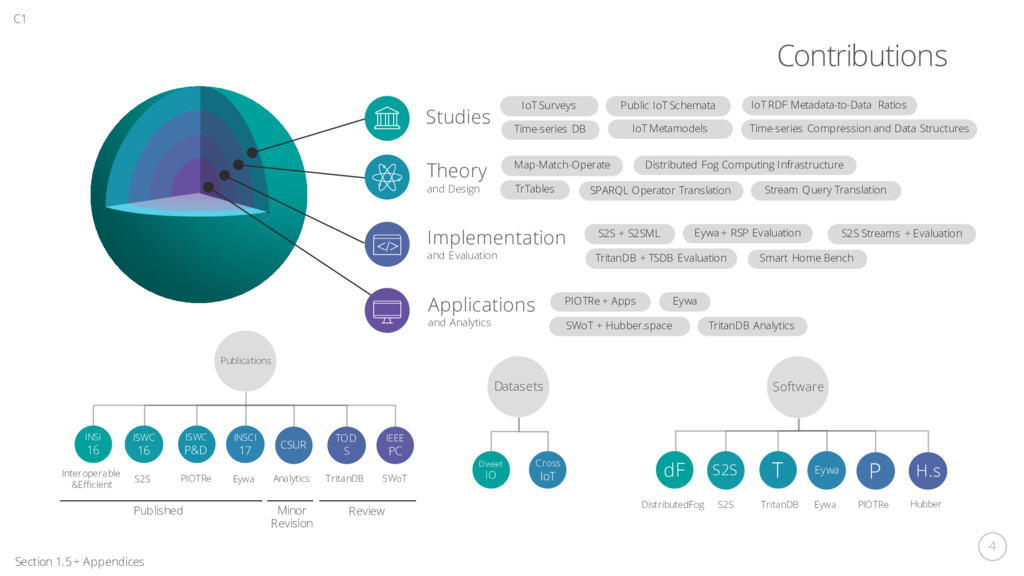
retrieval of a semantically interoperable representation of data and metadata, both historical and real-time, from the Internet of Things, for analytical applications?” Research Question C1 Section 1.4
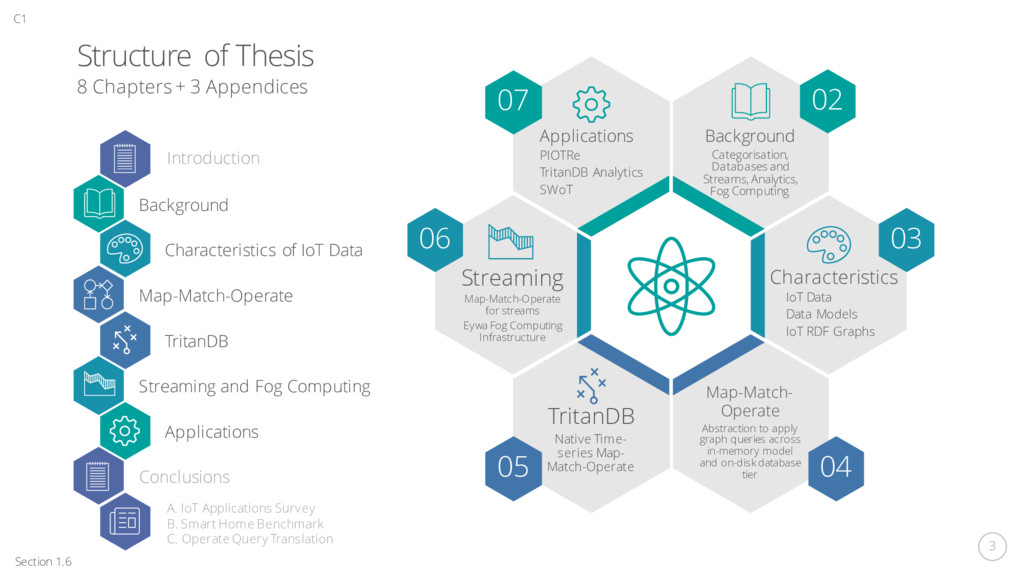
model and on-disk database tier TritanDB Native Time- series Map- Match-Operate Background Categorisation, Databases and Streams, Analytics, Fog Computing Applications PIOTRe TritanDB Analytics SWoT Characteristics IoT Data Data Models IoT RDF Graphs Streaming Map-Match-Operate for streams Eywa Fog Computing Infrastructure 07 02 03 04 05 06 Background Characteristics of IoT Data Map-Match-Operate TritanDB Streaming and Fog Computing Applications Structure of Thesis 8 Chapters + 3 Appendices Introduction Conclusions A. IoT Applications Survey B. Smart Home Benchmark C. Operate Query Translation Section 1.6 C1
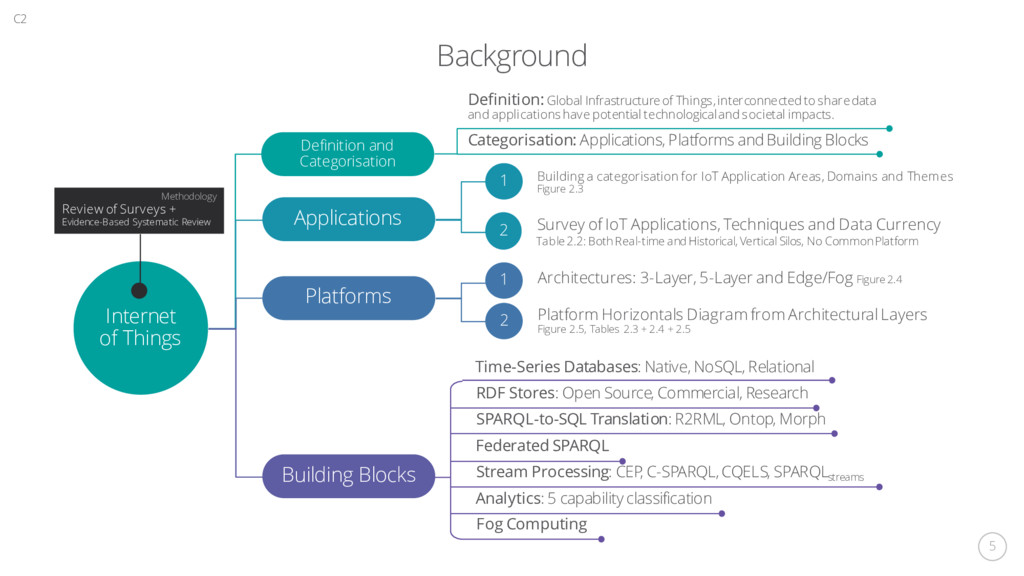
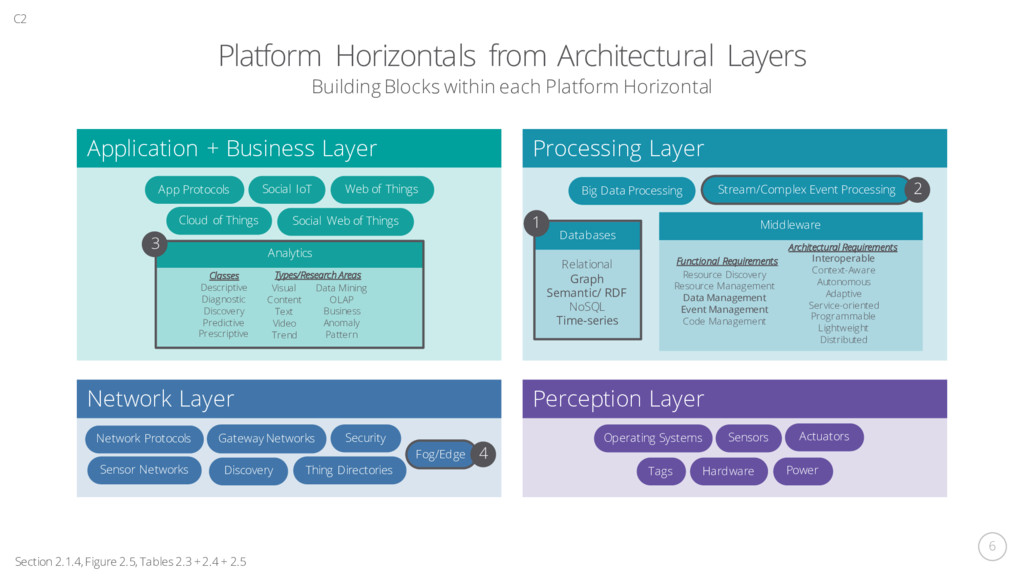
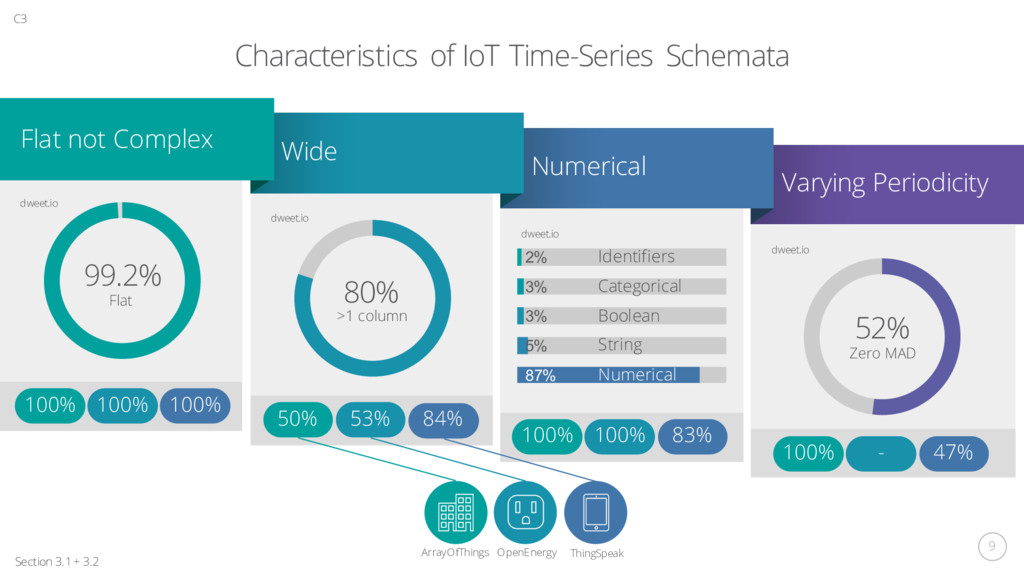
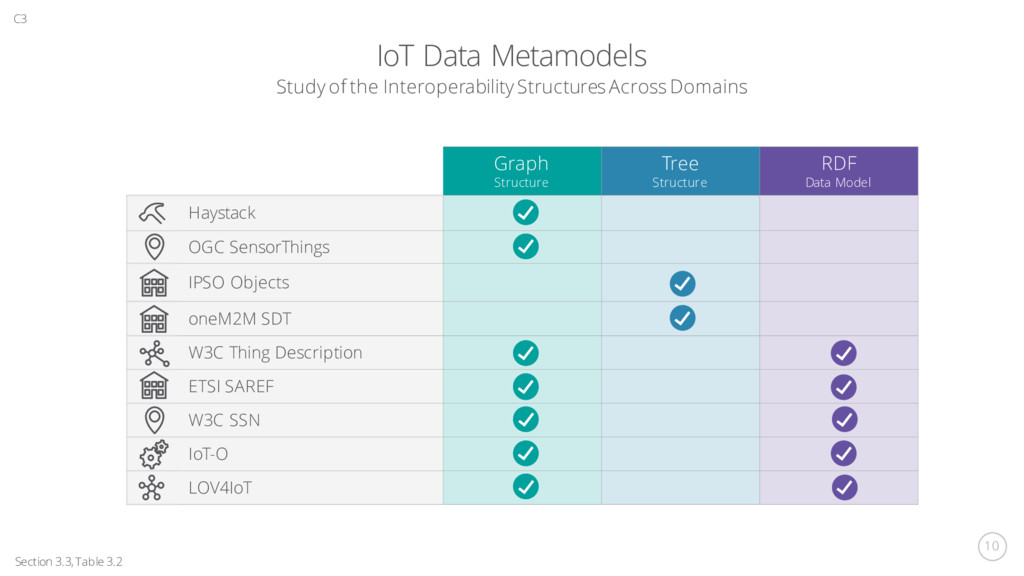
a categorisation for IoT Application Areas, Domains and Themes Figure 2.3 Survey of IoT Applications, Techniques and Data Currency Architectures: 3-Layer, 5-Layer and Edge/Fog Figure 2.4 Platform Horizontals Diagram from Architectural Layers Figure 