Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
Search
株式会社フィックスターズ
March 31, 2022
Programming
320
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編
2022年1月28日開催の「CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編」セミナー資料です。
株式会社フィックスターズ
March 31, 2022
More Decks by 株式会社フィックスターズ
See All by 株式会社フィックスターズ
コンピュータービジョンセミナー5 / 3次元復元アルゴリズム Multi-View Stereo の CUDA高速化
fixstars
0
1.2k
Kaggle_スコアアップセミナー_DFL-Bundesliga_Data_Shootout編/Kaggle_fixstars_corporation_20230509
fixstars
1
1.2k
実践的!FPGA開発セミナーvol.21 / FPGA_seminar_21_fixstars_corporation_20230426
fixstars
0
1.6k
量子コンピュータ時代のプログラミングセミナー / 20230413_Amplify_seminar_shift_optimization
fixstars
0
1.2k
実践的!FPGA開発セミナーvol.18 / FPGA_seminar_18_fixstars_corporation_20230125
fixstars
0
1k
実践的!FPGA開発セミナーvol.19 / FPGA_seminar_19_fixstars_corporation_20230222
fixstars
0
1.1k
実践的!FPGA開発セミナーvol.20 / FPGA_seminar_20_fixstars_corporation_20230329
fixstars
0
950
量子コンピュータ時代のプログラミングセミナー / 20230316_Amplify_seminar _route_planning_optimization
fixstars
0
920
量子コンピュータ時代のプログラミングセミナー / 20230216_Amplify_seminar _production_planning_optimization
fixstars
0
800
Other Decks in Programming
See All in Programming
LLMによるContent Moderationの本番運用の裏側と品質担保への挑戦
suikabar
3
860
ルールを書いて終わらせないハーネスエンジニアリング
yug1224
3
1.5k
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
500
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.8k
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
110
act2-costs.pdf
sumedhbala
0
110
はてなアカウント基盤 State of the Union
cockscomb
1
1.3k
AI がコードを書く時代における新卒エンジニアの仕事風景 (2026) / New Graduate Engineers in the Era of AI Coding (2026)
sushichan044
0
220
型も通る、synthも通る、それでも危ない 〜AIのCDKの権限とコストを機械で検証する〜 / It Passes Type Checks, It Passes Synth Checks, but It’s Still Risky — Automatically Verifying Permissions and Costs in AI’s CDK —
seike460
PRO
1
360
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
150
自作OSでスライド発表する
uyuki234
1
3.8k
Featured
See All Featured
Ruling the World: When Life Gets Gamed
codingconduct
0
280
My Coaching Mixtape
mlcsv
0
170
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
600
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
The Limits of Empathy - UXLibs8
cassininazir
1
500
Automating Front-end Workflow
addyosmani
1370
210k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Faster Mobile Websites
deanohume
310
32k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Marketing to machines
jonoalderson
1
5.6k
Transcript
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group CPU / GPU 高速化セミナー 性能モデルの理論と実践:理論編
