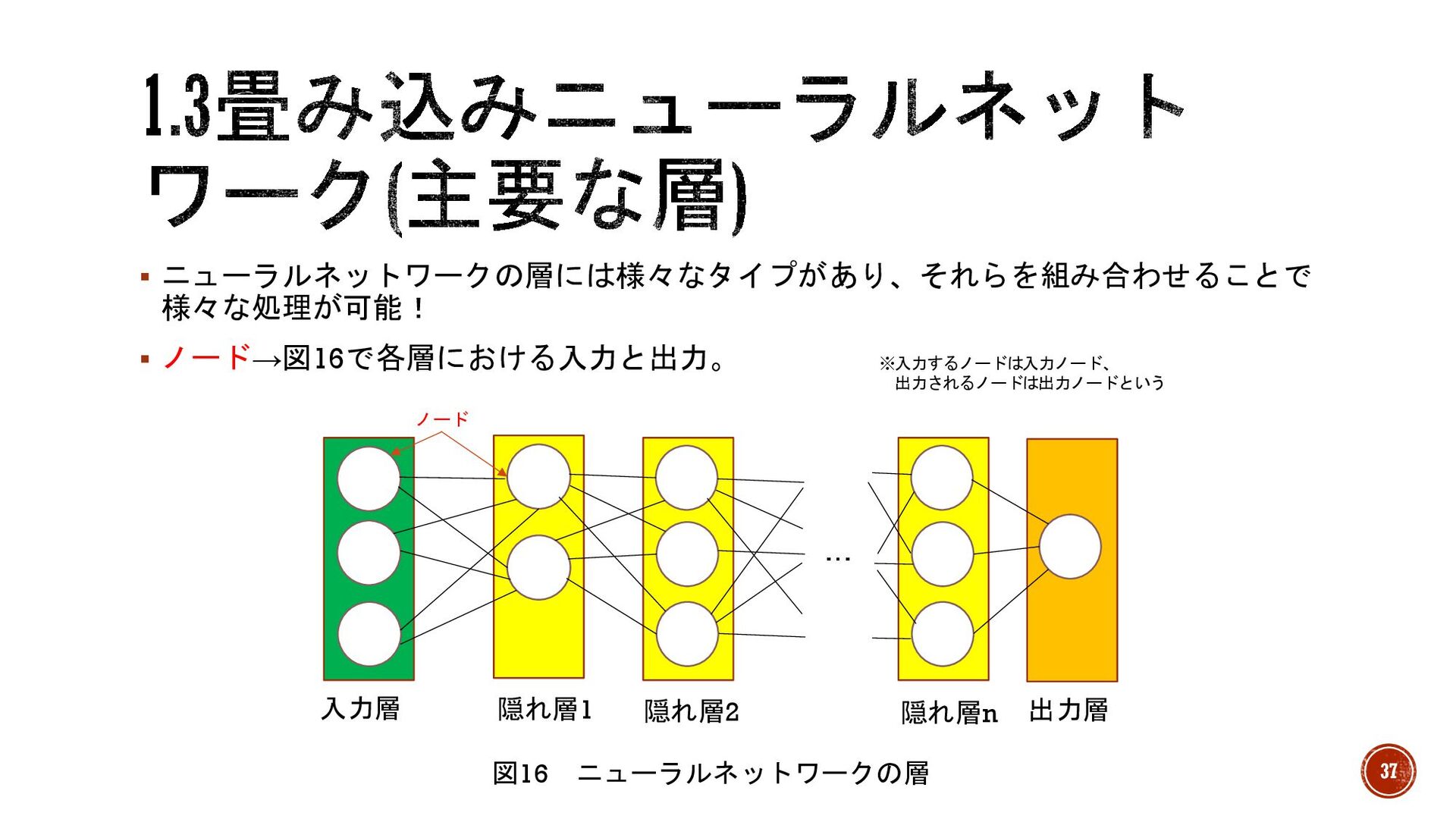
§ ニューラルネットワークの層には様々なタイプがあり、それらを組み合わせることで 様々な処理が可能! § ノード→図16で各層における入力と出力。 図16 ニューラルネットワークの層 入力層 隠れ層1 出力層
… 隠れ層n 隠れ層2 ノード ※入力するノードは入力ノード、 出力されるノードは出力ノードという 37
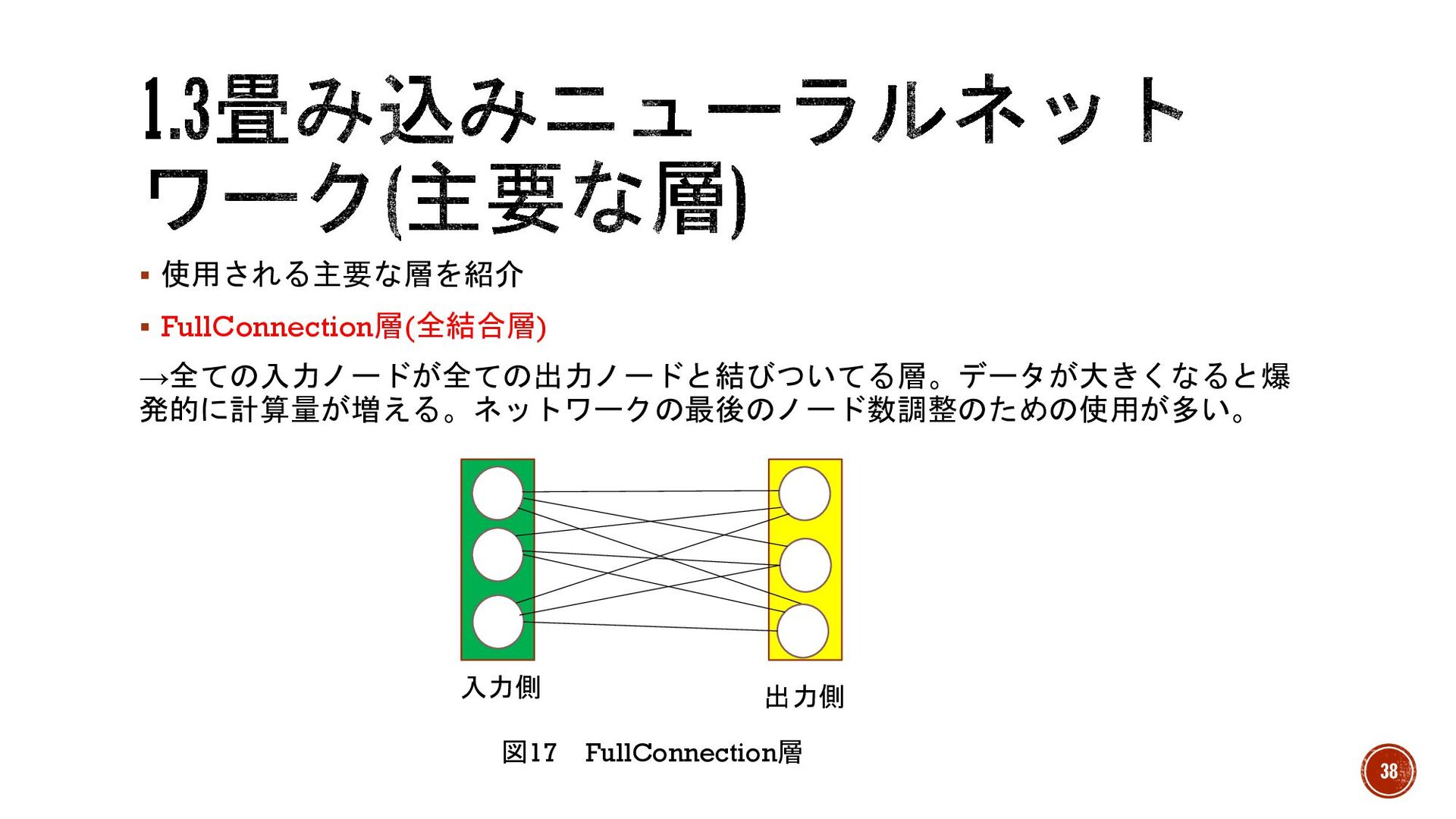
§ 使用される主要な層を紹介 § FullConnection層(全結合層) →全ての入力ノードが全ての出力ノードと結びついてる層。データが大きくなると爆 発的に計算量が増える。ネットワークの最後のノード数調整のための使用が多い。 図17 FullConnection層 入力側 出力側
38
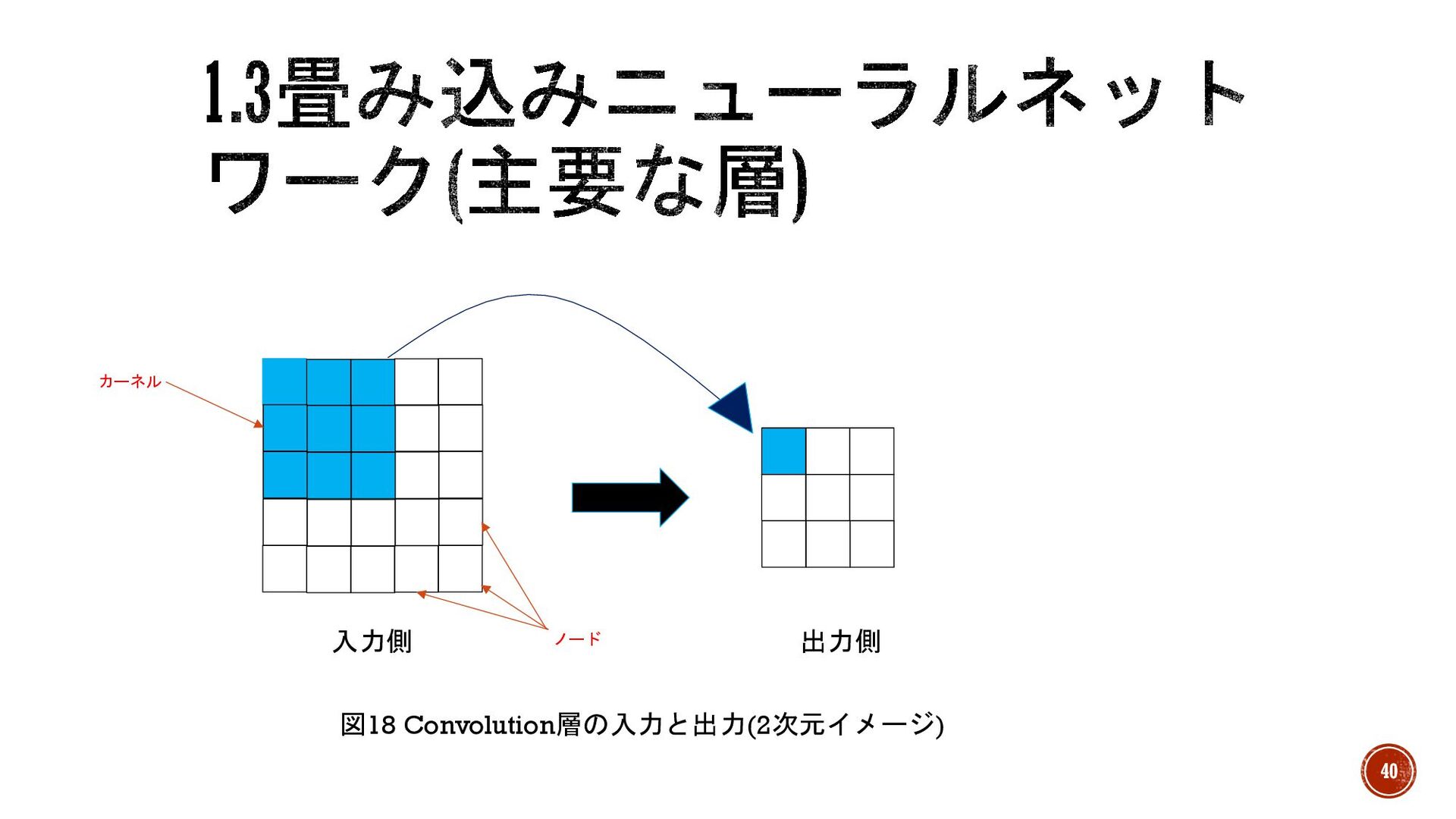
