in a Marketplace [Multi-objective Methods] Rishabh Mehrotra Ben Carterette Senior Research Scientist, Senior Research Manager, Spotify, London Spotify, New York [email protected][email protected] 23rd August 2020 @erishabh @BenCarterette https://sites.google.com/view/kdd20-marketplace-autorecsys/
in a Marketplace Rishabh Mehrotra Ben Carterette Senior Research Scientist, Senior Research Manager, Spotify, London Spotify, New York [email protected][email protected] 23rd August 2020 @erishabh @BenCarterette https://sites.google.com/view/kdd20-marketplace-autorecsys/ Break: back at 10:10 AM PST
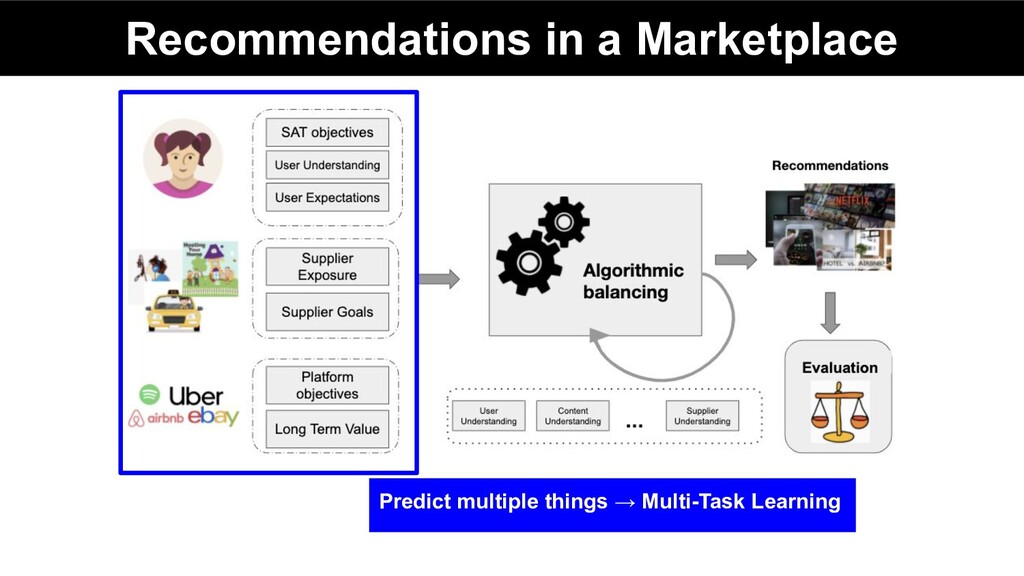
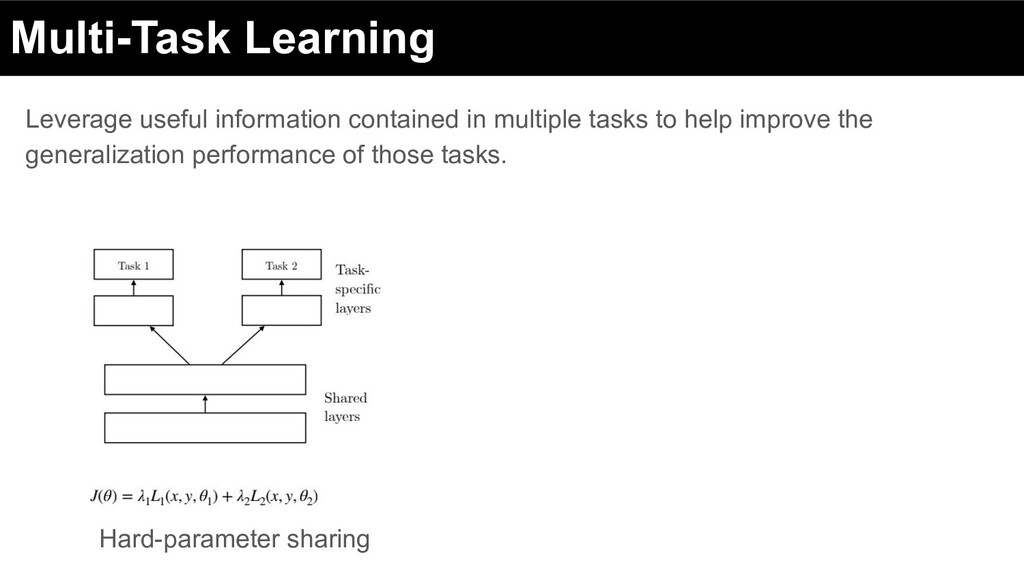
catered towards user-centric modeling - Multiple stakeholders in online marketplaces - Need to consider multiple objectives + ML models to optimize those objectives
online marketplaces - different industrial case-studies - UberEats, Postmates, Etsy, AirBnb, Music, P2P lending, Crowdfunding - Multiple, often conflicting objectives - +vely correlated, neutral, -vely correlated - ML methods needed to model the interplay between objectives - Important to carefully decide what a system optimizes for
