自動運転時代には、今よりも更新頻度の高い地図が必要です。MoTでは大手地図会社であるゼンリンとの共同開発により、ドライブレコーダの動画を元に道路情報の差分を自動で抽出し、地図更新に役立てるプロジェクトを行っています。このプロジェクトを紹介します。
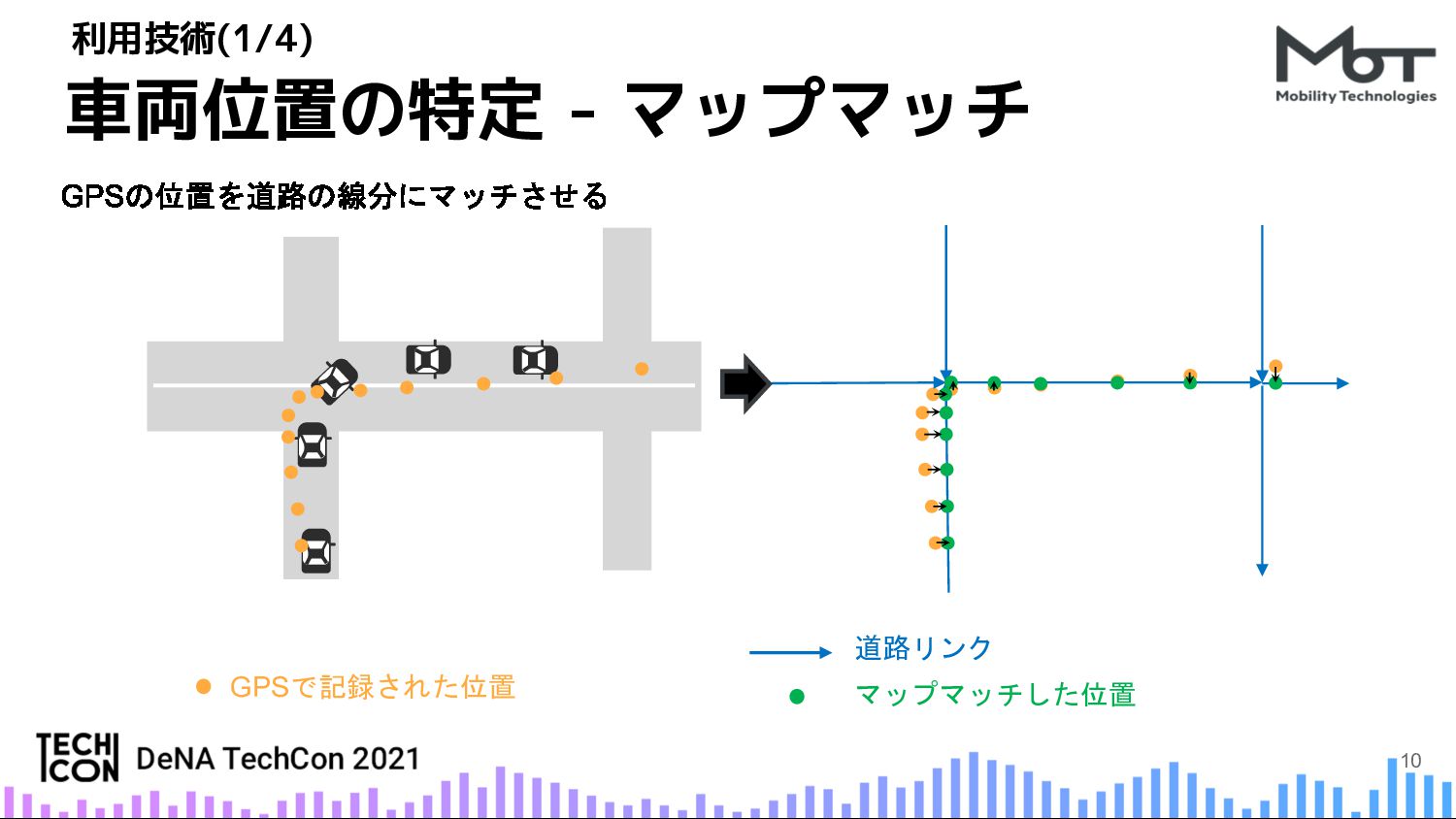
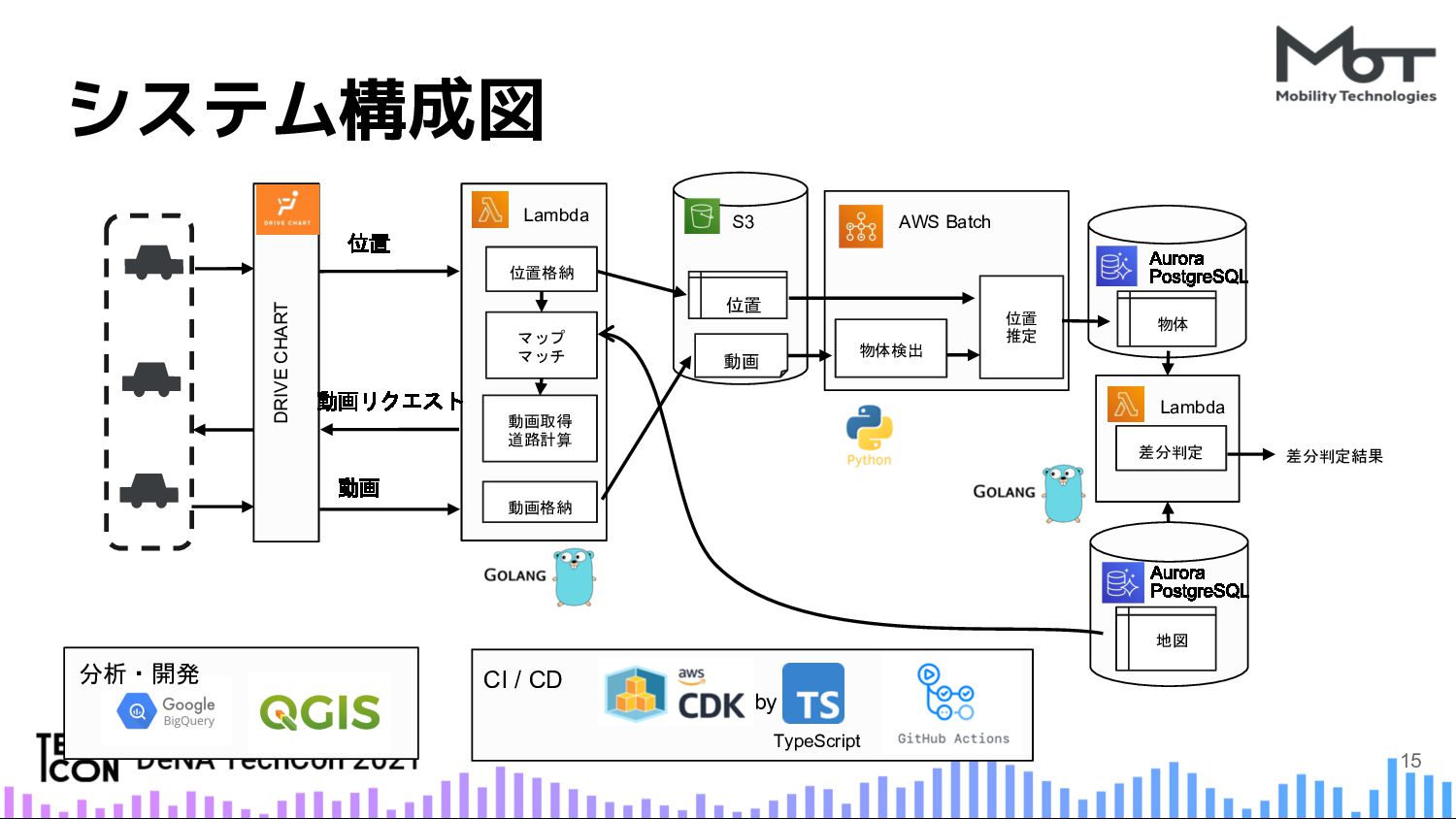
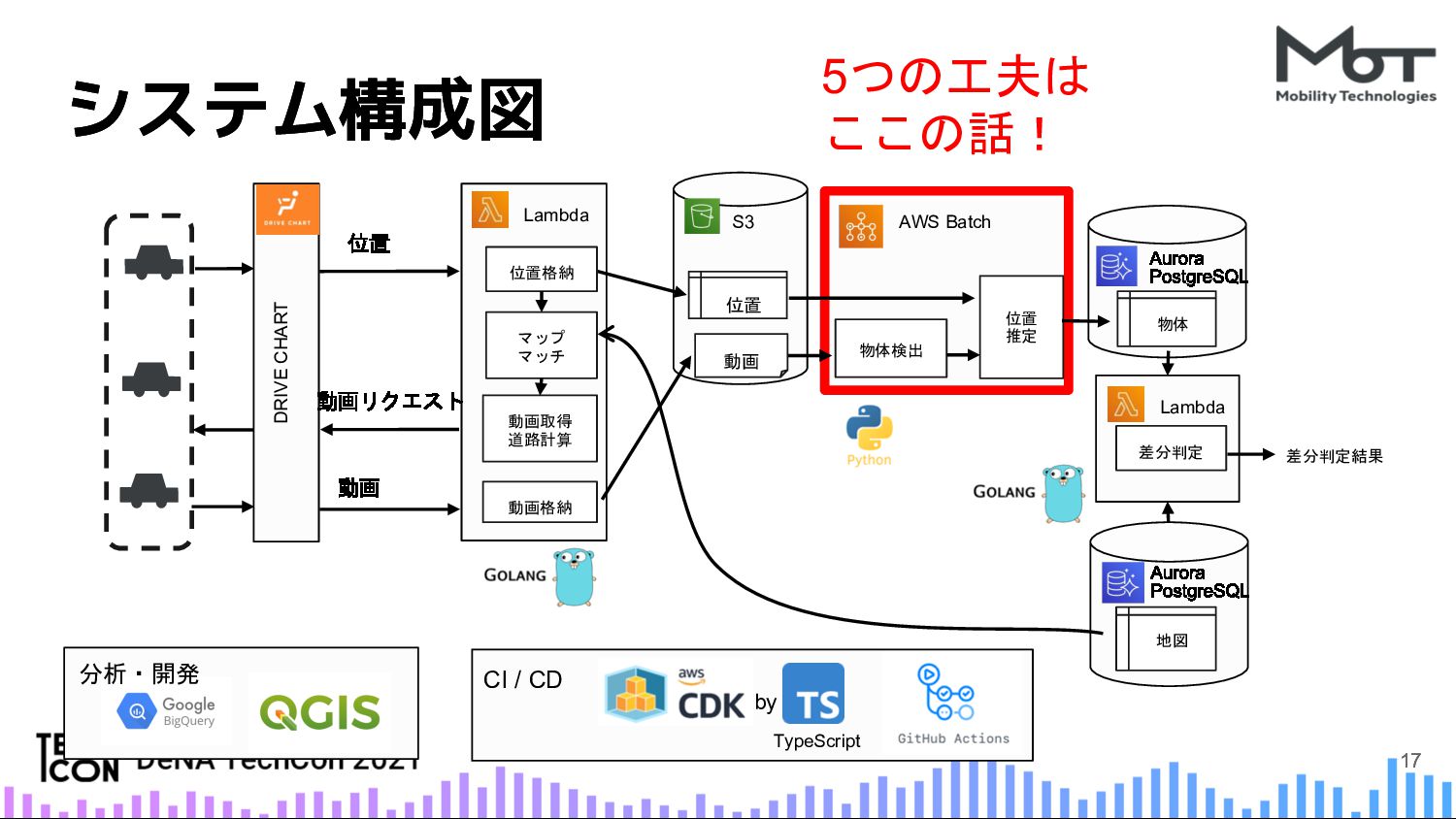
