Observability (e.g. Elasticsearch, Kibana, Prometheus, Sentry, Grafana, FluentBit, Datadog) • ML Experiment Management ( e.g. ModelChimp, Randopt, Forge, Lore, Datmo, Studio ML, Sacred, MLFlow, Polyaxon) • Data Versioning and management (e.g. DVC, Pachyderm, Snorkel) • ML SaaS (e.g. Algorithmia, Peltarion, Databricks, Seldon IO, Google AI Platform, AWS Sage Maker, Azure ML Studio, Dotscience, Daitaku DSS, Domino AI, Polyaxon, Weights & Biases, Spell, Gradient, Paperspace, H2O AI, Stack ML, Comet, Valohai, Neptune AI) SOME TOOLS
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
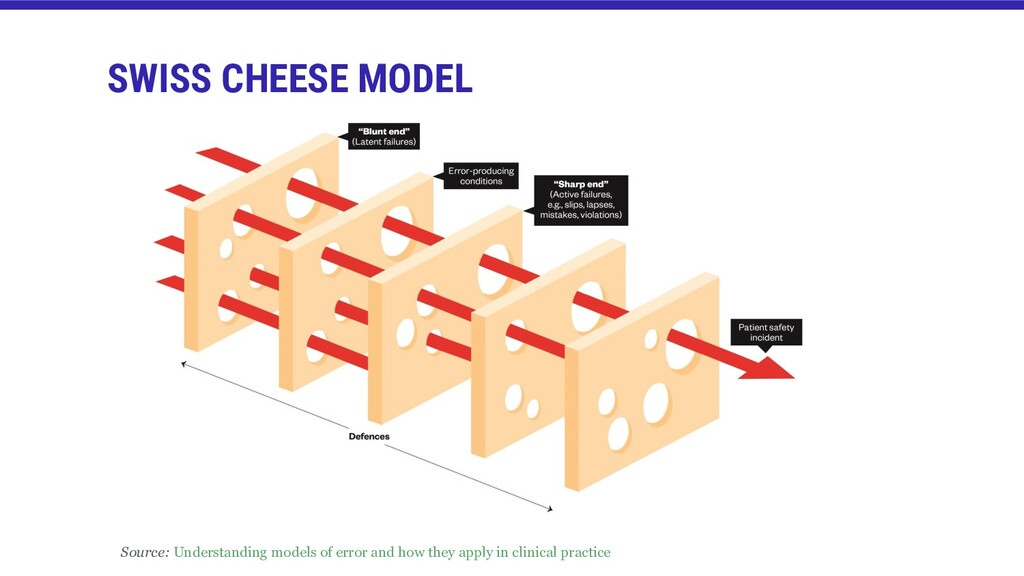
![DEFENSES, BARRIERS, SAFEGUARDS [...] High-tech systems have many defensive layers:](https://files.speakerdeck.com/presentations/28d7646be79e4cf48faefeb5088dcc6c/slide_13.jpg){kind=link}
![[...] In an ideal world, each defensive layer would be](https://files.speakerdeck.com/presentations/28d7646be79e4cf48faefeb5088dcc6c/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![LATENT CONDITIONS [...] Latent conditions are like a kind of](https://files.speakerdeck.com/presentations/28d7646be79e4cf48faefeb5088dcc6c/slide_18.jpg){kind=link}
![ACTIVE FAILURES [...]Active failures are insecure acts or minor transgressions](https://files.speakerdeck.com/presentations/28d7646be79e4cf48faefeb5088dcc6c/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}