2.5, Tables 2.3 + 2.4 + 2.5 1 2 1 2 C2 Definition and Categorisation Definition: Global Infrastructure of Things, interconnected to share data and applications have potential technological and societal impacts. Categorisation: Applications, Platforms and Building Blocks Table 2.2: Both Real-time and Historical, Vertical Silos, No Common Platform Time-Series Databases: Native, NoSQL, Relational RDF Stores: Open Source, Commercial, Research SPARQL-to-SQL Translation: R2RML, Ontop, Morph Federated SPARQL Stream Processing: CEP, C-SPARQL, CQELS, SPARQLstreams Analytics: 5 capability classification Fog Computing Methodology Review of Surveys + Evidence-Based Systematic Review
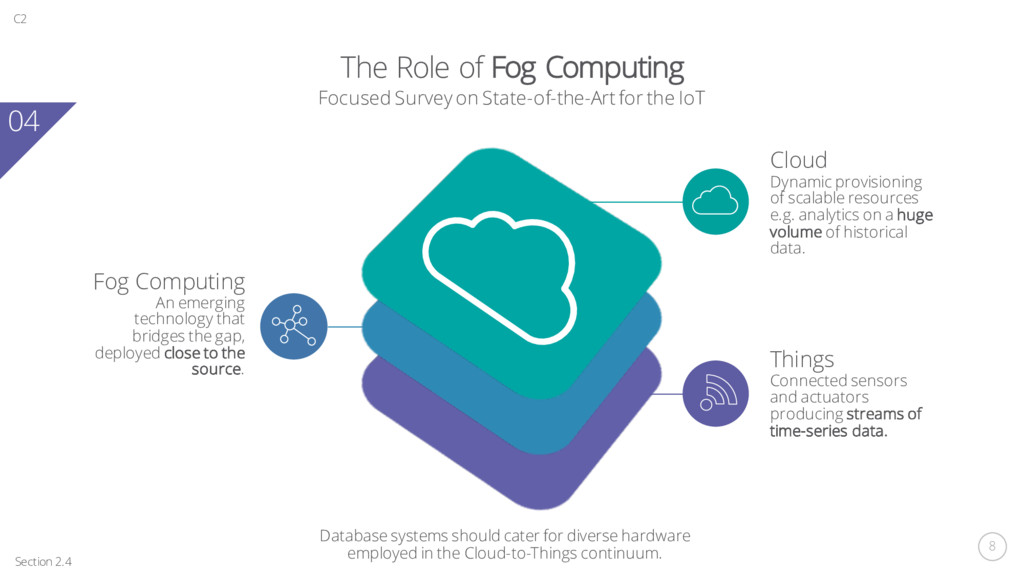
technology that bridges the gap, deployed close to the source. Cloud Dynamic provisioning of scalable resources e.g. analytics on a huge volume of historical data. Things Connected sensors and actuators producing streams of time-series data. Section 2.4 C2 Database systems should cater for diverse hardware employed in the Cloud-to-Things continuum. 04 Focused Survey on State-of-the-Art for the IoT
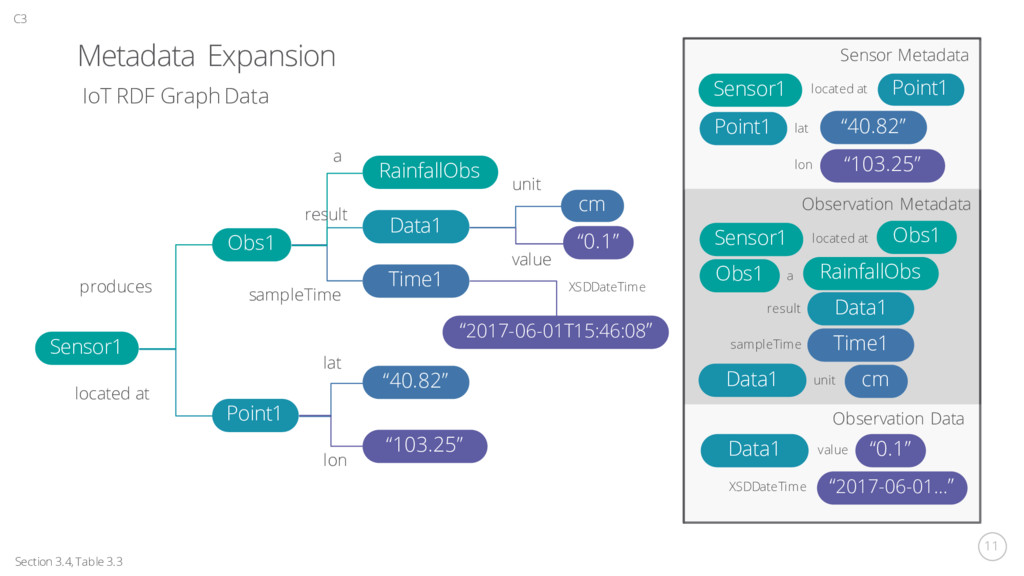
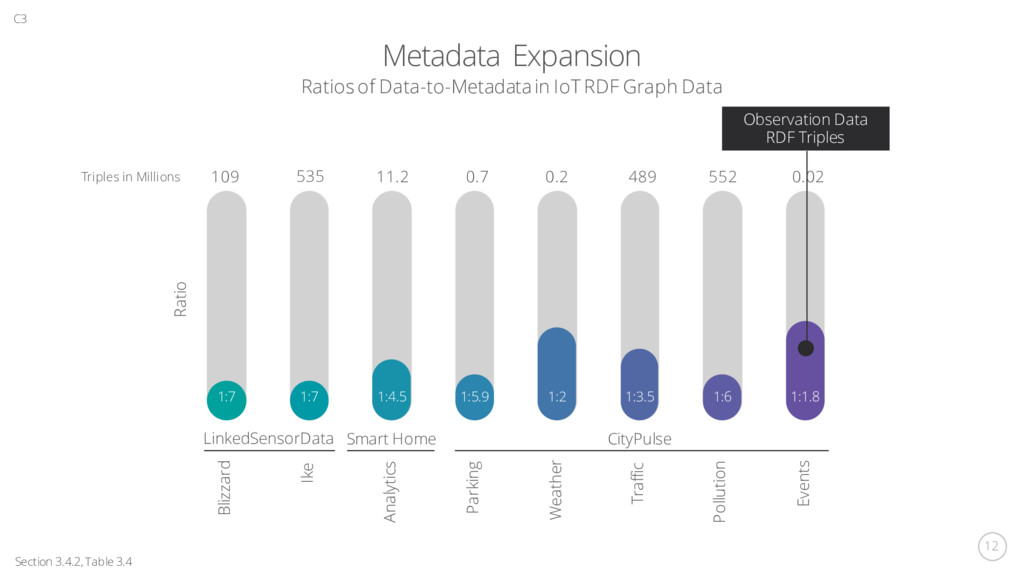
