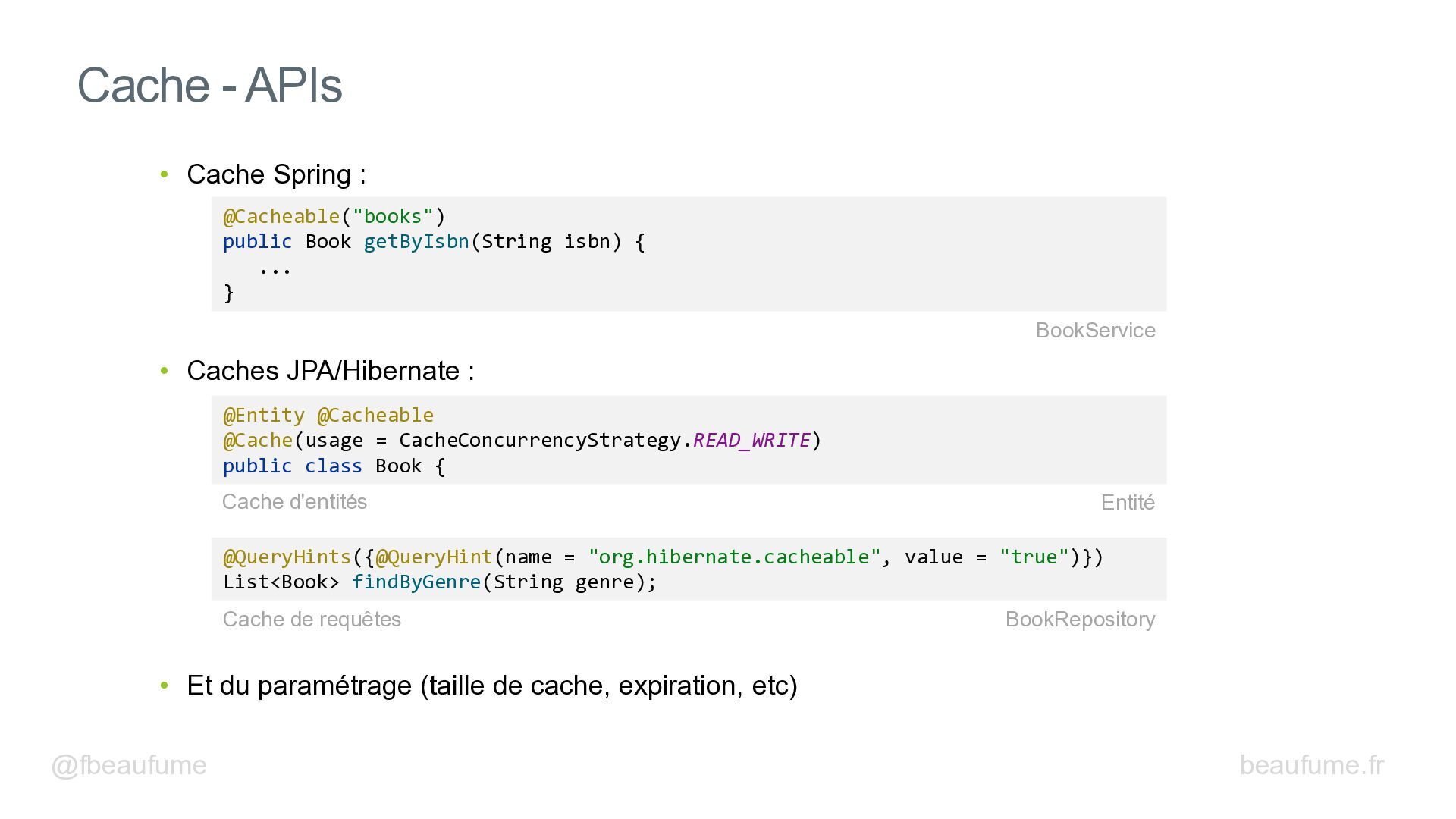
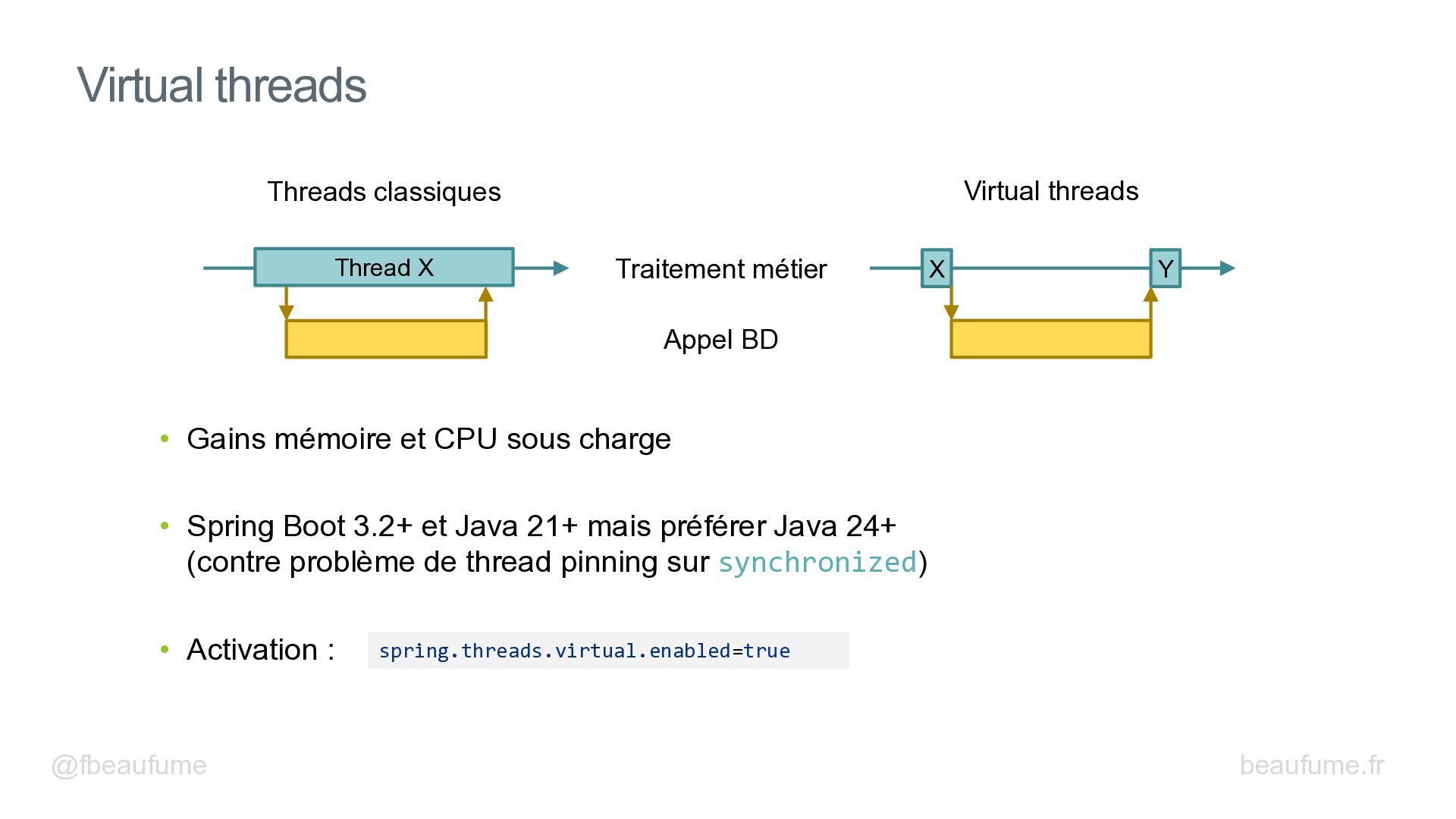
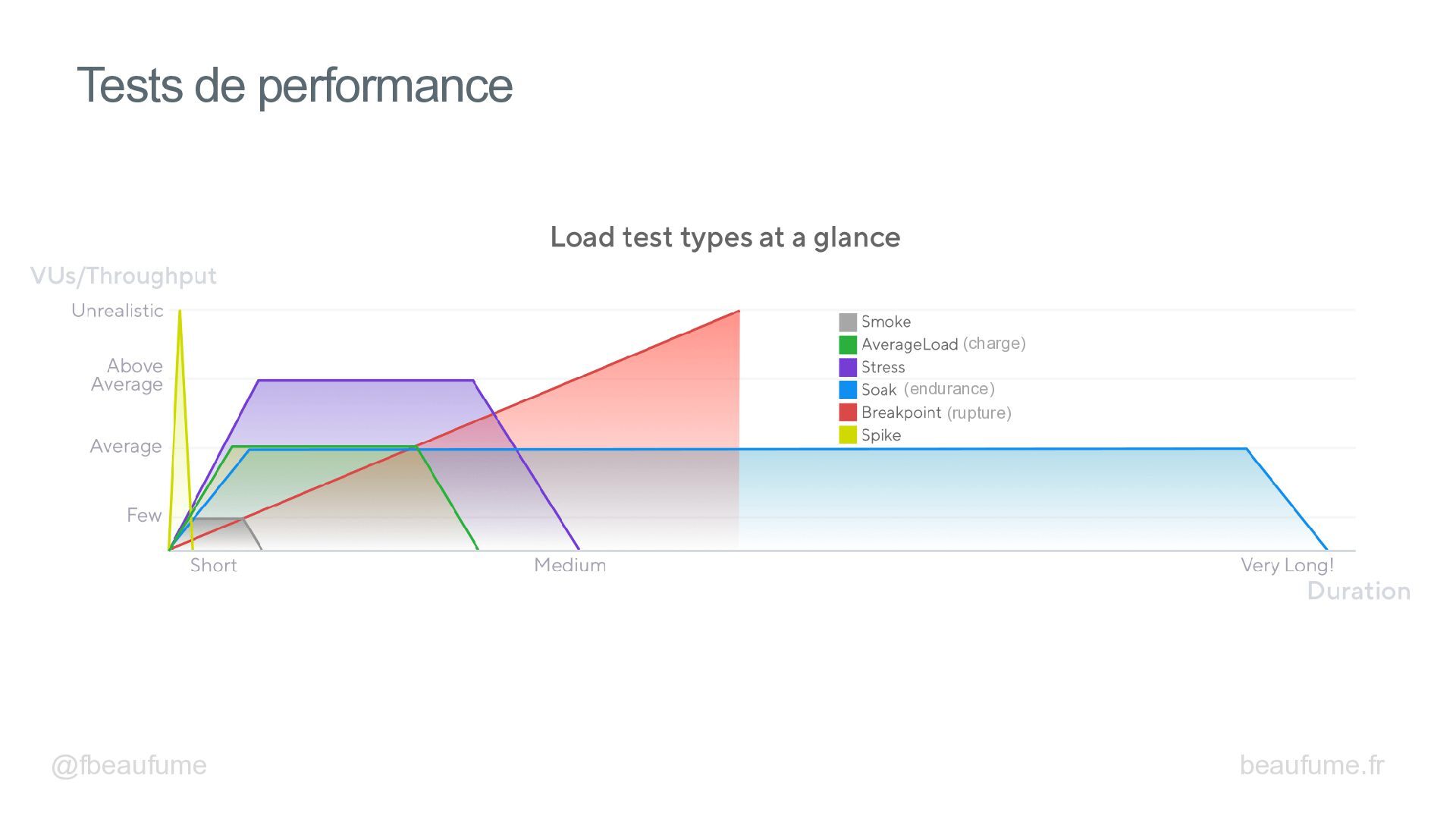
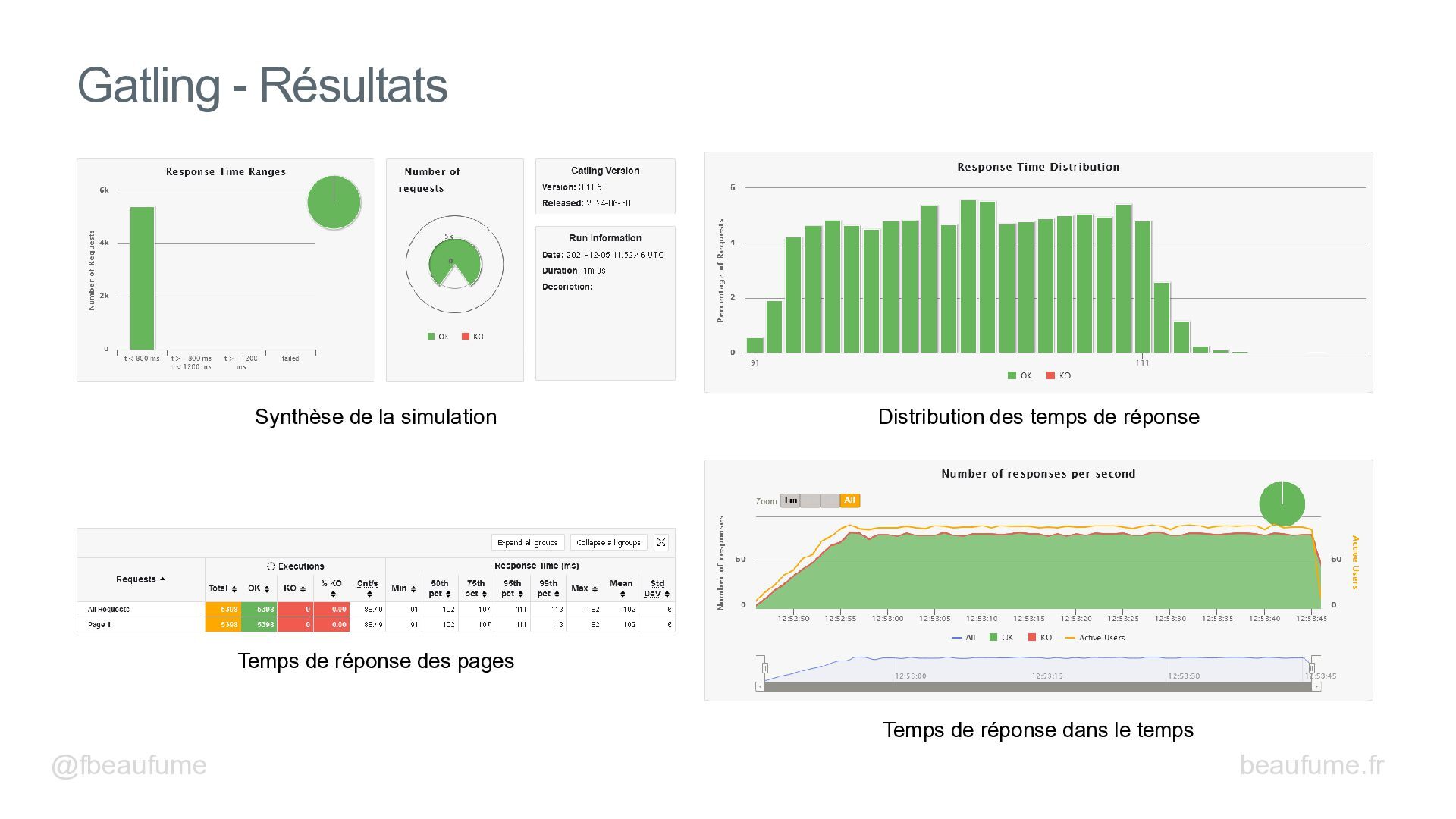
