RCU has seen lots of changes in the last 2 years. Of note is the RCU flavor consolidation and tree RCU’s lock contention improvements. There have been also improvements with static checking, fixes to scheduler deadlocks and improvements to RCU-based linked lists. This talk starts with an introduction of RCU along with presenting the recent Improvements and changes in RCU’s behavior.
Joël Fernandes, Google
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
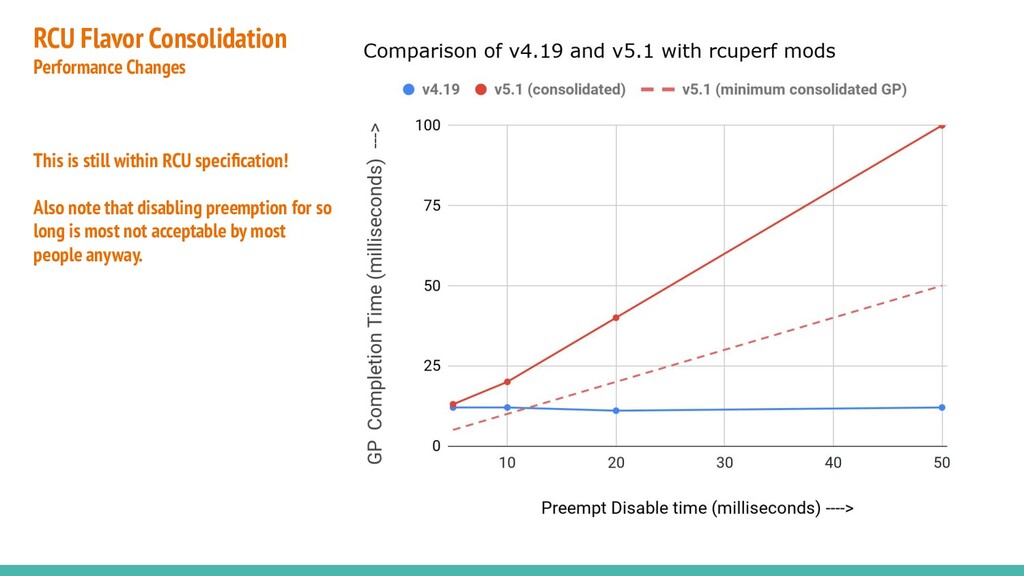{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