Data1 Time1 Point1 “40.82” “103.25” produces located at lat lon cm “0.1” “2017-06-01T15:46:08” XSDDateTime value unit sampleTime a result Sensor1 Point1 Point1 “40.82” “103.25” located at lat lon Sensor1 located at Obs1 Obs1 RainfallObs a Data1 Time1 result sampleTime cm Data1 unit Observation Metadata Sensor Metadata Data1 “0.1” “2017-06-01…” value XSDDateTime Observation Data Section 3.4, Table 3.3 C3
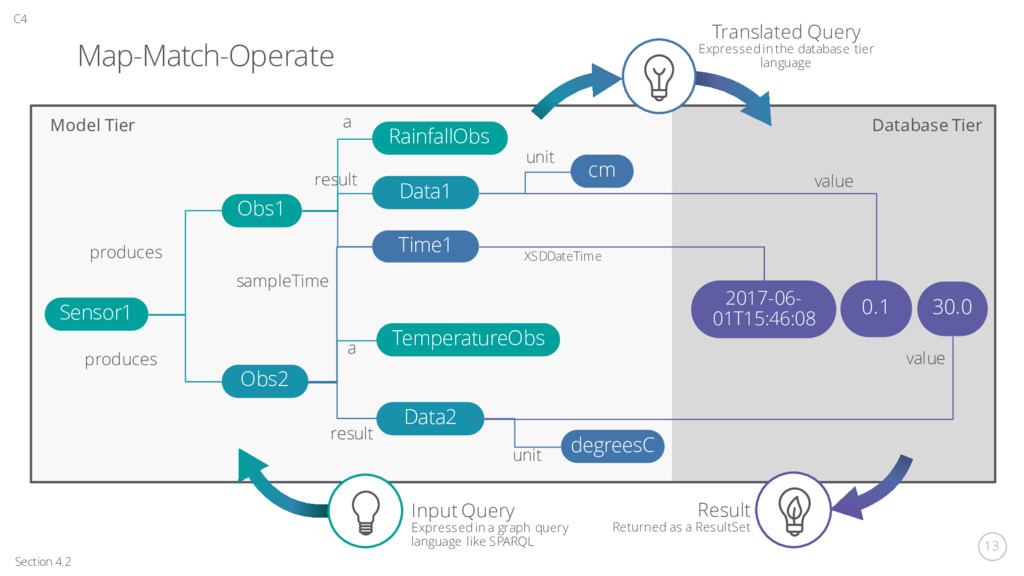
cm 0.1 2017-06- 01T15:46:08 XSDDateTime value unit sampleTime a result Section 4.2 C4 TemperatureObs a Data2 result degreesC 30.0 value unit Model Tier Database Tier Input Query Expressed in a graph query language like SPARQL Translated Query Expressed in the database tier language Result Returned as a ResultSet
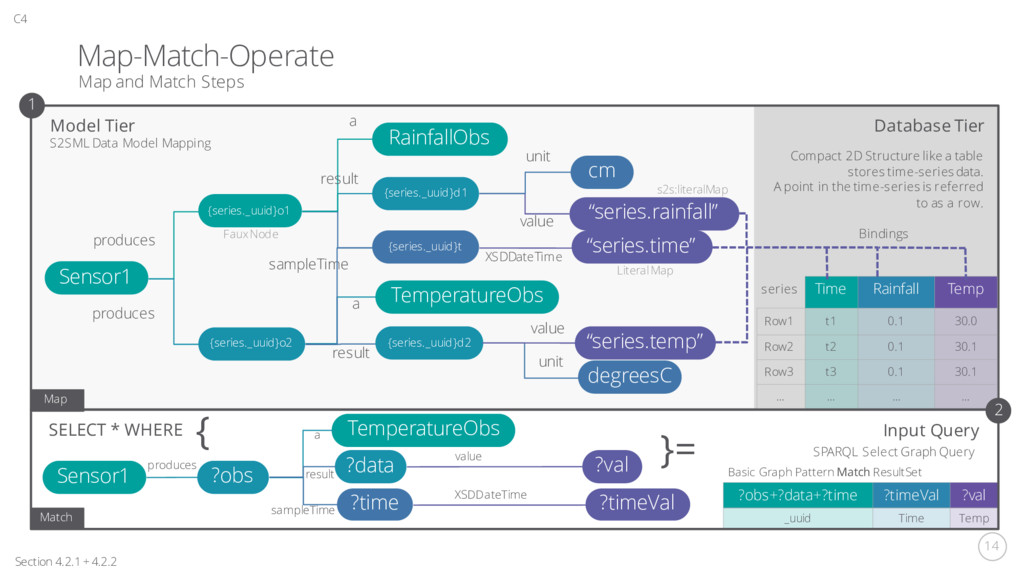
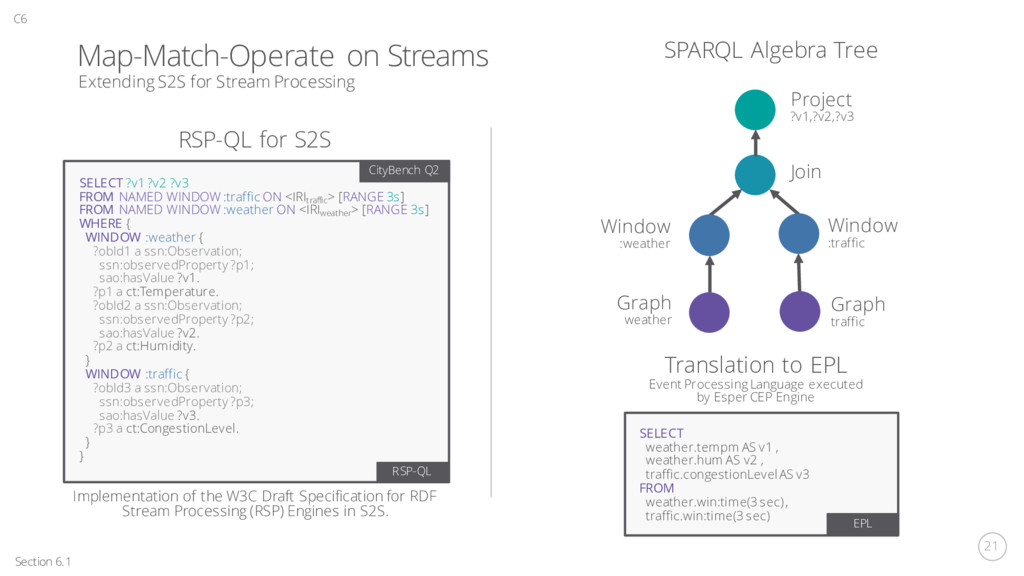
RainfallObs {series._uuid}d1 {series._uuid}t {series._uuid}o2 produces cm “series.rainfall” XSDDateTime value unit sampleTime a result Section 4.2.1 + 4.2.2 C4 TemperatureObs a {series._uuid}d2 result degreesC unit Model Tier Map and Match Steps “series.time” “series.temp” value produces S2SML Data Model Mapping 1 Database Tier Time Rainfall Temp Row1 t1 0.1 30.0 Row2 t2 0.1 30.1 Row3 t3 0.1 30.1 … … … … s2s:literalMap Faux Node Literal Map Bindings Compact 2D Structure like a table stores time-series data. A point in the time-series is referred to as a row. Map Match 2 Input Query Sensor1 ?obs TemperatureObs ?data ?val ?time ?timeVal SPARQL Select Graph Query produces result a sampleTime SELECT * WHERE }= { value XSDDateTime series Basic Graph Pattern Match ResultSet