Fixstars Group www.fixstars.com Copyright © Fixstars Group 本ウェビナーは 2部構成 2
• 理論編(本日) • 実践編(近日開催予定!)
Fixstars Group www.fixstars.com Copyright © Fixstars Group 発表者紹介 3 •
冨田 明彦(とみた あきひこ) ソリューションカンパニー 営業企画執行役 2008年に入社。金融、医療業界において、 ソフトウェア高速化業務に携わる。その 後、新規事業企画、半導体業界の事業を 担当し、現職。 • 秋山 茂樹(あきやま しげき) ソリューション第一事業部 リードエンジニア 2016年に入社。主に画像処理・機械学習 ソフトウェアについて x86-64 CPU や NVIDIA/AMD GPU, InfiniBand を用い た高速化業務を担当。
Fixstars Group www.fixstars.com Copyright © Fixstars Group 本日のAgenda はじめに (15分)
• 性能に関する課題 • 高速化サービスと開発の流れ 性能モデルの理論と検証 (60分) • 性能モデルが必要となる背景 • 性能モデルとは • ルーフラインモデル • ベンチマークによるルーフラインモデルの検証 Q&A / 告知 4
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group はじめに
Fixstars Group www.fixstars.com Copyright © Fixstars Group 性能に関する課題 6 生産効率の向上
• より短時間で欠陥検出 • より安価なハードで 安全性の向上 • より精度の高い物体検出 • より低消費電力なハードで
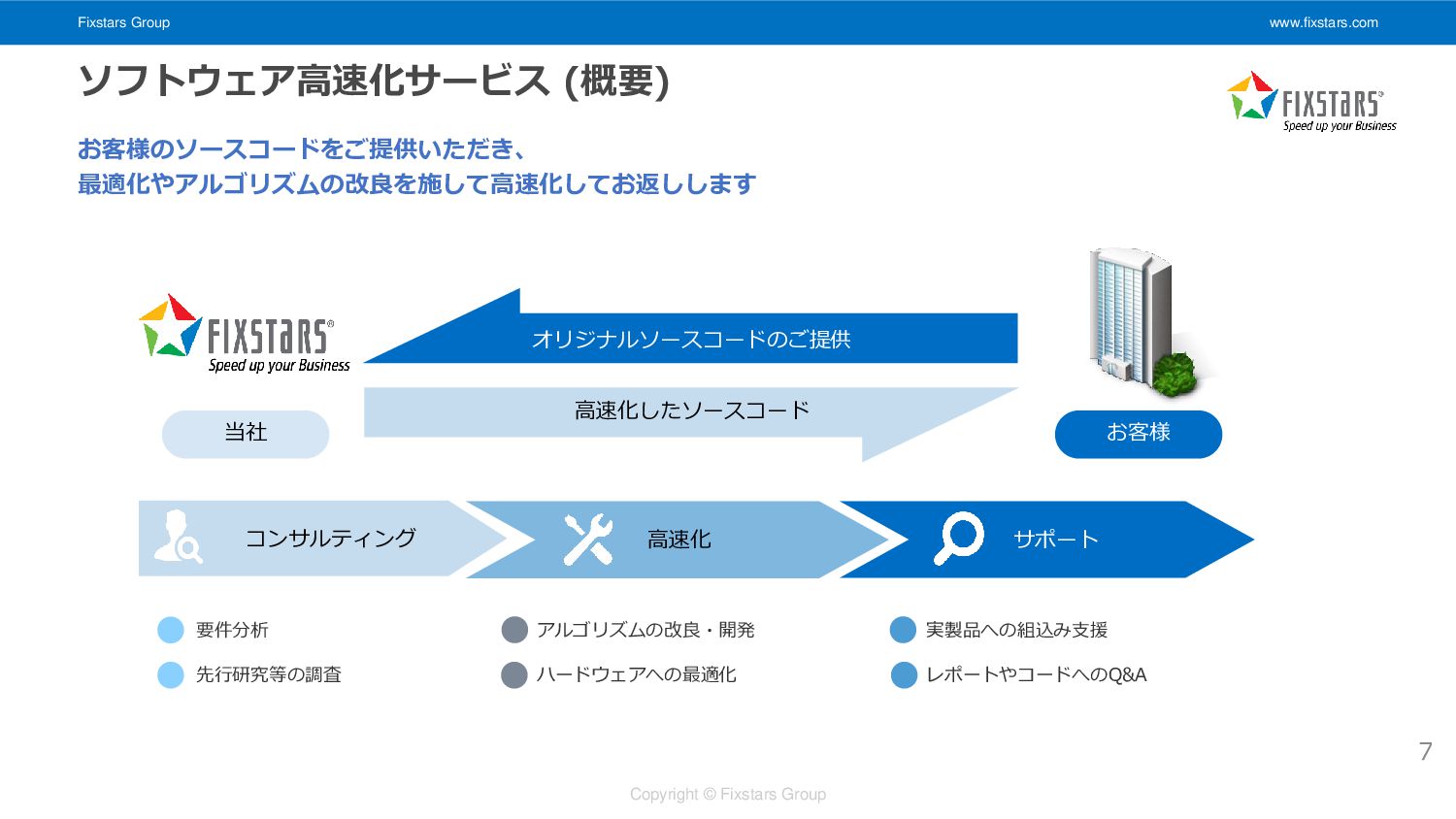
Fixstars Group www.fixstars.com Copyright © Fixstars Group ソフトウェア高速化サービス (概要) お客様のソースコードをご提供いただき、
最適化やアルゴリズムの改良を施して高速化してお返しします 当社 お客様 オリジナルソースコードのご提供 高速化したソースコード コンサルティング 高速化 サポート 要件分析 先行研究等の調査 アルゴリズムの改良・開発 ハードウェアへの最適化 実製品への組込み支援 レポートやコードへのQ&A 7
Fixstars Group www.fixstars.com Copyright © Fixstars Group ソフトウェア高速化サービス 様々な領域でソフトウェア高速化サービスを提供しています 大量データの高速処理は、お客様の製品競争力の源泉となっています
・NAND型フラッシュメモリ向けファー ムウェア開発 ・次世代AIチップ向け開発環境基盤開発 Semiconductor ・デリバティブシステムの高速化 ・HFT(アルゴリズムトレード)の高速化 Finance ・自動運転の高性能化、実用化 ・次世代パーソナルモビリティの研究開発 Mobility ・ゲノム解析の高速化 ・医用画像処理の高速化 ・AI画像診断システムの研究開発 Life Science ・Smart Factory化支援 ・マシンビジョンシステムの高速化 Industrial 8
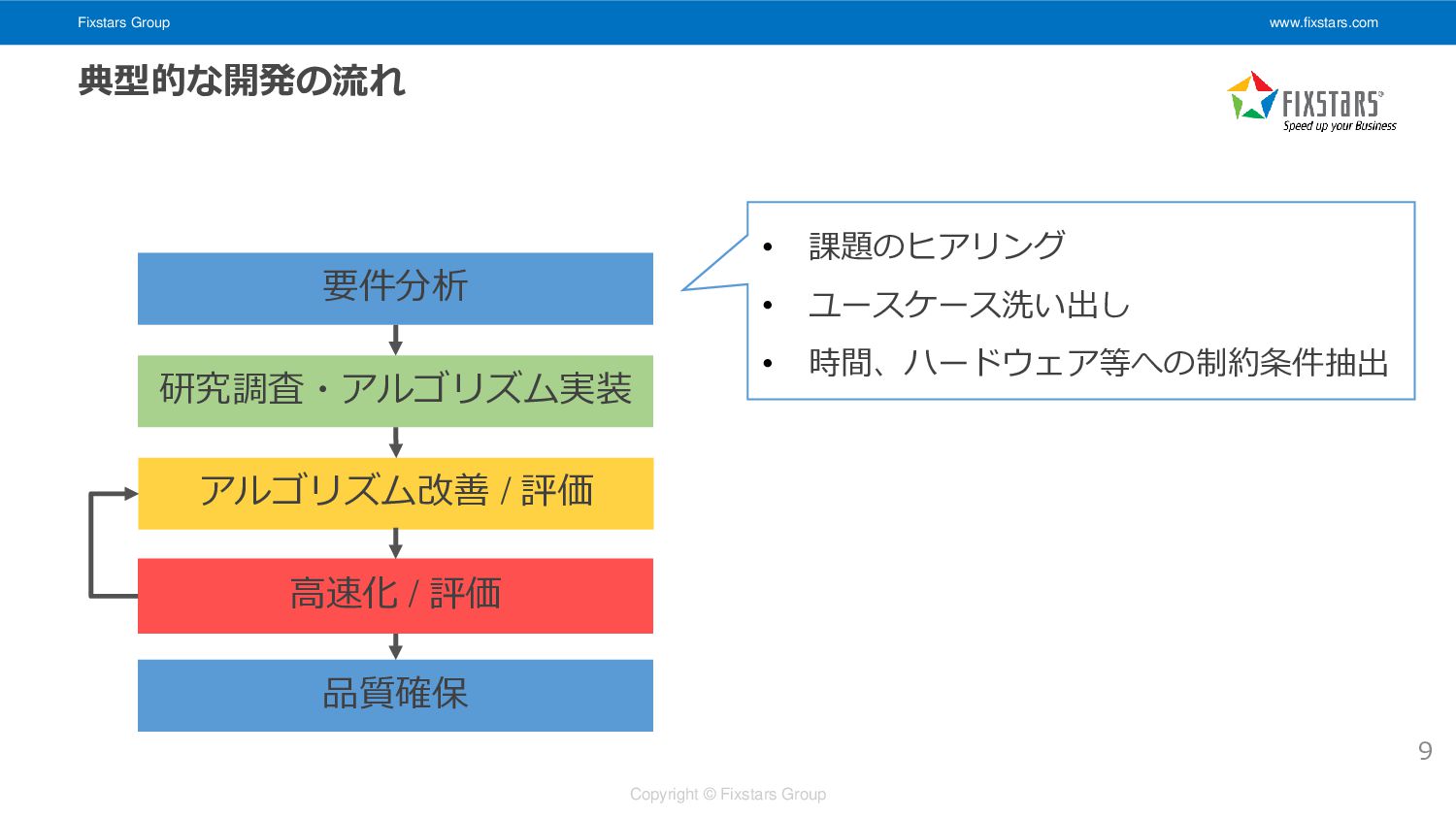
Fixstars Group www.fixstars.com Copyright © Fixstars Group 9 要件分析 研究調査・アルゴリズム実装
高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • 課題のヒアリング • ユースケース洗い出し • 時間、ハードウェア等への制約条件抽出
Fixstars Group www.fixstars.com Copyright © Fixstars Group 10 要件分析 研究調査・アルゴリズム実装
高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • 論文等サーベイ • アルゴリズム候補の絞り込み • アルゴリズムの比較と評価 • アルゴリズムの決定と実装
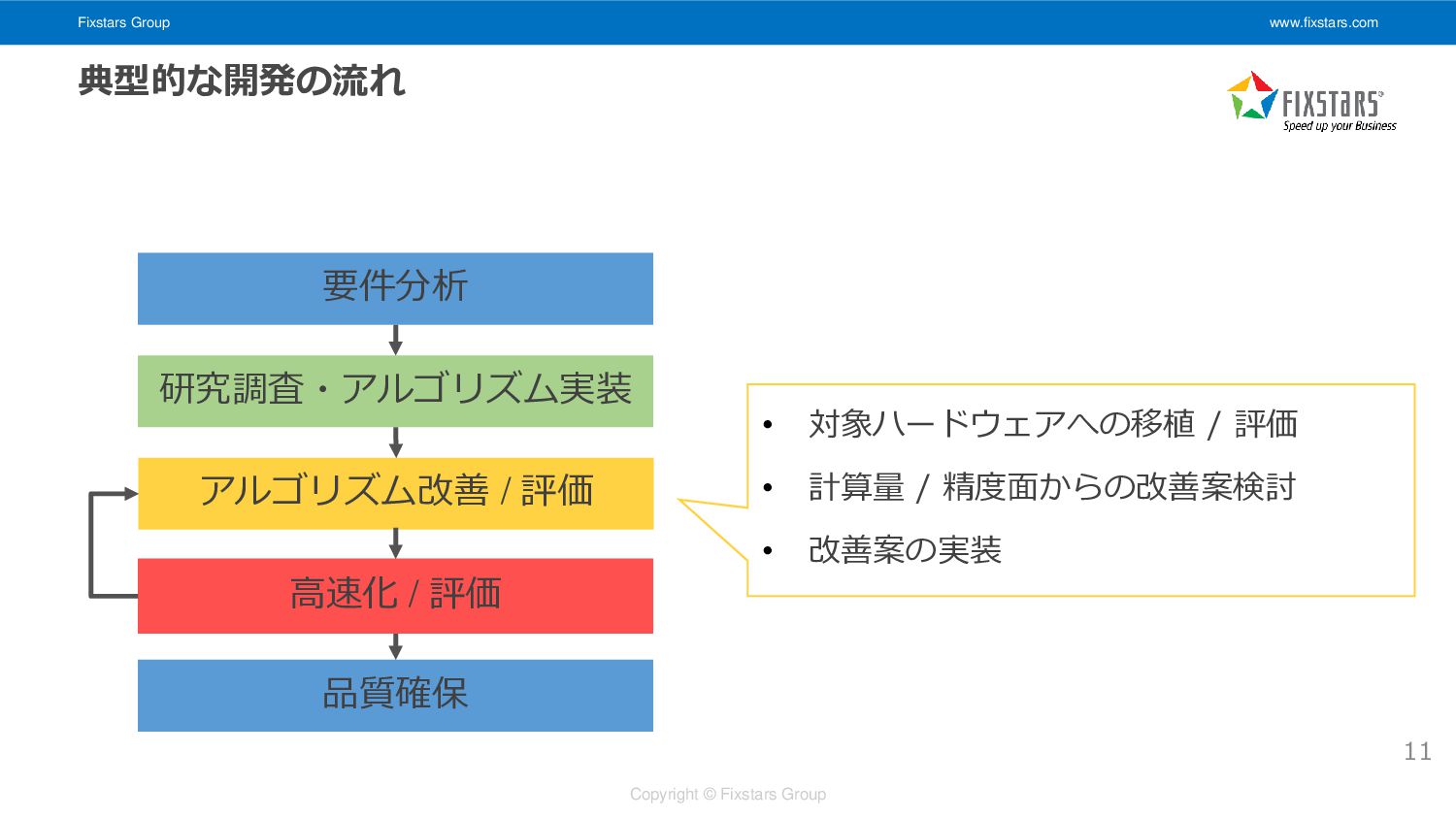
Fixstars Group www.fixstars.com Copyright © Fixstars Group 11 要件分析 研究調査・アルゴリズム実装
高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • 対象ハードウェアへの移植 / 評価 • 計算量 / 精度面からの改善案検討 • 改善案の実装
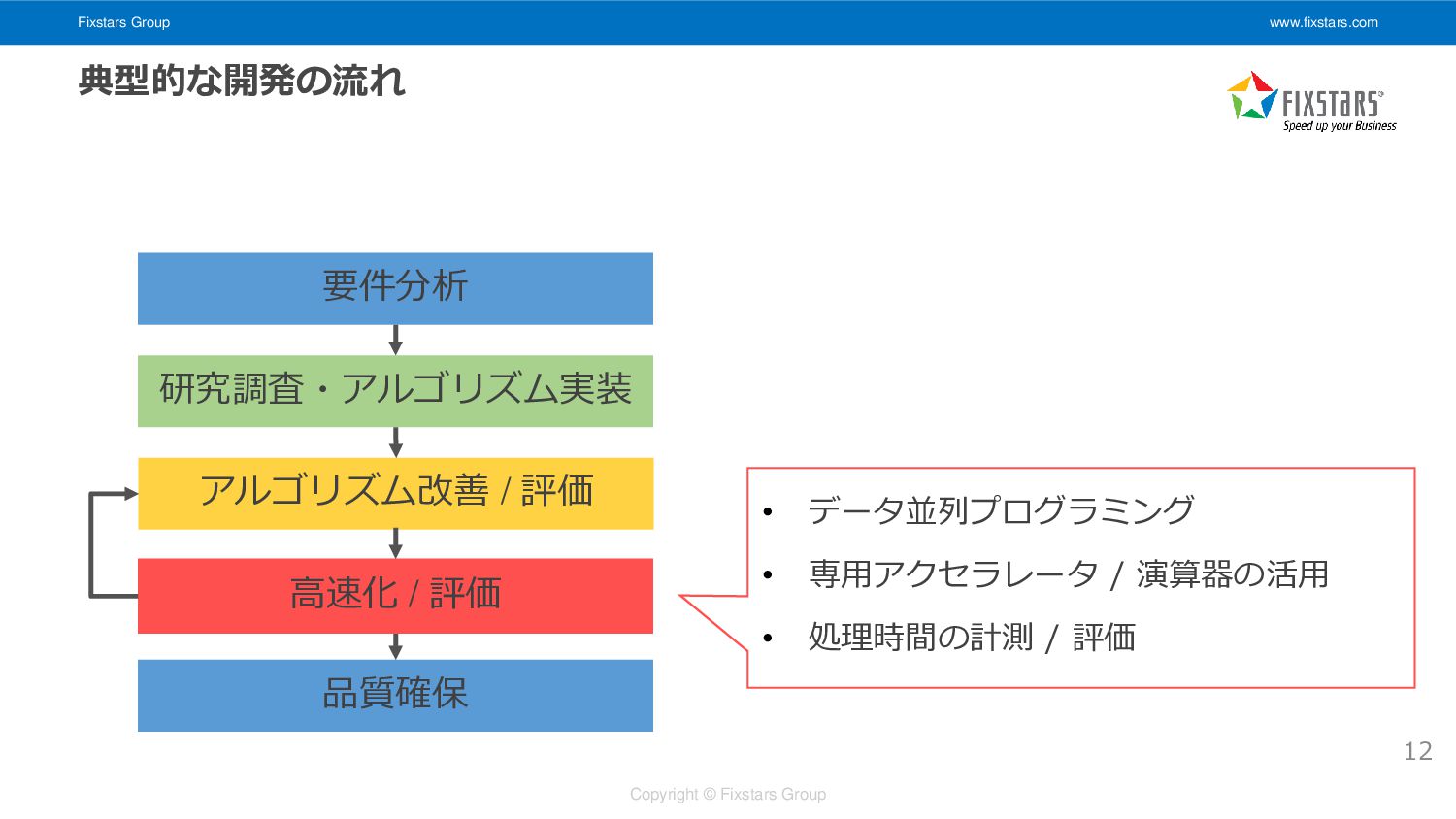
Fixstars Group www.fixstars.com Copyright © Fixstars Group 12 要件分析 研究調査・アルゴリズム実装
高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • データ並列プログラミング • 専用アクセラレータ / 演算器の活用 • 処理時間の計測 / 評価
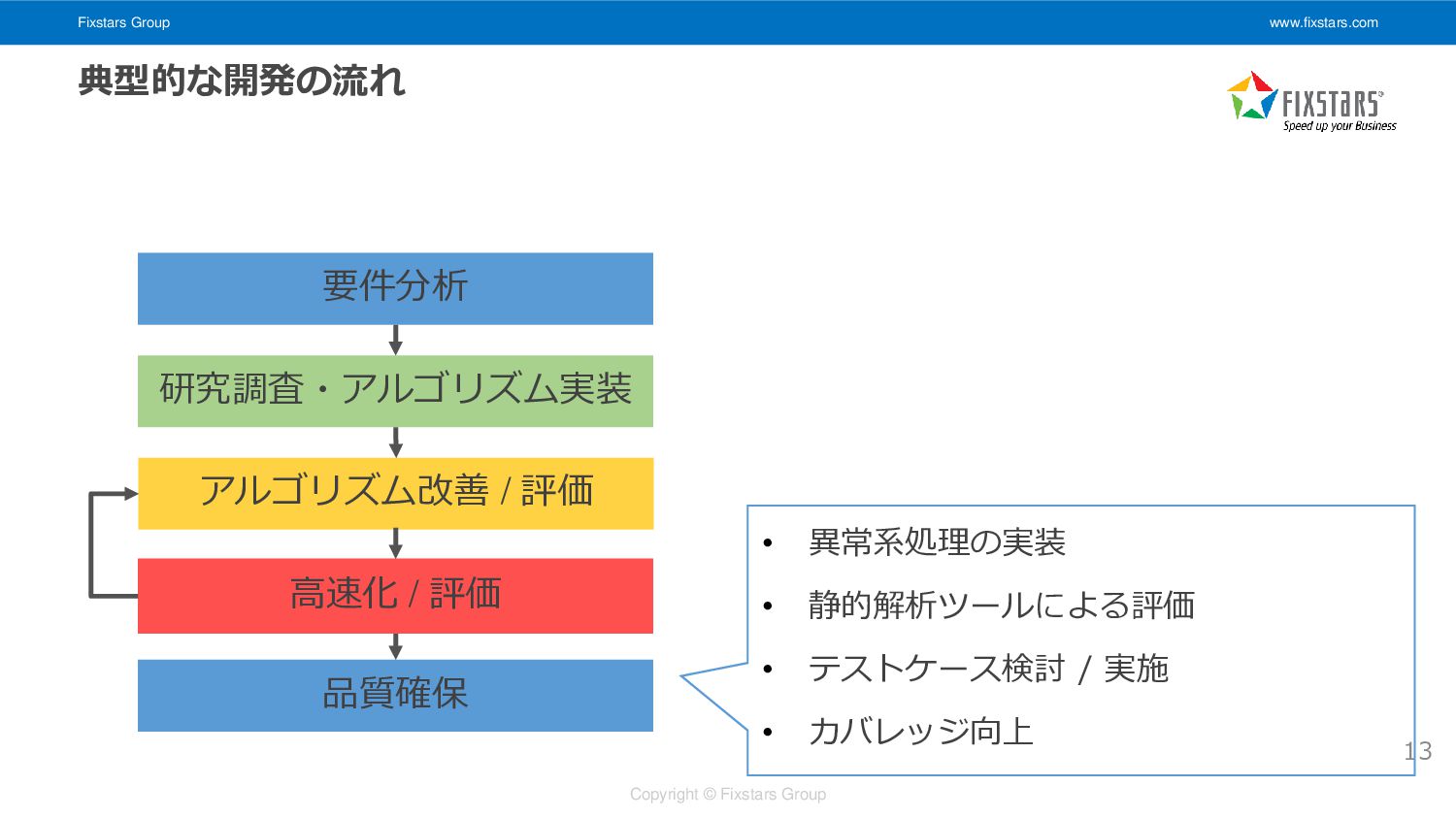
Fixstars Group www.fixstars.com Copyright © Fixstars Group 13 要件分析 研究調査・アルゴリズム実装
高速化 / 評価 アルゴリズム改善 / 評価 品質確保 典型的な開発の流れ • 異常系処理の実装 • 静的解析ツールによる評価 • テストケース検討 / 実施 • カバレッジ向上