技術的な紹介ポイントとしては、次のものになります。マップマッチ、機械学習(ディープラーニング)、SLAMそしてGISツール等を組み合わせた高度なアプリケーション。大量の動画データに対して分散処理するために、AWS FSx for LustreやAWS Batchを用いてシステムを構成。計算コストの高い機械学習推論処理を最適化する工夫。データサイエンティストの成果物を本番に取り込むためのフレームワーク。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
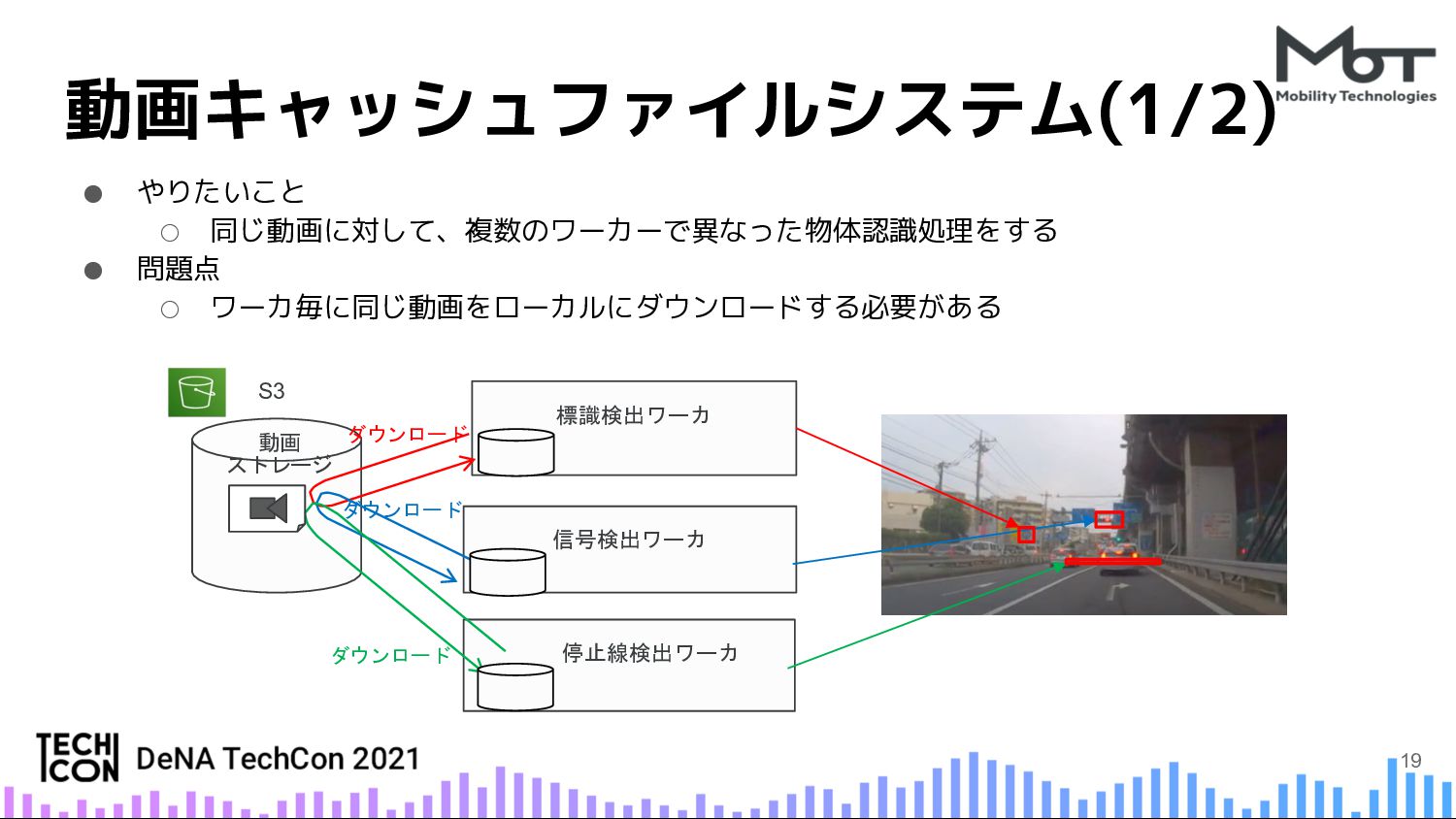{kind=link}
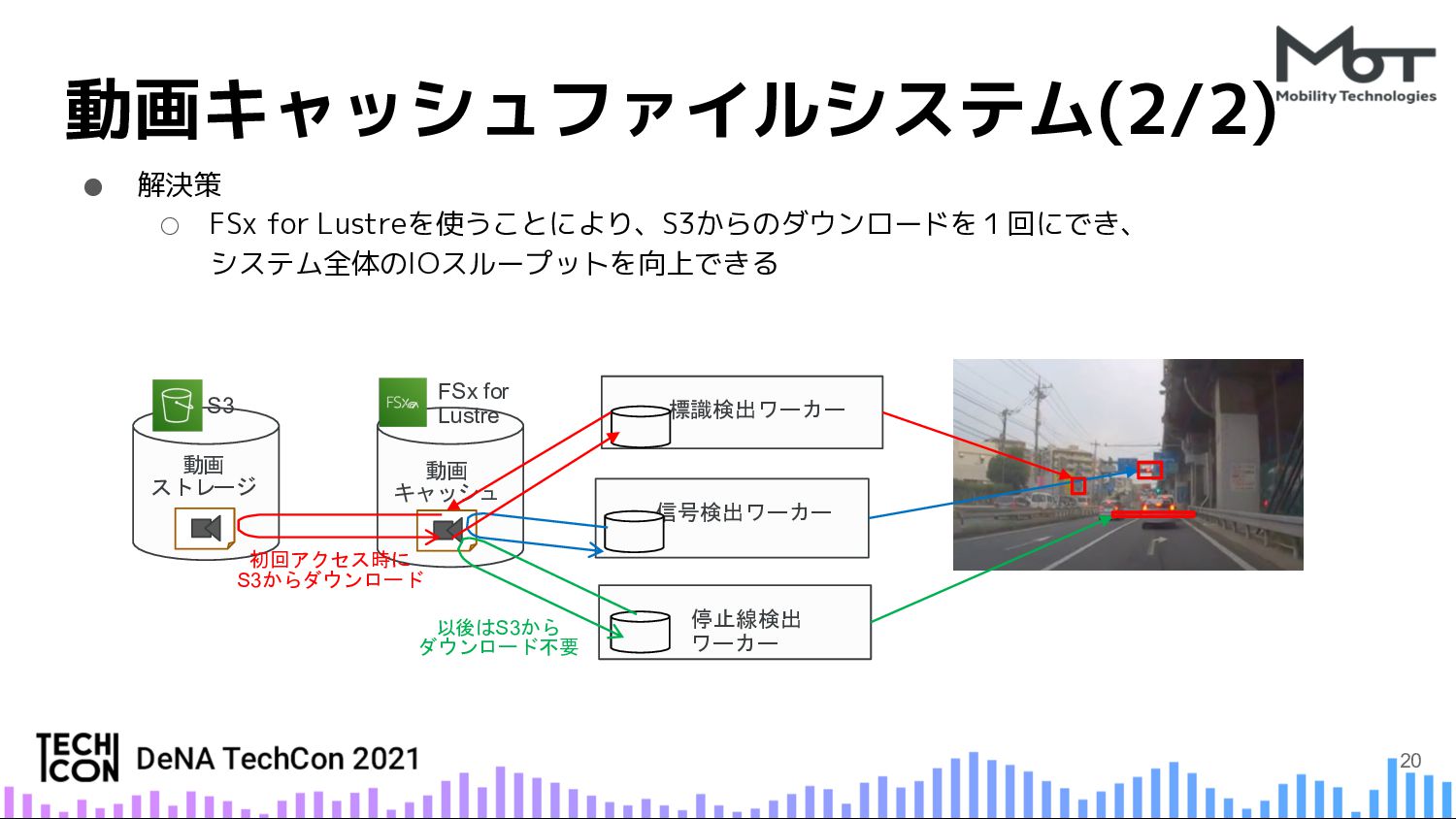{kind=link}
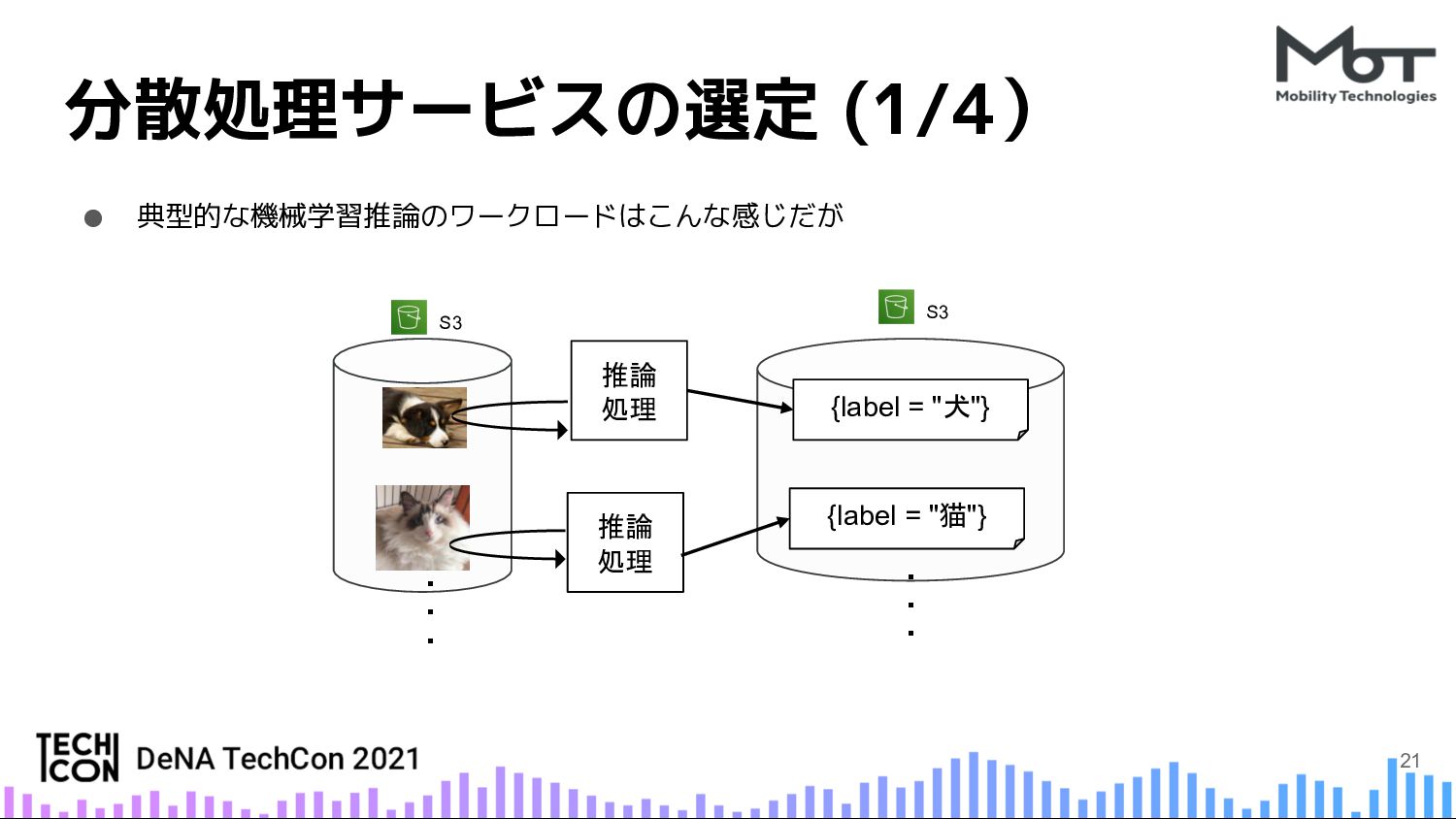