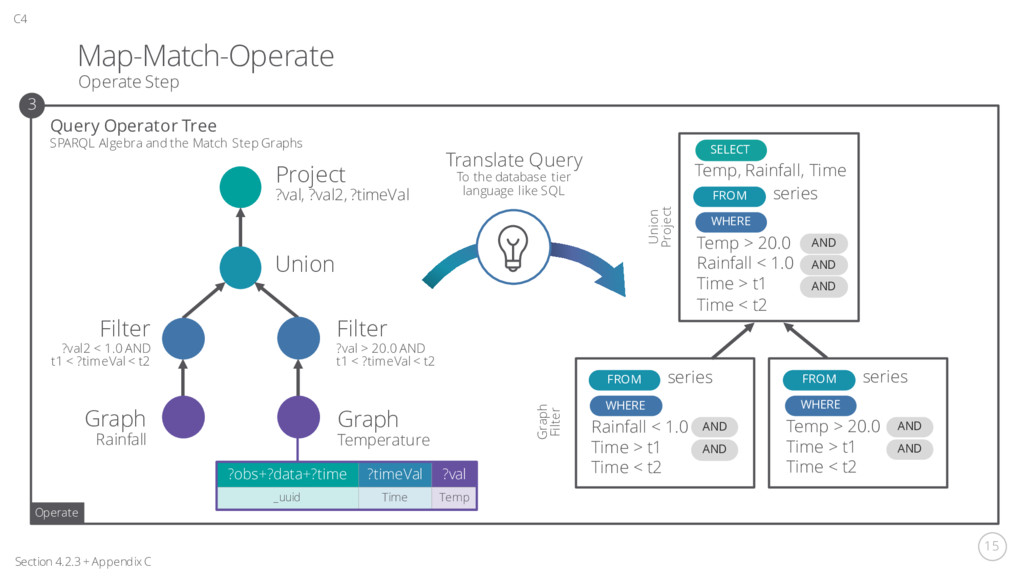
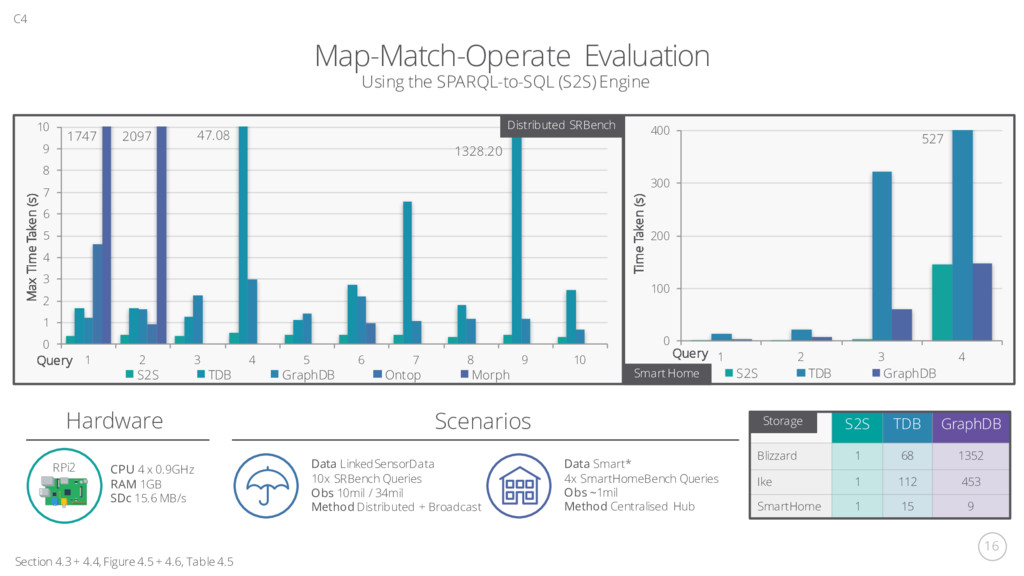
+ Appendix C C4 Query Operator Tree Operate Step SPARQL Algebra and the Match Step Graphs 3 Operate Union Filter ?val > 20.0 AND t1 < ?timeVal < t2 Graph Temperature Filter ?val2 < 1.0 AND t1 < ?timeVal < t2 Graph Rainfall Project ?val, ?val2, ?timeVal Temp > 20.0 Time > t1 Time < t2 FROM series WHERE AND AND Rainfall < 1.0 Time > t1 Time < t2 FROM series WHERE AND AND Temp > 20.0 Rainfall < 1.0 Time > t1 Time < t2 FROM series WHERE AND AND AND SELECT Temp, Rainfall, Time Translate Query To the database tier language like SQL Graph Filter Union Project
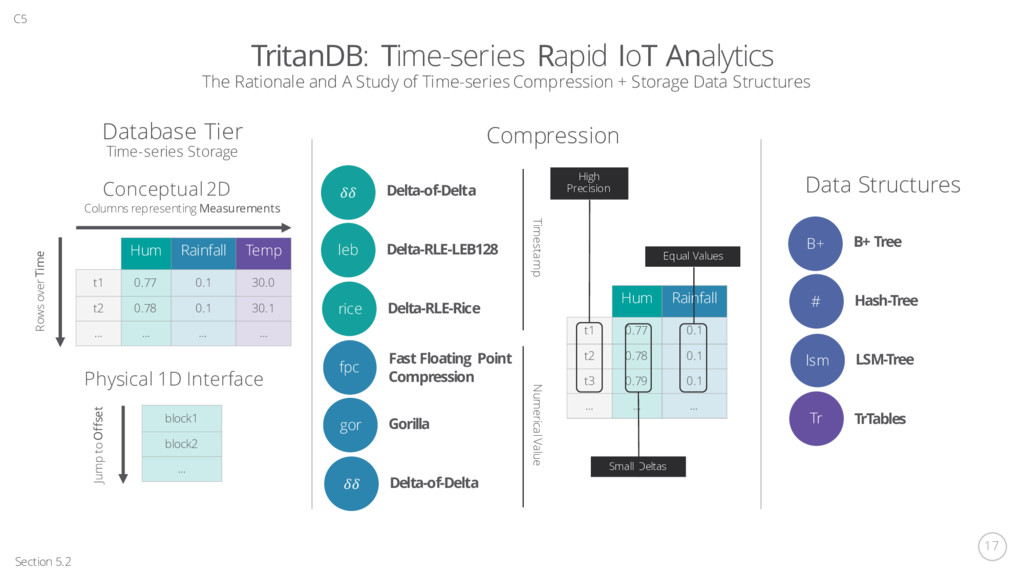
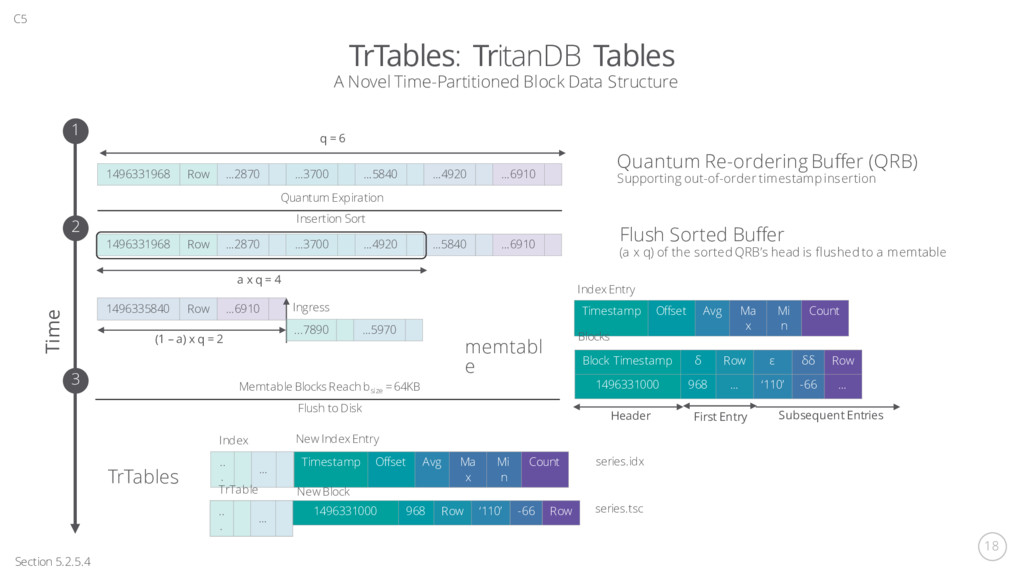
Block Data Structure 1496331968 Row …2870 …3700 …5840 …4920 …6910 Time q = 6 Quantum Re-ordering Buffer (QRB) Supporting out-of-order timestamp insertion Quantum Expiration Insertion Sort 1496331968 Row …2870 …3700 …4920 …5840 …6910 a x q = 4 Flush Sorted Buffer (a x q) of the sorted QRB’s head is flushed to a memtable 1496335840 Row …6910 (1 – a) x q = 2 ...7890 …5970 Ingress Timestamp Offset Avg Ma x