Fixstars Group www.fixstars.com Copyright © Fixstars Group 本ウェビナーの対象プロセス 14 ココ
要件分析 研究調査・アルゴリズム実装 高速化 / 評価 アルゴリズム改善 / 評価 品質確保
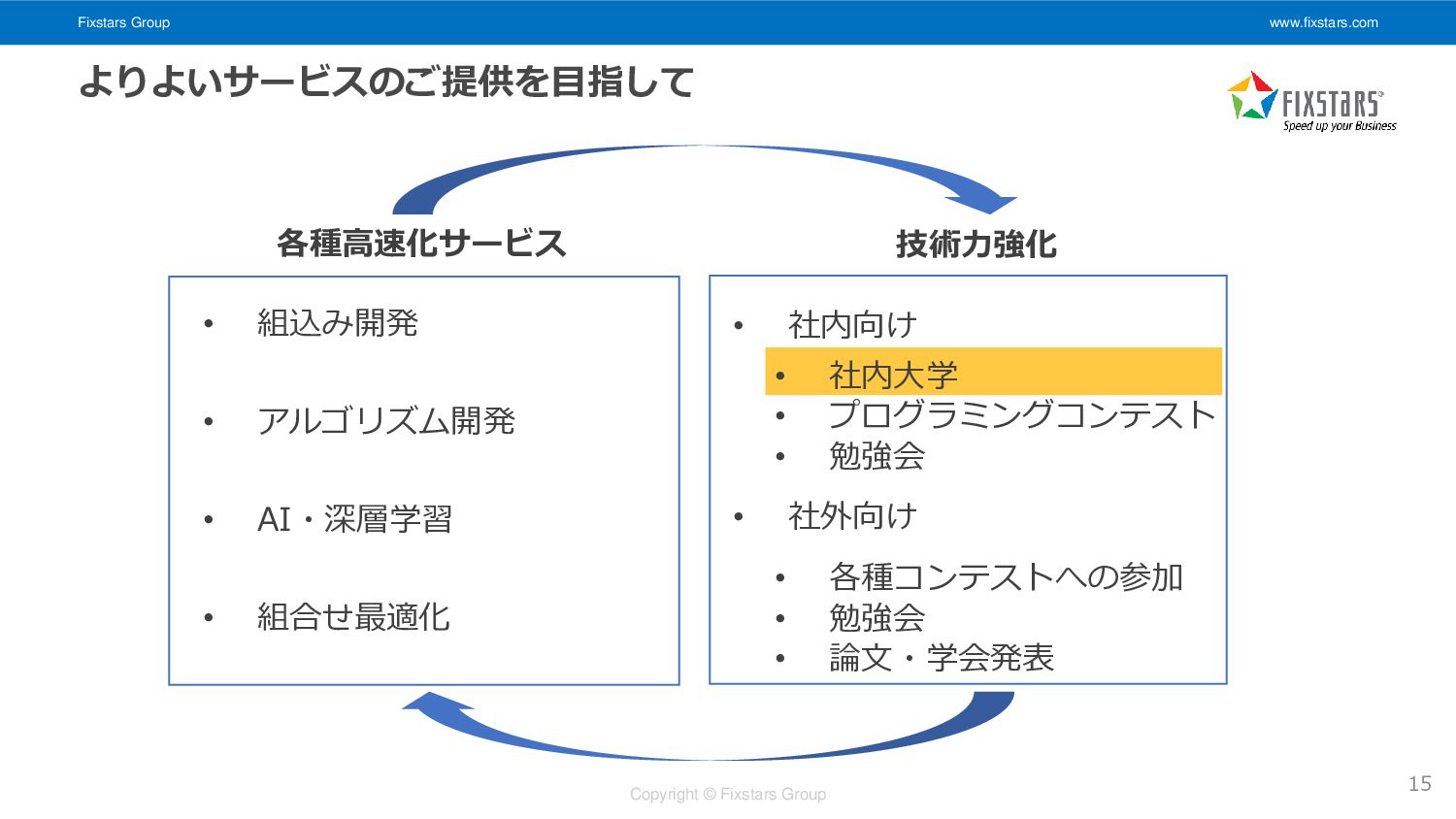
Fixstars Group www.fixstars.com Copyright © Fixstars Group • 社内大学 •
プログラミングコンテスト • 勉強会 • 各種コンテストへの参加 • 勉強会 • 論文・学会発表 • 社内向け • 社外向け よりよいサービスのご提供を目指して 15 • 組込み開発 • アルゴリズム開発 • AI・深層学習 • 組合せ最適化 各種高速化サービス 技術力強化
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 性能モデルの理論と検証
Fixstars Group www.fixstars.com Copyright © Fixstars Group 今回の話題 • CPU/GPU
高速化にあたって重要な「性能モデル」について紹介 • 場当たり的な高速化ではなく 理論的な分析を通した高速化のための枠組み • 「性能モデル」を用いると... • プログラムの性能の上限を見積ることができる • 高速化余地がどれくらいあるかわかる • 高速なシステムの設計に役立つ • 性能ボトルネックが何かあらかじめわかる 17
Fixstars Group www.fixstars.com Copyright © Fixstars Group 目次 • 性能モデルが必要となる背景
• 性能モデルとは • ルーフラインモデル • ベンチマークによるルーフラインモデルの検証 18
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 性能モデルが必要となる背景
Fixstars Group www.fixstars.com Copyright © Fixstars Group 典型的な高速化の流れ 1. 性能分析
• プロファイラを用いて以下を調査する • どの関数で時間がかかっているか • 関数のどの部分で時間がかかっているか • なぜ時間がかかっているか 2. 各種高速化テクニックを適用 • アルゴリズム変更 • 命令レベルの改善 (命令数削減, 近似命令の活用, SIMD化, etc.) • メモリアクセスの改善 (キャッシュの活用, アクセスパターン改善, etc.) • etc. 3. 以上を繰り返す 20
Fixstars Group www.fixstars.com Copyright © Fixstars Group 典型的な高速化の問題点 • 反復的な作業であるため、ゴールが見えない
• 作業を始めるにあたって以下を明らかにしたい • 目標 • 高速化余地がどの程度あるか • 作業内容 • どういった高速化手法を適用すべきか、どの程度有効か • 工数 • 高速化作業にどの程度時間がかかるか • これらの疑問に答えるために性能モデルを活用できる 特に受託開発では これらをうまく説明できることが 顧客満足につながる 21
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 性能モデルとは
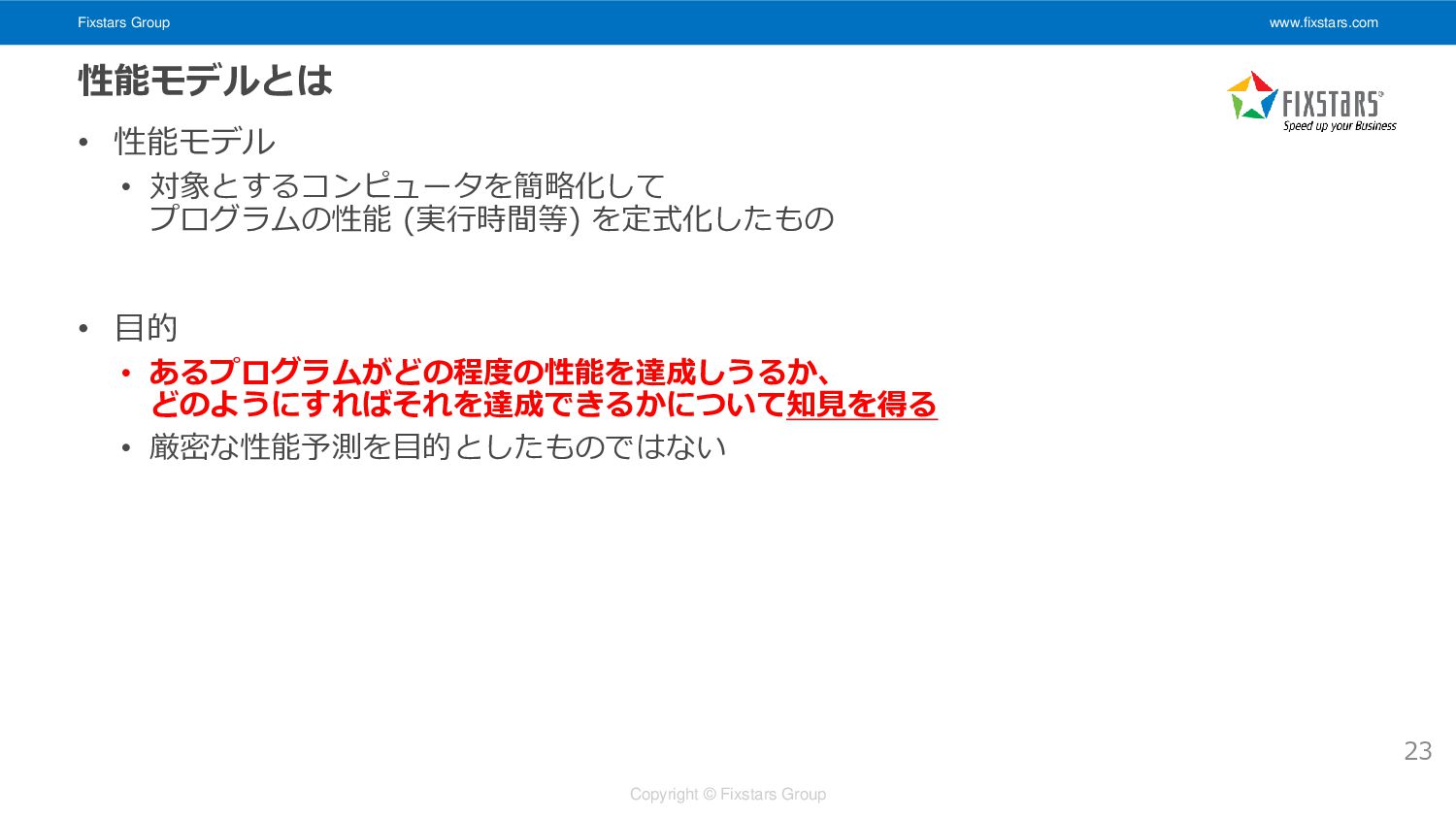
Fixstars Group www.fixstars.com Copyright © Fixstars Group 性能モデルとは • 性能モデル
• 対象とするコンピュータを簡略化して プログラムの性能 (実行時間等) を定式化したもの • 目的 • あるプログラムがどの程度の性能を達成しうるか、 どのようにすればそれを達成できるかについて知見を得る • 厳密な性能予測を目的としたものではない 23
Fixstars Group www.fixstars.com Copyright © Fixstars Group 性能モデルの原始的な例 (1/3) •
シンプルな性能モデル • 命令の種類ごとに実行回数を数えて重み付け • 命令数 • 浮動小数点演算: 2N • メモリアクセス数: 3N • 実行時間: T = F * 2N + M * 3N • F: 浮動小数点演算1命令あたり実行時間 • M: メモリアクセス1命令あたり実行時間 void SAXPY(int N, float a, const float *x, float *y) { for (int i = 0; i < N; ++i) y[i] = a * x[i] + y[i]; } F, M は理論演算性能, メモリ帯域から計算 24
Fixstars Group www.fixstars.com Copyright © Fixstars Group 性能モデルの原始的な例 (2/3) •
N = 109 として計算してみる • プロセッサ: Core i7-4790 • クロック周波数: 3.6GHz • メモリ帯域: 25.6GB/s • 1コア1スレッドのみ使用 • 浮動小数点命令1回あたり実行時間 • F = 1 / (3.6*1e9) [sec] • メモリアクセス命令1回あたり実行時間 • M = 1 / (25.6*1e9 / 4) [sec] • プログラムの実行時間 • T = 2FN + 3MN = 1.02 [sec] • 実測した結果: 0.81 sec 25
Fixstars Group www.fixstars.com Copyright © Fixstars Group 性能モデルの原始的な例 (3/3) •