Marketplace 3. Methods for Multi-Objective Ranking & Recommendations a. Pareto optimality b. Multi-objective models i. Multi-task Learning ii. Scalarization iii. Multi-objective bandits iv. Multi-objective RL 4. Leveraging Consumer, Supplier & Content Understanding 5. Industrial Applications
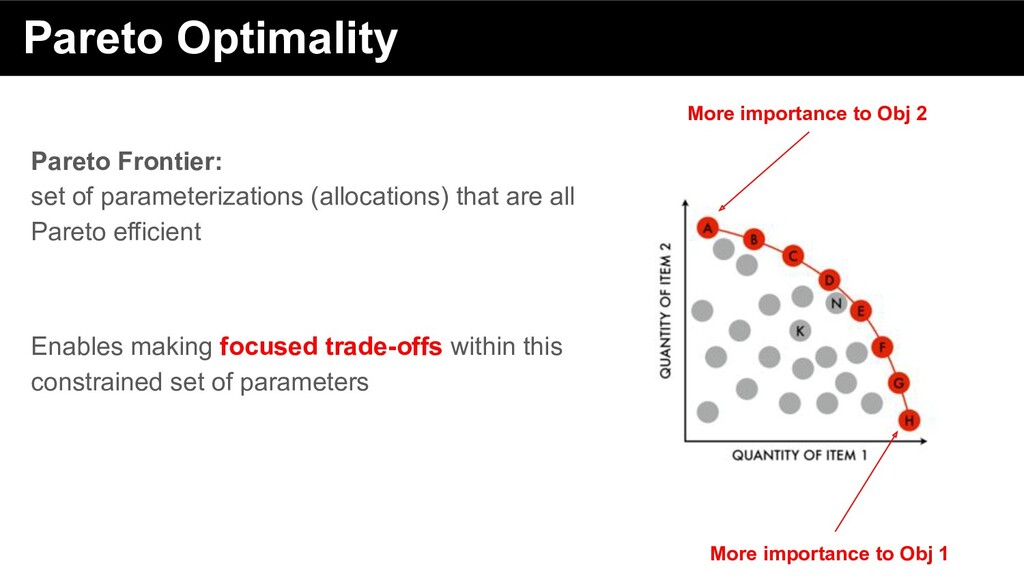
efficient manner - does not imply equality or fairness ... an economic state where resources cannot be reallocated to make one individual better off without making at least one individual worse off. Pareto Optimality Pareto Frontier: - set of parameterizations (allocations) that are all Pareto efficient
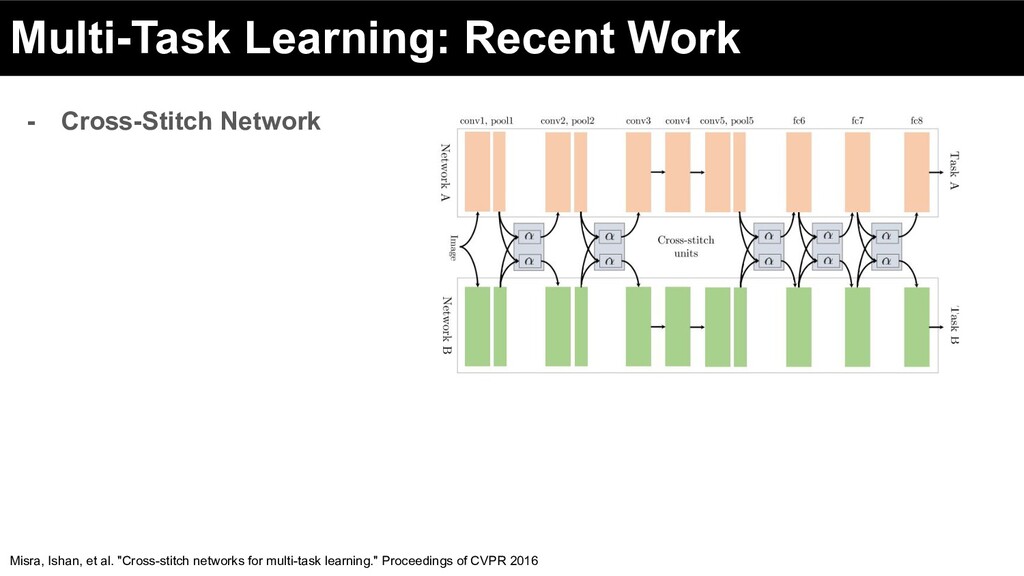
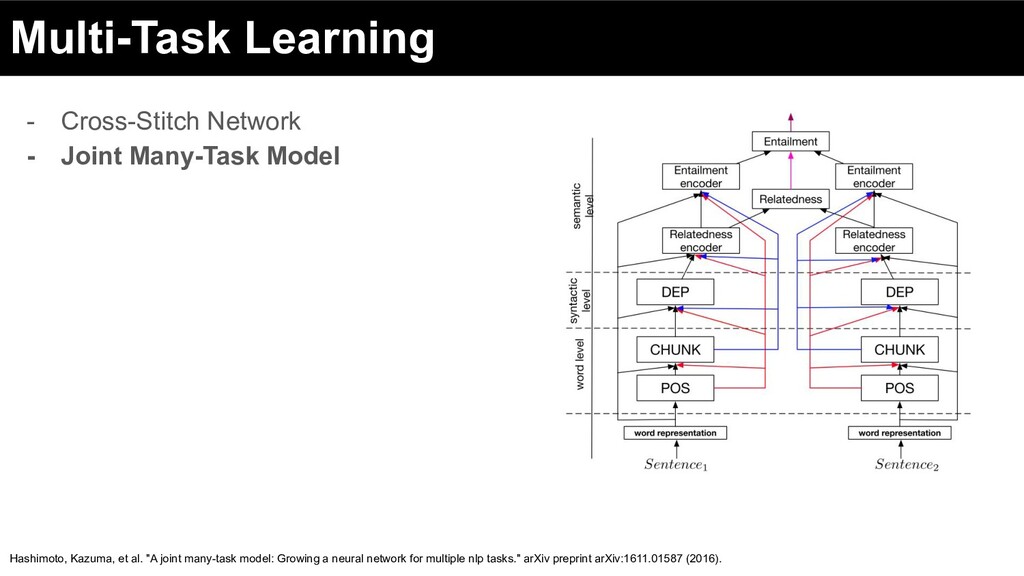
Marketplace 3. Methods for Multi-Objective Ranking & Recommendations a. Pareto optimality b. Multi-objective models i. Multi-task Learning ii. Scalarization iii. Multi-objective bandits iv. Multi-objective RL 4. Leveraging Consumer, Supplier & Content Understanding 5. Industrial Applications
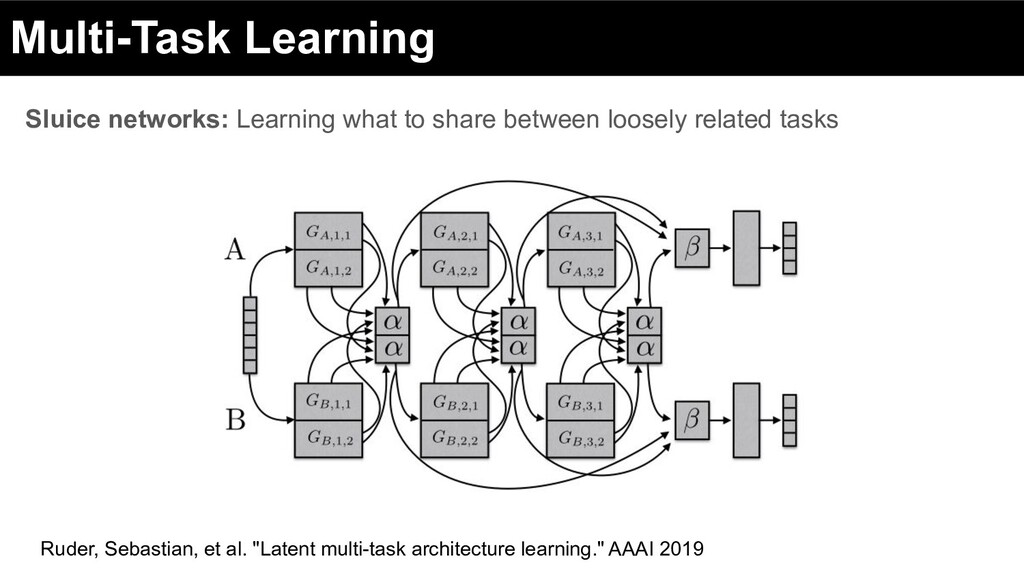
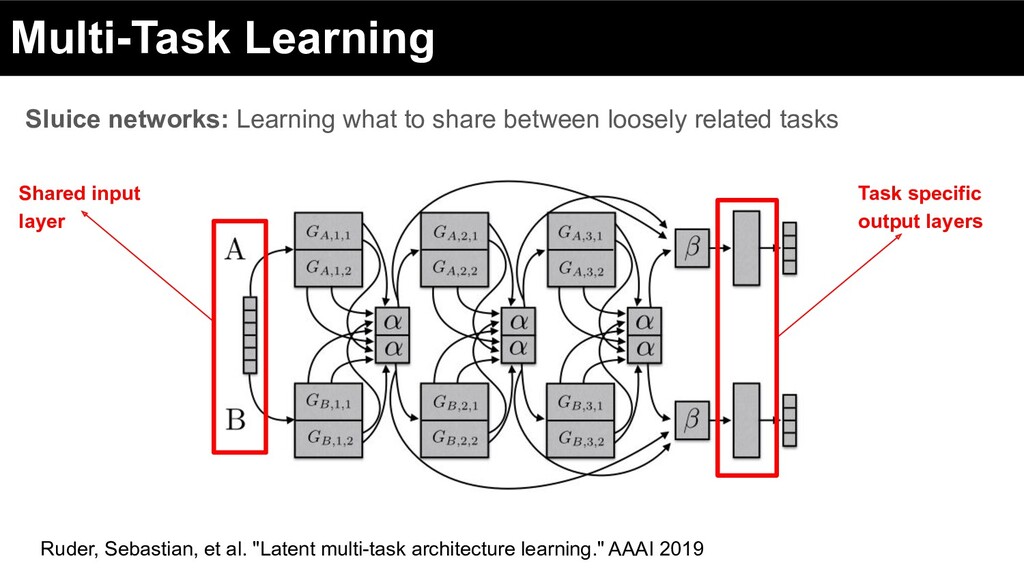