{kind=link}
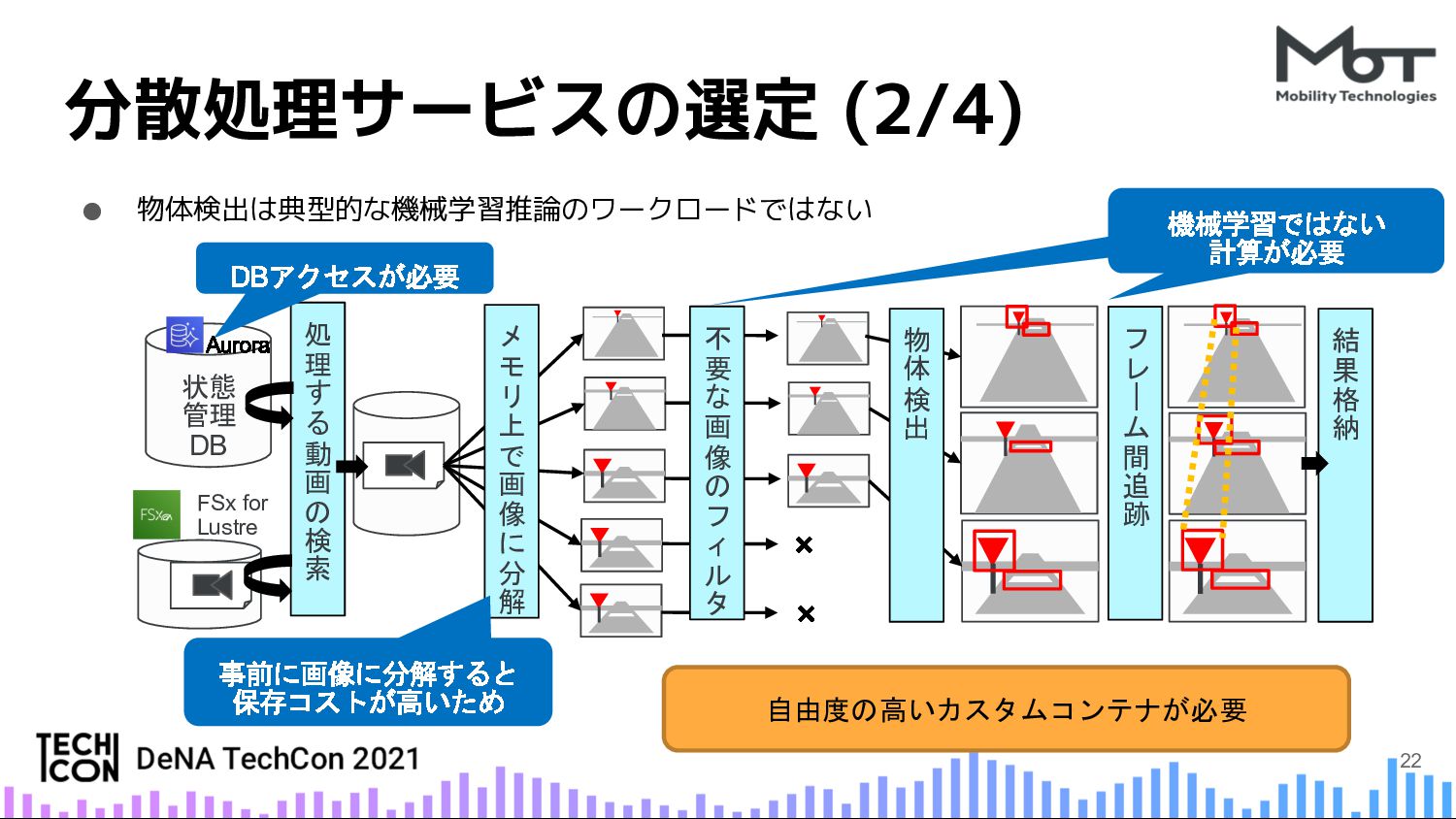{kind=link}
{kind=link}
{kind=link}
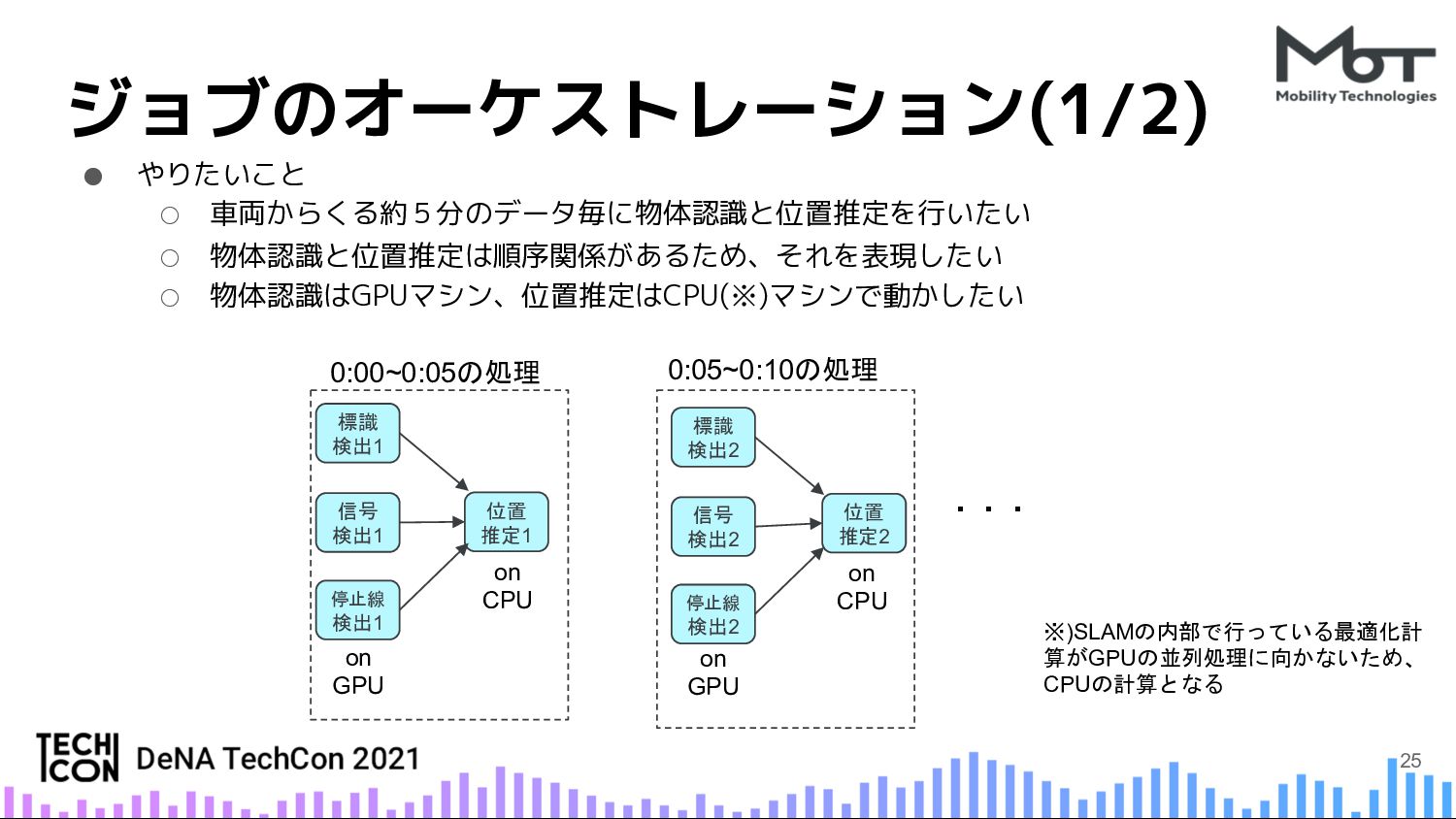