§ Convolution層(畳み込み層) →図19のように入力ノードいくつかのまとまりで圧縮し、特徴を抽出する層。 § カーネル →出力するために用いられる入力ノードの領域。図18で入力側の水色部分。サイズが 3×3のとき3×3カーネルというようにサイズをつけて呼ぶ場合もある。また、サイズが 縦と横同じ場合は正方カーネルとよび、 Convolution層で主に使用される。 §
畳み込み →カーネルごとに情報を圧縮することでデータ全体を小さくすること。 39
入力側 出力側 カーネル ノード 図18 Convolution層の入力と出力(2次元イメージ) 40
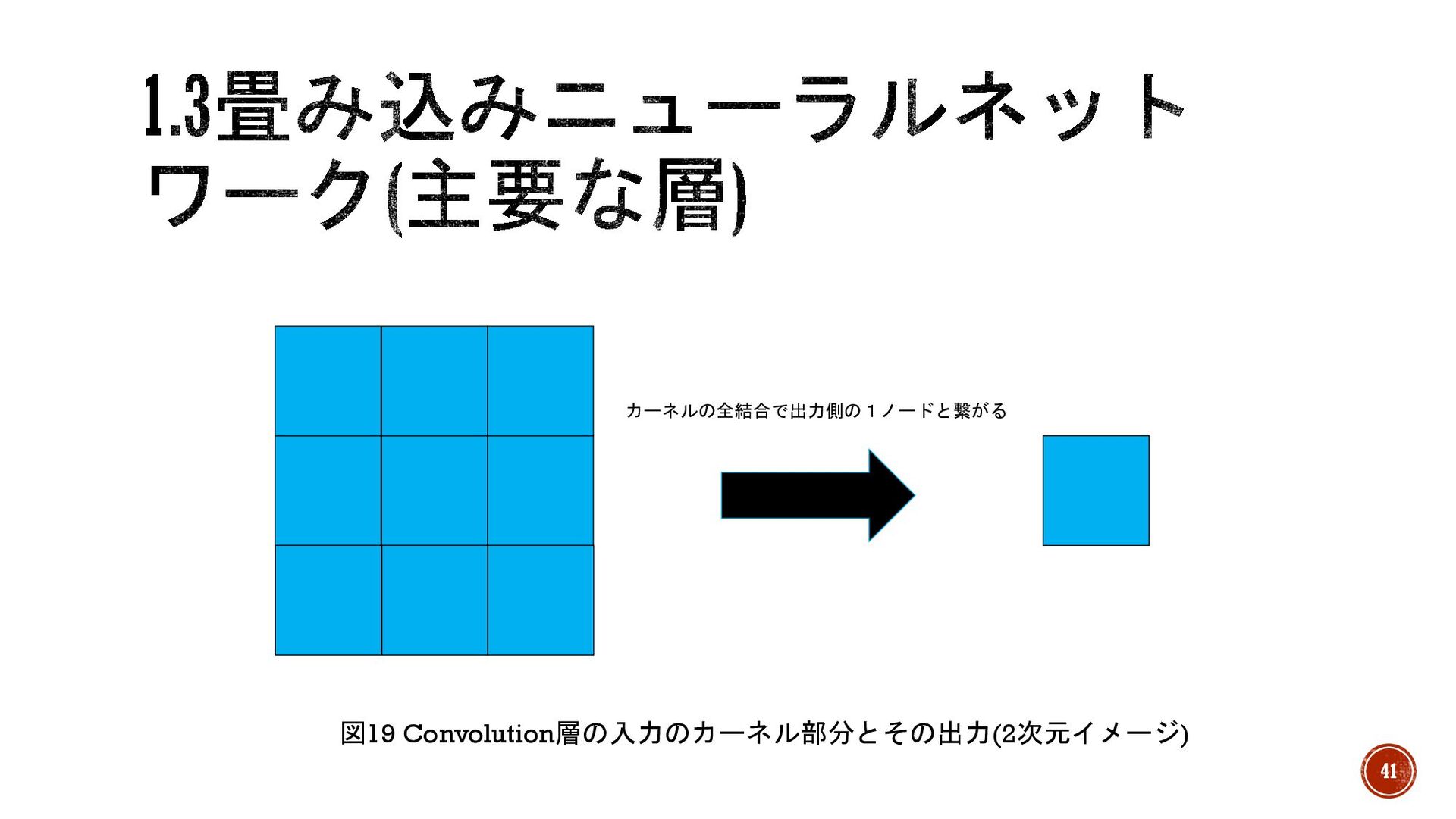
カーネルの全結合で出力側の1ノードと繋がる 図19 Convolution層の入力のカーネル部分とその出力(2次元イメージ) 41
§ 畳み込みのやり方例 1.図18のようにカーネルのサイズを決めて、一番左上端にカーネルおきます。 2.カーネルを全結合で1つの出力側のノードに出力。 3.図20のようにカーネルを1ノード分右にずらします。 ※ストライド→カーネルをずらす大きさで、サイズをつけて1×1ストライドともいう。 