当然ながら、性能モデルによる予測と実測が合わない • 実行モデルと現実のプロセッサが乖離しているため • 性能モデルにより完璧に性能を予測できるわけではない • コンピュータのもつ多数の性質をモデル化するのは困難 • 「知見を得る」という目的に応じて考慮する性質を選択する 26
Fixstars Group www.fixstars.com Copyright © Fixstars Group よく知られている性能モデル (のようなもの) •
Computational complexity • アルゴリズムのリソース使用量 (演算量, メモリ使用量等) を解析 • キャッシュミス回数に対する cache complexity などもある • アムダールの法則 • プログラムの並列化効率を「並列化可能な処理の割合」から定式化 • DAG Execution Model • タスク並列プログラムにおける並列化効率の定式化 • ルーフラインモデル • プロセッサの演算性能・メモリ帯域および プログラムの演算数・メモリアクセス量を用いて 得られる演算性能を定式化 27
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group ルーフラインモデル
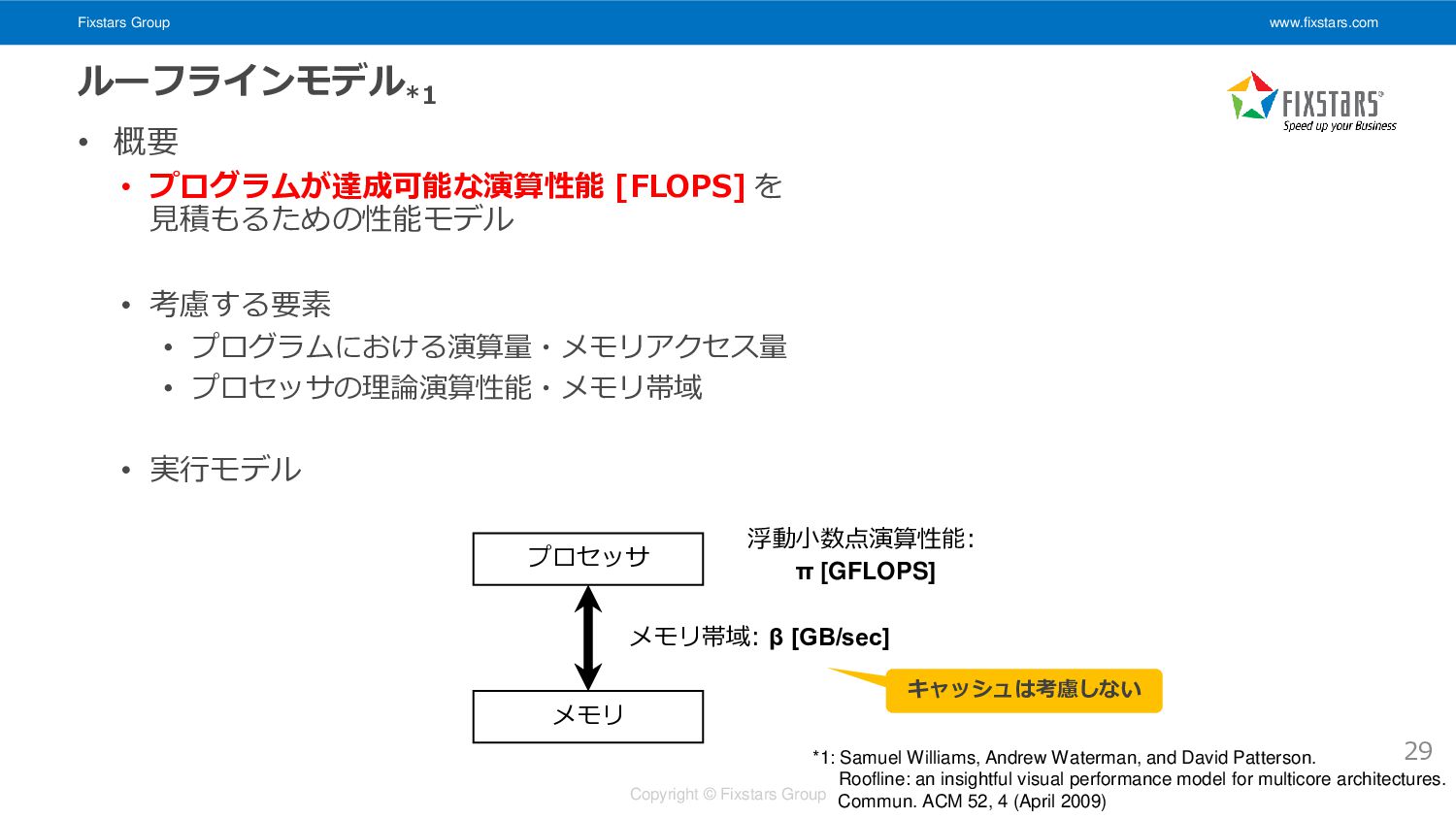
Fixstars Group www.fixstars.com Copyright © Fixstars Group ルーフラインモデル *1 •
概要 • プログラムが達成可能な演算性能 [FLOPS] を 見積もるための性能モデル • 考慮する要素 • プログラムにおける演算量・メモリアクセス量 • プロセッサの理論演算性能・メモリ帯域 • 実行モデル 29 プロセッサ メモリ 浮動小数点演算性能: π [GFLOPS] メモリ帯域: β [GB/sec] *1: Samuel Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009) キャッシュは考慮しない
Fixstars Group www.fixstars.com Copyright © Fixstars Group 補足1: プロセッサの演算性能とは •
1秒間に実行可能な浮動小数点演算数 *1 • 単位: FLOPS (FLoating point number Operations per Seconds) • 例: Intel Core i7-4790 • クロック周波数: 3.6 GHz *2 (= clock/sec) • 1クロックあたり実行可能な浮動小数点演算数 (単精度の場合) • CPUコア数: 4 • CPUコアあたりSIMD演算器数: 2 • SIMDレーン数: 8 (AVX) • SIMDレーンあたり演算数: 2 (Fused Multiply-Add 命令) • 3.6 * 4 * 2 * 8 * 2 = 460.8 [GFLOPS] 30 *1: 整数演算が重要な場合は整数演算数で考える *2: 動的周波数制御 (Intel Turbo Boost 等) も 考慮する必要がある
Fixstars Group www.fixstars.com Copyright © Fixstars Group 補足2: メモリ帯域とは •
1秒間に読み書き可能なメモリアクセス量 • 単位: Byte/sec • 例: Intel Core i7-4790 • メモリ規格: DDR3-1600 (12.8 GB/s) • 最大メモリチャネル数: 2 • 積をとると 25.6 GB/s • あくまでスペック値なので実測した方がよい 31
Fixstars Group www.fixstars.com Copyright © Fixstars Group 演算強度と達成可能な性能 • 演算強度
(Operational Intensity, Arithmetic Intensity) • アプリにおける演算量とメモリアクセス量の比 • 達成可能な性能 (Attainable Performance) • 理論的に達成可能な性能の上限 演算強度 𝐼 [Flop/Byte] = 演算量 𝑊 [Flop] メモリアクセス量 𝑄 [Byte] 達成可能な性能 𝑃 [FLOPS] = min ൝ 理論演算性能 𝜋 [FLOPS] メモリ帯域 𝛽[Byte/sec] × 演算強度 𝐼 [Flop/Byte] プロセッサに対して 独立な指標 32 アプリの演算量・メモリアクセス量, プロセッサの演算性能・メモリ帯域から計算
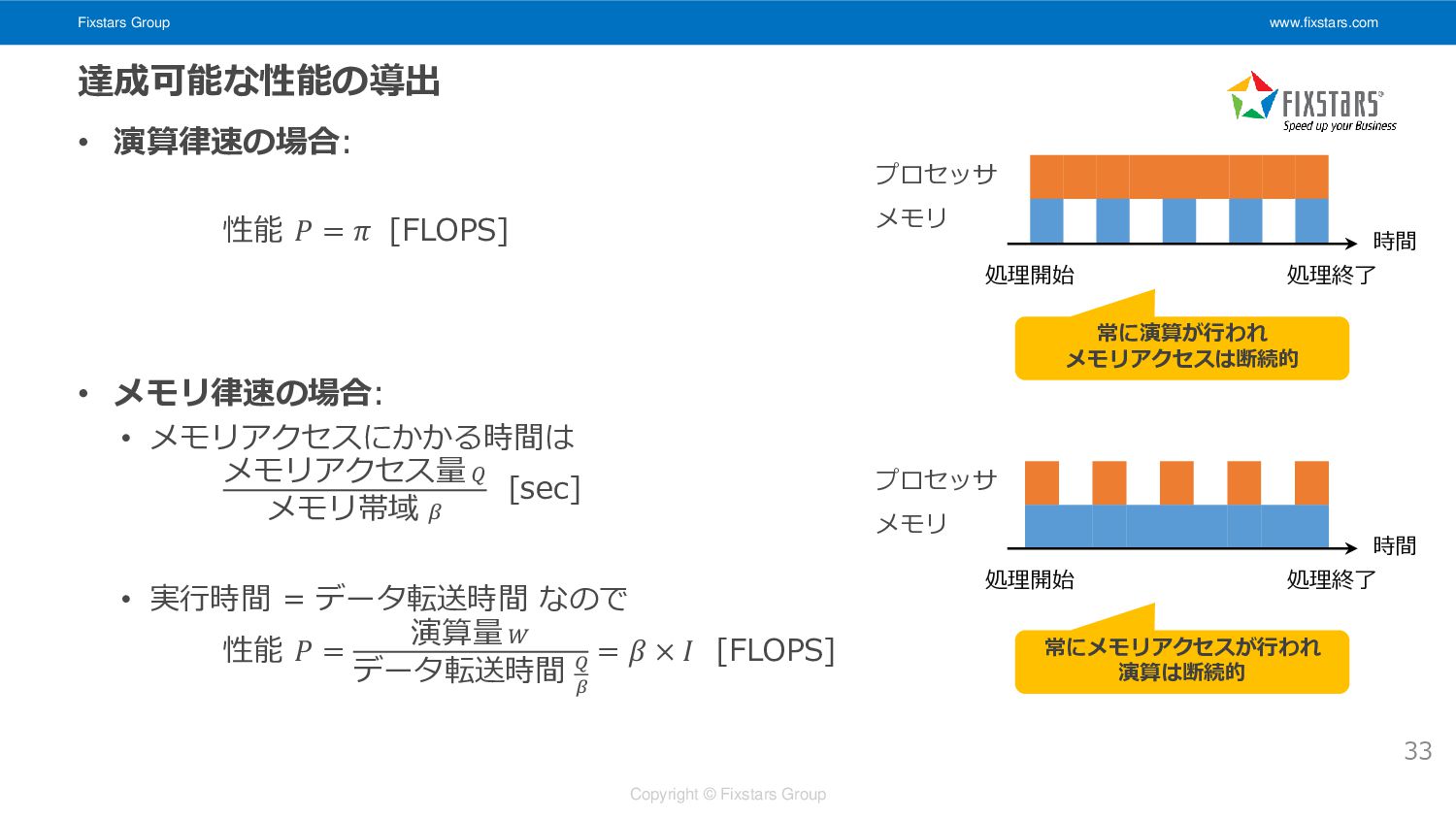
Fixstars Group www.fixstars.com Copyright © Fixstars Group 達成可能な性能の導出 • 演算律速の場合:
性能 𝑃 = 𝜋 [FLOPS] • メモリ律速の場合: • メモリアクセスにかかる時間は メモリアクセス量 𝑄 メモリ帯域 𝛽 [sec] • 実行時間 = データ転送時間 なので 性能 𝑃 = 演算量 𝑊 データ転送時間 𝑄 𝛽 = 𝛽 × 𝐼 [FLOPS] 33 プロセッサ メモリ プロセッサ メモリ 常に演算が行われ メモリアクセスは断続的 常にメモリアクセスが行われ 演算は断続的 時間 処理開始 処理終了 時間 処理開始 処理終了
Fixstars Group www.fixstars.com Copyright © Fixstars Group ルーフラインモデルが成立する前提条件 1. 演算とデータ転送が常に並行して行われる
(or どちらかが支配的である) • 対象プログラムがそのように実装されている必要がある • Out-of-Order プロセッサなら意識しなくてもある程度満たしている 2. メモリ階層が単一である • キャッシュがある場合は以下を考慮して拡張する必要がある • メモリ – キャッシュ間データ転送帯域 • キャッシュ – レジスタ間データ転送帯域 • 演算性能 34