{kind=link}
{kind=link}
{kind=link}
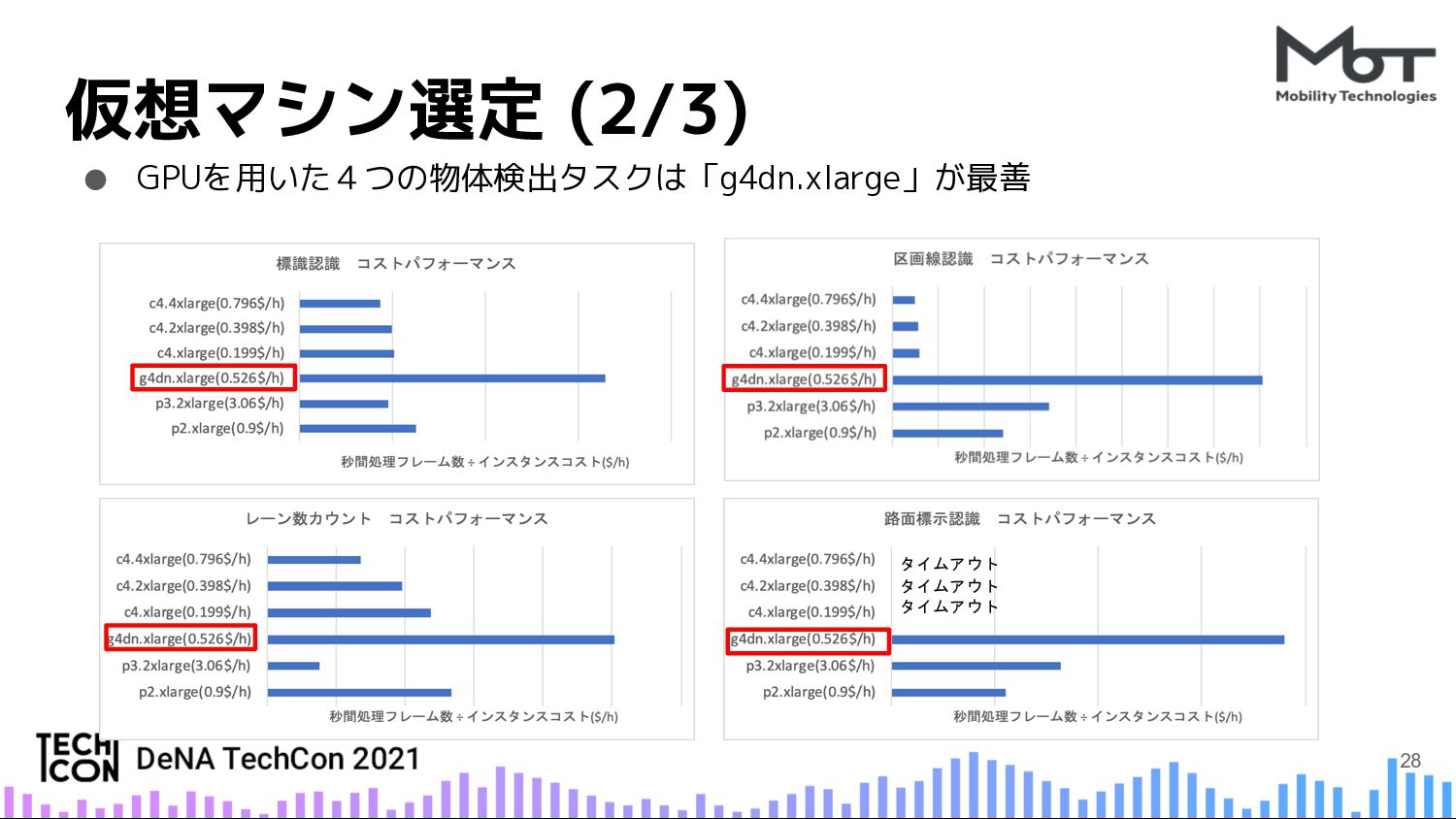{kind=link}
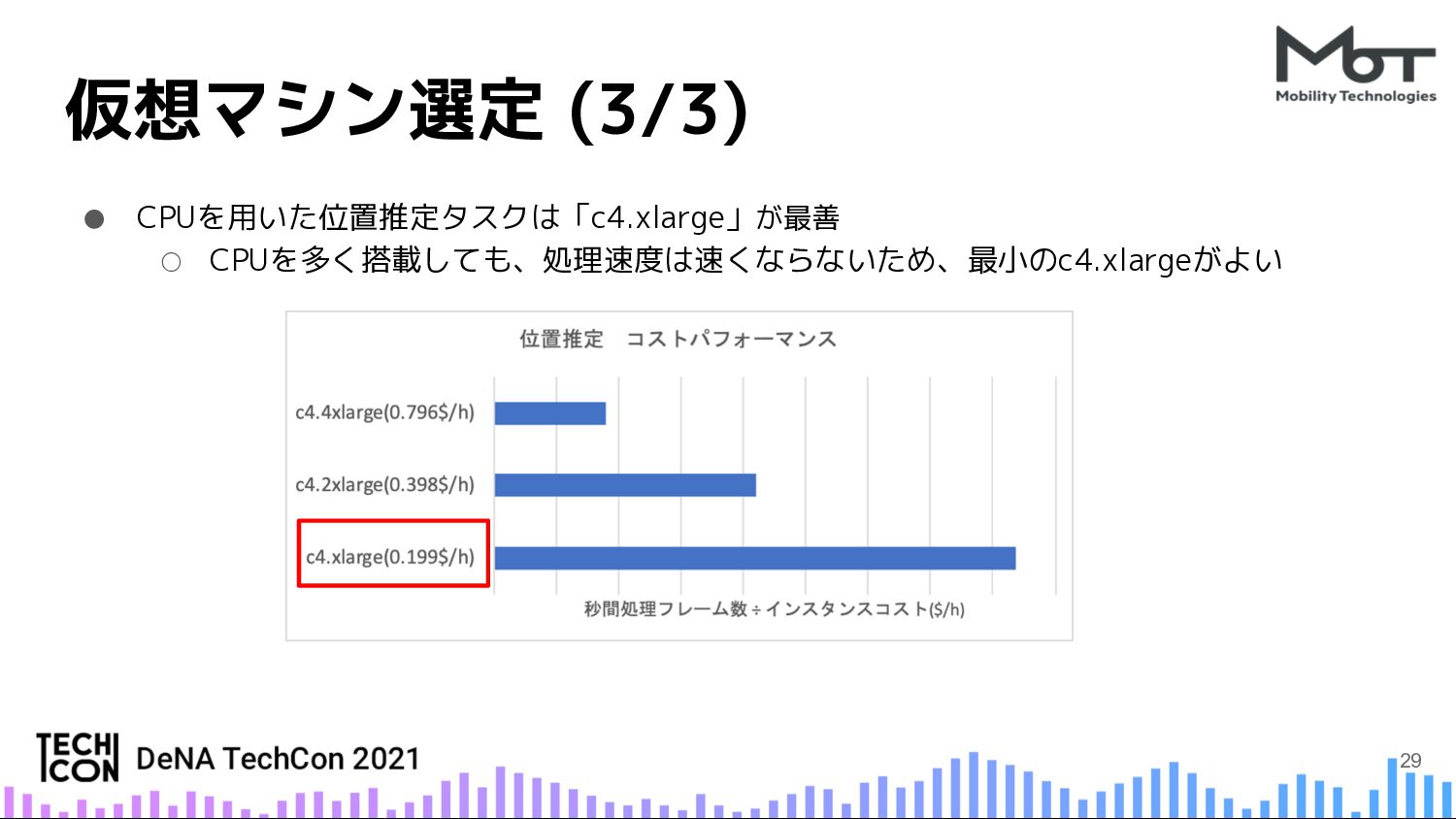