Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWS Summit Japan 2025 Amazon SageMaker HyperPod...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Kazuki Fujii
December 14, 2025
Research
50
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWS Summit Japan 2025 Amazon SageMaker HyperPodを利用した日本語LLM(Swallow)の構築 (CUS-02)
Kazuki Fujii
December 14, 2025
More Decks by Kazuki Fujii
See All by Kazuki Fujii
IHPCSS2025-Kazuki-Fujii
fujiikazuki2000
0
30
2024-02-Tokyo-Tech-大規模言語モデルの事前学習知見
fujiikazuki2000
0
39
情報処理学会-全国大会2024-大規模言語モデルの分散並列学習
fujiikazuki2000
0
37
言語処理学会2024-継続事前学習による日本語に強い大規模言語モデルの構築
fujiikazuki2000
0
55
合成データパイプラインを利用したSwallowProjectに おけるLLM性能向上
fujiikazuki2000
1
300
論文では語られないLLM開発において重要なこと Swallow Projectを通して
fujiikazuki2000
8
2k
大規模言語モデルの学習知見
fujiikazuki2000
0
210
自然言語処理のための分散並列学習
fujiikazuki2000
1
720
Other Decks in Research
See All in Research
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
260
kintone リサーチ副部/UXリサーチャー 業務紹介
cybozuinsideout
PRO
0
100
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
360
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.3k
IA for theory
gpeyre
0
250
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
SLAMはどこまで解決されたのか?
tomonom
0
770