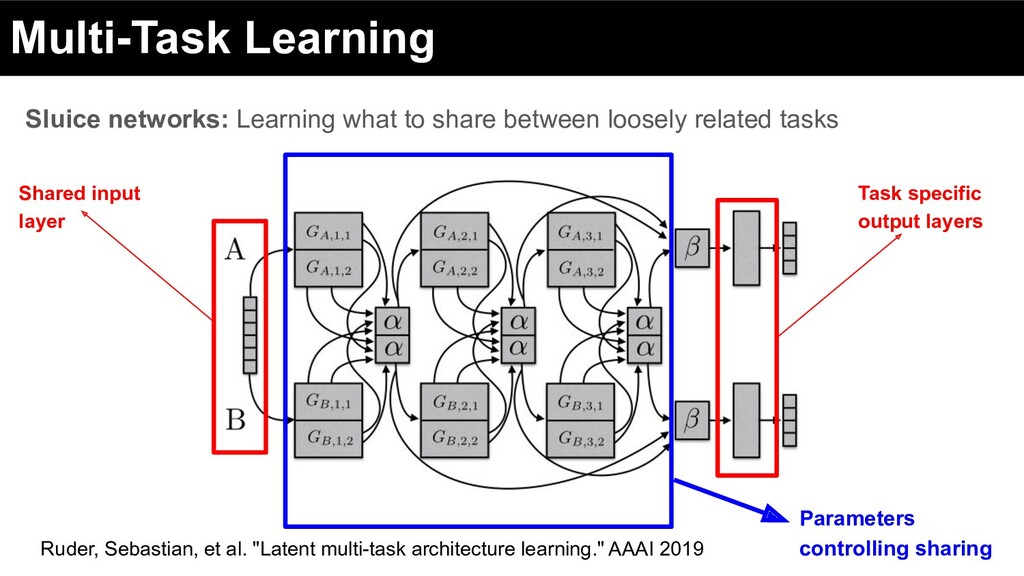
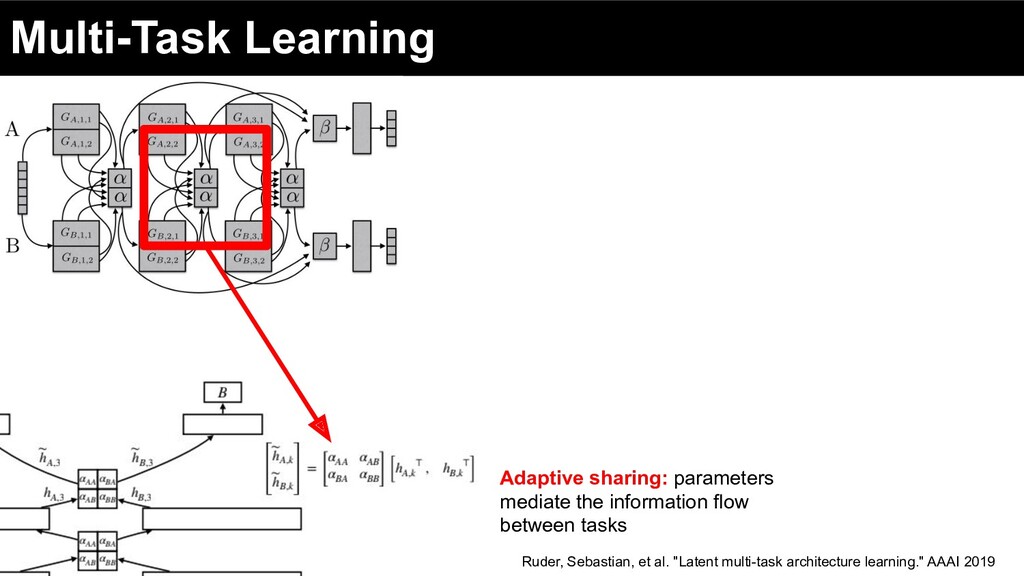
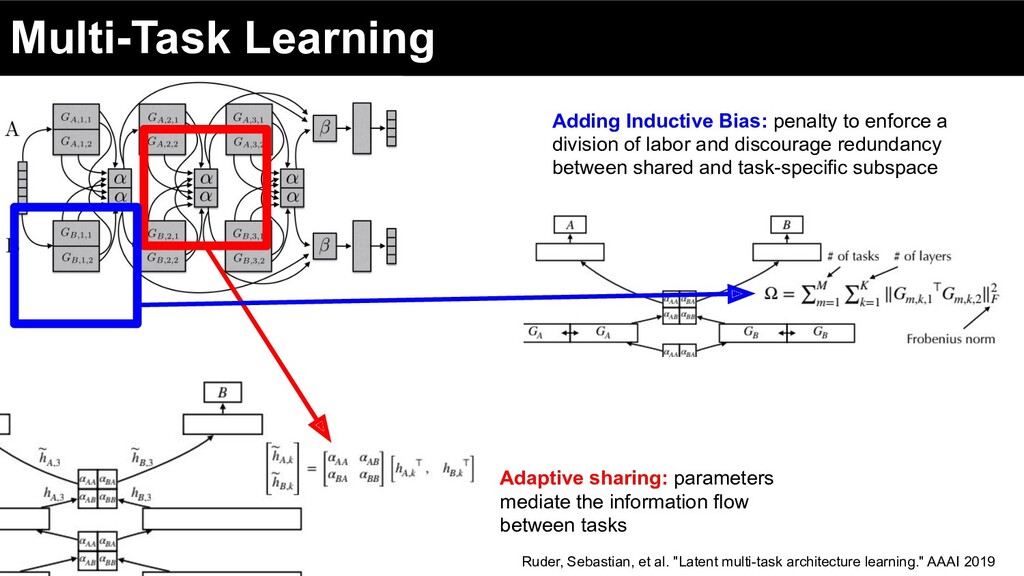
of labor and discourage redundancy between shared and task-specific subspace Adaptive sharing: parameters mediate the information flow between tasks Ruder, Sebastian, et al. "Latent multi-task architecture learning." AAAI 2019
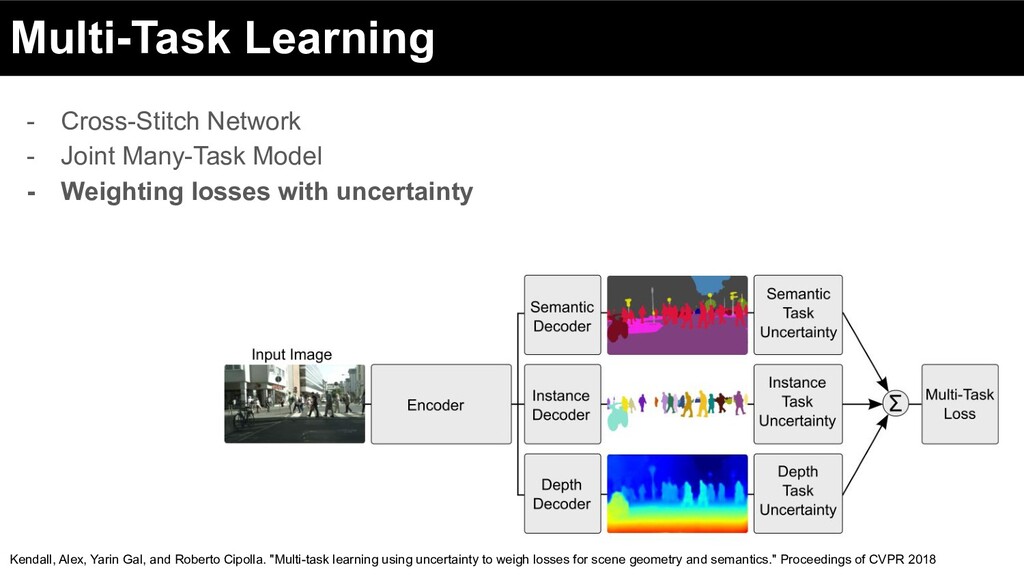
Weighting losses with uncertainty Kendall, Alex, Yarin Gal, and Roberto Cipolla. "Multi-task learning using uncertainty to weigh losses for scene geometry and semantics." Proceedings of CVPR 2018
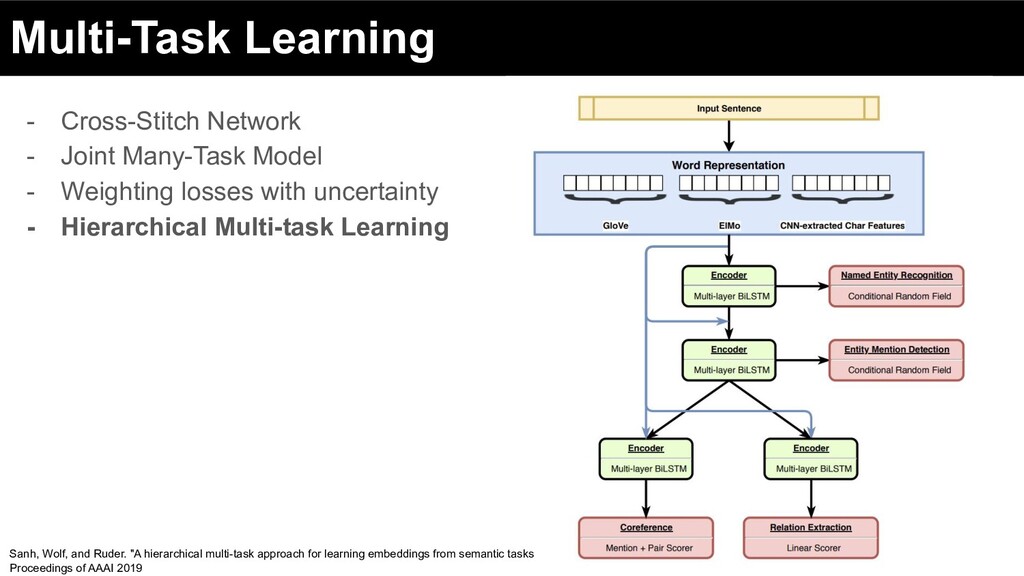
Weighting losses with uncertainty - Hierarchical Multi-task Learning Sanh, Wolf, and Ruder. "A hierarchical multi-task approach for learning embeddings from semantic tasks Proceedings of AAAI 2019
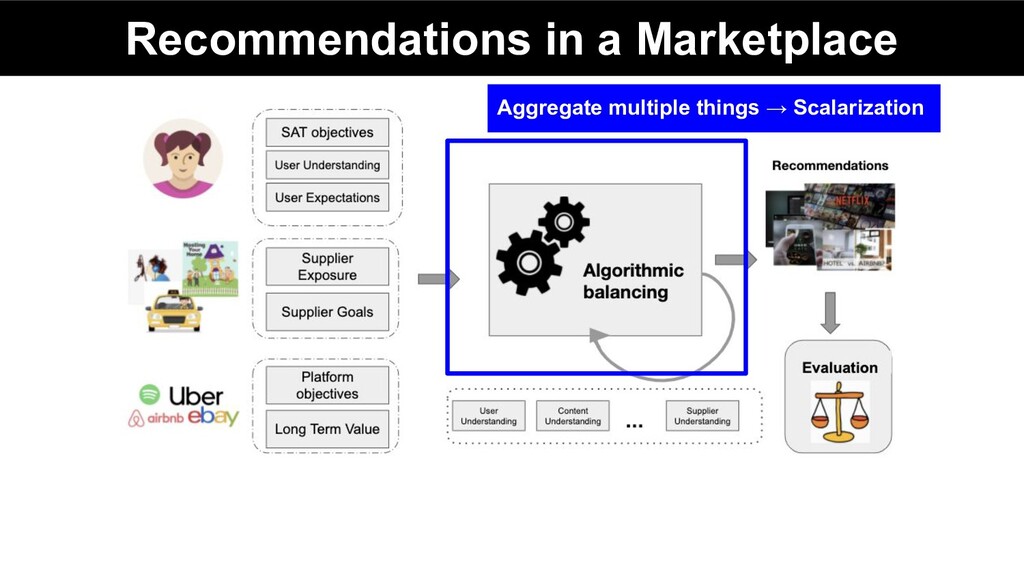
function, allows every vector to receive a scalar value to be optimized Different aggregation function can be used depending on the problem at hand: • Sum • Weighted sum • Min, Max • (augmented) weighted Chebyshev norm (Steuer & Choo, 1983) • Ordered Weighted Averages (OWA) (Yager, 1988) • Ordered Weighted Regret (OWR) (Ogryczak et al., 2011)