Fixstars Group www.fixstars.com Copyright © Fixstars Group 例: ナイーブな行列積の性能見積り (1/2)
• 問題: 以下の行列積コードの得られる性能の上限は? • プロセッサの性能 • 浮動小数点演算性能: 4000 GFLOPS • メモリ帯域: 200 GB/sec • M = N = K = 1000, キャッシュは考慮しないものとする 36 float A[M * K], B[K * N], C[M * N]; for (int i = 0; i < M; ++i) { for (int j = 0; j < N; ++j) { float value = 0.0f; for (int k = 0; k < K; ++k) value += A[i * K + k] * B[k * N + j]; C[i * N + j] = value; } }
Fixstars Group www.fixstars.com Copyright © Fixstars Group 例: ナイーブな行列積の性能見積り (2/2)
• 答え • 演算量 W = 2MNK = 2*10^9 [flop] • メモリアクセス量 Q = 8MNK + 4MN = 8*10^9 + 4*10^6 [byte] • 演算強度 I = W / Q ≈ 0.25 [flop/byte] • 達成可能な性能 P ≈ min(4000, 200 * 0.25) = 50 [GFLOPS] 37 どれだけ命令レベル高速化を頑張っても 理論演算性能比 1.25% の性能しか得られない *2 → データ局所性を活用して演算強度を上げる必要がある (実践編へ) 知見: ナイーブな行列積はメモリ律速 *1 *1 プロセッサの演算性能を 4000 GFLOPS, メモリ帯域を 200 GB/s とした場合 *2 実際にはキャッシュ等の影響でこれ以上の性能となりうる
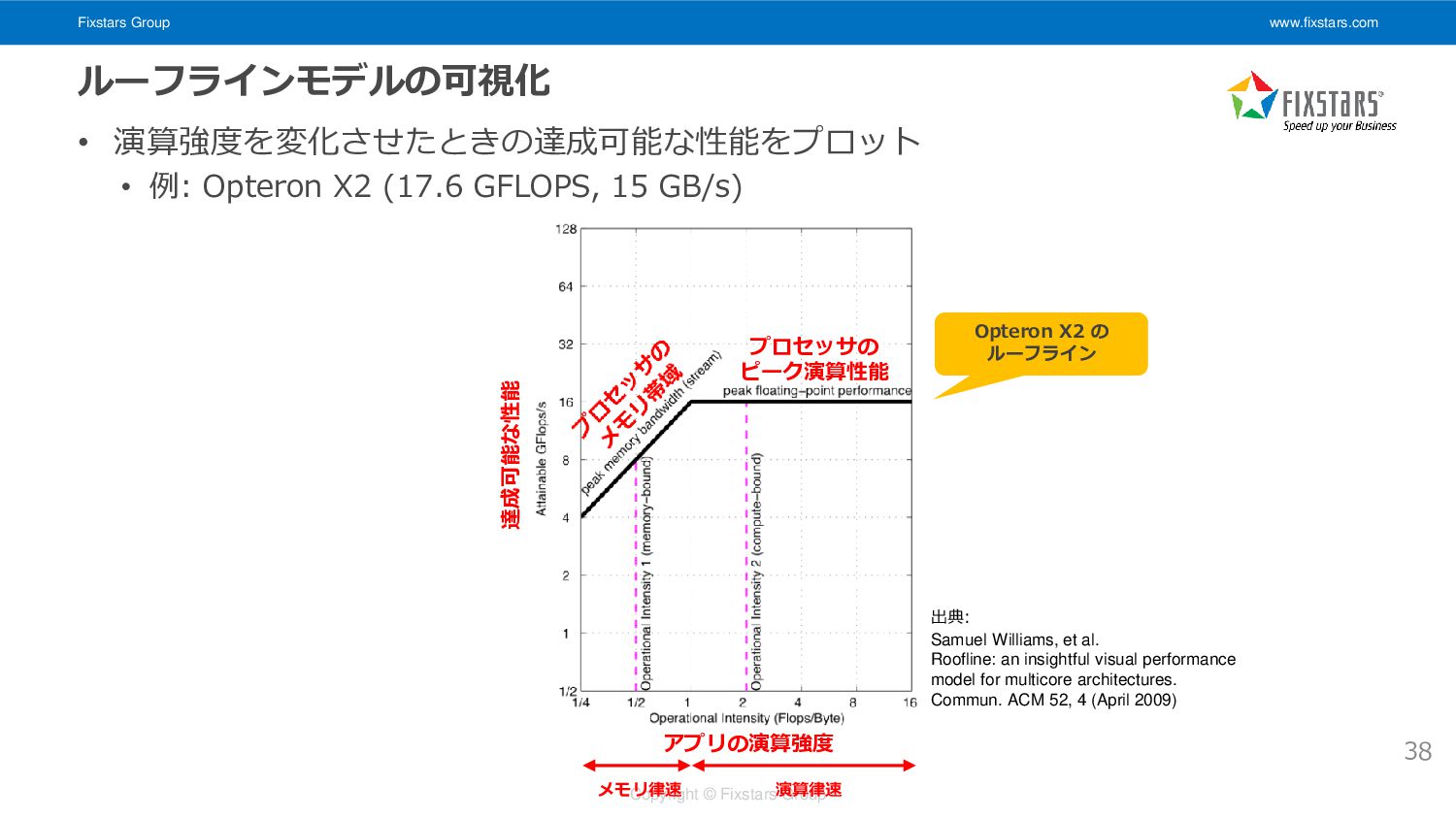
Fixstars Group www.fixstars.com Copyright © Fixstars Group ルーフラインモデルの可視化 • 演算強度を変化させたときの達成可能な性能をプロット
• 例: Opteron X2 (17.6 GFLOPS, 15 GB/s) 38 アプリの演算強度 達成可能な性能 Opteron X2 の ルーフライン プロセッサの ピーク演算性能 メモリ律速 演算律速 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009)
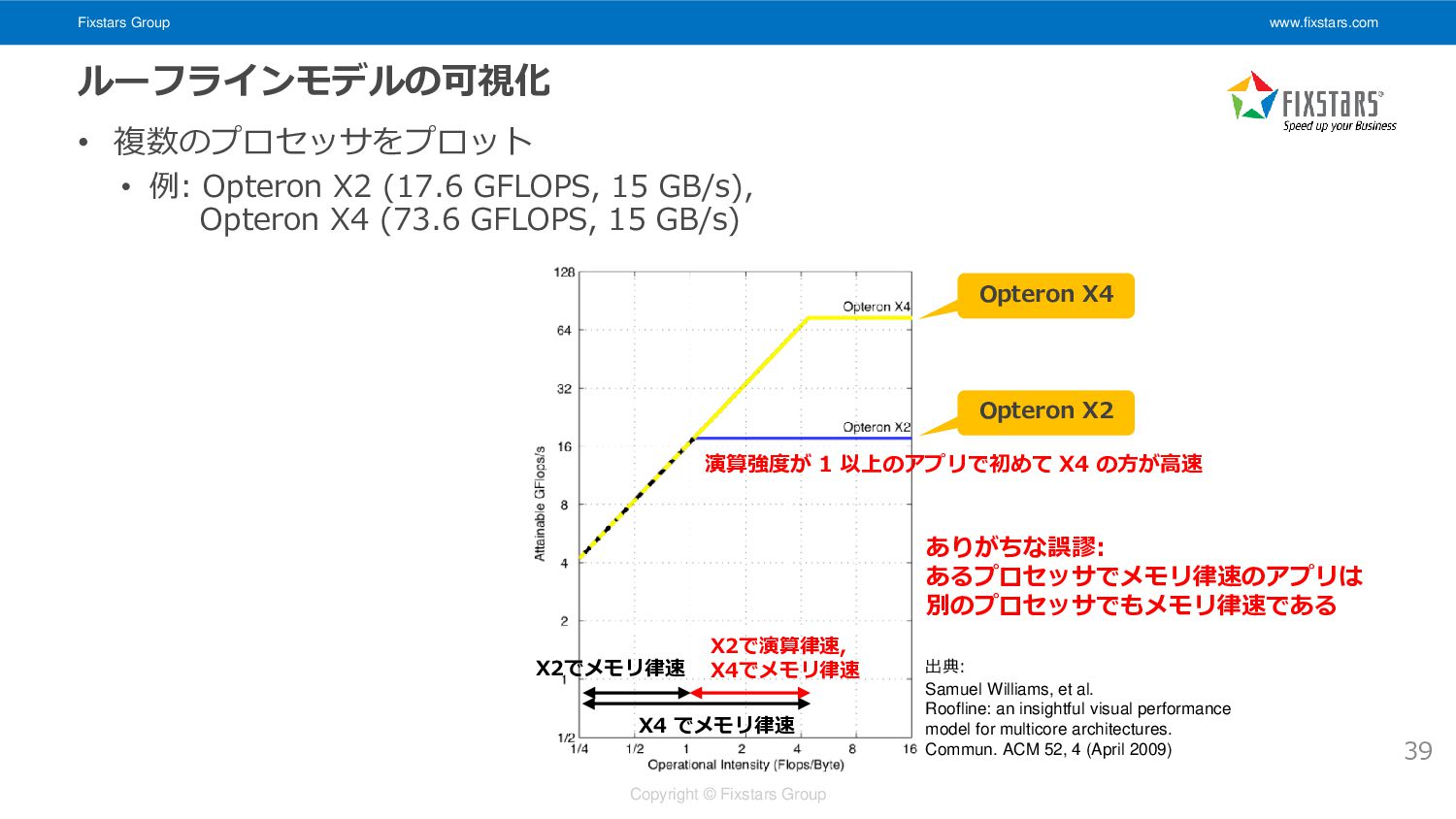
Fixstars Group www.fixstars.com Copyright © Fixstars Group ルーフラインモデルの可視化 • 複数のプロセッサをプロット
• 例: Opteron X2 (17.6 GFLOPS, 15 GB/s), Opteron X4 (73.6 GFLOPS, 15 GB/s) 39 ありがちな誤謬: あるプロセッサでメモリ律速のアプリは 別のプロセッサでもメモリ律速である X2でメモリ律速 X4 でメモリ律速 演算強度が 1 以上のアプリで初めて X4 の方が高速 X2で演算律速, X4でメモリ律速 Opteron X4 Opteron X2 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009)
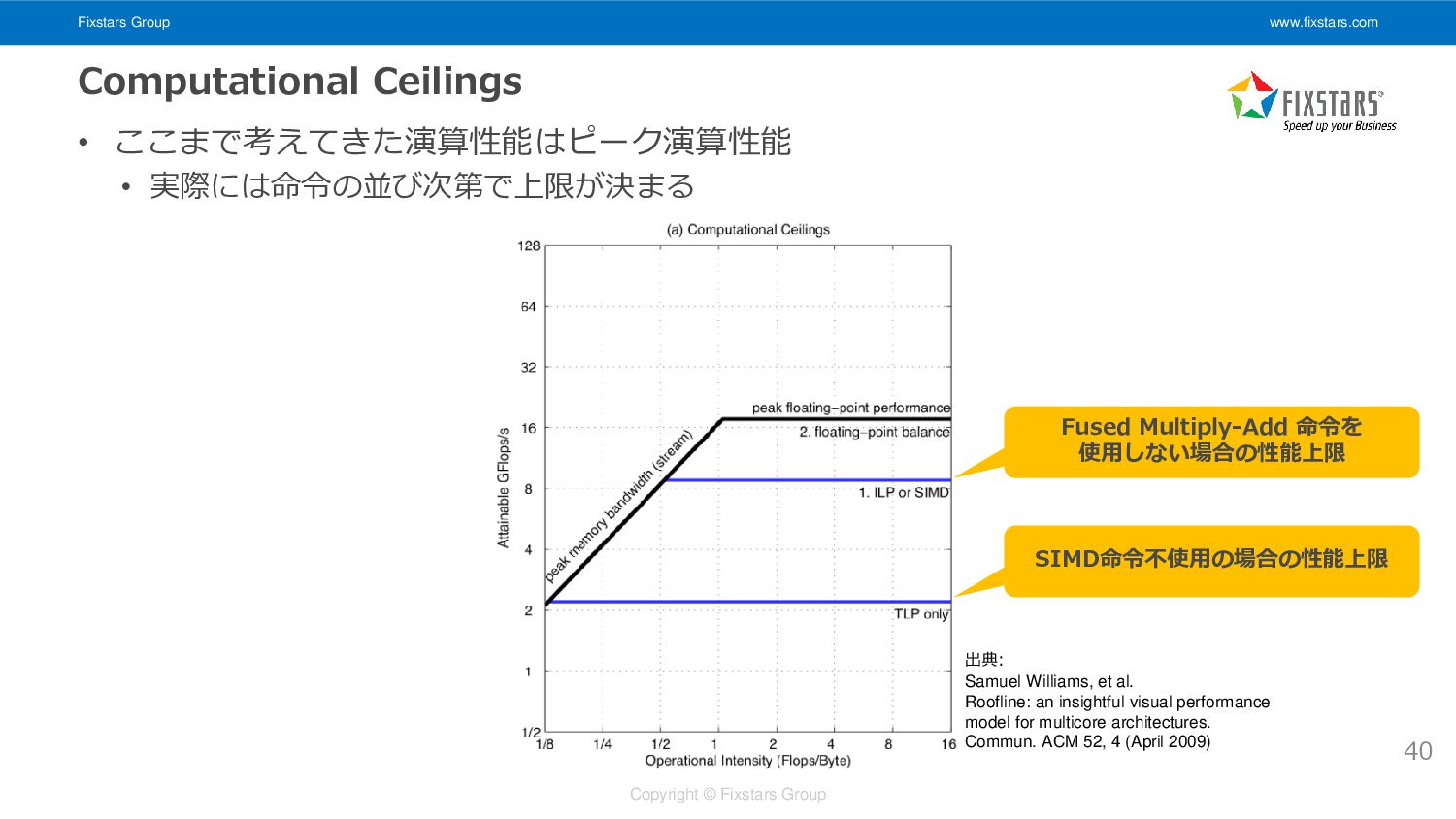
Fixstars Group www.fixstars.com Copyright © Fixstars Group Computational Ceilings •
ここまで考えてきた演算性能はピーク演算性能 • 実際には命令の並び次第で上限が決まる 40 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009) Fused Multiply-Add 命令を 使用しない場合の性能上限 SIMD命令不使用の場合の性能上限
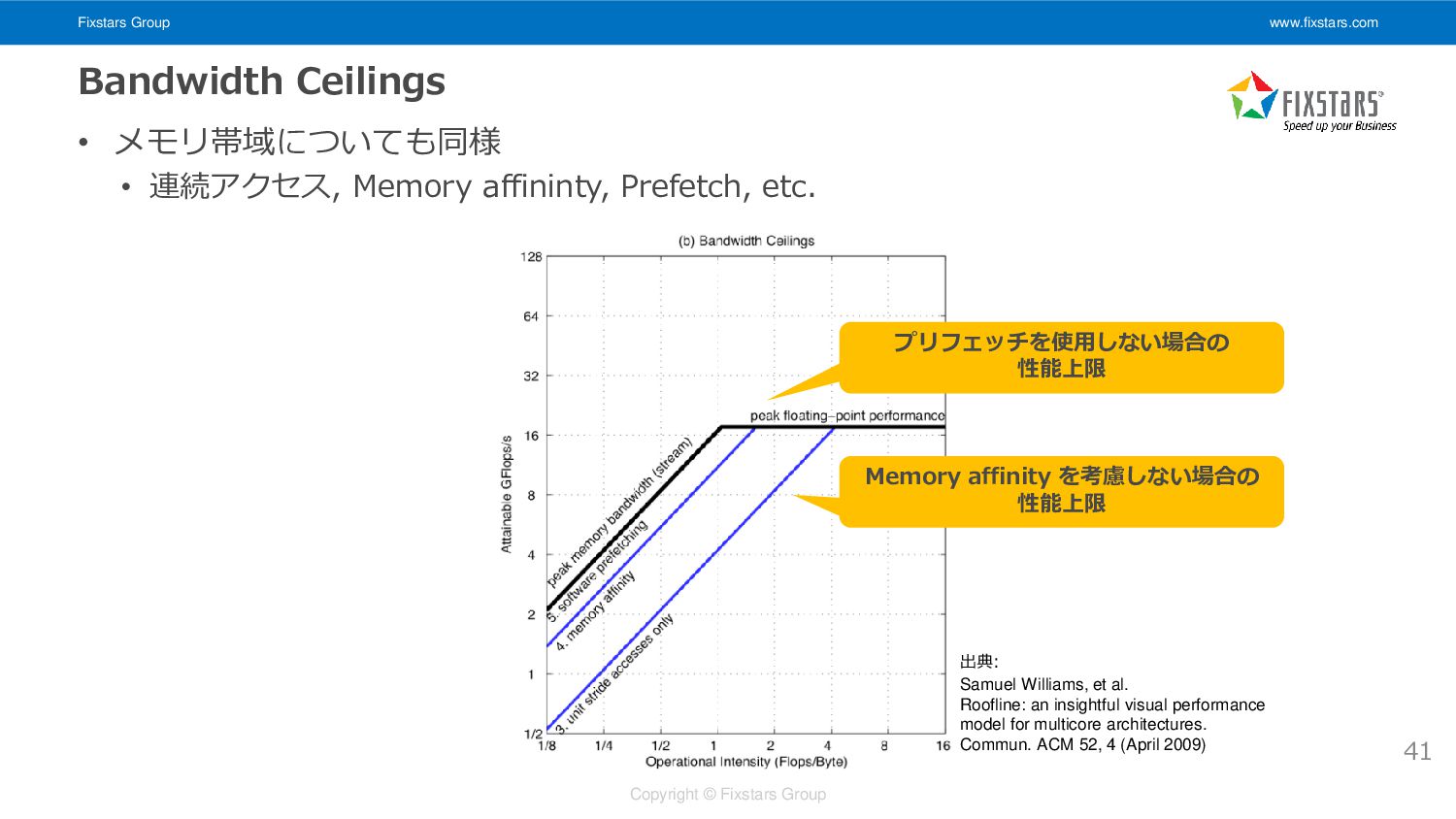
Fixstars Group www.fixstars.com Copyright © Fixstars Group Bandwidth Ceilings •
メモリ帯域についても同様 • 連続アクセス, Memory affininty, Prefetch, etc. 41 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009) プリフェッチを使用しない場合の 性能上限 Memory affinity を考慮しない場合の 性能上限
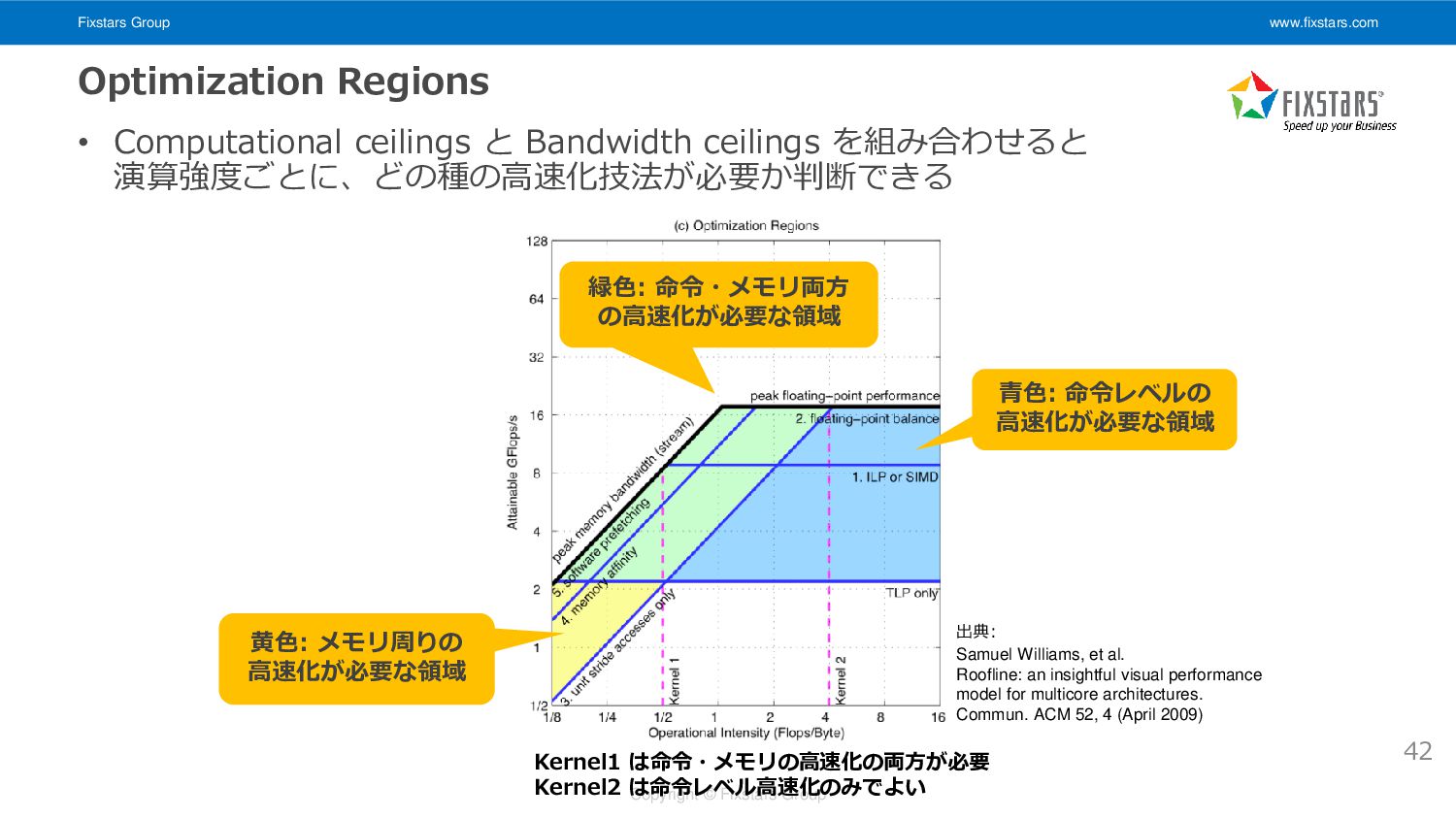
Fixstars Group www.fixstars.com Copyright © Fixstars Group Optimization Regions •
Computational ceilings と Bandwidth ceilings を組み合わせると 演算強度ごとに、どの種の高速化技法が必要か判断できる 黄色: メモリ周りの 高速化が必要な領域 緑色: 命令・メモリ両方 の高速化が必要な領域 青色: 命令レベルの 高速化が必要な領域 Kernel1 は命令・メモリの高速化の両方が必要 Kernel2 は命令レベル高速化のみでよい 42 出典: Samuel Williams, et al. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM 52, 4 (April 2009)