4.ずらしたカーネルのサイズ分のノードを出力ノードの1つ右のノードに結びつける。 5.これをカーネルの右端が入力ノードの右端に被るまで順番に続ける。 42
図20 カーネルを1ノード分右にずらして出力(2次元イメージ) 43
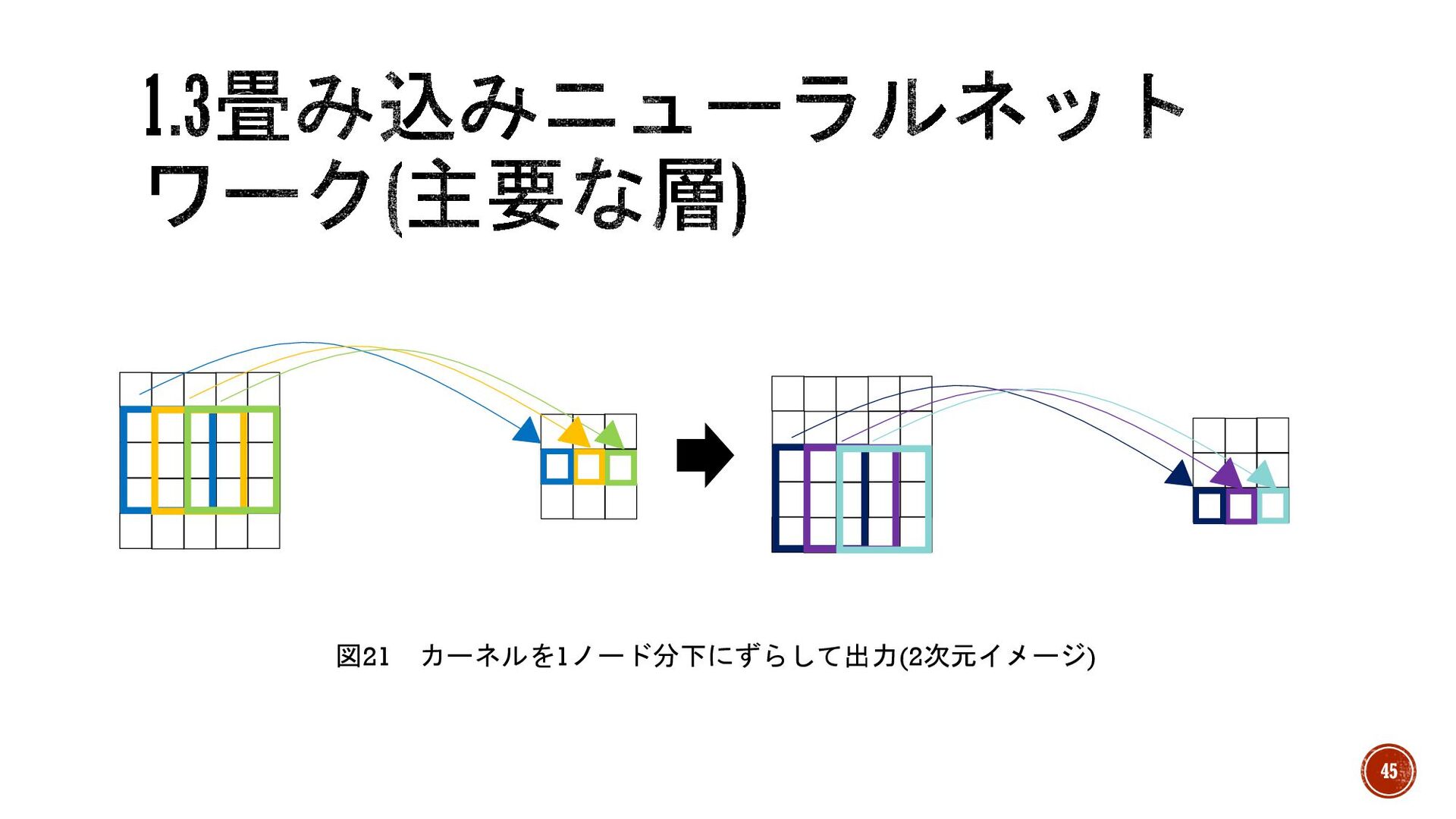
6.右端までずらしたら、図21のようにカーネルを一番左まで戻し、下方向に1ノード分 ずらします。 7.ずらした位置からカーネル分のノードを出力側の左上ノード1つ下のノードに結びつ ける。 8.右端まで処理が終わったら一番左まで戻し、下方向に1ノード分ずらし、進める処理 をすべての入力ノードが最低1回は処理されるまで続ける。 44
図21 カーネルを1ノード分下にずらして出力(2次元イメージ) 45
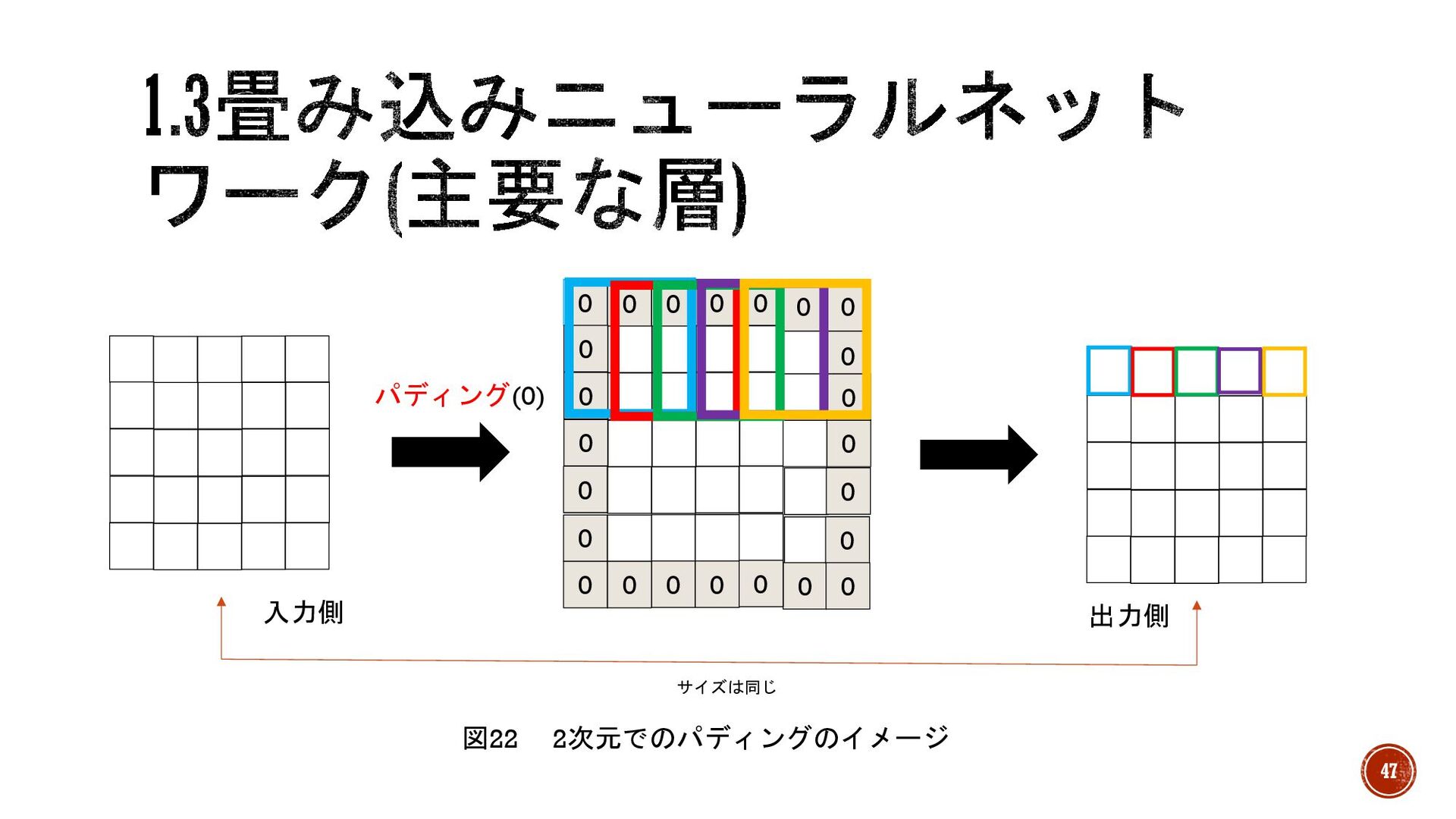