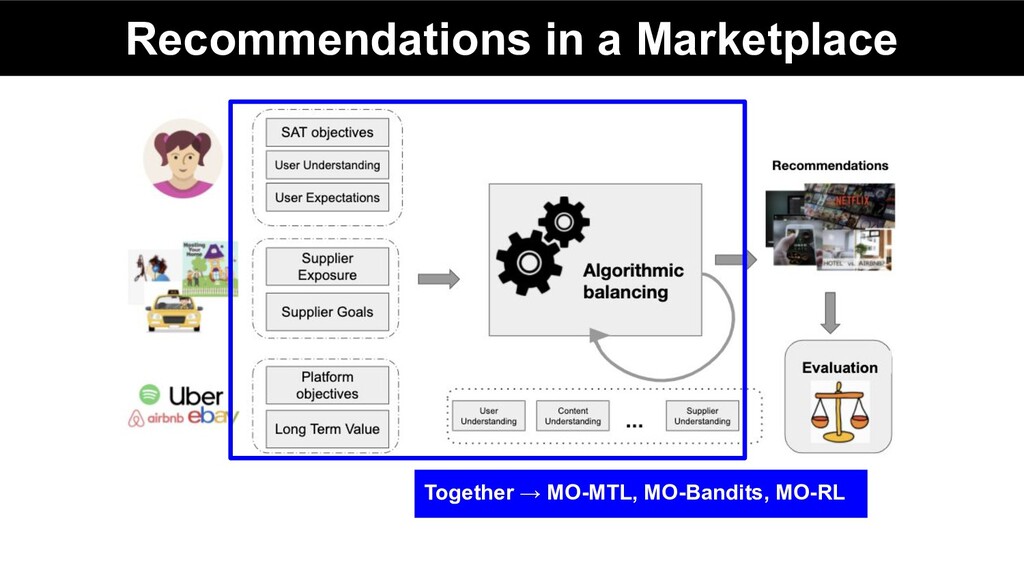
Marketplace 3. Methods for Multi-Objective Ranking & Recommendations a. Pareto optimality b. Multi-objective models i. Multi-task Learning ii. Scalarization iii. Multi-objective Multi-Task Learning iv. Multi-objective bandits v. Multi-objective RL 4. Leveraging Consumer, Supplier & Content Understanding 5. Industrial Applications
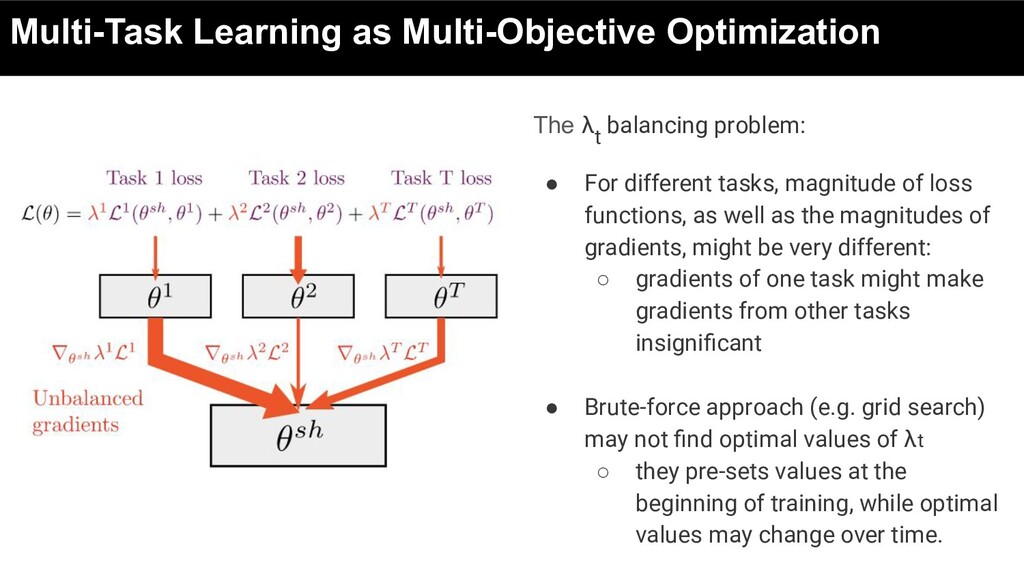
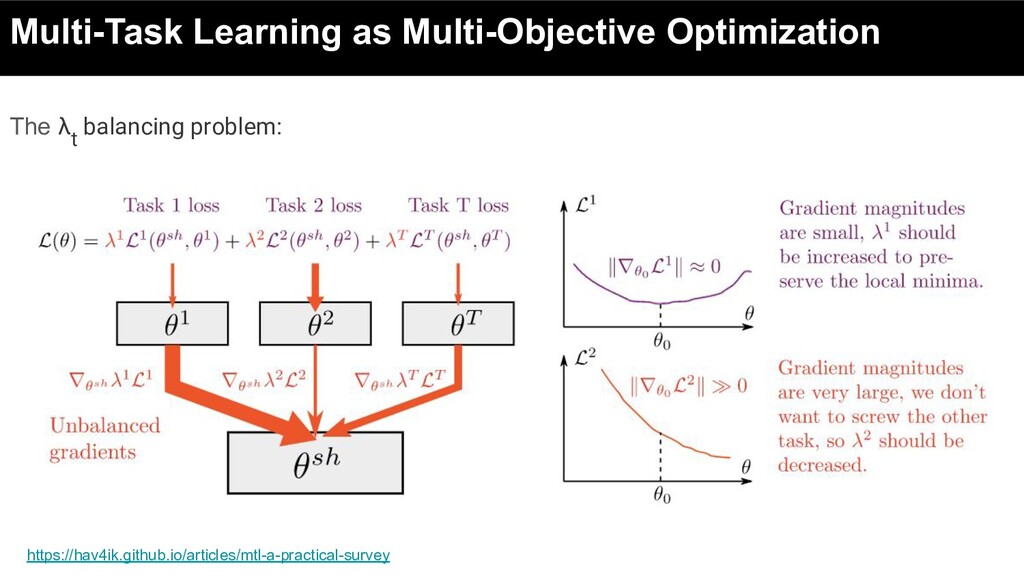
network parameters shared between tasks θt : task-specific parameters where Lt(.) is an empirical task-specific loss for t-th task defined as the average loss across the whole dataset
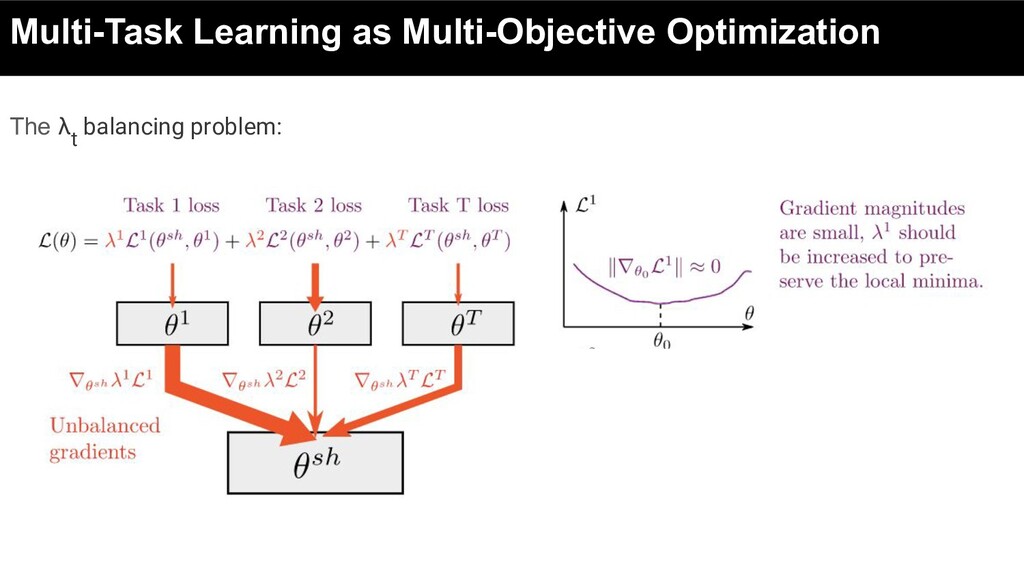
• For different tasks, magnitude of loss functions, as well as the magnitudes of gradients, might be very different: ◦ gradients of one task might make gradients from other tasks insignificant • Brute-force approach (e.g. grid search) may not find optimal values of λt ◦ they pre-sets values at the beginning of training, while optimal values may change over time.