Mi n Count memtabl e Index Entry Blocks Block Timestamp δ Row ε δδ Row 1496331000 968 … ‘110’ -66 … Header First Entry Subsequent Entries Memtable Blocks Reach bsize = 64KB Flush to Disk TrTables Timestamp Offset Avg Ma x Mi n Count New Index Entry .. . … Index .. . … TrTable New Block 1496331000 968 Row ‘110’ -66 Row series.idx series.tsc 1 2 3
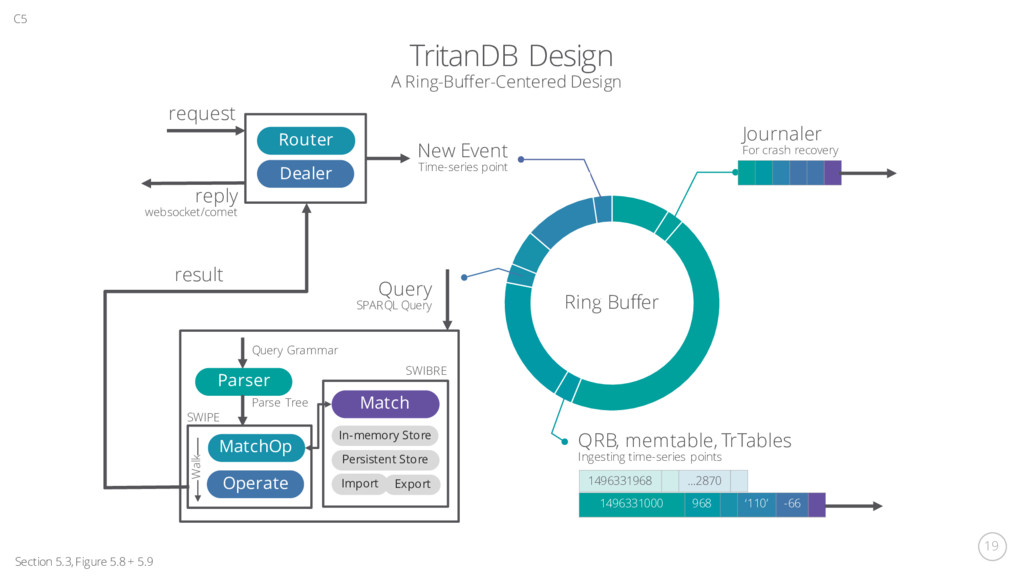
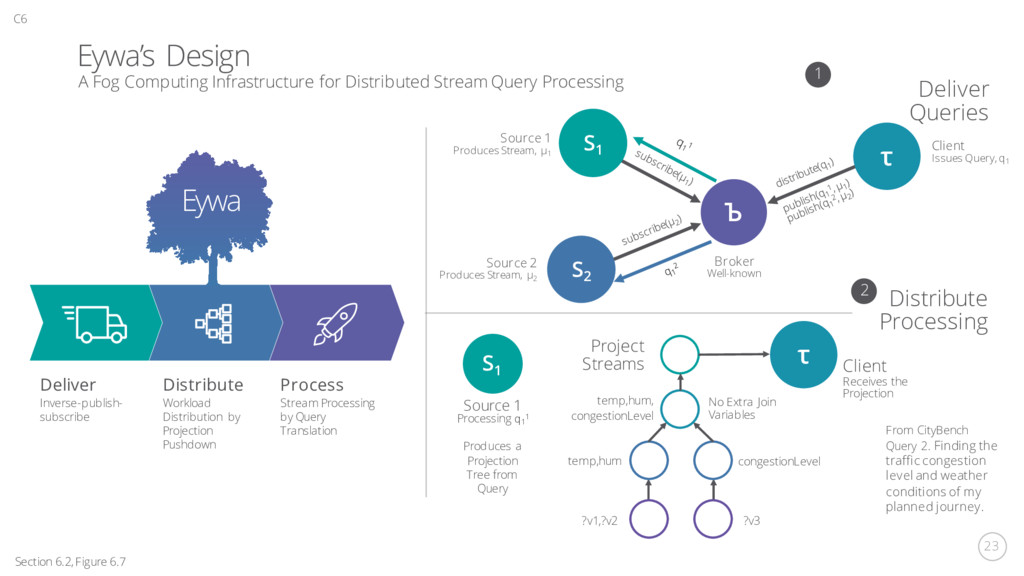
A Ring-Buffer-Centered Design Journaler For crash recovery QRB, memtable, TrTables Ingesting time-series points Query SPARQL Query New Event Time-series point 1496331968 …2870 1496331000 968 ‘110’ -66 Ring Buffer Router Dealer request reply websocket/comet Parser MatchOp Query Grammar Parse Tree Operate result Walk Persistent Store In-memory Store Import Export Match SWIBRE SWIPE
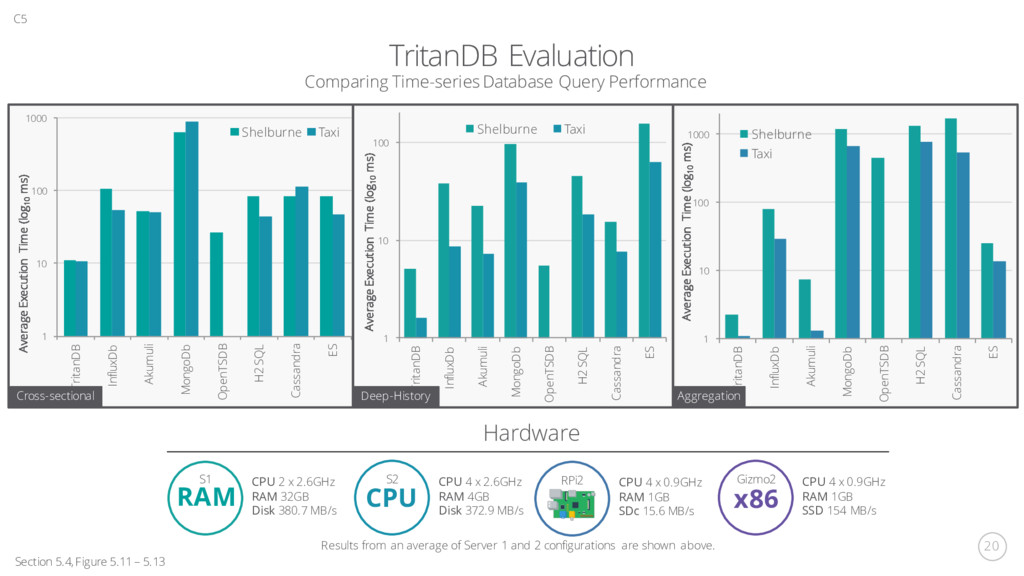
H2 SQL Cassandra ES Average Execution Time (log10 ms) Shelburne Taxi 1 10 100 TritanDB InfluxDb Akumuli MongoDb OpenTSDB H2 SQL Cassandra ES Average Execution Time (log10 ms) Shelburne Taxi TritanDB Evaluation Section 5.4, Figure 5.11 – 5.13 C5 Comparing Time-series Database Query Performance Cross-sectional S1 CPU 2 x 2.6GHz RAM 32GB Disk 380.7 MB/s Hardware S2 CPU 4 x 2.6GHz RAM 4GB Disk 372.9 MB/s RPi2 CPU 4 x 0.9GHz RAM 1GB SDc 15.6 MB/s Gizmo2 CPU 4 x 