§ サイズを変えたくない! →図22のように入力データ全体の周囲に擬似的なノードを増やしてから畳み込み。 § パディング →図22のように入力データ全体の周囲にある擬似的なノード。これは入力と出力のサ イズが一致するように付ける。値としては0で埋めたり、周囲のデータをそのまま使用 する。 46
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 サイズは同じ パディング(0) 図22 2次元でのパディングのイメージ 入力側 出力側 47
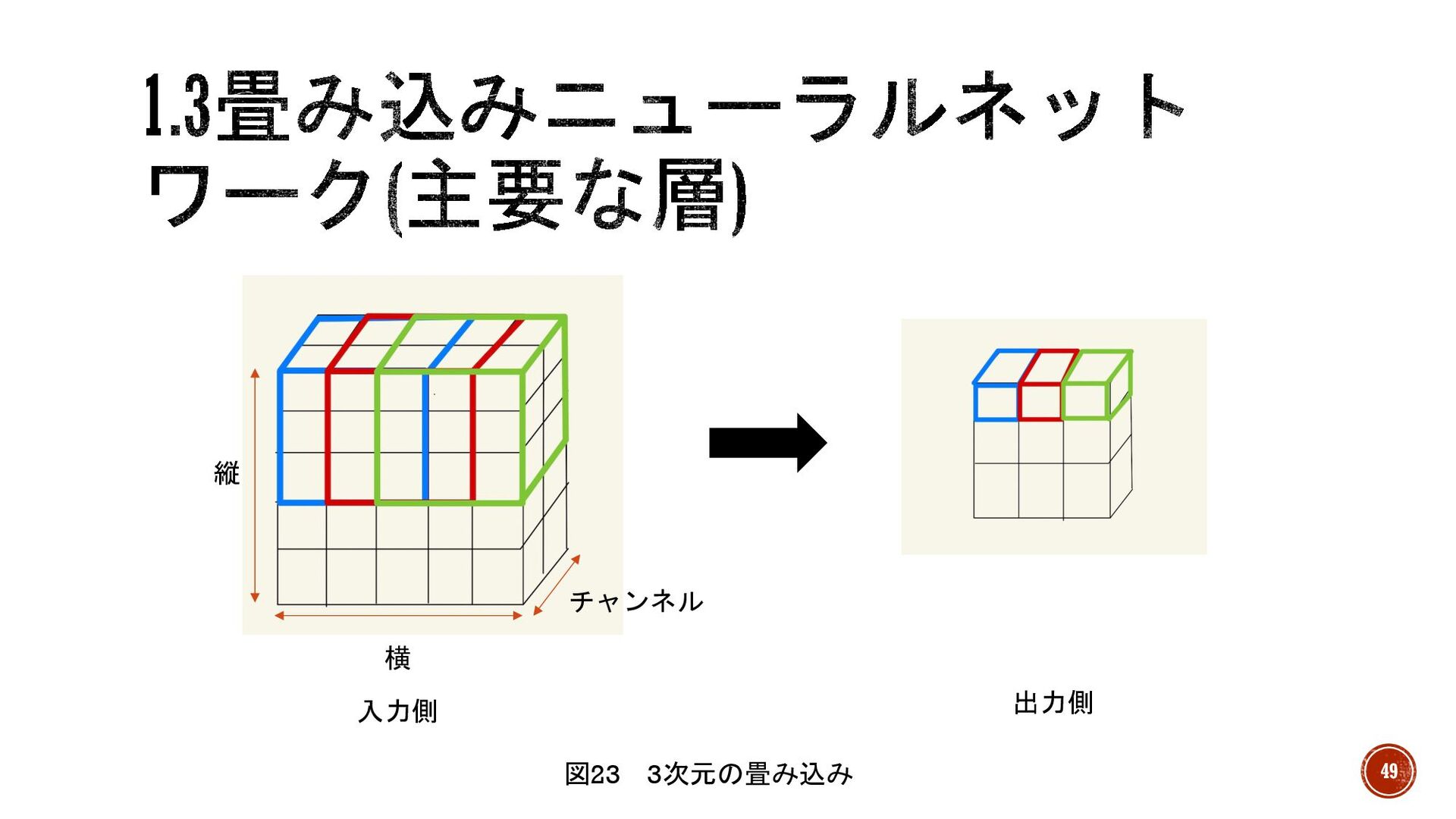
§ ここまで2次元で説明したが、実際は3次元がほとんど。 § 画像処理においても、画像データは図23の入力側ように縦・横・チャンネル(RGB等) の3次元が多い。 § しかし、3次元データに対する畳み込みも、2次元データとあまり変わりません。 § 図23のように全てのチャンネルにおける同じ位置(縦横)のノードを1つの出力ノード に結びつける。
48
縦 横 チャンネル 入力側 出力側 図23 3次元の畳み込み 49
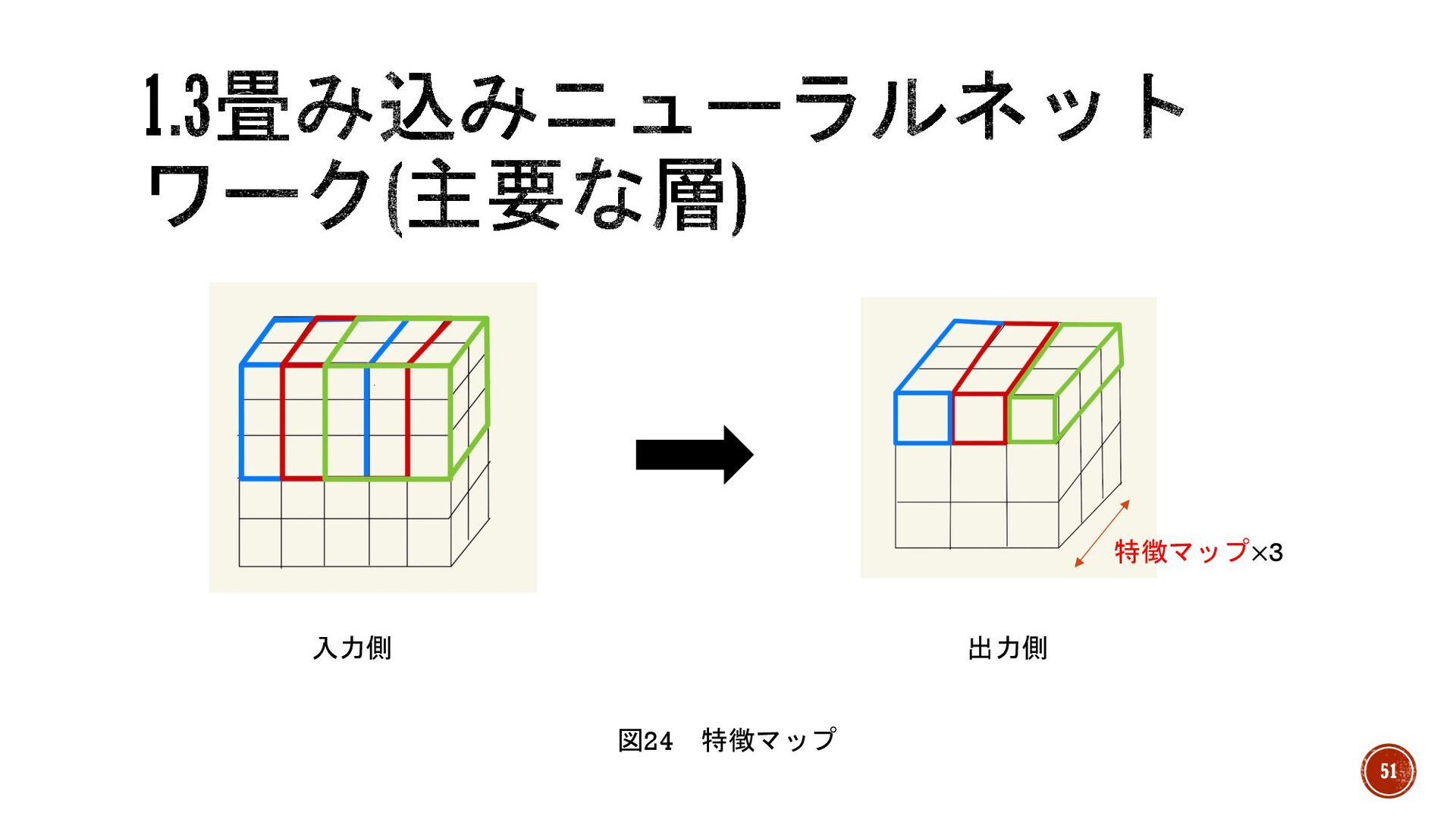