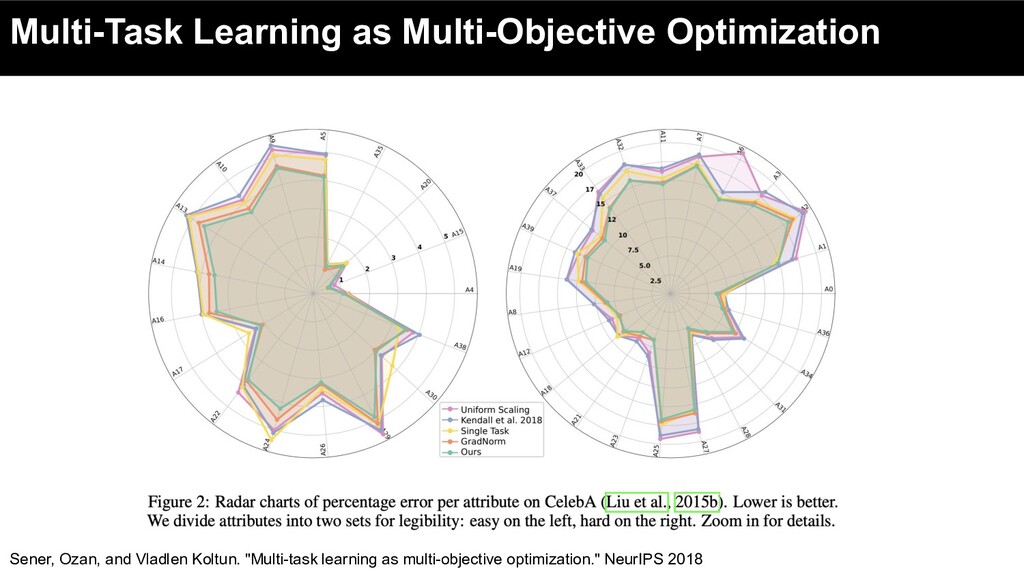
summation objective: ◦ consider MTL problem from the perspective of multi-objective optimization: ▪ optimizing a collection of possibly conflicting objectives. Sener, Ozan, and Vladlen Koltun. "Multi-task learning as multi-objective optimization." NeurIPS 2018
summation objective: ◦ consider MTL problem from the perspective of multi-objective optimization: ▪ optimizing a collection of possibly conflicting objectives. • The MTL objective is then specified using a vector-valued loss L : Sener, Ozan, and Vladlen Koltun. "Multi-task learning as multi-objective optimization." NeurIPS 2018
Marketplace 3. Methods for Multi-Objective Ranking & Recommendations a. Pareto optimality b. Multi-objective models i. Multi-task Learning ii. Scalarization iii. Multi-objective Multi-Task Learning iv. Multi-objective bandits v. Multi-objective RL 4. Leveraging Consumer, Supplier & Content Understanding 5. Industrial Applications
Szörényi, Weng, and Mannor. Multiobjective Bandits: Optimizing the Generalized Gini Index. In ICML 2017 II. Tekin and Turğay. Multi-objective contextual multi-armed bandit with a dominant objective. IEEE Transactions on Signal Processing (2018) III. Turğay, Öner, and Tekin. Multi-objective contextual bandit problem with similarity information. AISTATS 2018 IV. Mehrotra, Xue, and Lalmas. Multi-objective Linear Contextual Bandits via Generalised Gini Function. KDD 2020
Szörényi, Weng, and Mannor. Multiobjective Bandits: Optimizing the Generalized Gini Index. In ICML 2017 II. Tekin and Turğay. Multi-objective contextual multi-armed bandit with a dominant objective. IEEE Transactions on Signal Processing (2018) III. Turğay, Öner, and Tekin. Multi-objective contextual bandit problem with similarity information. AISTATS 2018 IV. Mehrotra, Xue, and Lalmas. Multi-objective Linear Contextual Bandits via Generalised Gini Function. KDD 2020
of Ordered weighted averaging → preserves impartiality w.r.t. individual criterion - Respects Pigou-Dalton transfer: prefer allocations that are more equitable
arm selection strategy ◦ probability distribution based on which a recommendation is selected • For a bandit instance at round t, we are given features with
arm selection strategy ◦ probability distribution based on which a recommendation is selected • For a bandit instance at round t, we are given features with • If we choose arm k, we observe linear reward where