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
NLP colloquium: AI Safety Survey
kanekomasahiro
0
840
Fukui Shibiten 39 - AI Art
butchi
0
140
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
400
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
300
Featured
See All Featured
Building the Perfect Custom Keyboard
takai
2
810
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
640
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
The agentic SEO stack - context over prompts
schlessera
0
840
WCS-LA-2024
lcolladotor
0
680
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
290
Designing Experiences People Love
moore
143
24k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Transcript
自己紹介 藤井 一喜 / Kazuki Fujii 東京科学大学 情報理工学院 修士課程2年 Preferred
Networks PLaMo インターン / Turing株式会社 基盤AIチーム 業務委託 • Swallow Project 事前学習、チューニング、データ高品質化を担当 • 研究興味 ◦ 大規模モデルの分散学習、低精度計算による高速化 ◦ データ品質改善によるLLMの性能改善 1
Swallow Project オープンモデルを利用して日本語に強い 大規模言語モデル (LLM) を研究開発する • 東京科学大学、産総研の共同研究 ◦ 岡崎研究室
(NLP) ◦ 横田研究室 (HPC, ML) • 数多くの日本語LLMをリリース ◦ これまでに12モデルシリーズ を公開 ◦ 産業応用 にも活用される 2
継続事前学習 (Continual Pre-Training) 3 Llama-3, Gemma-2 ... Open LLMs 日本語