0.9GHz RAM 1GB SSD 154 MB/s 1 10 100 1000 TritanDB InfluxDb Akumuli MongoDb OpenTSDB H2 SQL Cassandra ES Average Execution Time (log10 ms) Shelburne Taxi Results from an average of Server 1 and 2 configurations are shown above. Deep-History Aggregation RAM CPU x86
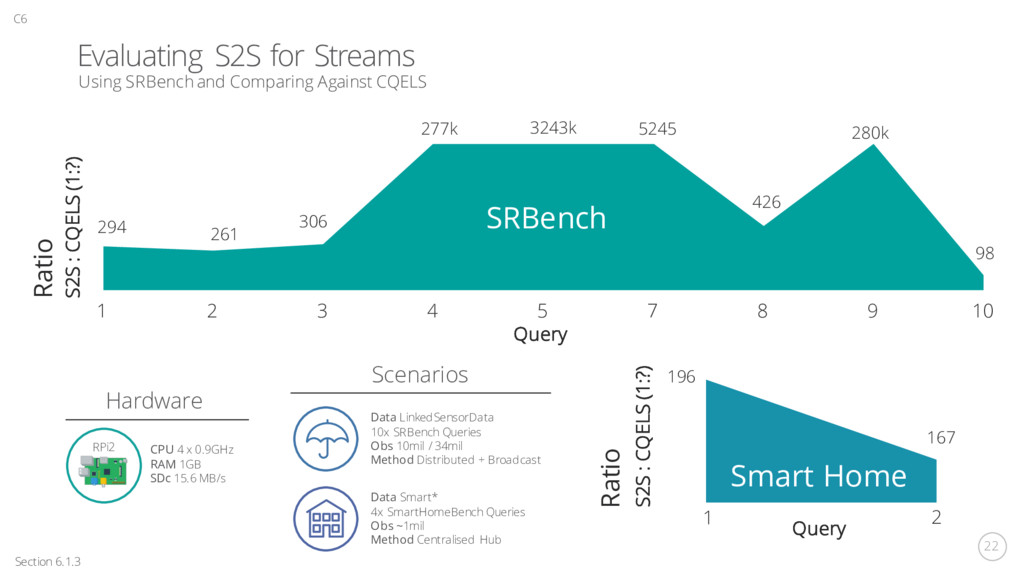
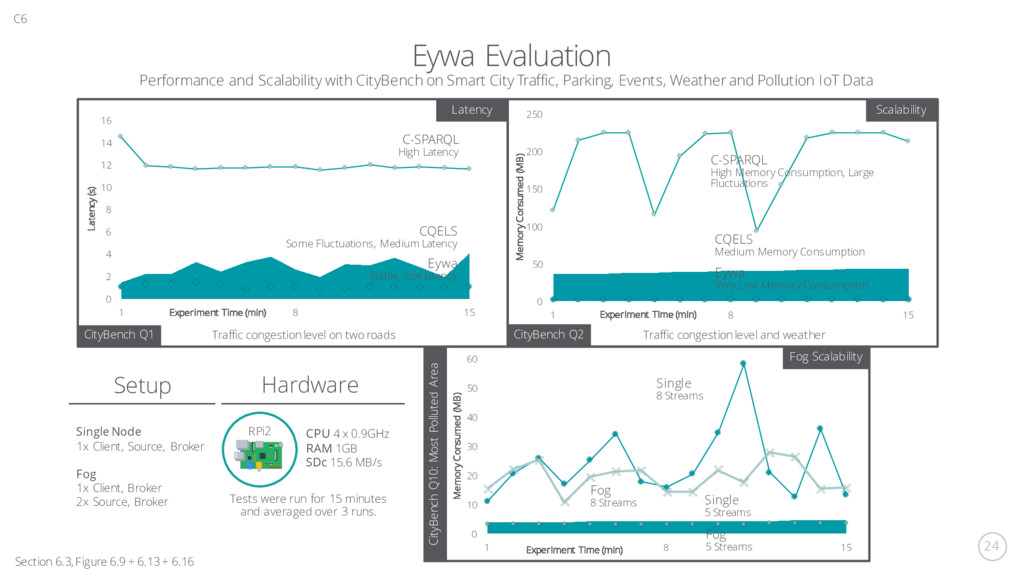
Memory Consumed (MB) Experiment Time (min) Eywa Evaluation Section 6.3, Figure 6.9 + 6.13 + 6.16 C6 Performance and Scalability with CityBench on Smart City Traffic, Parking, Events, Weather and Pollution IoT Data 0 2 4 6 8 10 12 14 16 1 8 15 Latency (s) Experiment Time (min) C-SPARQL High Latency CQELS Some Fluctuations, Medium Latency Eywa Stable, low latency Latency CityBench Q1 Traffic congestion level on two roads Scalability CityBench Q2 Traffic congestion level and weather C-SPARQL High Memory Consumption, Large Fluctuations CQELS Medium Memory Consumption Eywa Very Low Memory Consumption 0 10 20 30 40 50 60 1 8 15 Memory Consumed (MB) Experiment Time (min) Fog Scalability Single 8 Streams Fog 8 Streams Fog 5 Streams Single 5 Streams CityBench Q10: Most Polluted Area RPi2 CPU 4 x 0.9GHz RAM 1GB SDc 15.6 MB/s Hardware Tests were run for 15 minutes and averaged over 3 runs. Single Node 1x Client, Source, Broker Fog 1x Client, Broker 2x Source, Broker Setup