arm selection strategy ◦ probability distribution based on which a recommendation is selected • For a bandit instance at round t, we are given features with • If we choose arm k, we observe linear reward where • If vectorial mean feedback for each arm is known: ◦ Find optimal arm via full sweep
arm selection strategy ◦ probability distribution based on which a recommendation is selected • For a bandit instance at round t, we are given features with • If we choose arm k, we observe linear reward where • If vectorial mean feedback for each arm is known: ◦ Find optimal arm via full sweep • But its not known, its context dependent ◦ Optimal policy given by:
single policy that optimises a combinations of the rewards ◦ Which reward combination is preferable at which state? • Pareto approach: ◦ Find multiple policies that cover the Pareto front: Sampling in a high-dimensional case
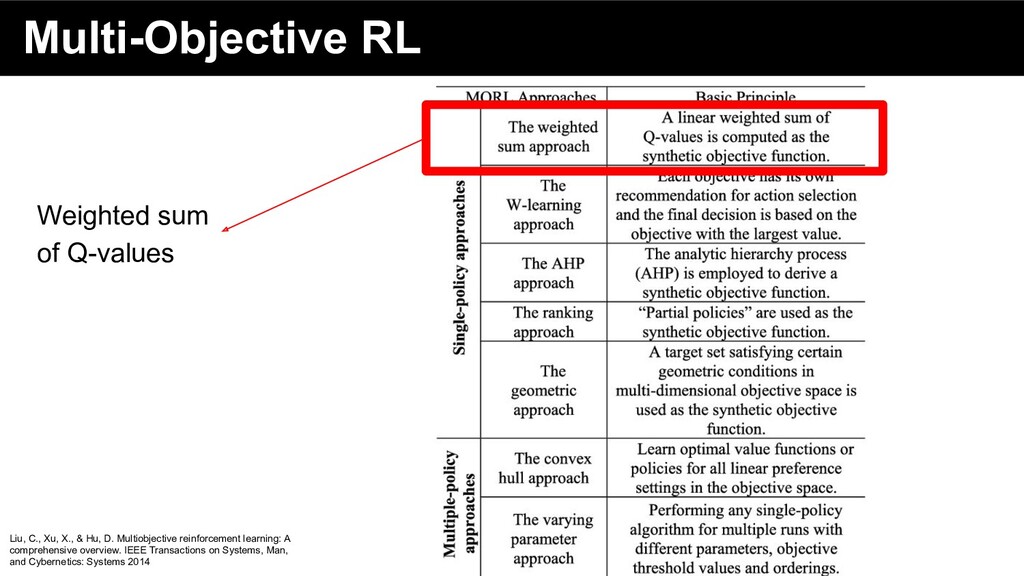
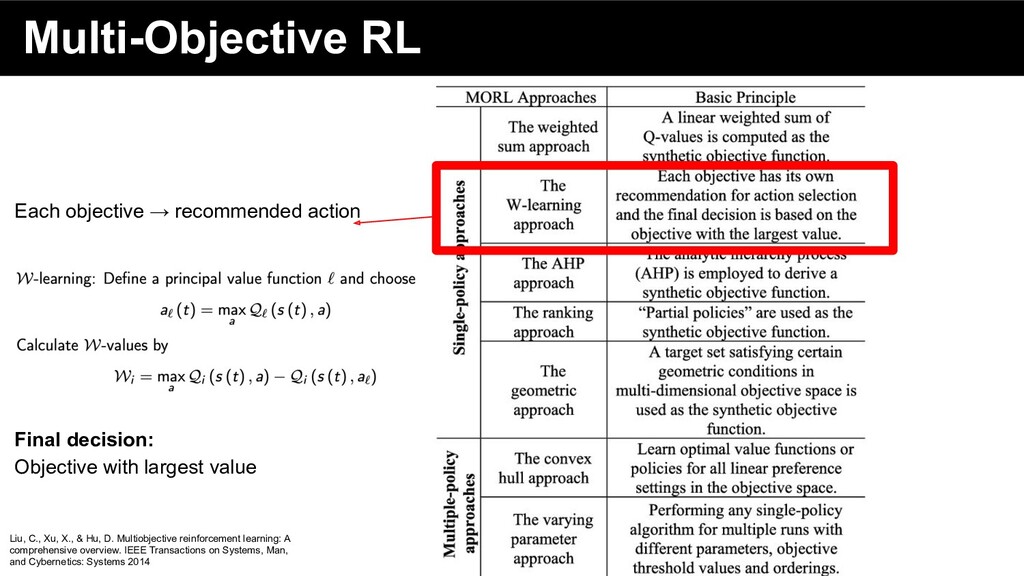
reinforcement learning: A comprehensive overview. IEEE Transactions on Systems, Man, and Cybernetics: Systems 2014 Single Policy approach Multiple Policy approach
reinforcement learning: A comprehensive overview. IEEE Transactions on Systems, Man, and Cybernetics: Systems 2014 Each objective → recommended action Final decision: Objective with largest value
reinforcement learning: A comprehensive overview. IEEE Transactions on Systems, Man, and Cybernetics: Systems 2014 Ranking: • Define an ordering of rewards • check low-priority rewards only if decision is not possible by high-priority rewards
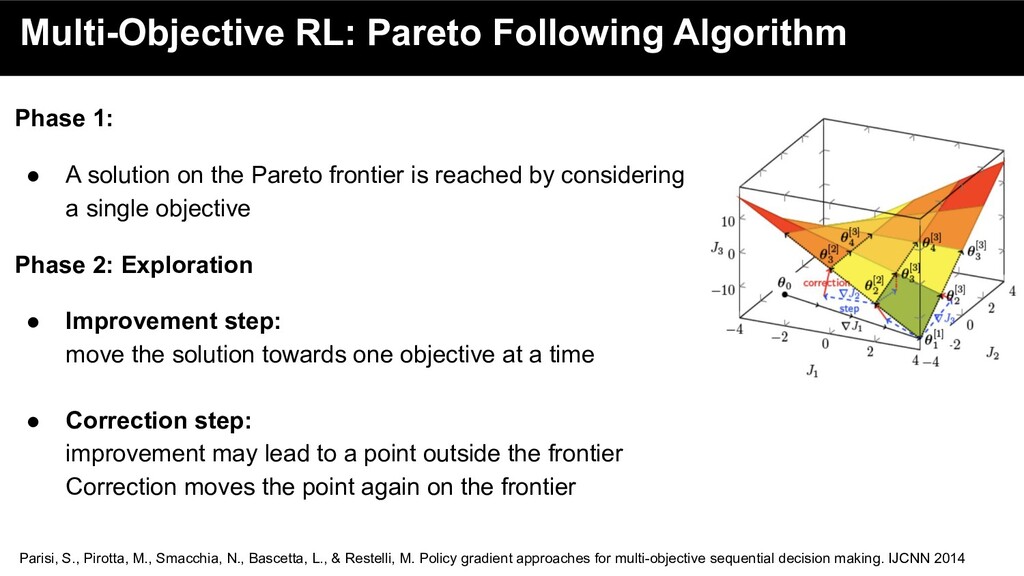
on the Pareto frontier is reached by considering a single objective Parisi, S., Pirotta, M., Smacchia, N., Bascetta, L., & Restelli, M. Policy gradient approaches for multi-objective sequential decision making. IJCNN 2014
on the Pareto frontier is reached by considering a single objective Phase 2: Exploration • Improvement step: move the solution towards one objective at a time Parisi, S., Pirotta, M., Smacchia, N., Bascetta, L., & Restelli, M. Policy gradient approaches for multi-objective sequential decision making. IJCNN 2014
on the Pareto frontier is reached by considering a single objective Phase 2: Exploration • Improvement step: move the solution towards one objective at a time • Correction step: improvement may lead to a point outside the frontier Correction moves the point again on the frontier Parisi, S., Pirotta, M., Smacchia, N., Bascetta, L., & Restelli, M. Policy gradient approaches for multi-objective sequential decision making. IJCNN 2014