§ 一般的な畳み込みは特徴を圧縮し、データサイズを小さくする代わりに図24のように 3次元方向(奥行き)に増やす。 § 画像データとした時特徴を圧縮し、特徴ごとに2次元マップを大量に作るイメージ § 特徴マップ →出力される3次元データを2次元の集まりとしたときのそれぞれの2次元データ § フィルターサイズ(特徴マップ数)
→出力側の3次元方向のサイズ ※マップ→地図っぽい何か 50
入力側 出力側 特徴マップ×3 図24 特徴マップ 51
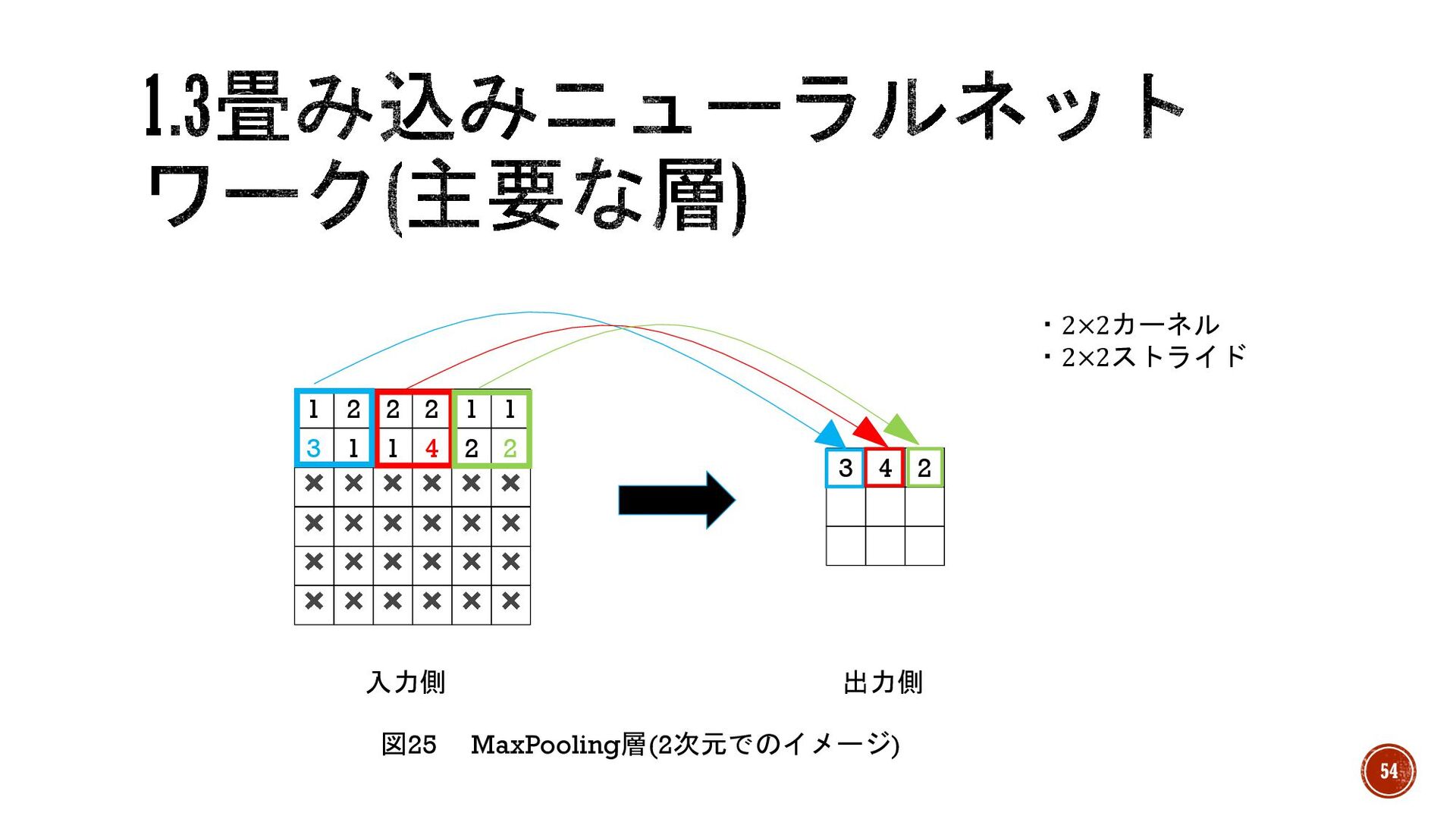
§ MaxPooling層/ AveragePooling層(最大プーリング層/平均プーリング層) →入力ノードをいくつかのまとまりごとに処理をかけて出力を行う処理。固定的な処 理なので学習する重みを持たない。よくConvolution層で特徴を抽出した後に MaxPooling層で特徴を濃くしたり、AveragePooling層で特徴を平均化する。 § 手順 1.入力に対し、カーネルサイズ分のノードを取ってくる。 2.