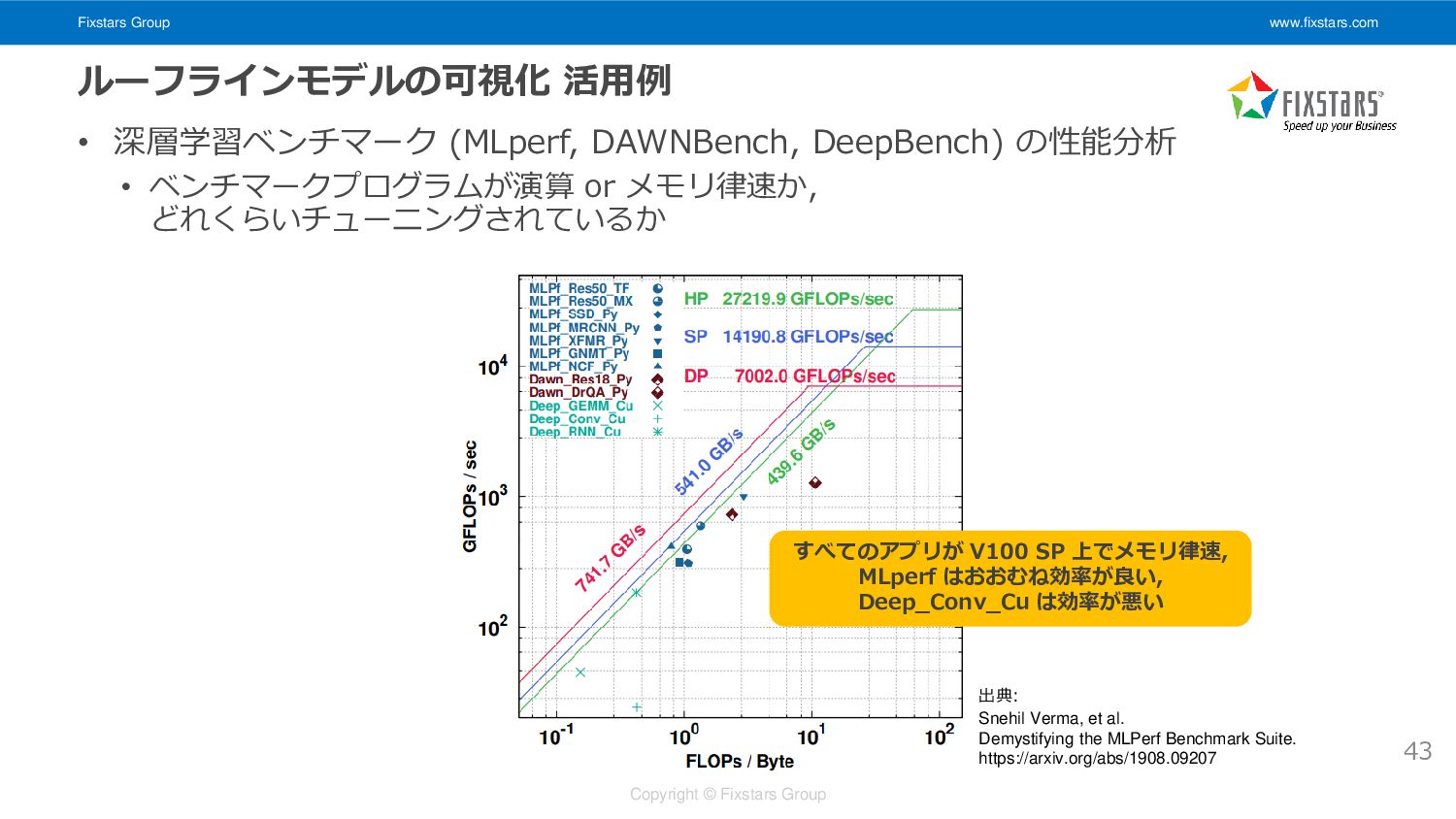
Fixstars Group www.fixstars.com Copyright © Fixstars Group ルーフラインモデルの可視化 活用例 •
深層学習ベンチマーク (MLperf, DAWNBench, DeepBench) の性能分析 • ベンチマークプログラムが演算 or メモリ律速か, どれくらいチューニングされているか 43 出典: Snehil Verma, et al. Demystifying the MLPerf Benchmark Suite. https://arxiv.org/abs/1908.09207 すべてのアプリが V100 SP 上でメモリ律速, MLperf はおおむね効率が良い, Deep_Conv_Cu は効率が悪い
Fixstars Group www.fixstars.com Copyright © Fixstars Group ピーク性能を達成するためには • 命令レベルの高速化
• SIMD, FMA 命令の活用 • 命令レベル並列性 (ILP) の改善 • パイプラインハザードを減らす (命令レイテンシ隠蔽, 分岐予測改善, etc.) • スーパースカラ (複数の実行ユニット) を活用する • スレッドレベル並列性 (TLP) の改善 • 演算器を使い切れるだけの並列性を供給する • 浮動小数点命令の割合を増やす (FP命令とそれ以外の命令が同じ演算器で実行される場合) • メモリアクセスの高速化 • 適切な粒度, 量, alignment でメモリアクセス • メモリアクセスレイテンシの隠蔽 (w/ ILP, TLP, Prefetch) • プロセッサ・メモリトポロジの考慮 • 演算強度の向上 • レジスタ, キャッシュ等のメモリ階層を活用 • その他 (ルーフラインモデルの範疇外) • 負荷分散の改善, 同期の削減, etc. 44
Fixstars Group www.fixstars.com Copyright © Fixstars Group なぜルーフラインモデルが重要か • プログラムの性能を
(ある程度) 見積もることができる • 高速化余地がどれくらいあるか • どのリソースがボトルネックか • 別のプロセッサに移植した場合にどの程度の性能となるか (→ 機種選定に役立つ) • 高速なソフトウェアの設計に役立つ • アルゴリズム選定, cache-aware algorithms で必要なキャッシュサイズ • 数ある高速化手法のうち、不要なものを事前に枝刈りできる • 試行錯誤を減らせるかも 45
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group ベンチマークによる ルーフラインモデルの検証
Fixstars Group www.fixstars.com Copyright © Fixstars Group ルーフラインモデルの検証 • ルーフラインモデルがどの程度正確か
ベンチマークプログラムを用いて検証する • 演算性能の計測 • メモリ帯域の計測 • 演算・メモリ複合実行性能の計測 • 実験環境 • x86-64 CPU • Intel Core i7-3770 3.40GHz (IvyBridge), Ubuntu 18.04 • Intel Core i7-4790 3.60GHz (Haswell), WSL1 • Intel Core i7-6500U 2.50GHz (Skylake), WSL1 • AMD Ryzen 7 3700X 3.60GHz (Zen 2), Ubuntu 18.04 47
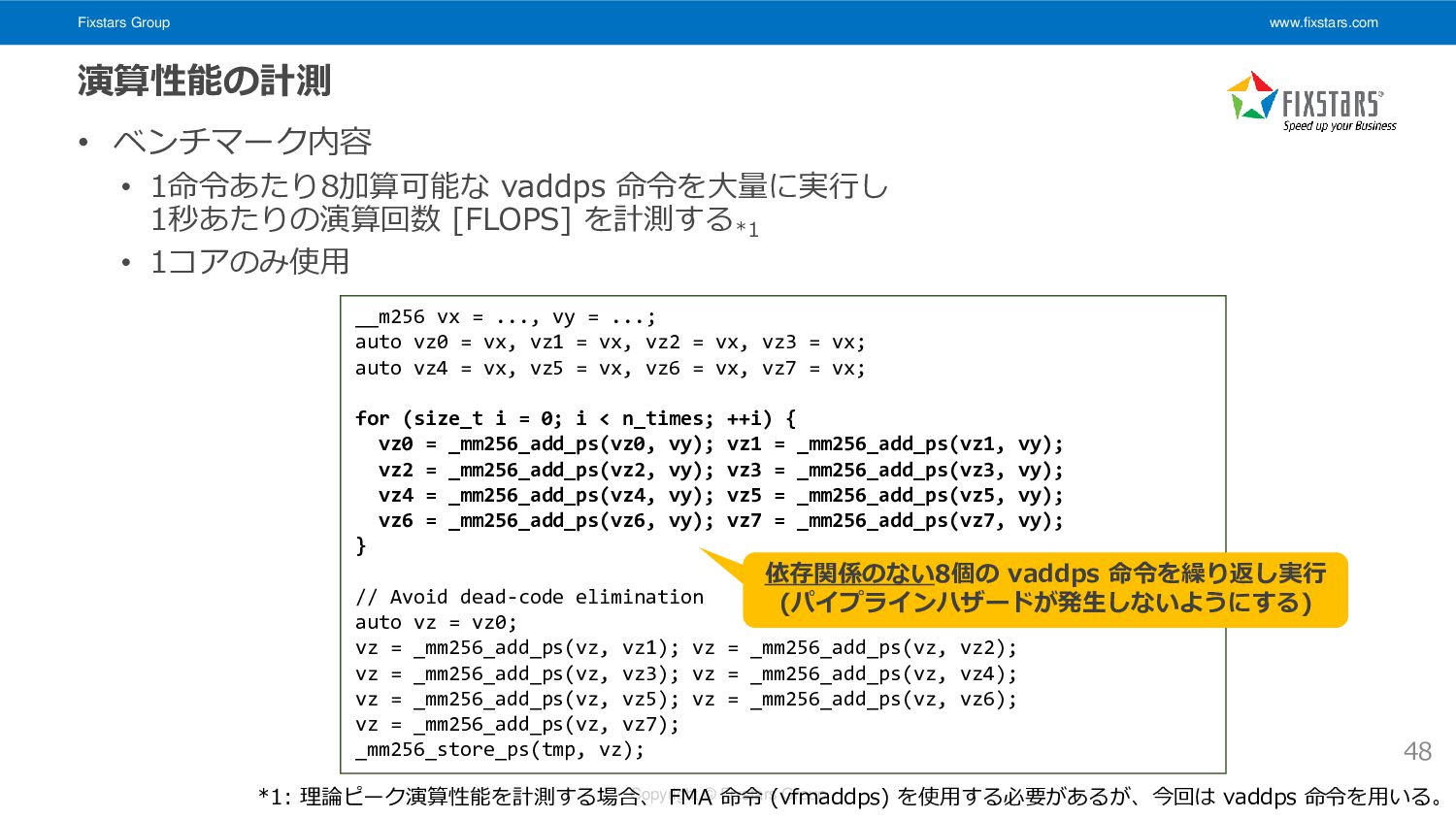
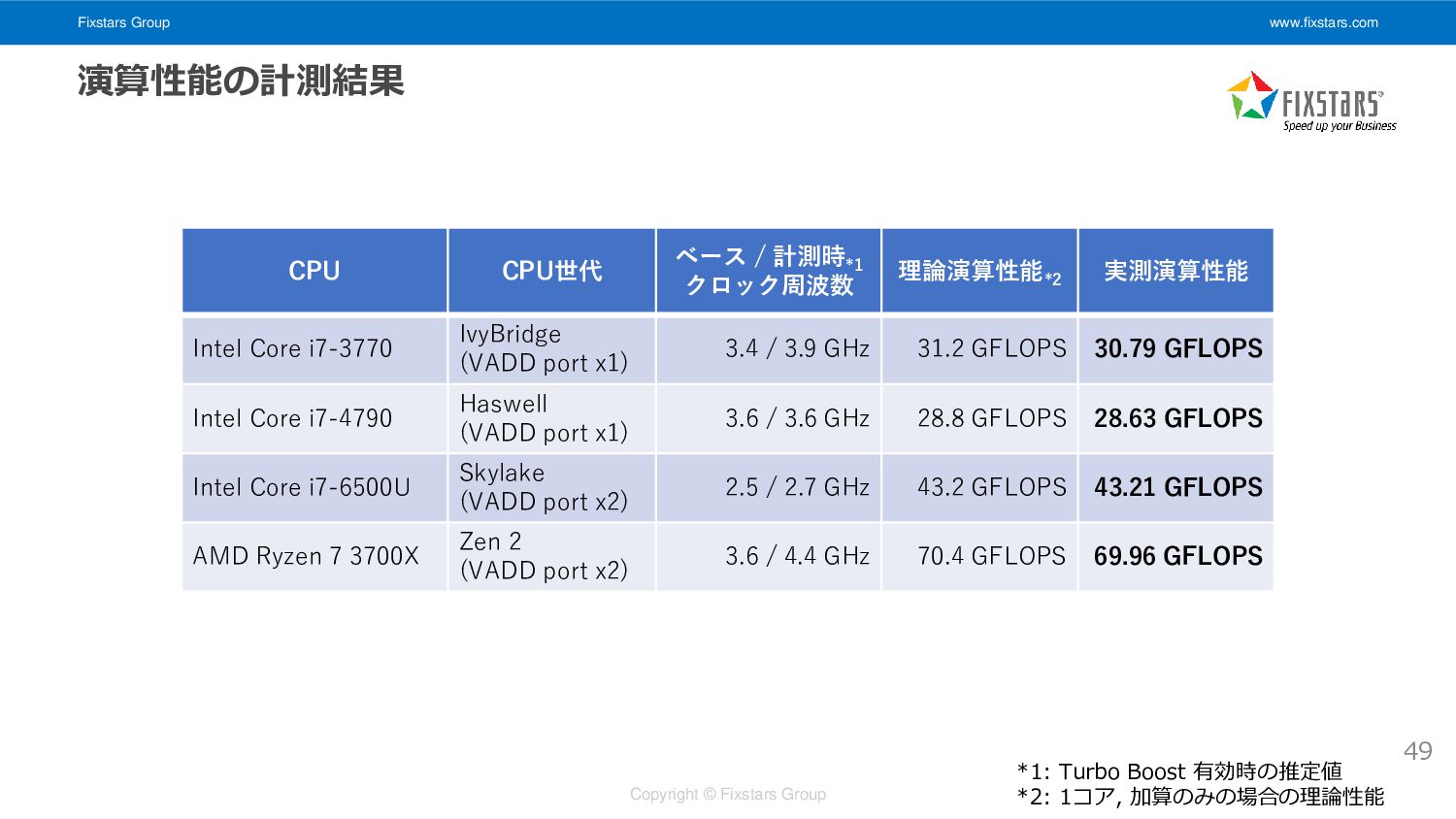
Fixstars Group www.fixstars.com Copyright © Fixstars Group 演算性能の計測 • ベンチマーク内容
• 1命令あたり8加算可能な vaddps 命令を大量に実行し 1秒あたりの演算回数 [FLOPS] を計測する *1 • 1コアのみ使用 48 __m256 vx = ..., vy = ...; auto vz0 = vx, vz1 = vx, vz2 = vx, vz3 = vx; auto vz4 = vx, vz5 = vx, vz6 = vx, vz7 = vx; for (size_t i = 0; i < n_times; ++i) { vz0 = _mm256_add_ps(vz0, vy); vz1 = _mm256_add_ps(vz1, vy); vz2 = _mm256_add_ps(vz2, vy); vz3 = _mm256_add_ps(vz3, vy); vz4 = _mm256_add_ps(vz4, vy); vz5 = _mm256_add_ps(vz5, vy); vz6 = _mm256_add_ps(vz6, vy); vz7 = _mm256_add_ps(vz7, vy); } // Avoid dead-code elimination auto vz = vz0; vz = _mm256_add_ps(vz, vz1); vz = _mm256_add_ps(vz, vz2); vz = _mm256_add_ps(vz, vz3); vz = _mm256_add_ps(vz, vz4); vz = _mm256_add_ps(vz, vz5); vz = _mm256_add_ps(vz, vz6); vz = _mm256_add_ps(vz, vz7); _mm256_store_ps(tmp, vz); 依存関係のない8個の vaddps 命令を繰り返し実行 (パイプラインハザードが発生しないようにする) *1: 理論ピーク演算性能を計測する場合、 FMA 命令 (vfmaddps) を使用する必要があるが、今回は vaddps 命令を用いる。