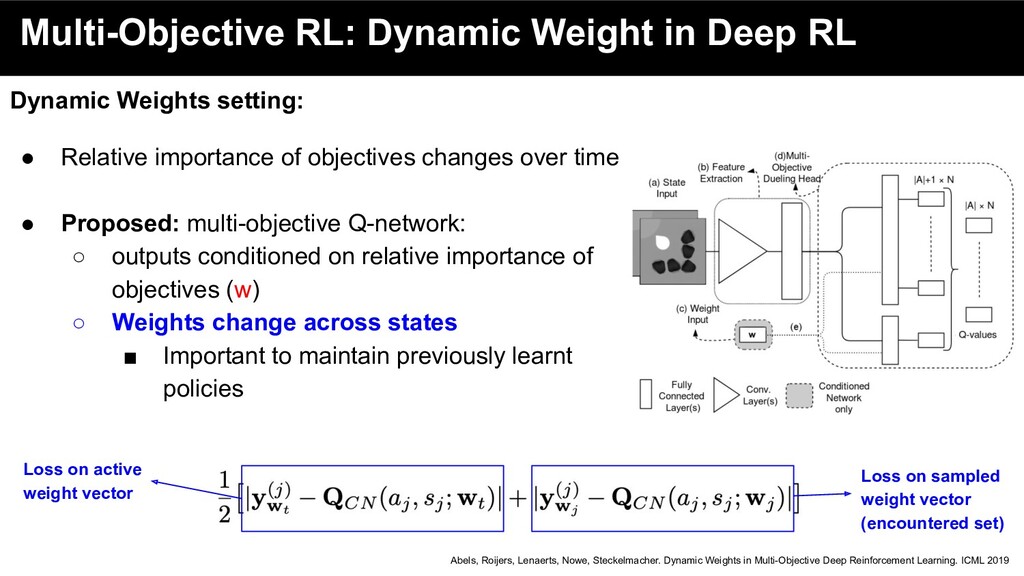
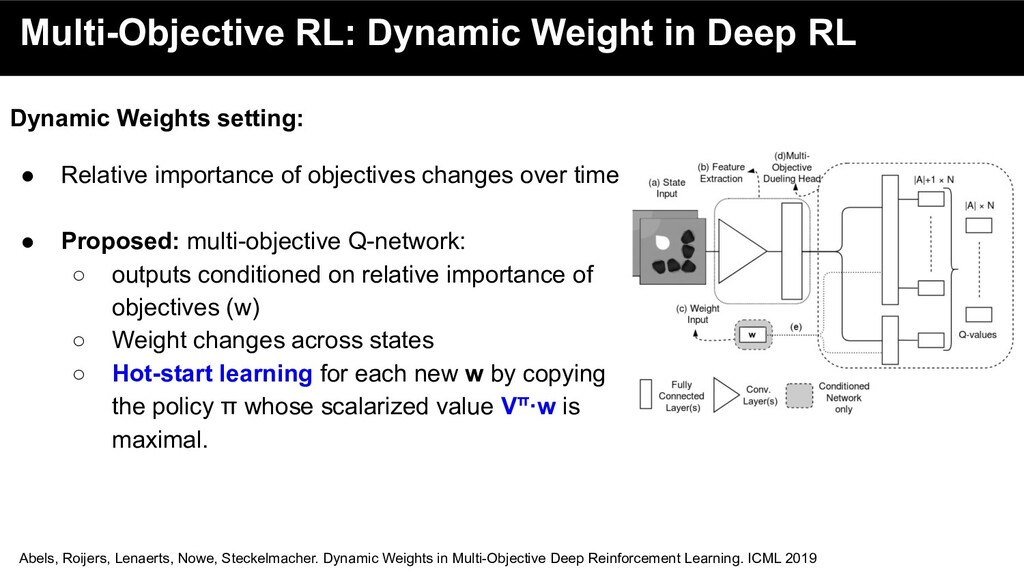
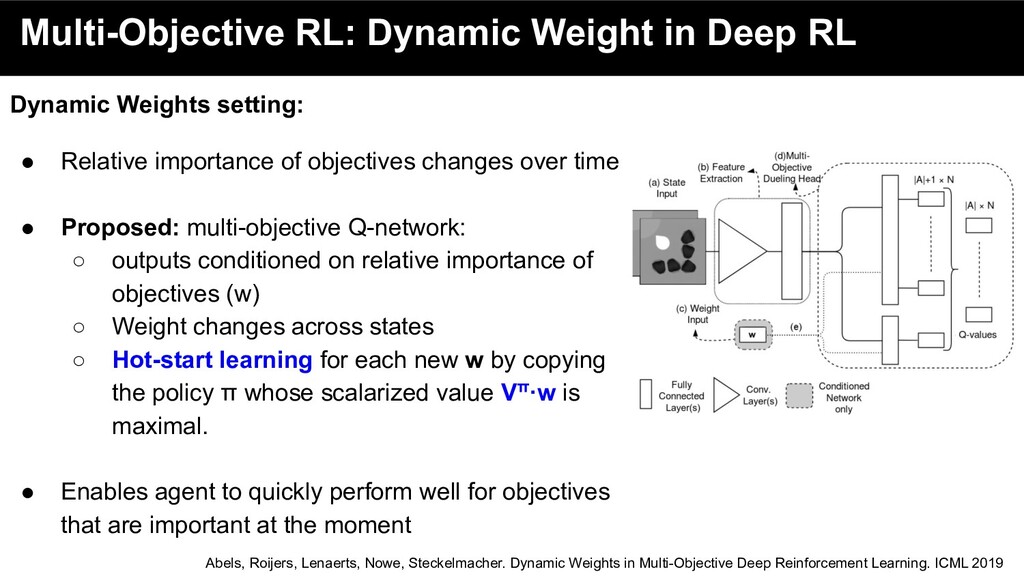
• Relative importance of objectives changes over time Abels, Roijers, Lenaerts, Nowe, Steckelmacher. Dynamic Weights in Multi-Objective Deep Reinforcement Learning. ICML 2019
• Relative importance of objectives changes over time Abels, Roijers, Lenaerts, Nowe, Steckelmacher. Dynamic Weights in Multi-Objective Deep Reinforcement Learning. ICML 2019 ICML 2019
• Relative importance of objectives changes over time • Proposed: multi-objective Q-network: ◦ outputs conditioned on relative importance of objectives (w) Abels, Roijers, Lenaerts, Nowe, Steckelmacher. Dynamic Weights in Multi-Objective Deep Reinforcement Learning. ICML 2019
• Relative importance of objectives changes over time • Proposed: multi-objective Q-network: ◦ outputs conditioned on relative importance of objectives (w) ◦ Weights change across states ▪ Important to maintain previously learnt policies Abels, Roijers, Lenaerts, Nowe, Steckelmacher. Dynamic Weights in Multi-Objective Deep Reinforcement Learning. ICML 2019
• Relative importance of objectives changes over time • Proposed: multi-objective Q-network: ◦ outputs conditioned on relative importance of objectives (w) ◦ Weights change across states ▪ Important to maintain previously learnt policies Abels, Roijers, Lenaerts, Nowe, Steckelmacher. Dynamic Weights in Multi-Objective Deep Reinforcement Learning. ICML 2019 Loss on active weight vector Loss on sampled weight vector (encountered set)
• Relative importance of objectives changes over time • Proposed: multi-objective Q-network: ◦ outputs conditioned on relative importance of objectives (w) ◦ Weight changes across states ◦ Hot-start learning for each new w by copying the policy π whose scalarized value Vπ·w is maximal. Abels, Roijers, Lenaerts, Nowe, Steckelmacher. Dynamic Weights in Multi-Objective Deep Reinforcement Learning. ICML 2019
• Relative importance of objectives changes over time • Proposed: multi-objective Q-network: ◦ outputs conditioned on relative importance of objectives (w) ◦ Weight changes across states ◦ Hot-start learning for each new w by copying the policy π whose scalarized value Vπ·w is maximal. • Enables agent to quickly perform well for objectives that are important at the moment Abels, Roijers, Lenaerts, Nowe, Steckelmacher. Dynamic Weights in Multi-Objective Deep Reinforcement Learning. ICML 2019