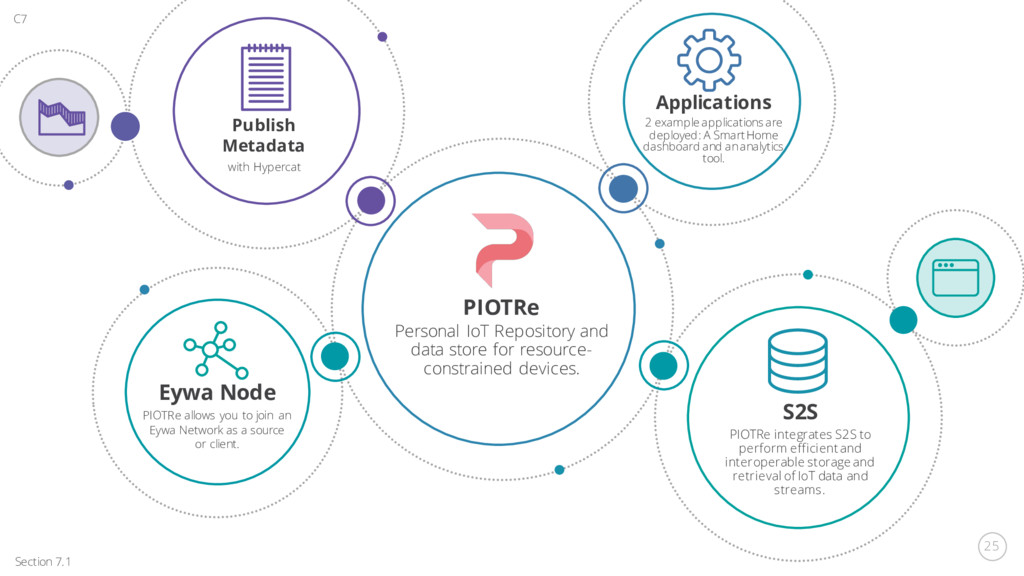
for resource- constrained devices. S2S PIOTRe integrates S2S to perform efficient and interoperable storage and retrieval of IoT data and streams. Eywa Node PIOTRe allows you to join an Eywa Network as a source or client. Applications 2 example applications are deployed: A Smart Home dashboard and an analytics tool. Publish Metadata with Hypercat Section 7.1 C7
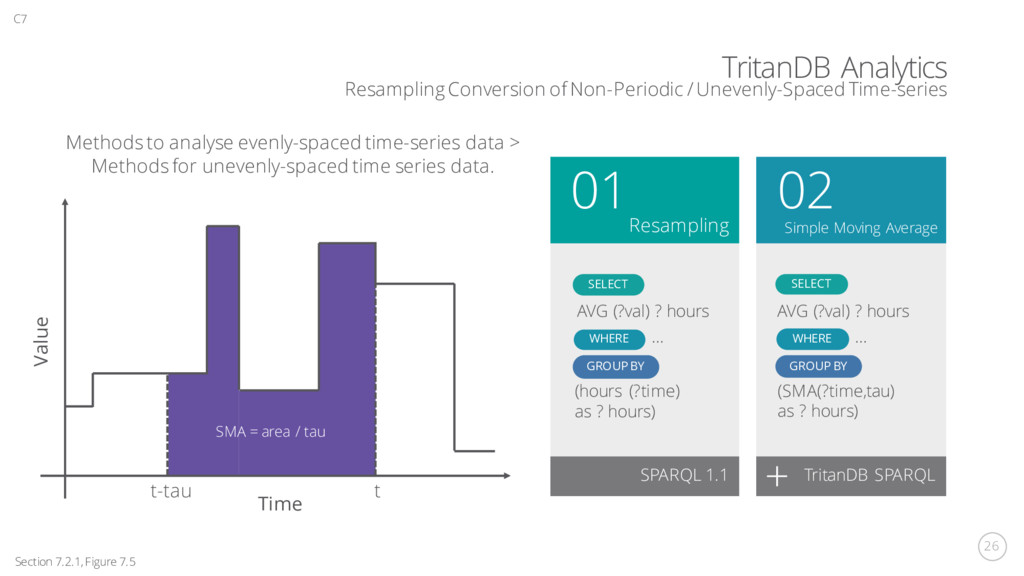
01 02 SPARQL 1.1 TritanDB SPARQL (hours (?time) as ? hours) GROUP BY SELECT AVG (?val) ? hours WHERE … (SMA(?time,tau) as ? hours) GROUP BY SELECT AVG (?val) ? hours WHERE … Resampling Simple Moving Average Value Time t-tau t Section 7.2.1, Figure 7.5 C7 Methods to analyse evenly-spaced time-series data > Methods for unevenly-spaced time series data. SMA = area / tau
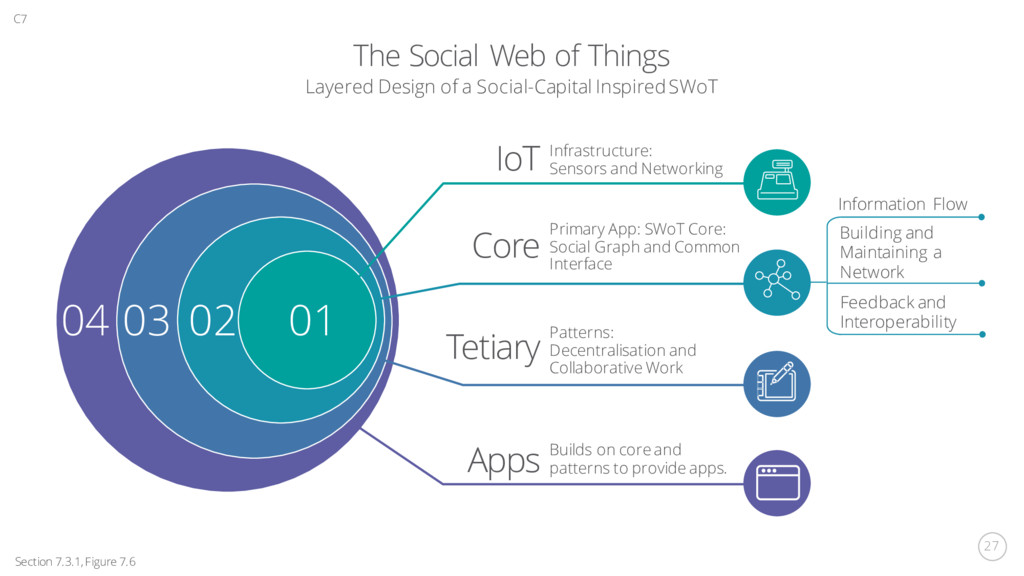
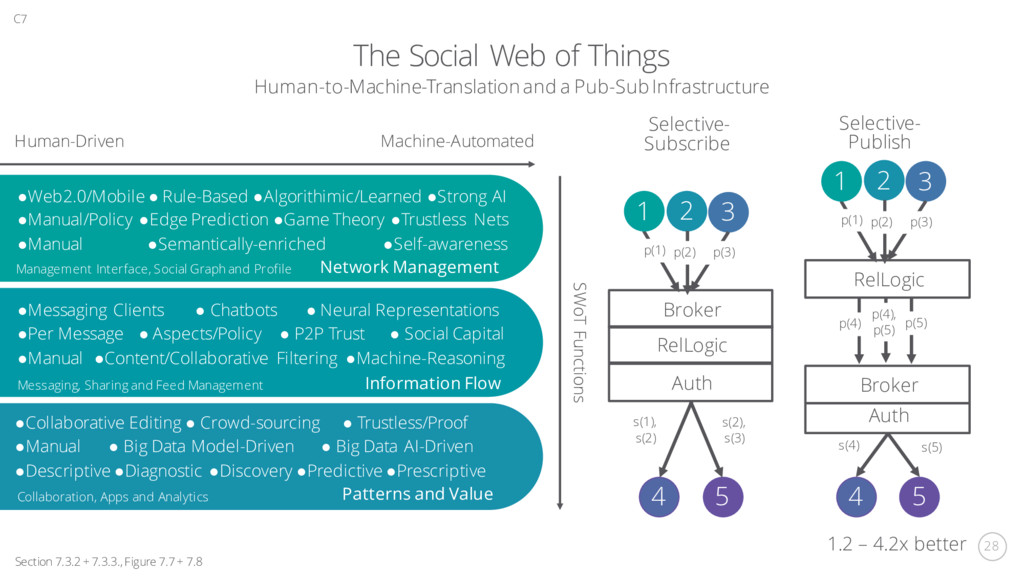
Social-Capital Inspired SWoT Infrastructure: Sensors and Networking IoT Core Primary App: SWoT Core: Social Graph and Common Interface Patterns: Decentralisation and Collaborative Work Builds on core and patterns to provide apps. Tetiary Apps 01 02 03 04 C7 Section 7.3.1, Figure 7.6 Building and Maintaining a Network Information Flow Feedback and Interoperability
Multimodal Data Support for complex data structures and images, sounds and unstructured text Other Graph/Tree Models Extending Map-Match-Operate to work on other Graph/Tree models RDF Property Paths Support chain of predicates and predicate cardinality (arbitrary number of hops), across tiers Horizontal Scalability feasibility of partitioning timeseries data across instances Focus of this Thesis Current time-series IoT data characteristics, a particular graph model, RDF, and processing done on a single node or in a co- operative cloud scenario. C8 Section 8.2
besides projections, can be processed in the data plane between the source and client nodes Social Web of Things Knowledge Graph Research on utilising the knowledge graph formed from integrating mappings of Thing metadata provided as S2SML Opportunities C8 Section 8.3 + 8.4 Leading to Future Work Final Remarks Map-Match-Operate, TritanDB and Eywa help achieve efficient storage and retrieval of a semantically interoperable representation of data and metadata, both historical and real- time, utilising the unique characteristics of Internet of Things data. The thesis goes beyond the immediate performance and interoperability of the solutions proposed, showing how they can lead to analytical applications and platforms in different directions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}