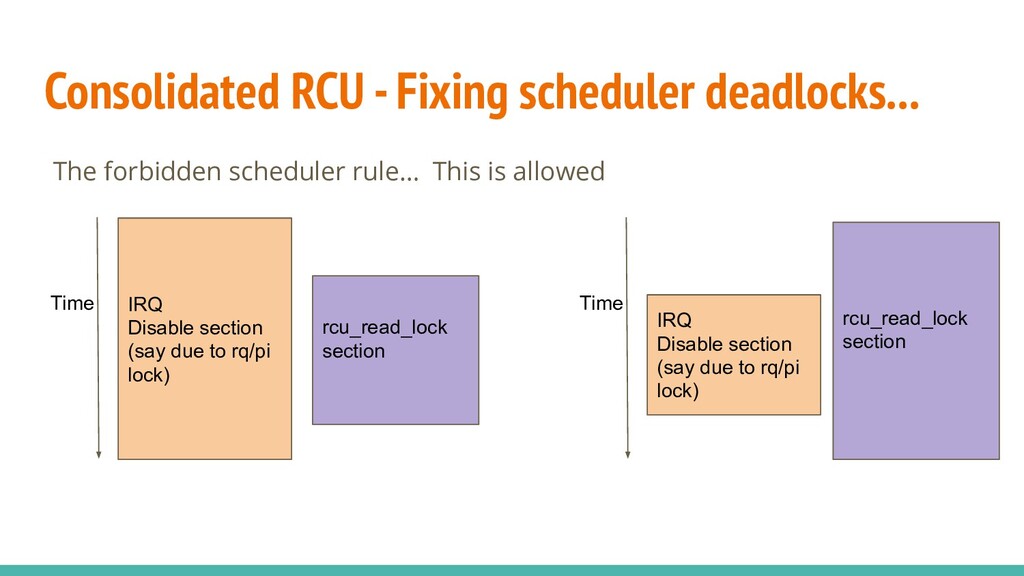{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![List RCU usage - hardening Patches: https://lore.kernel.org/lkml/[email protected]/T/#t https://lore.kernel.org/patchwork/project/lkml/list/?series=401865 Next steps:](https://files.speakerdeck.com/presentations/cf05259261c142548820ed20d936c513/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
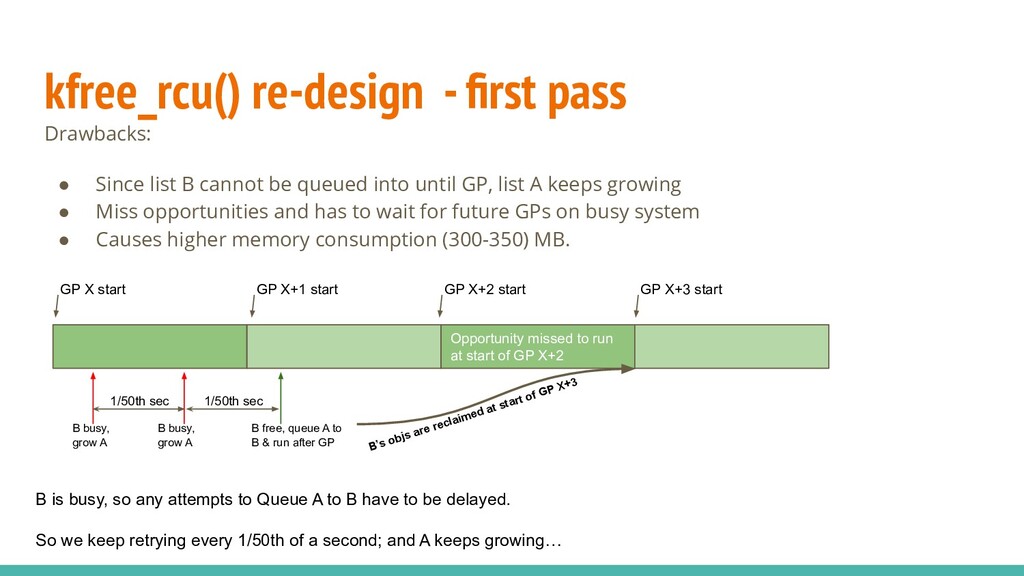{kind=link}
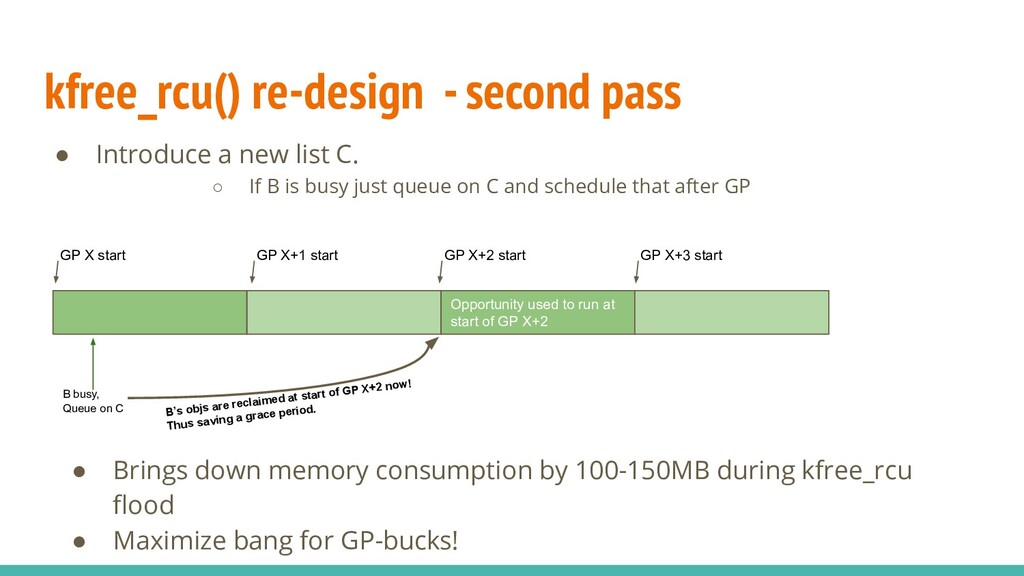{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}