+ 英語 + コード Llama-3-Swallow Gemma-2-Swallow • 利点 o Open LLMの力を利用できる o 比較的低コストで学習可能 • 欠点 o アーキテクチャの制約 o 元モデルのLicenseに縛られる 課題 • 破滅的忘却 • 英語スコアの低下
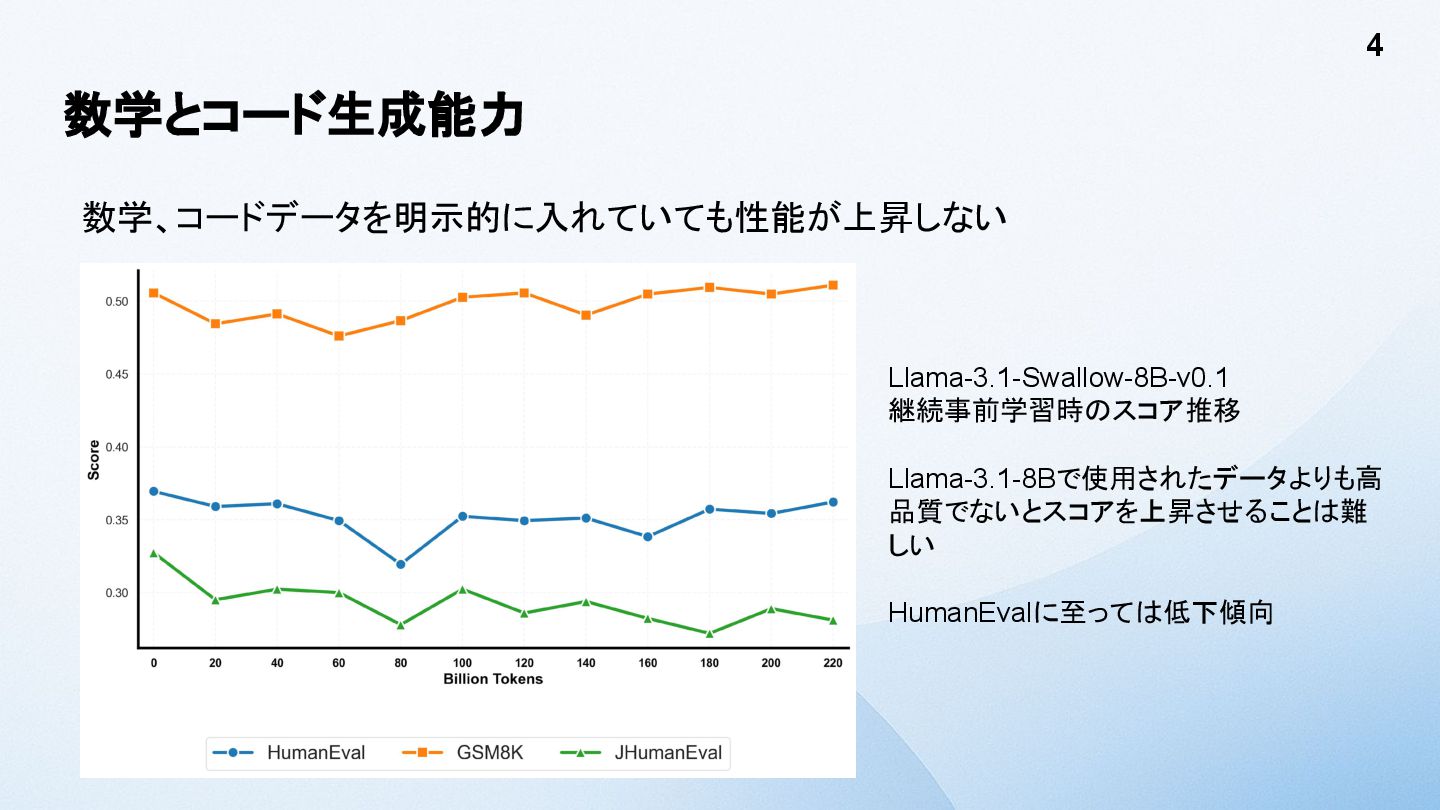
数学とコード生成能力 数学、コードデータを明示的に入れていても性能が上昇しない 4 Llama-3.1-Swallow-8B-v0.1 継続事前学習時のスコア推移 Llama-3.1-8Bで使用されたデータよりも高 品質でないとスコアを上昇させることは難 しい HumanEvalに至っては低下傾向
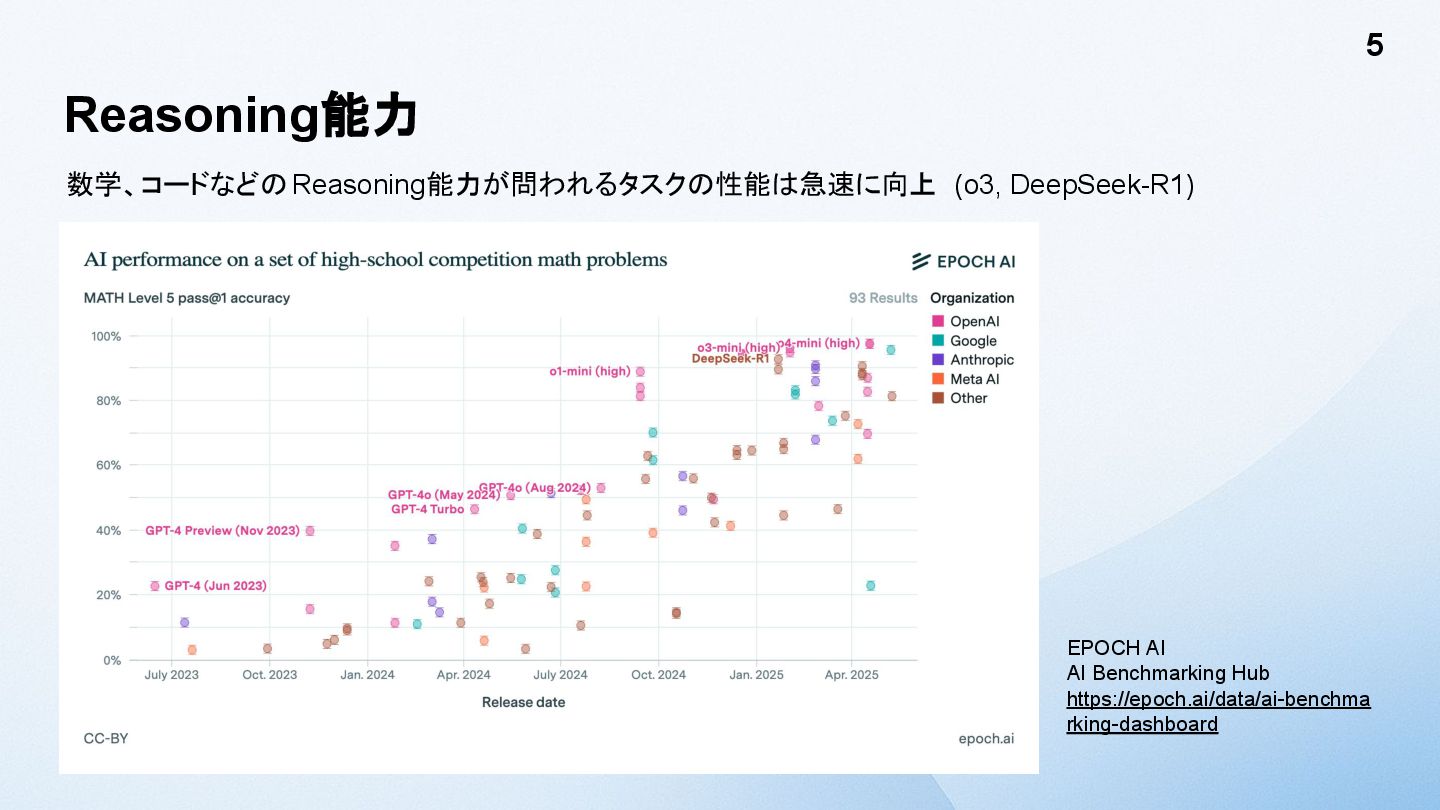
Reasoning能力 数学、コードなどのReasoning能力が問われるタスクの性能は急速に向上 (o3, DeepSeek-R1) 5 EPOCH AI AI Benchmarking Hub
https://epoch.ai/data/ai-benchma rking-dashboard
Swallow Projectの成果 2025/1〜2025/4 の成果 6
リリースモデル ▪ Llama-3.3-Swallow-70B-v0.4 ▪ 2025/3/10 リリース済み ▪ 日本語QA能力強化 ▪ コード強化
v1 ▪ Llama-3.1-Swallow-8B-v0.5 ▪ 2025/6 リリース済み ▪ 日本語QA能力強化 ▪ コード強化 v2 ▪ 数学能力強化 7