Découvrez les techniques essentielles pour booster les performances de vos backends Spring : bon paramétrage des entités JPA, lectures de données efficaces et N+1 Select, insertions par blocs, modifications par lot, logs et métriques d'Hibernate, pool de connexion, gestion des transactions, cache, virtual threads, mesures avec Gatling et autres.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
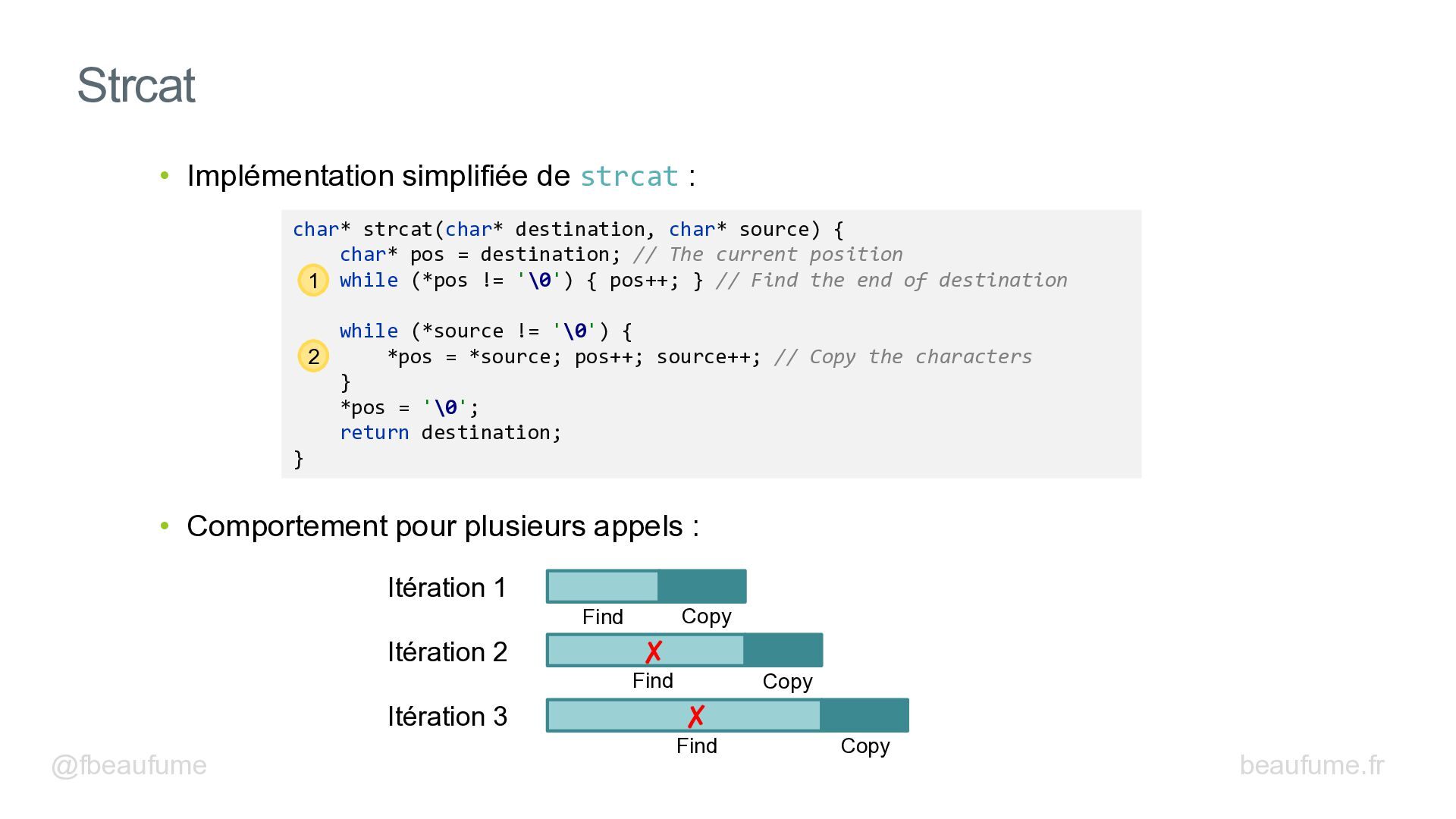{kind=link}