tutorial http://roijers.info/pub/slides_faim.pdf Multi-Objective Reinforcement Learning MORL Lecture Slide - RL course at Univ of Edinburgh http://www.inf.ed.ac.uk/teaching/courses/rl/slides16/rl16.pdf A Survey of Multi-Objective Sequential Decision-Making Journal of AI Research, 2013 https://arxiv.org/pdf/1402.0590.pdf Multiobjective Reinforcement Learning: A Comprehensive Overview. IEEE Transactions on Systems, Man, and Cybernetics, 2015 https://ieeexplore.ieee.org/abstract/document/6918520
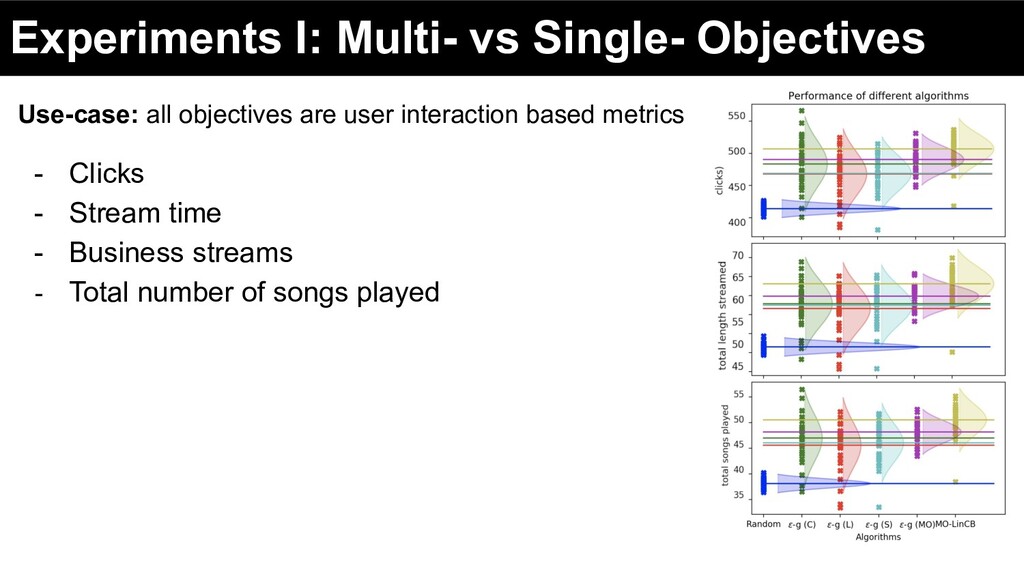
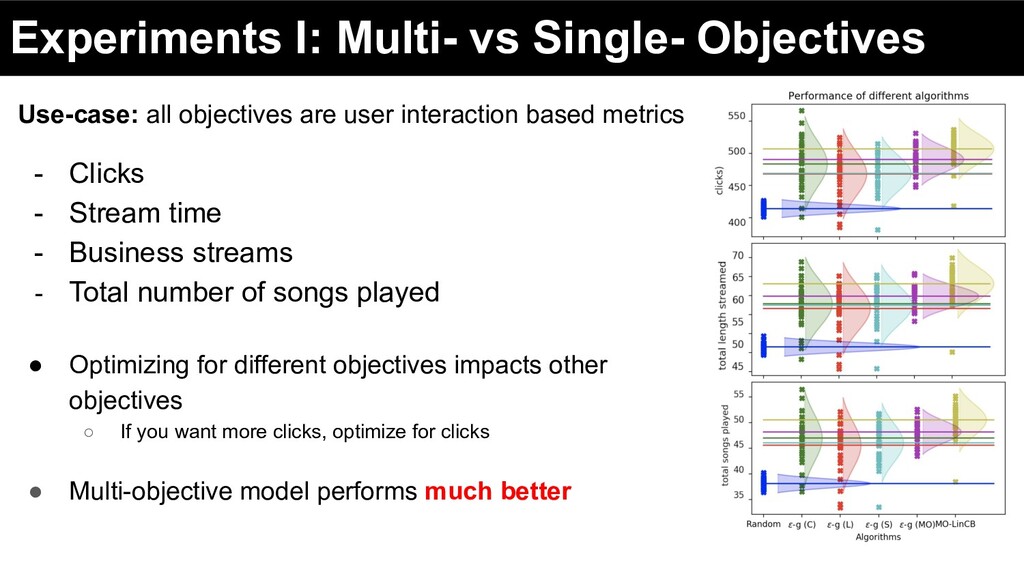
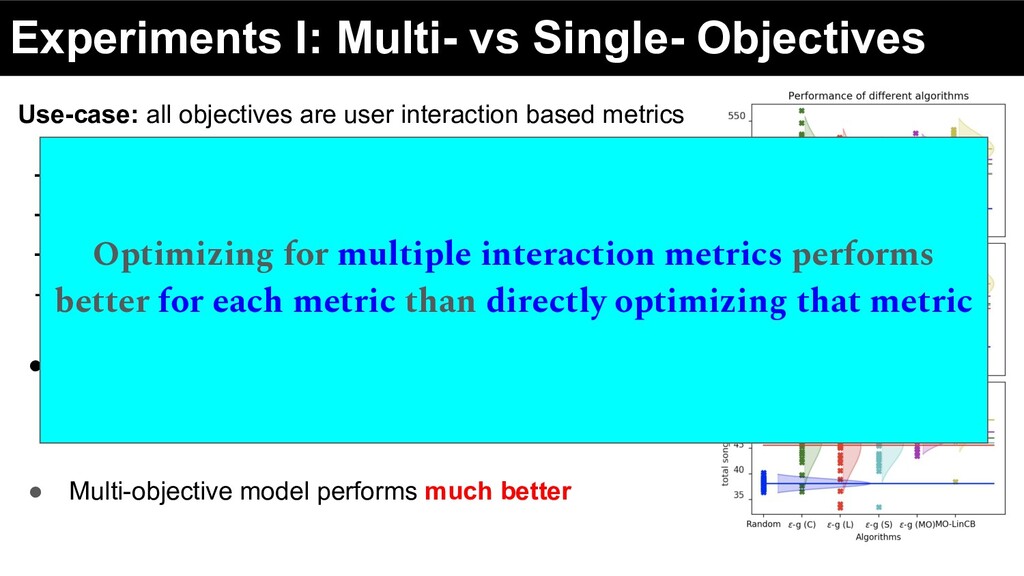
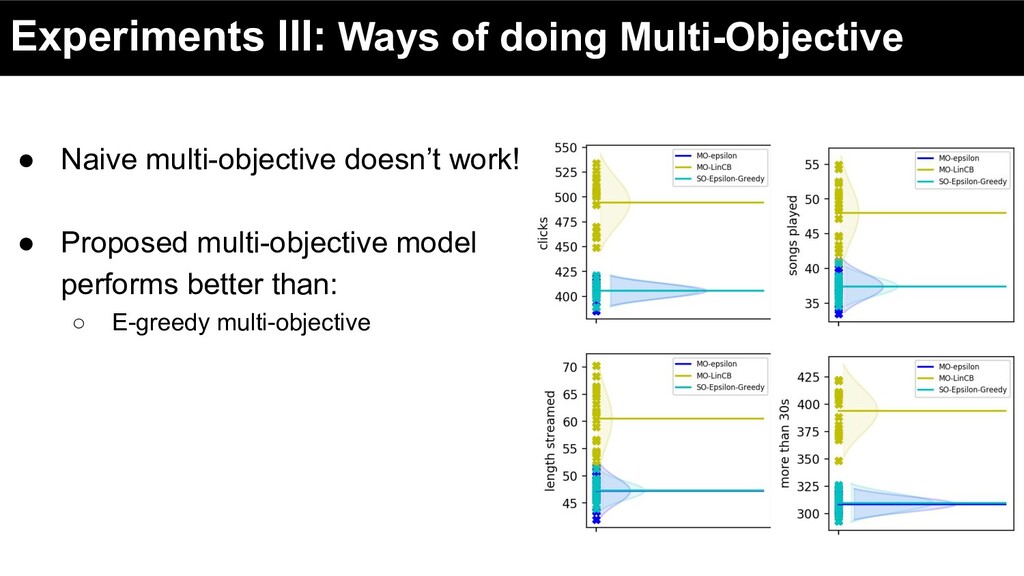
user interaction based metrics - Clicks - Stream time - Business streams - Total number of songs played • Optimizing for different objectives impacts other objectives ◦ If you want more clicks, optimize for clicks
user interaction based metrics - Clicks - Stream time - Business streams - Total number of songs played • Optimizing for different objectives impacts other objectives ◦ If you want more clicks, optimize for clicks • Multi-objective model performs much better
user interaction based metrics - Clicks - Stream time - Business streams - Total number of songs played • Optimizing for different objectives impacts other objectives ◦ If you want more clicks, optimize for clicks • Multi-objective model performs much better Optimizing for multiple interaction metrics performs better for each metric than directly optimizing that metric
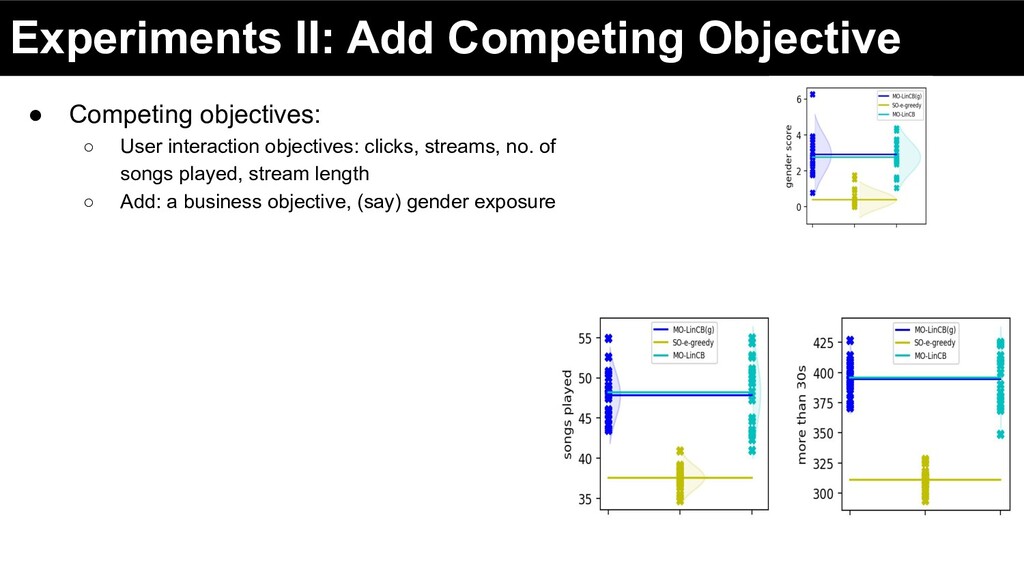
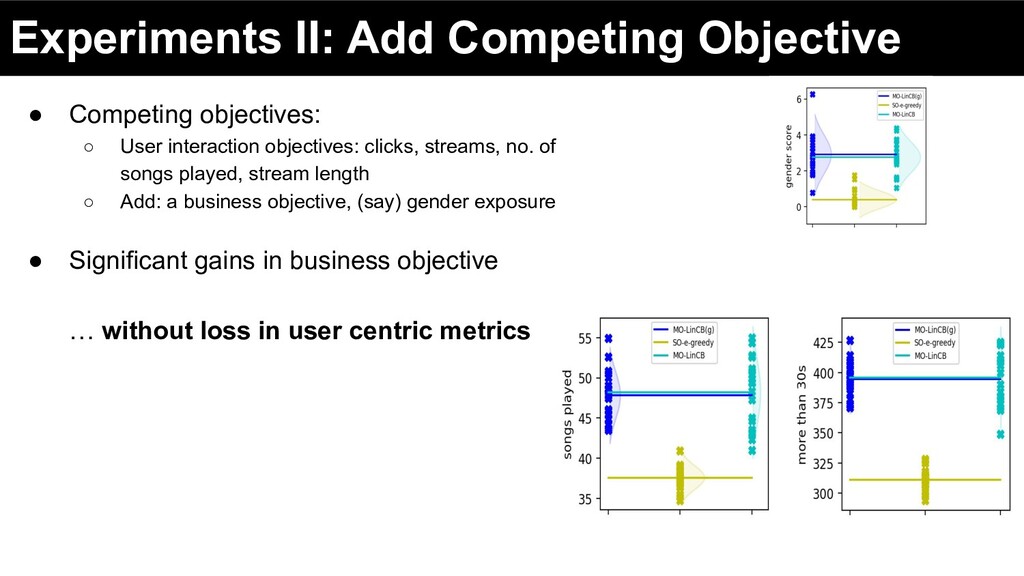
interaction objectives: clicks, streams, no. of songs played, stream length ◦ Add: a business objective, (say) gender exposure • Significant gains in business objective … without loss in user centric metrics
interaction objectives: clicks, streams, no. of songs played, stream length ◦ Add: a business objective, (say) gender exposure • Significant gains in business objective … without loss in user centric metrics Not necessarily a Zero-Sum Game … perhaps we “can” get gains in business objectives without loss in user centric objectives
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Online Gradient Descent: ➔ Non-vanishing step size ➔ Project a[t]](https://files.speakerdeck.com/presentations/a7aa68c41c3f4dd78f4d4eb17a9a75e0/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}