{kind=link}
{kind=link}
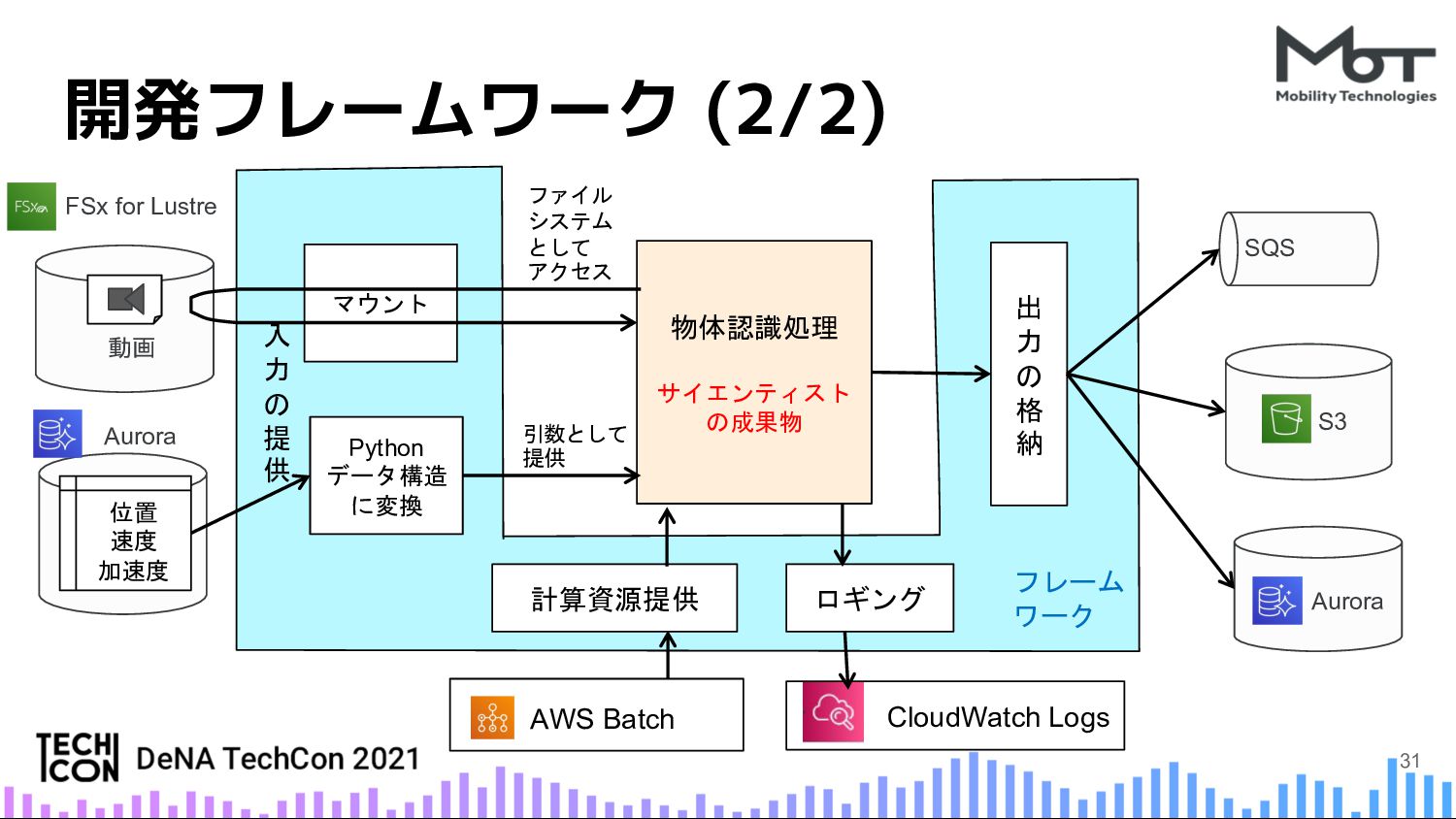{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}