Fixstars Group www.fixstars.com Copyright © Fixstars Group 演算性能の計測結果 CPU CPU世代
ベース / 計測時 *1 クロック周波数 理論演算性能 *2 実測演算性能 Intel Core i7-3770 IvyBridge (VADD port x1) 3.4 / 3.9 GHz 31.2 GFLOPS 30.79 GFLOPS Intel Core i7-4790 Haswell (VADD port x1) 3.6 / 3.6 GHz 28.8 GFLOPS 28.63 GFLOPS Intel Core i7-6500U Skylake (VADD port x2) 2.5 / 2.7 GHz 43.2 GFLOPS 43.21 GFLOPS AMD Ryzen 7 3700X Zen 2 (VADD port x2) 3.6 / 4.4 GHz 70.4 GFLOPS 69.96 GFLOPS *1: Turbo Boost 有効時の推定値 *2: 1コア, 加算のみの場合の理論性能 49
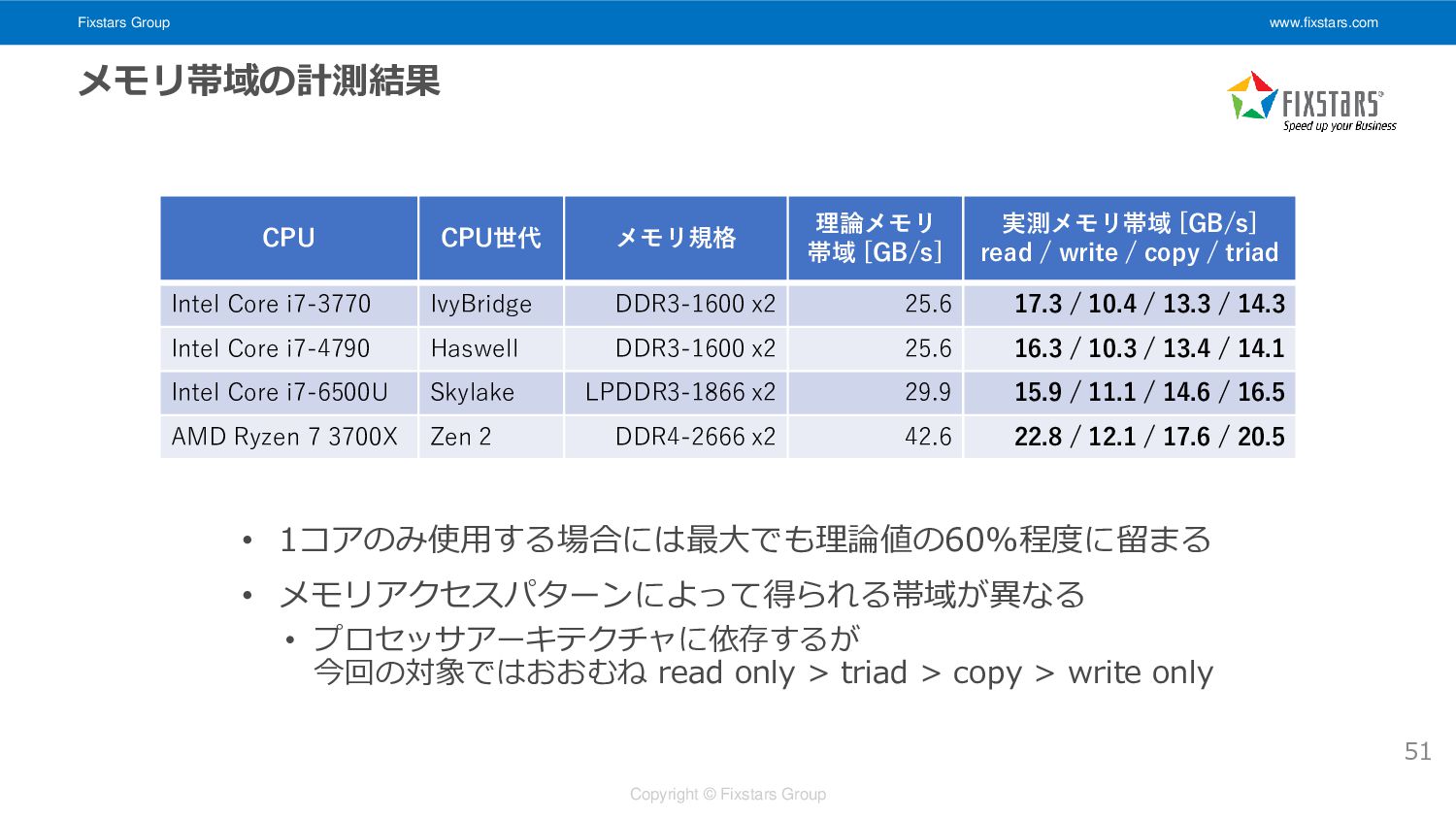
Fixstars Group www.fixstars.com Copyright © Fixstars Group メモリ帯域の計測 • ベンチマーク内容
• キャッシュに収まらないサイズの配列に対して 4つのパターンでメモリアクセスし、スループットを計測する • read only (read:write=1:0), write only (read:write=0:1), copy (read:write=1:1), triad (read:write=2:1) • 1コアのみ使用 float *sp0 = src0, *sp1 = src1, *dp = dst, *dst_end = dst + size; while (dp < dst_end) { // triad: dst[i] = alpha * src0[i] + src1[i]; auto vx0 = _mm256_load_ps(sp0 + 0 * 8), vx1 = _mm256_load_ps(sp0 + 1 * 8); auto vx2 = _mm256_load_ps(sp0 + 2 * 8), vx3 = _mm256_load_ps(sp0 + 3 * 8); auto vy0 = _mm256_load_ps(sp1 + 0 * 8), vy1 = _mm256_load_ps(sp1 + 1 * 8); auto vy2 = _mm256_load_ps(sp1 + 2 * 8), vy3 = _mm256_load_ps(sp1 + 3 * 8); auto vz0 = _mm256_fmadd_ps(valpha, vx0, vy0); auto vz1 = _mm256_fmadd_ps(valpha, vx1, vy1); auto vz2 = _mm256_fmadd_ps(valpha, vx2, vy2); auto vz3 = _mm256_fmadd_ps(valpha, vx3, vy3); _mm256_store_ps(dp + 0 * 8, vz0); _mm256_store_ps(dp + 1 * 8, vz1); _mm256_store_ps(dp + 2 * 8, vz2); _mm256_store_ps(dp + 3 * 8, vz3); sp0 += 4 * 8, sp1 += 4 * 8, dp += 4 * 8; } 50
Fixstars Group www.fixstars.com Copyright © Fixstars Group メモリ帯域の計測結果 • 1コアのみ使用する場合には最大でも理論値の60%程度に留まる
• メモリアクセスパターンによって得られる帯域が異なる • プロセッサアーキテクチャに依存するが 今回の対象ではおおむね read only > triad > copy > write only CPU CPU世代 メモリ規格 理論メモリ 帯域 [GB/s] 実測メモリ帯域 [GB/s] read / write / copy / triad Intel Core i7-3770 IvyBridge DDR3-1600 x2 25.6 17.3 / 10.4 / 13.3 / 14.3 Intel Core i7-4790 Haswell DDR3-1600 x2 25.6 16.3 / 10.3 / 13.4 / 14.1 Intel Core i7-6500U Skylake LPDDR3-1866 x2 29.9 15.9 / 11.1 / 14.6 / 16.5 AMD Ryzen 7 3700X Zen 2 DDR4-2666 x2 42.6 22.8 / 12.1 / 17.6 / 20.5 51
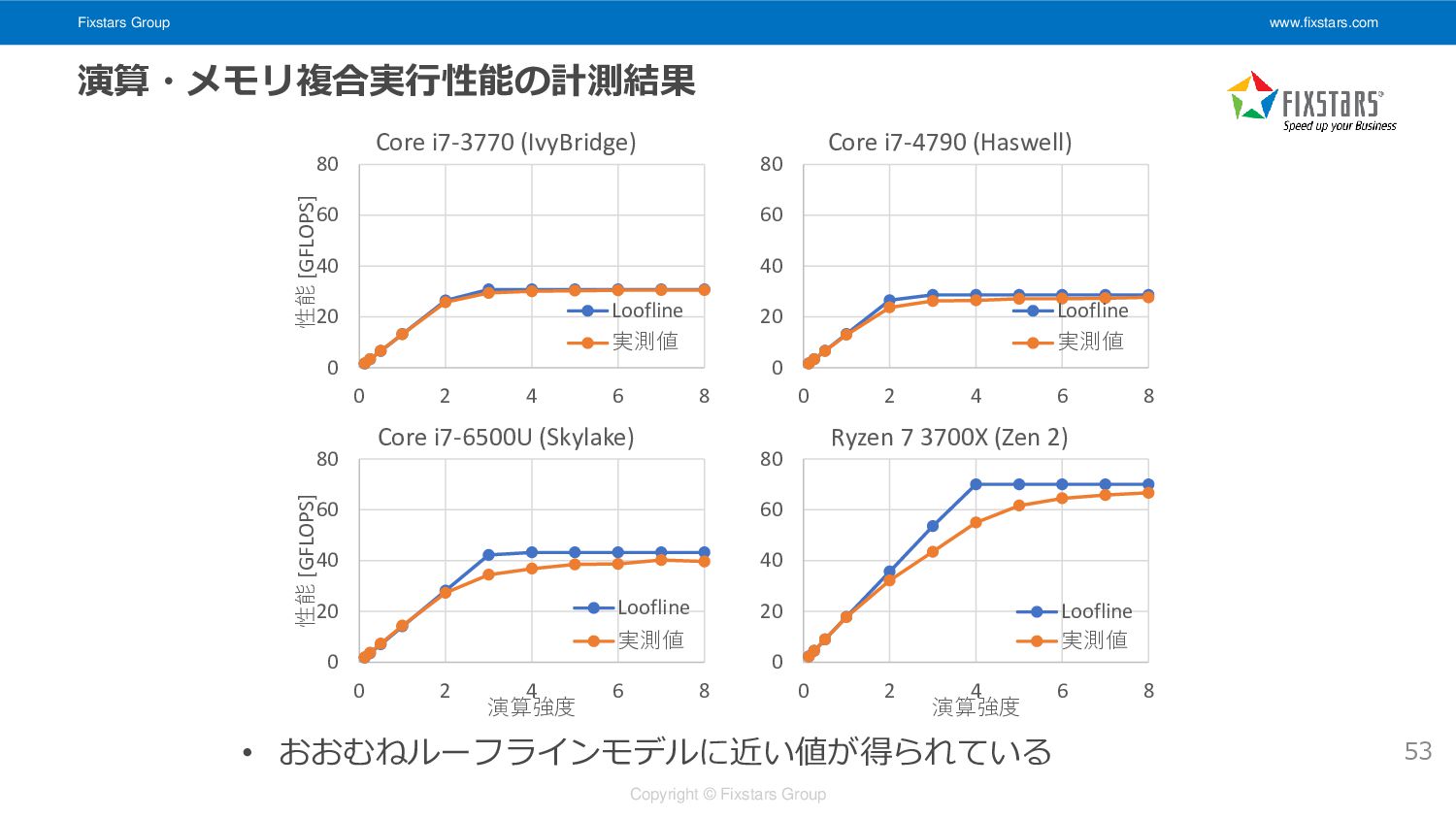
Fixstars Group www.fixstars.com Copyright © Fixstars Group 演算・メモリ複合実行性能の計測 • ベンチマーク内容