MaxPooling層の場合 →カーネルの中で最大の値を出力ノードの値にする。 52
2. AveragePooling層の場合 →カーネルの値を平均してその値を出力ノードの値とする。 3.カーネルをストライド分ずらして処理していく 4.全ての入力ノードが最低1回は処理されるまで続ける。 53
✖ ✖ ✖ ✖ ✖ ✖ ✖ ✖ ✖ ✖
✖ ✖ ✖ ✖ ✖ ✖ ✖ ✖ 4 2 2 2 1 1 ✖ ✖ ✖ 3 1 1 1 2 2 ✖ ✖ ✖ 3 4 2 入力側 出力側 図25 MaxPooling層(2次元でのイメージ) 54 ・2×2カーネル ・2×2ストライド
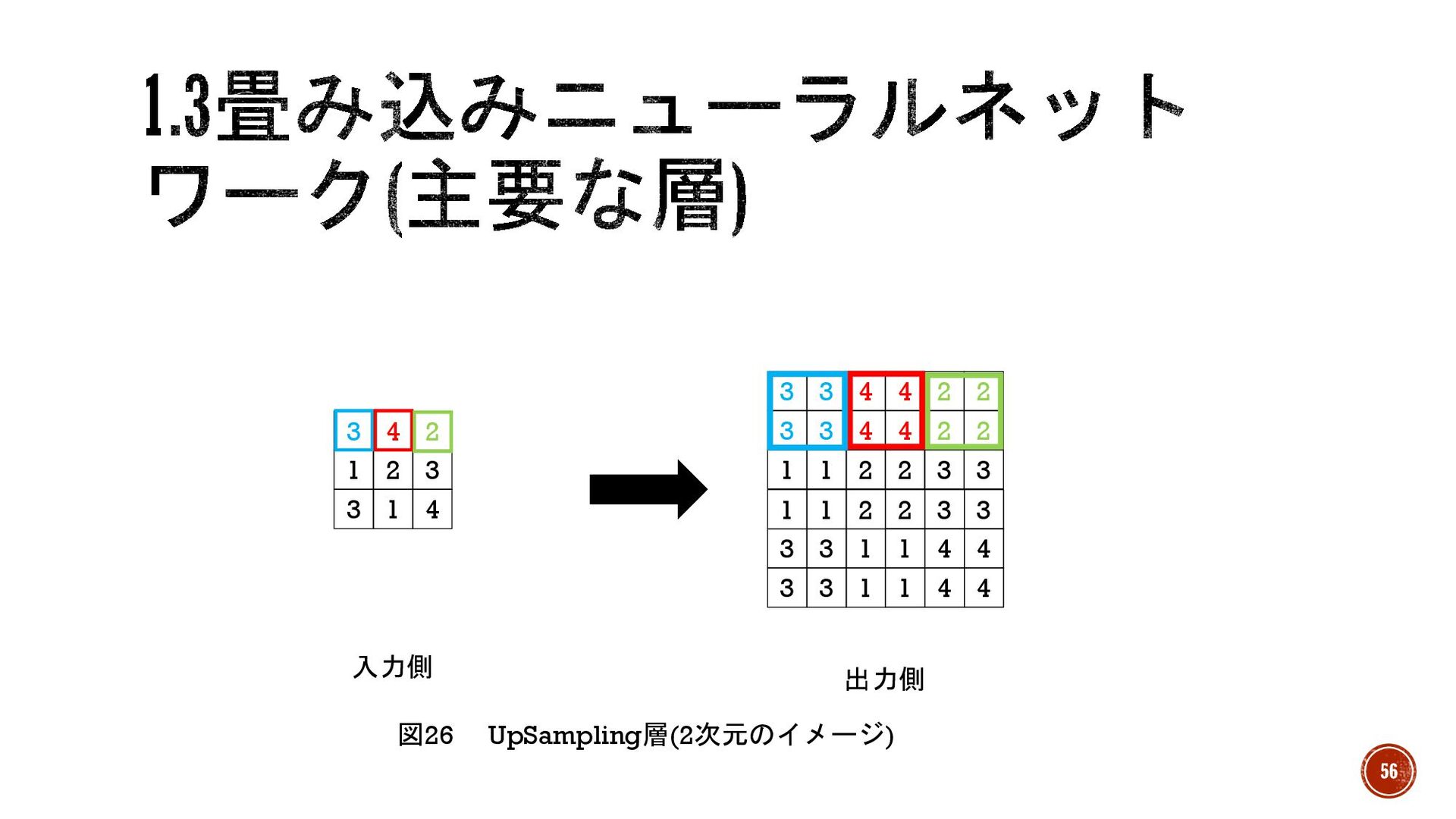
§ UpSampling層(アップサンプリング層) →入力ノードを拡大し、出力のデータのサイズを拡大する層。 Convolution層で小さ くしたデータを大きくし、元のサイズに戻す時に使用される。固定的な処理なので学 習する重みを持たない。 § 手順(MaxPooling層/とAveragePooling層の逆のイメージ) 1.入力側の1つのノードを指定された縦横サイズ分拡大し、出力 2.入力ノードすべてに対して行う
55
1 2 3 3 4 2 3 1 4 3
3 1 1 1 2 3 3 1 1 4 4 2 3 3 1 4 4 4 2 2 4 2 2 2 3 3 3 3 4 3 3 4 1 1 2 入力側 出力側 図26 UpSampling層(2次元のイメージ) 56
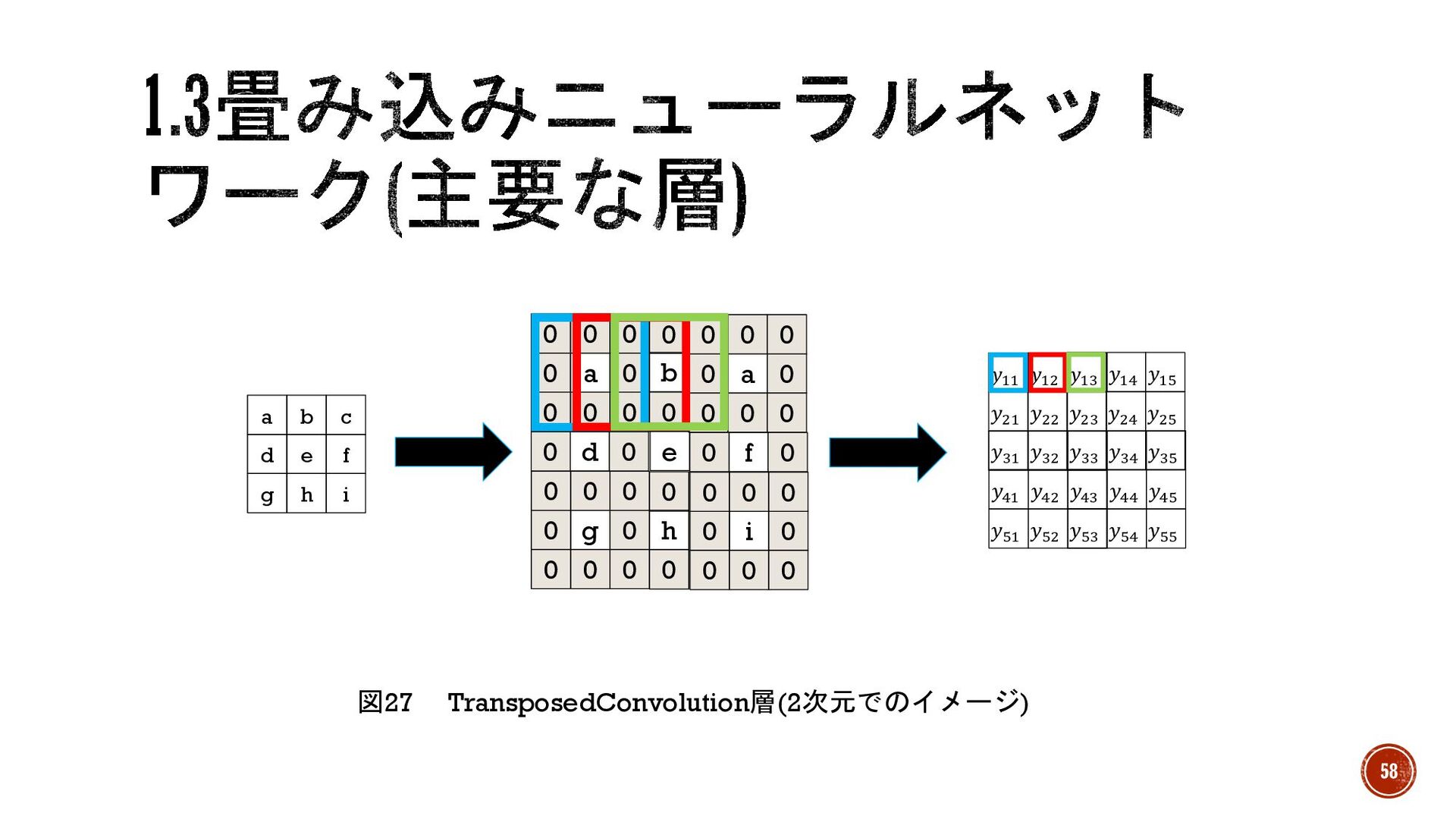
§ TransposedConvolution層、Deconvolution層(逆畳み込み層) → Convolution層の逆の処理で、特徴を畳み込みながらデータサイズを大きくする 層。よくUpSampling層とConvolution層のセットの代わりに使用。 § 手順(よく使われる方法) 1.図27のようにデータ同士の間にパディング(0で埋める)を行う 2.間引いたデータに対してConvolution層と同じような畳み込みを行う 57
図27 TransposedConvolution層(2次元でのイメージ) d e f a b c g h
i 0 a 0 0 0 0 0 0 0 0 i 0 0 0 0 0 0 0 0 g 0 0 0 0 0 0 0 0 a 0 0 0 0 0 0 0 f 0 0 0 b 0 0 h 0 e d 0 0 𝑦%& 𝑦%' 𝑦(& 𝑦(' 𝑦&& 𝑦&' 𝑦)& 𝑦)' 𝑦'& 𝑦'' 𝑦%( 𝑦%% 𝑦%) 𝑦(( 𝑦(% 𝑦() 𝑦&( 𝑦&% 𝑦&) 𝑦)( 𝑦)% 𝑦)) 𝑦'( 𝑦'% 𝑦') 58