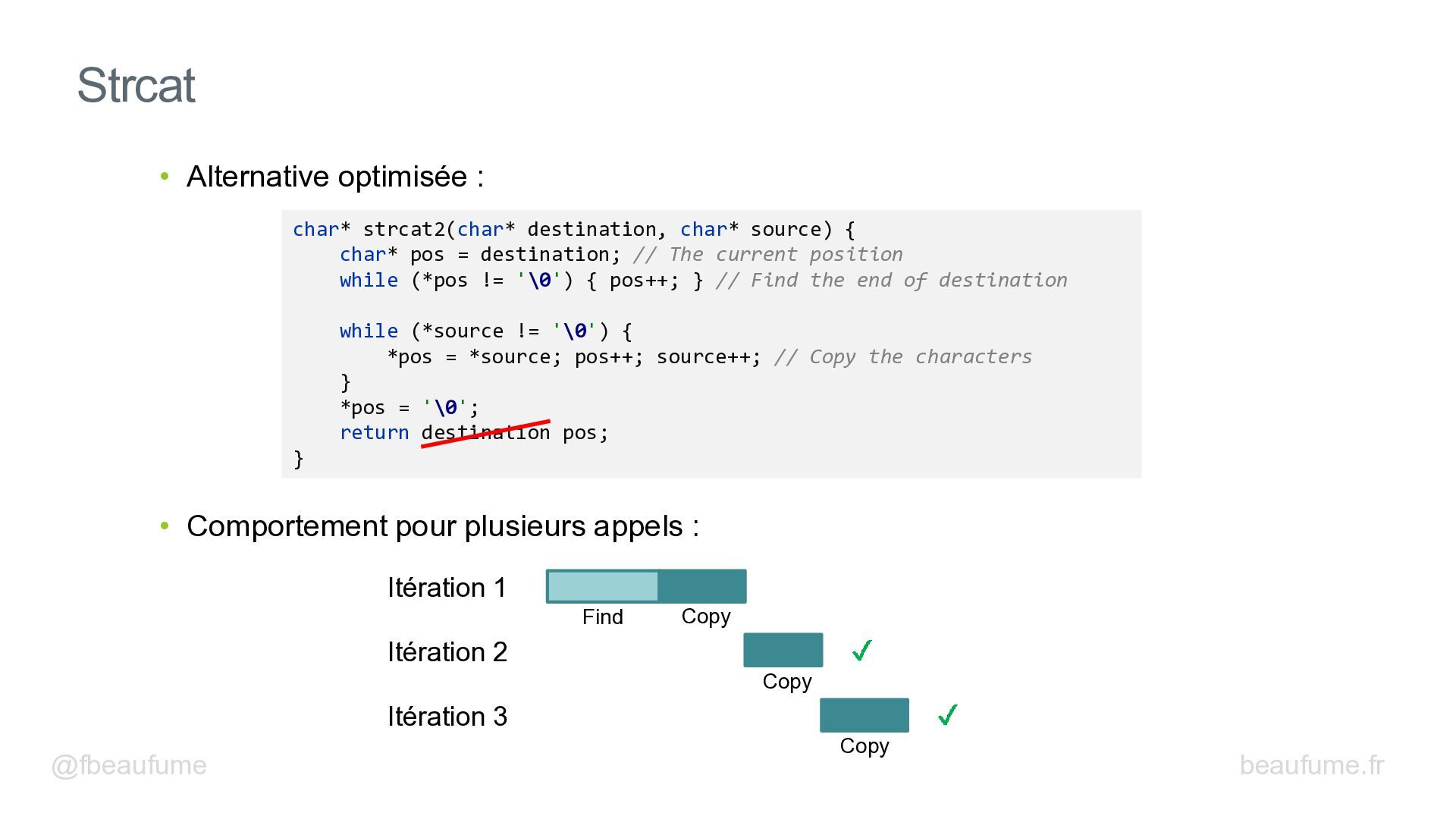{kind=link}
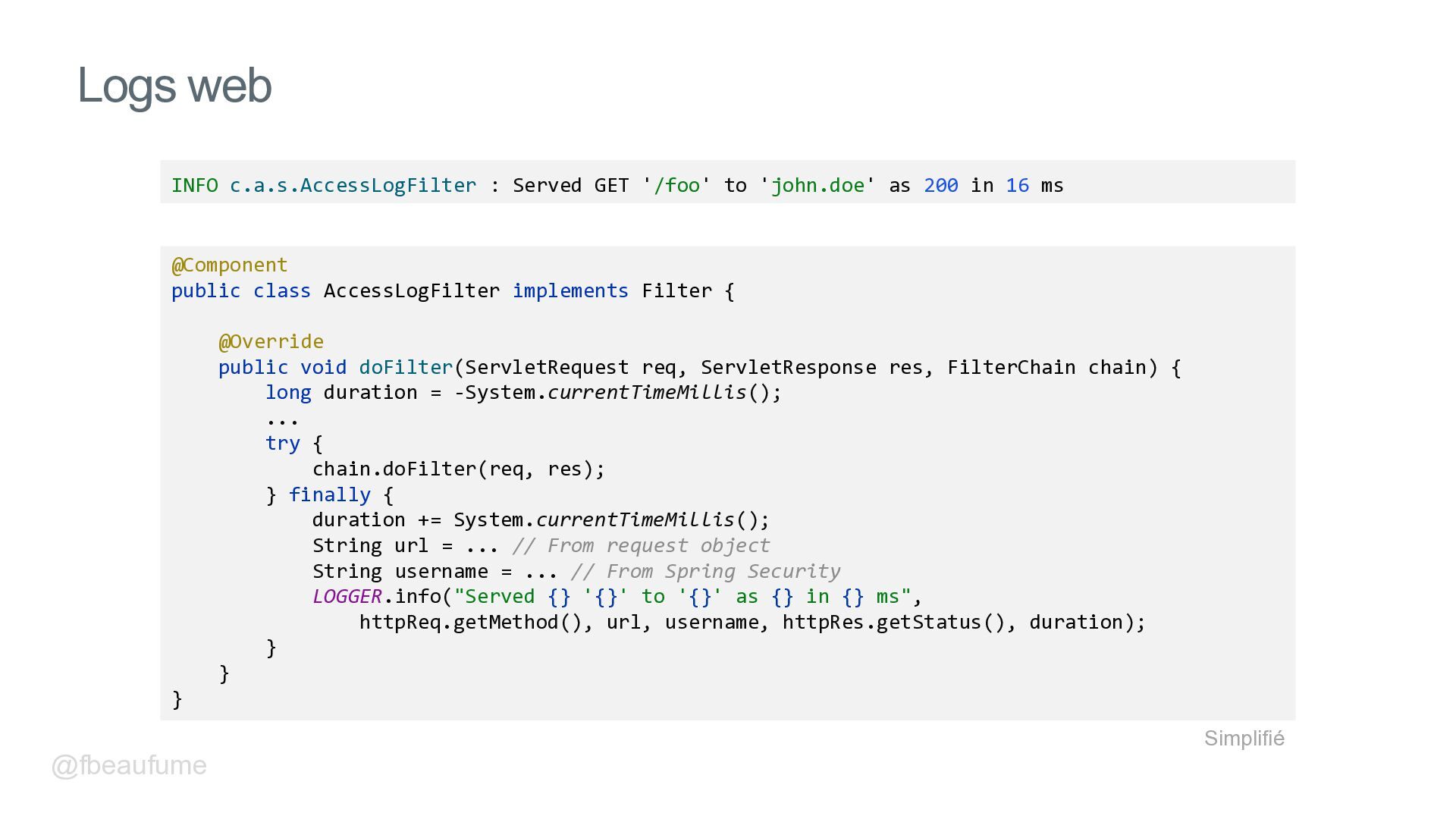{kind=link}
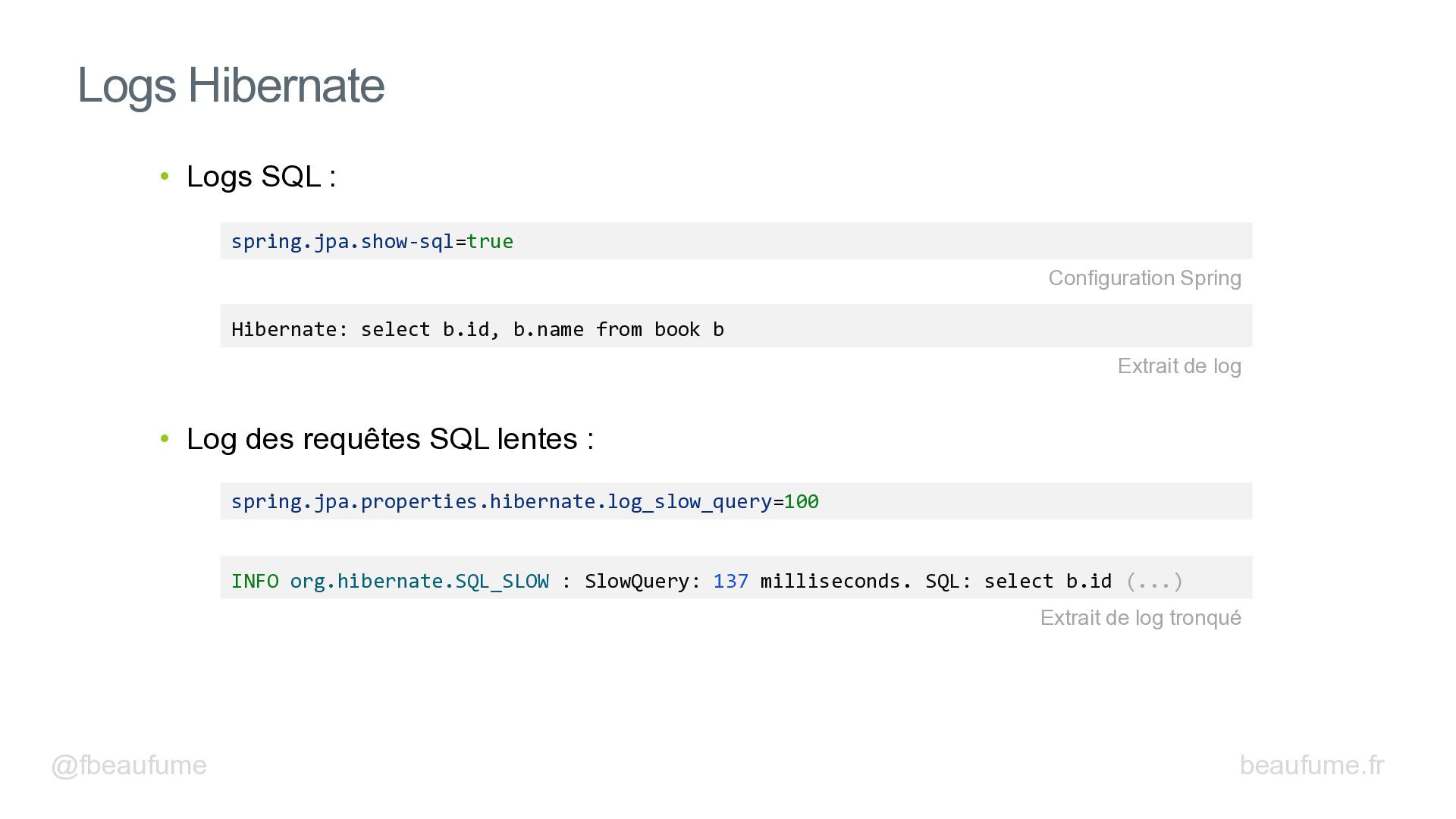{kind=link}
