pd.read_csv(bad_file_to_import_in_neo4j.csv) # Handle NaNs df.fillna(replacement) # Clean/replace bad chars in column names df.columns = df.columns.str.replace(names_with_no_punctuation) df.columns = [names_with_no_spaces] # Set Types - recommended df[‘column’].astype(‘int64’) # Save df.to_csv(good_file_to_import_in_neo4j.csv) Data Import in Neo4j (up to 10M records)
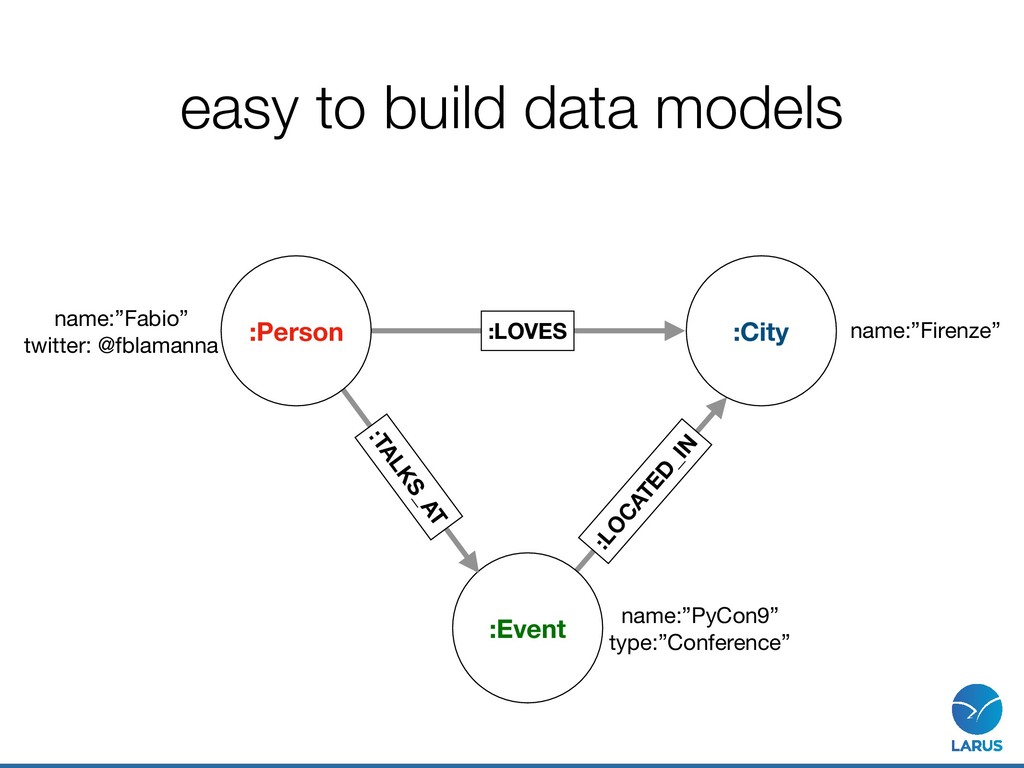
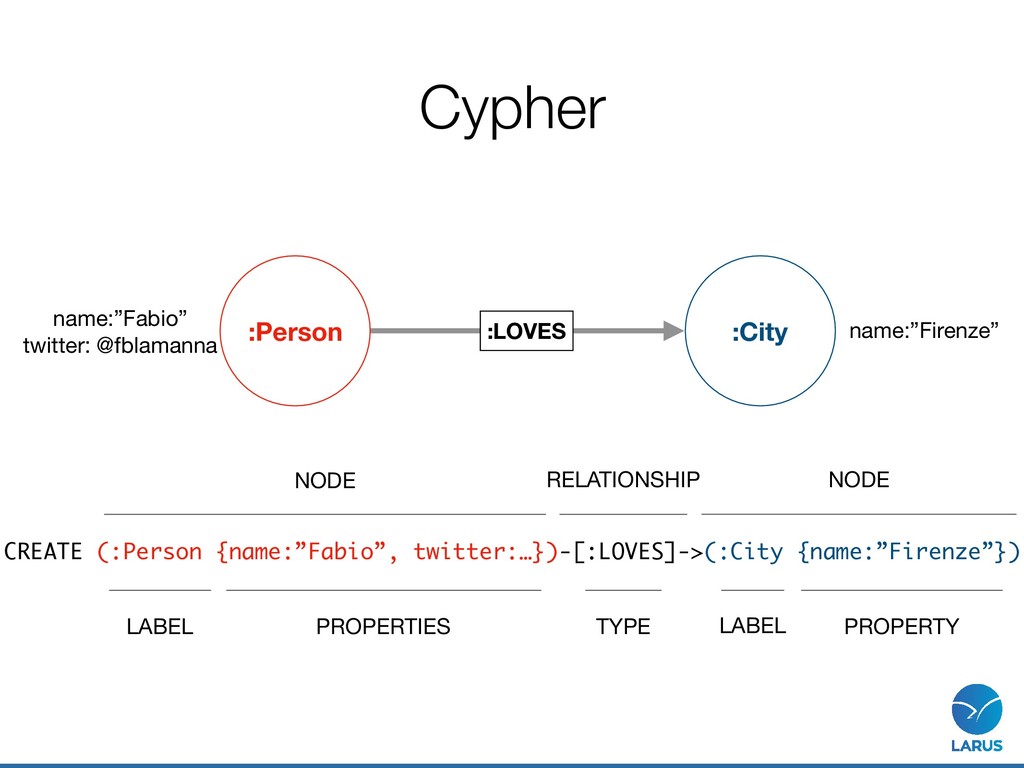
Relationship >>> a = Node("Person", name="Fabio") >>> b = Node("City", cityname="Firenze") >>> c = Node("Event", name="PyCon9") >>> ab = Relationship(a, "LOVES", b) >>> ab (Fabio)-[:LOVES]->(Firenze) >>> ac = Relationship(a, "TALKS_AT", c) >>> ac (Fabio)-[:TALKS_AT]->(PyCon9)
s = ab | ac {(fabio:Person {name:"Fabio"}), (firenze:City {name:"Firenze"}), (pycon9:Event {name:"PyCon9"}), (Fabio)-[:LOVES]->(Firenze), (Fabio)-[:TALKS_AT]->(PyCon9)} # Intersection >>> s = ab & ac {(fabio:Person {name:"Fabio"})}
from pypher import Pypher q = Pypher() q.Match.node("a", labels="Person").WHERE.a.property("twitter") == "@fblamanna" q.RETURN.a MATCH (a:Person) WHERE a.twitter = "@fblamanna" RETURN a
from pypher import Pypher q = Pypher() p.Match.node('a').relationship('r').node('b').RETURN('a', 'b', 'r') >>> print(p) Cypher: MATCH ('a')-['r']-('b') RETURN a, b, r
Data preparation I/O operations Official driver + Packages (py2neo, Pypher and more to come…) Discover the potential of Neo4j with your favourite snake!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![recommendations MATCH (you)-[:BOUGHT]->(something)<-[:BOUGHT]-(other)-[:BOUGHT]->(reco) WHERE id(you) = “Fabio” RETURN](https://files.speakerdeck.com/presentations/35a9dc520f954f449f010ade3bacc5d0/slide_20.jpg){kind=link}
![paradise papers MATCH p=(o:Officer {name: "The Duchy of Lancaster"})-[*..2]-() RETURN](https://files.speakerdeck.com/presentations/35a9dc520f954f449f010ade3bacc5d0/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![(fabio)-[:THANKS]->(PyCon9) Fabio Lamanna @fblamanna](https://files.speakerdeck.com/presentations/35a9dc520f954f449f010ade3bacc5d0/slide_45.jpg){kind=link}