• 配列の各要素に対してロード・N回加算・ストアを行う • read:write:add=1:1:N • 演算強度: N / ((1 + 1) * sizeof(float)) = N/8 • 1コアのみ使用 52 const auto va = ...; const auto *sp0 = src0, *dp = dst, *dst_end = dst + size; while (dp < dst_end) { // dst[i] = src0[i] + (a + a + ... + a); auto vz0 = _mm256_load_ps(sp0 + 0 * 8), vz1 = _mm256_load_ps(sp0 + 1 * 8); auto vz2 = _mm256_load_ps(sp0 + 2 * 8), vz3 = _mm256_load_ps(sp0 + 3 * 8); auto vz4 = _mm256_load_ps(sp0 + 4 * 8), vz5 = _mm256_load_ps(sp0 + 5 * 8); auto vz6 = _mm256_load_ps(sp0 + 6 * 8), vz7 = _mm256_load_ps(sp0 + 7 * 8); UNROLL for (int i = 0; i < N; ++i) { // N: 演算強度を変化させるためのパラメータ vz0 = _mm256_add_ps(vz0, va); vz1 = _mm256_add_ps(vz1, va); vz2 = _mm256_add_ps(vz2, va); vz3 = _mm256_add_ps(vz3, va); vz4 = _mm256_add_ps(vz4, va); vz5 = _mm256_add_ps(vz5, va); vz6 = _mm256_add_ps(vz6, va); vz7 = _mm256_add_ps(vz7, va); } _mm256_store_ps(dp + 0 * 8, vz0); _mm256_store_ps(dp + 1 * 8, vz1); _mm256_store_ps(dp + 2 * 8, vz2); _mm256_store_ps(dp + 3 * 8, vz3); _mm256_store_ps(dp + 4 * 8, vz4); _mm256_store_ps(dp + 5 * 8, vz5); _mm256_store_ps(dp + 6 * 8, vz6); _mm256_store_ps(dp + 7 * 8, vz7); sp0 += 8 * 8, dp += 8 * 8; }
Fixstars Group www.fixstars.com Copyright © Fixstars Group 演算・メモリ複合実行性能の計測結果 • おおむねルーフラインモデルに近い値が得られている
0 20 40 60 80 0 2 4 6 8 性能 [GFLOPS] Core i7-3770 (IvyBridge) Loofline 実測値 0 20 40 60 80 0 2 4 6 8 Core i7-4790 (Haswell) Loofline 実測値 0 20 40 60 80 0 2 4 6 8 性能 [GFLOPS] 演算強度 Core i7-6500U (Skylake) Loofline 実測値 0 20 40 60 80 0 2 4 6 8 演算強度 Ryzen 7 3700X (Zen 2) Loofline 実測値 53
Fixstars Group www.fixstars.com Copyright © Fixstars Group まとめ • CPU/GPU
高速化において重要な「ルーフラインモデル」について解説 • プログラムの性能上限を見積もることができる • どのリソースがボトルネックか判定できる • 色んなプロセッサに移植した場合の性能を推定できる • 有効な高速化手法を選ぶのに役立つ • ベンチマークによる検証を実施 • ルーフラインモデルによる理論性能と実性能を比較し、 おおむね理論性能に近い結果が得られることを確認 54
Fixstars Group www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 実践編予告: AMD GPU における 行列積の高速化
Fixstars Group www.fixstars.com Copyright © Fixstars Group 実践編 予告 •
AMD GPU における行列積の高速化 • ルーフラインモデルを活用した高速化の例を解説 • 性能の上限を求める • 最適なレジスタ・キャッシュブロッキングサイズを求める 56
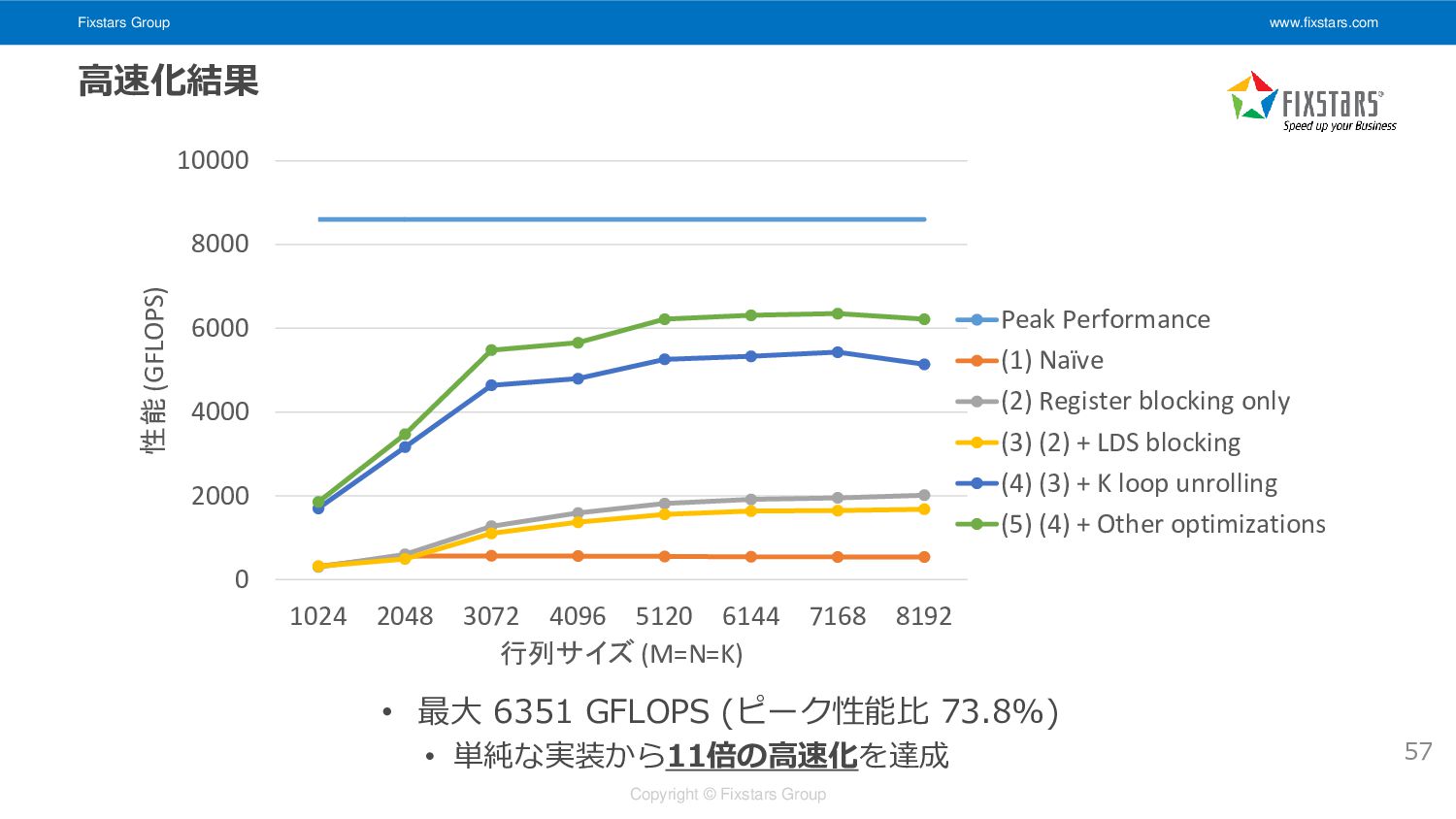
Fixstars Group www.fixstars.com Copyright © Fixstars Group 高速化結果 • 最大
6351 GFLOPS (ピーク性能比 73.8%) • 単純な実装から11倍の高速化を達成 0 2000 4000 6000 8000 10000 1024 2048 3072 4096 5120 6144 7168 8192 性能 (GFLOPS) 行列サイズ (M=N=K) Peak Performance (1) Naïve (2) Register blocking only (3) (2) + LDS blocking (4) (3) + K loop unrolling (5) (4) + Other optimizations 57
Fixstars Group www.fixstars.com Copyright © Fixstars Group Thank You お問い合わせ窓口
:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}