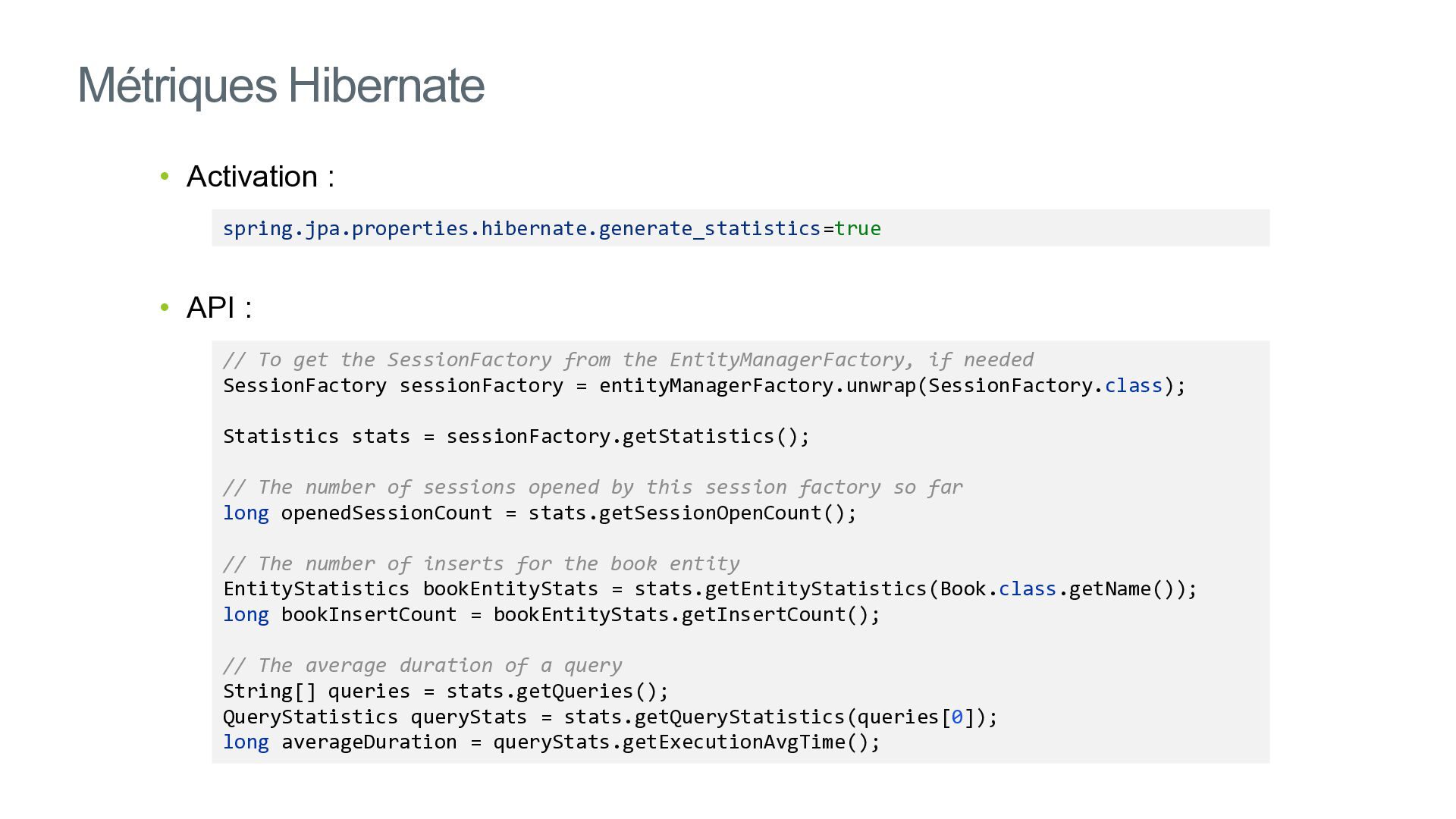{kind=link}
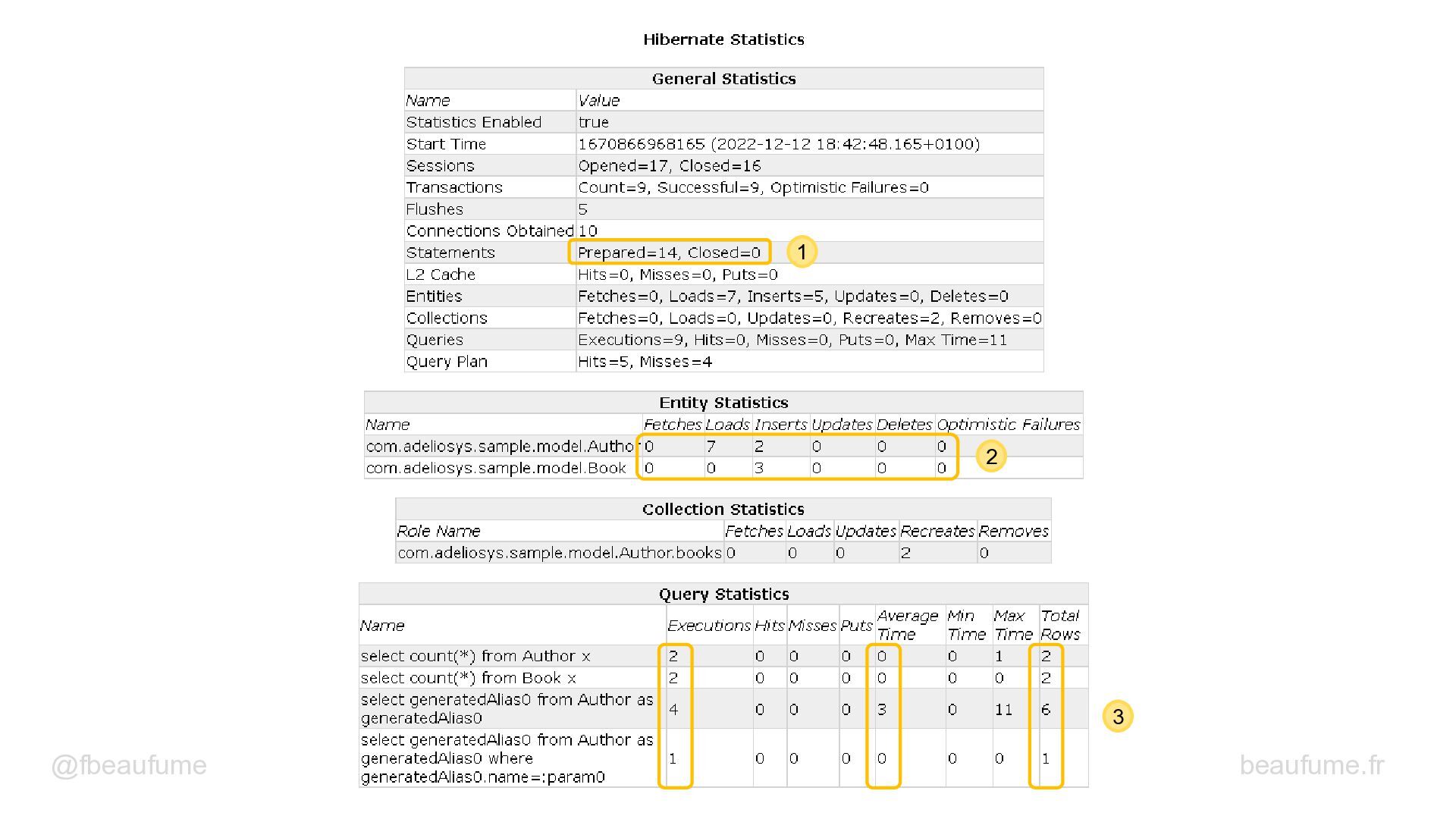{kind=link}
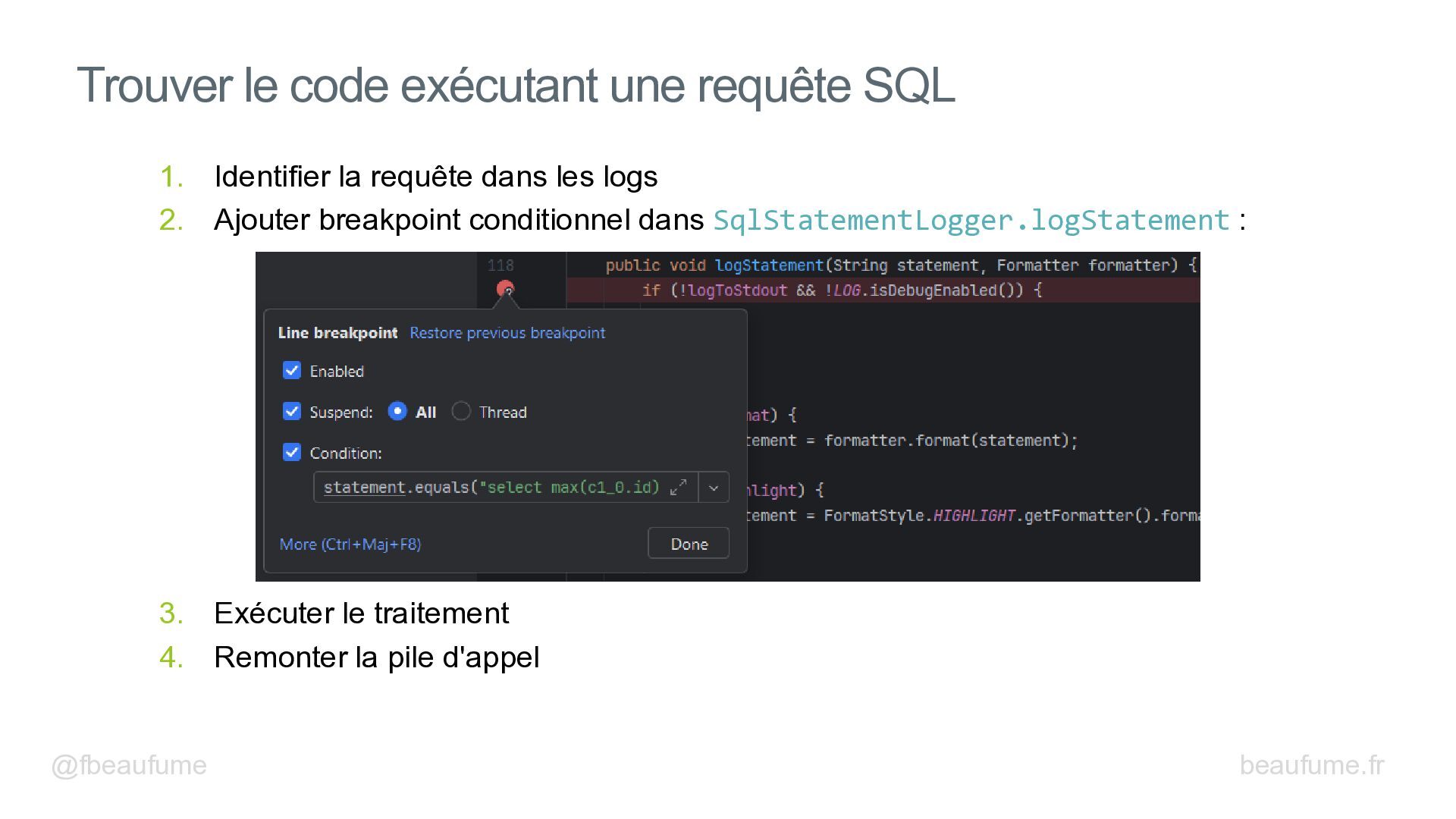{