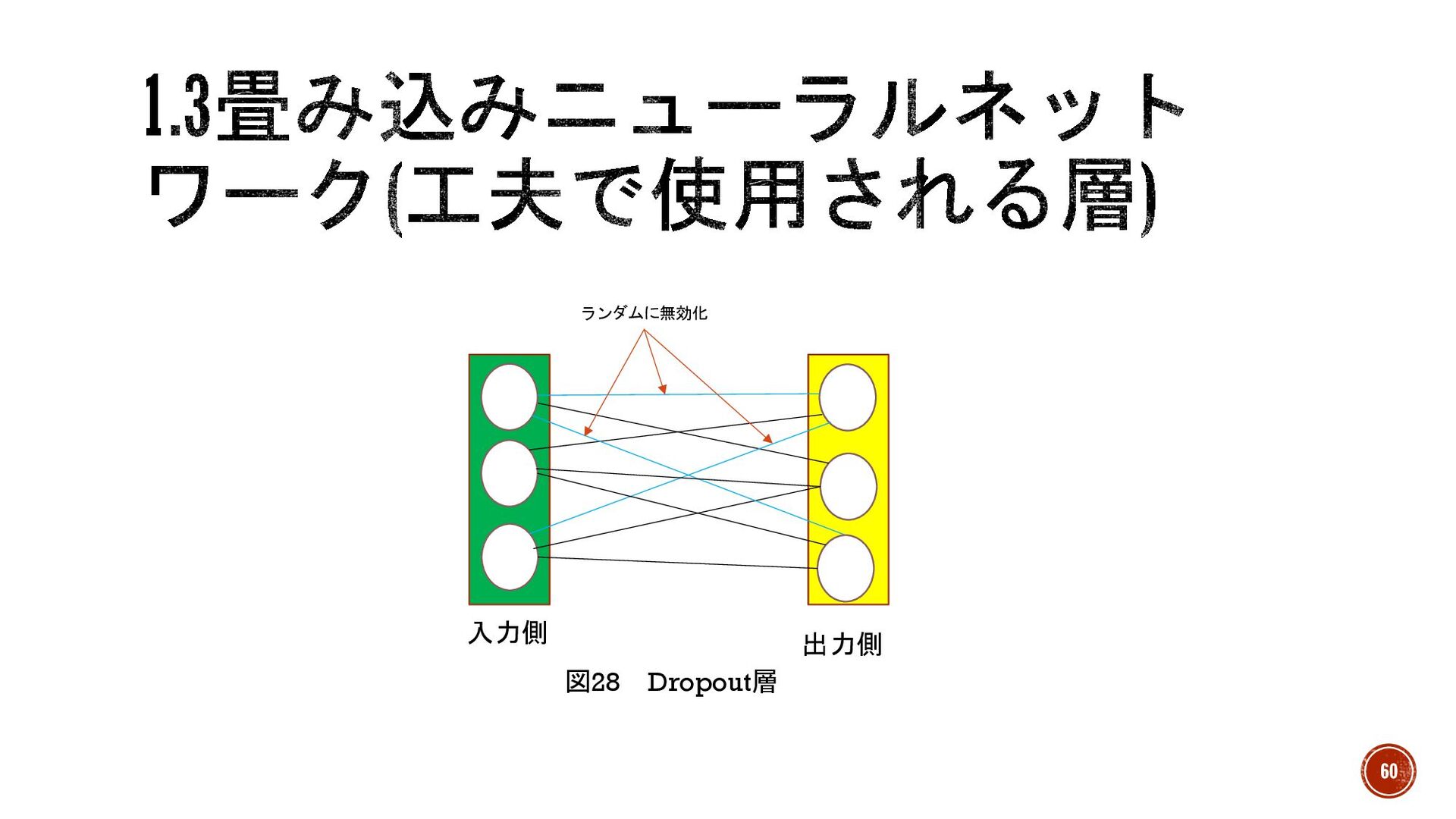
§ 層が増えすぎたりすると過学習が起こりやすくなる。そこで解決するために誕生した 層を2つ紹介 § Dropout層(ドロップアウト層) →ランダムにノードを無効化することで、強制的に遊びを作る層。過学習の原因の1 つである学習したデータに完全にフィットすることを防ぎます。無効化するノードは この層を通るたびに一定の割合でランダムに決定。 59
図28 Dropout層 入力側 出力側 ランダムに無効化 60
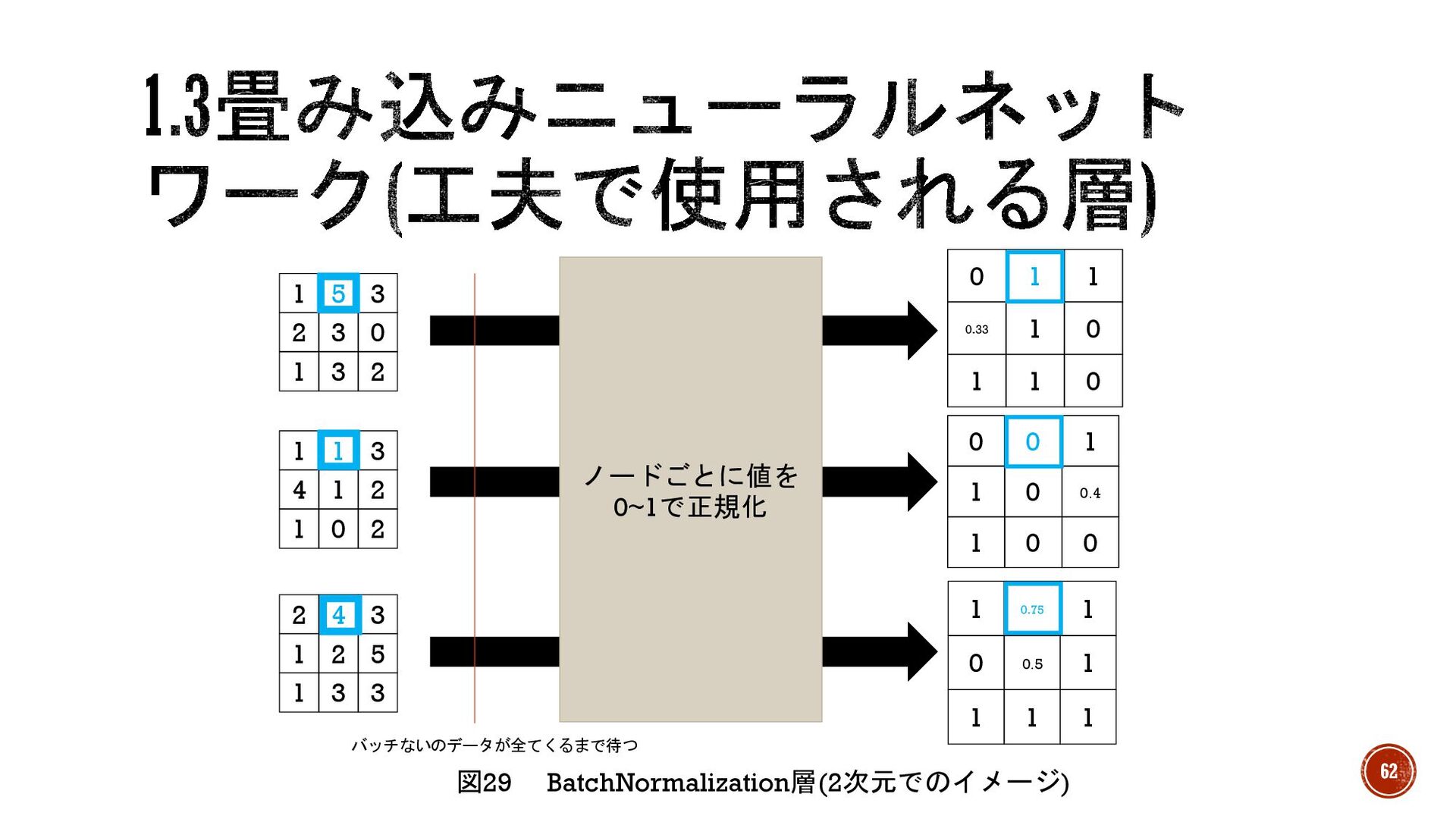
§ BatchNormalization層(バッチ正規化バッチ層) →学習が不安定になる(振動する)のを防ぐ層。バッチ単位で受け取った値を正規化する ことで変化を一定の範囲に落とし込み、学習を安定させる。 ※1. 入力ノードに近い層(浅い層)は出力ノードに近い層(深い層)より出力に影響を与え るため、浅い層の変化に深い層が振り回されることが起きる。 § 正規化 →データを互いに比較できるように変形する。
※2. 正規化により勾配消失も抑制するので学習の度合いが進み、結果的に学習時間を 短縮する。 61
0.33 1 0 0 1 1 1 1 0 2
3 0 1 5 3 1 3 2 4 1 2 1 1 3 1 0 2 1 2 5 2 4 3 1 3 3 0 0.5 1 1 0.75 1 1 1 1 1 0 0.4 0 0 1 1 0 0 ノードごとに値を 0~1で正規化 バッチないのデータが全てくるまで待つ 図29 BatchNormalization層(2次元でのイメージ) 62
§ CNN →ニューラルネットワークの構造の種類の中で特に画像処理で非常に強力な力を発揮 する。ネットワークの構造にConvolution層を使用してるもの全般を指す。基本となる 構造は図30のようにConvolution層を2回入れた後Pooling層を1つ入れるのを繰り返 す。特に2つ目のConvolution層ではパディングを入れ、Pooling層にはMaxPooling層 を入れることが多い。 § Convolutionブロック →
Convolution層2つと後Pooling層1つを1つのブロックとしたもの。 63
CV CV Pooling CV CV Pooling CV CV Pooling …
図30 CNNの基本構造 Convolutionブロック 64
§ モデル →ニューラルネットワークにおけるネットワークの構造。 § 学習済みモデル →学習し終わった重みが適用されたニューラルネットワーク。 § タスク →問題や質問、利用可能なデータに基づいて行われる予測または推論の種類。 65