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
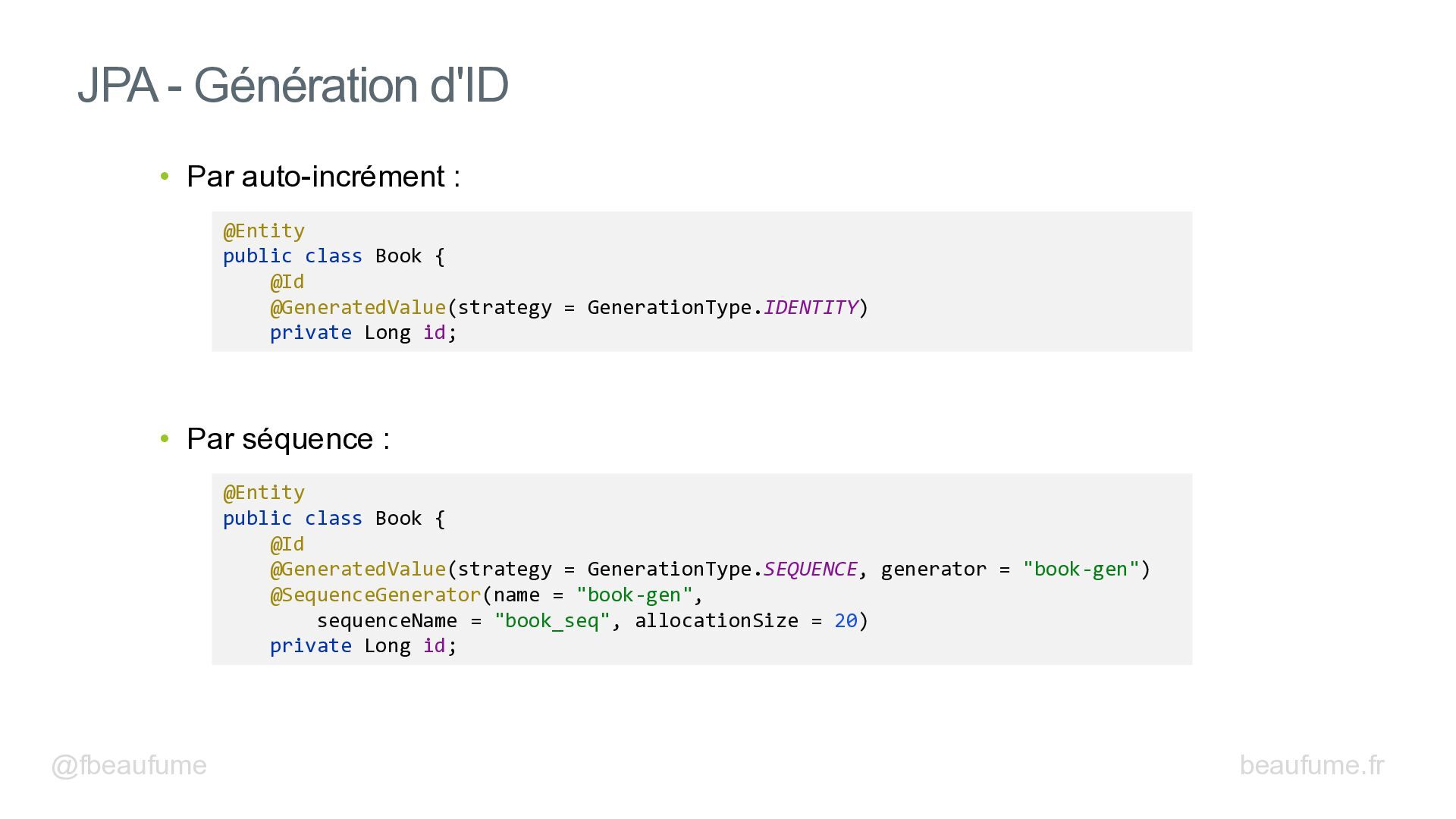{kind=link}
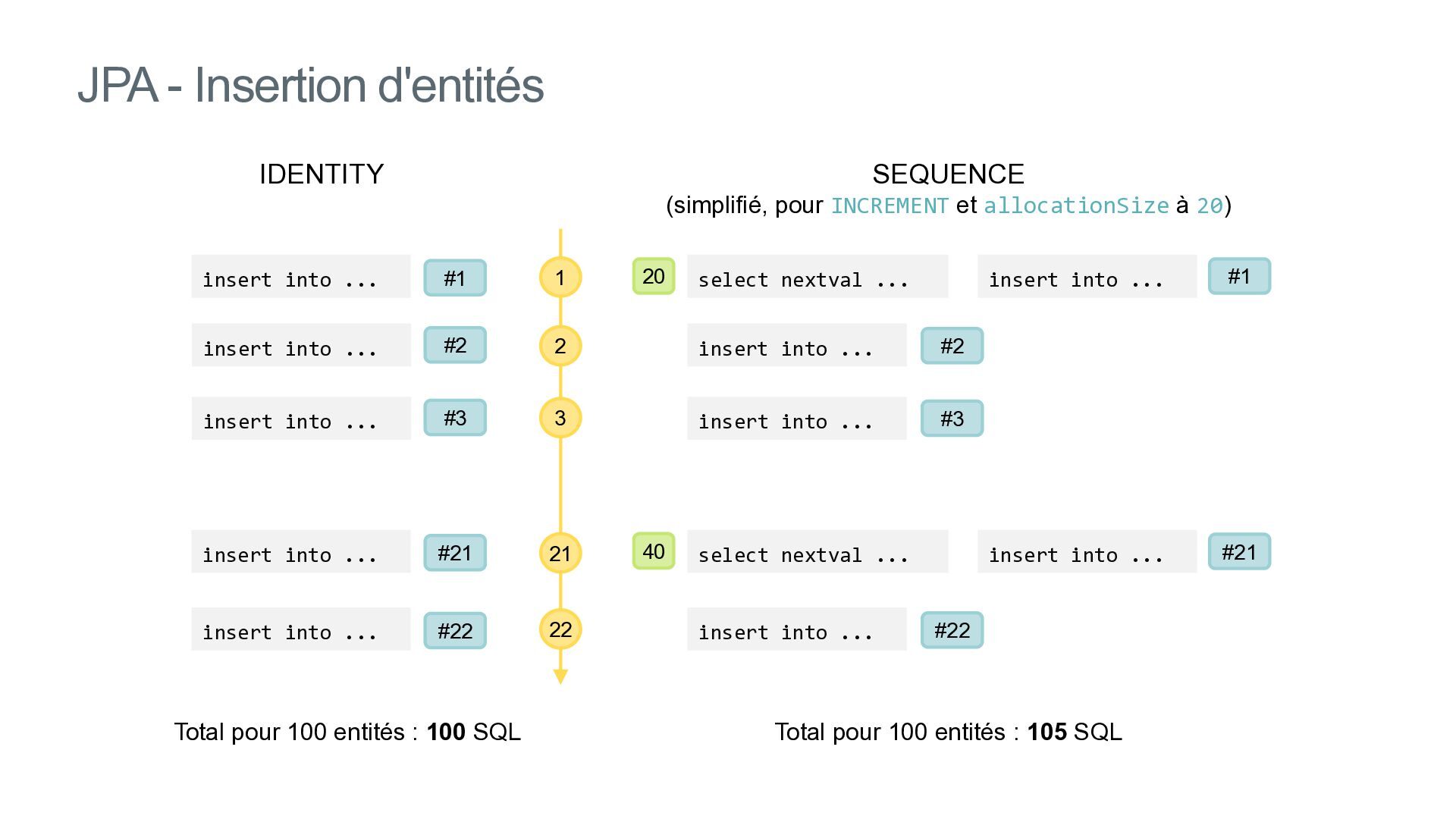{kind=link}
{kind=link}
{kind=link}