§ タスクを見てみる § 分類(Classification) →対象物を決められた種類(クラス)を振り分けるタスク。様々な分野で行われ、使用さ れるモデルが多く存在。モデルで有名なのはVGG、ResNet。 § 異常検知(Anomaly Detection) →対象が異常な状態かどうかを判定するタスク。正常な状態を学習し、推論時にその
政情からずれている点が多いときに異常と判断。使用される有名なモデルは AutoEncoder、AnoGAN。 66
§ 物体検出(Object Detection) →画像内のどの位置にどのような物体が存在するかを検出するタスク。物体検知とも いう。使用される有名なモデルはSSD、Faster R-CNN、YOLO。 § 領域検出(Segmentation) →画像内の対象物の領域を検出するタスク。対象物の種類ごと色を塗った形で表現さ れることが多い。使用される有名なモデルはU-Net、PSPNet、DeepLab、Mask
R- CNN。 67
§ その他のタスクを見る § 画像生成 →画像を新しく生成するタスク。近年で使われるモデルとしてGAN(より本物に近い画 像を生成するためのモデル)をベースにしている。 § 深度推定 →2Dである画像から深度(奥行き)を推定し、擬似的に3Dにしたり、対象物の分離を 行ったりするタスク。センサー技術を合わせたARCoreなどを使用し、推定するが過去
の画像を利用する場合などはこのモデルを使用。 68
§ ポーズ推定 →人間と動物の関節に注目し、関節とそのつながりを画像から予測することで対象物 のポーズを認識するタスク。関節以外にも顔のパーツに注目し、顔の位置や向きを検 出し居眠りの検知を行うことも可能。モデルで有名なのはOpenPose。 § ORC(Optical Character Recognition/Reader) →文字認識を行うタスク。日本語で光学的文字認識。ディープラーニングを用いるこ
とで精度が向上し、手書き文字の認識によく用いられる。 69
演習問題を用意する予定でしたが間に合わず、申し訳 ありません。後日出来次第connpassに投稿するので お願いします!🙇 70
{kind=link}
{kind=link}
{kind=link}
![§ 即戦力になるための ディープラーニング開発実践ハンズオン § [著]井上大樹、佐藤峻 § 価格:3280円(税抜) § リンク: https://gihyo.jp/book/2021/978-4-297-11942-3](https://files.speakerdeck.com/presentations/3bcc992ce98d432bafde047a1b6ff0eb/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}