{kind=link}
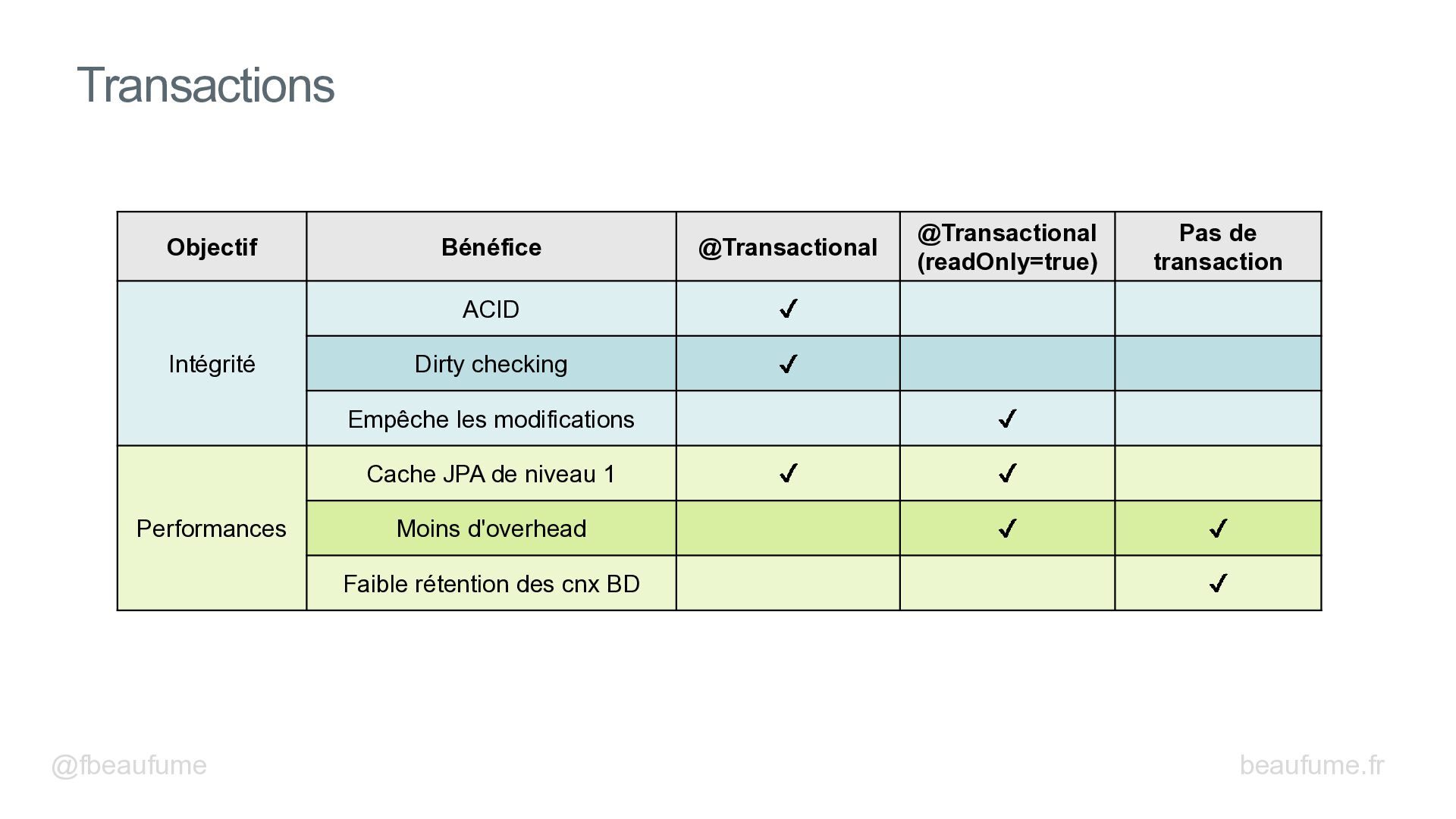{kind=link}
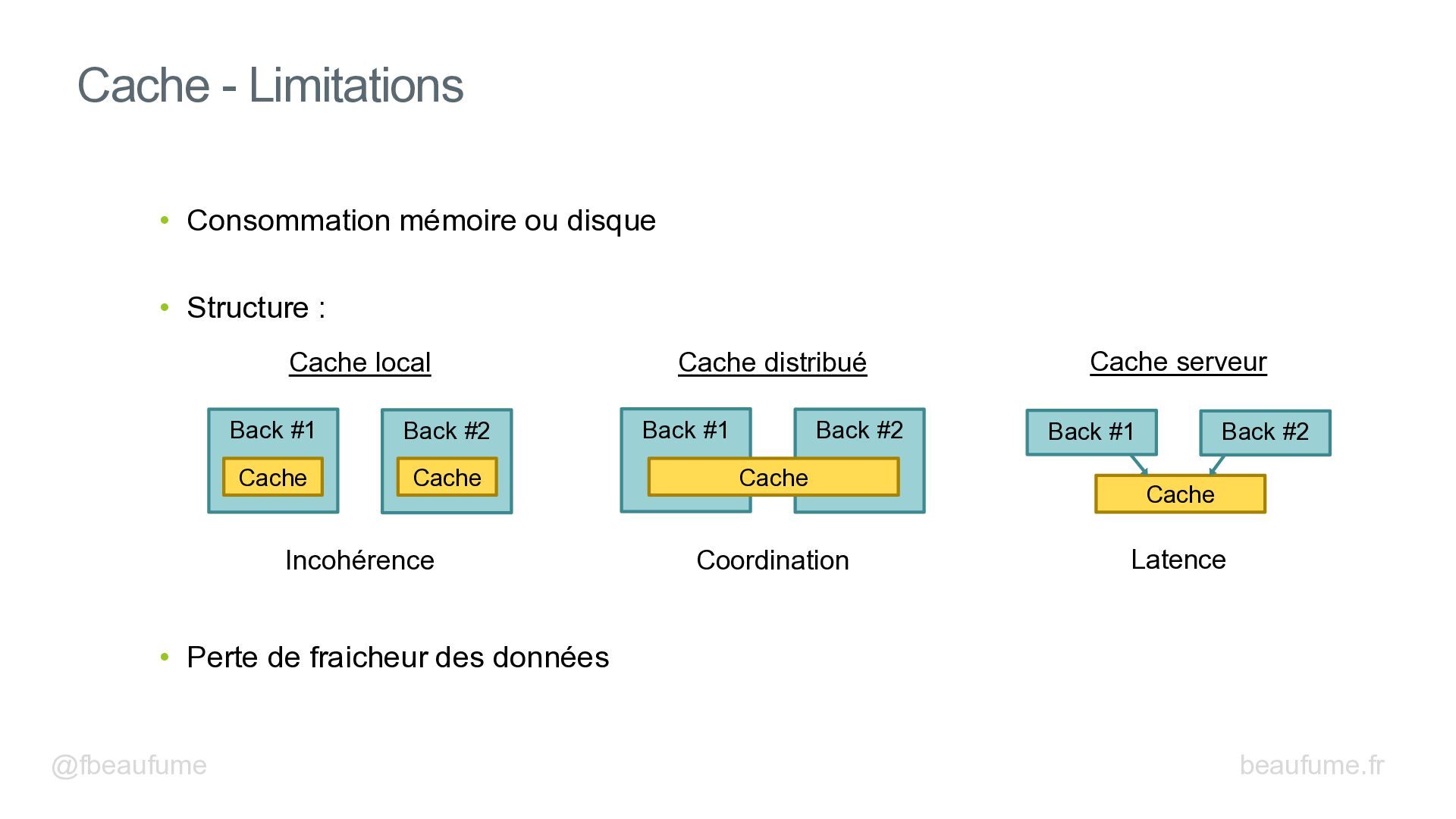{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}