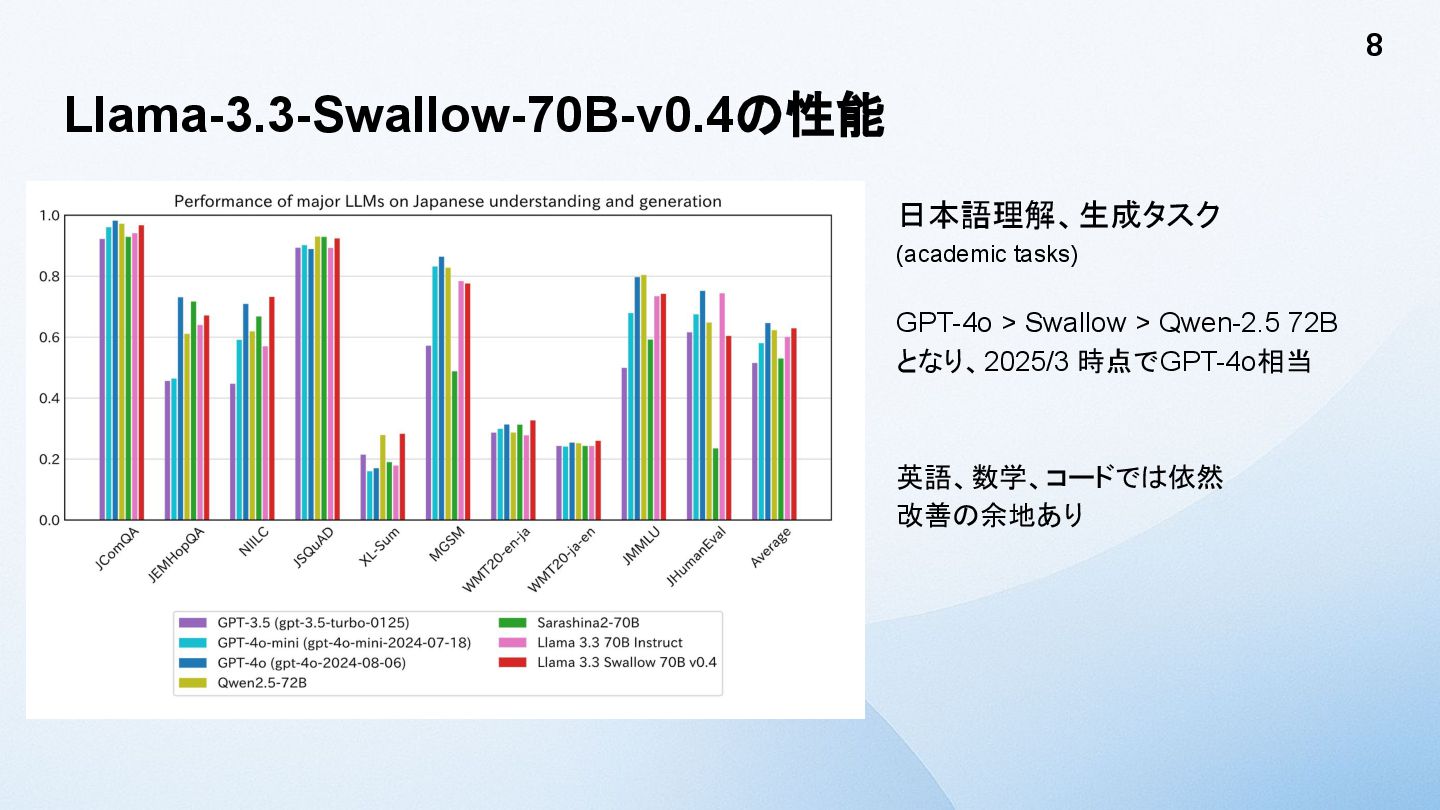
Llama-3.3-Swallow-70B-v0.4の性能 日本語理解、生成タスク (academic tasks) GPT-4o > Swallow > Qwen-2.5 72B
となり、2025/3 時点でGPT-4o相当 英語、数学、コードでは依然 改善の余地あり 8
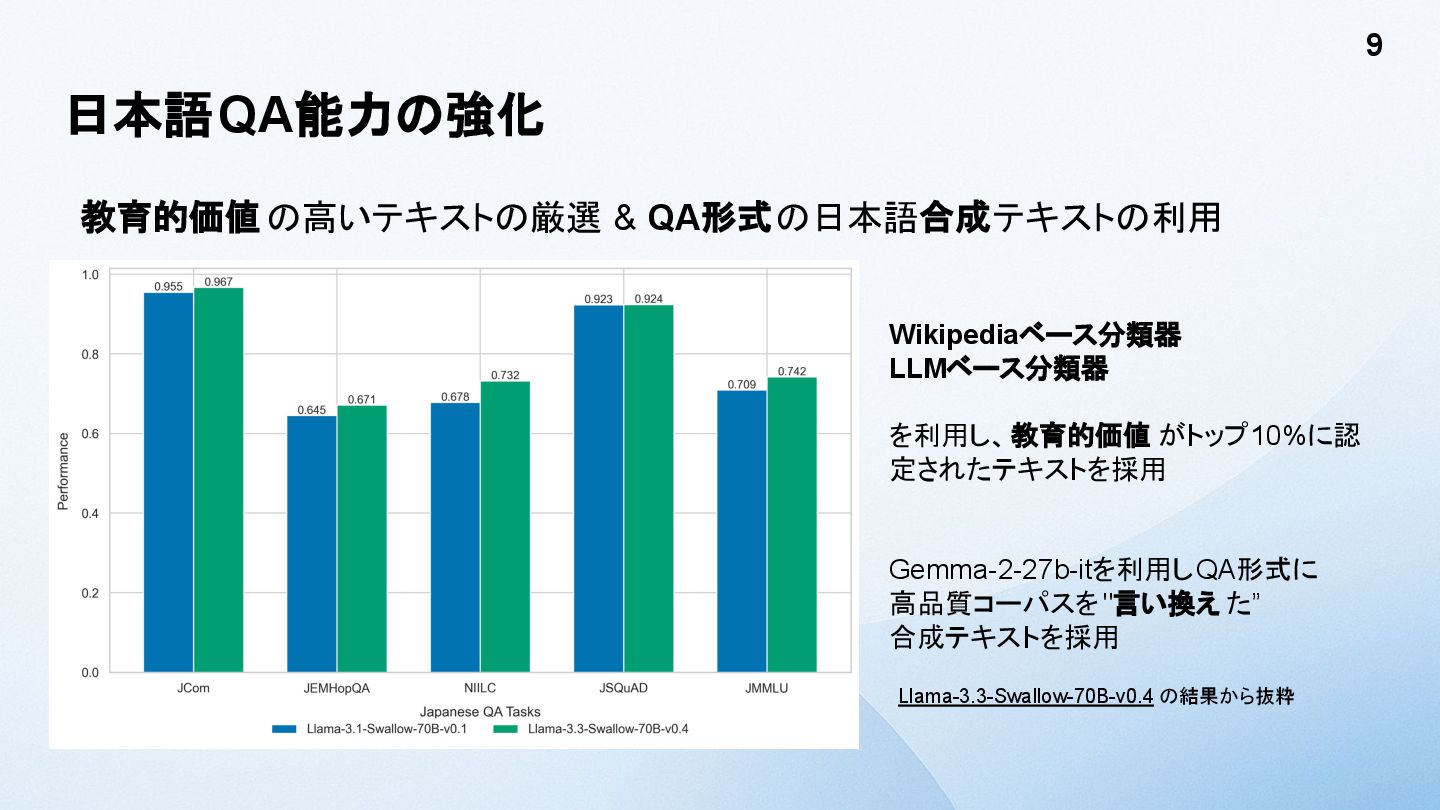
日本語QA能力の強化 教育的価値 の高いテキストの厳選 & QA形式の日本語合成テキストの利用 9 Wikipediaベース分類器 LLMベース分類器 を利用し、教育的価値 がトップ10%に認
定されたテキストを採用 Gemma-2-27b-itを利用しQA形式に 高品質コーパスを"言い換え た” 合成テキストを採用 Llama-3.3-Swallow-70B-v0.4 の結果から抜粋
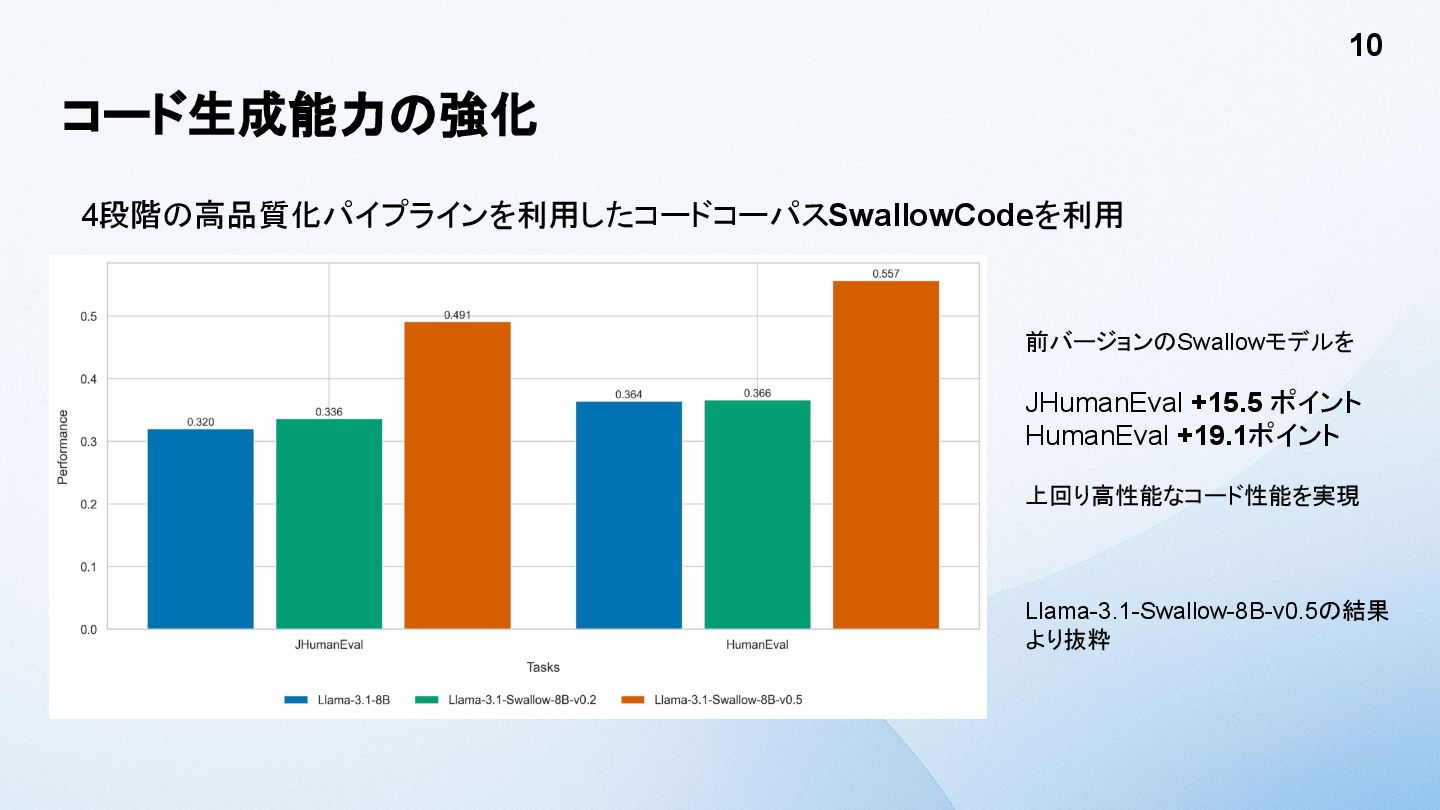
コード生成能力の強化 4段階の高品質化パイプラインを利用したコードコーパス SwallowCodeを利用 10 前バージョンのSwallowモデルを JHumanEval +15.5 ポイント HumanEval +19.1ポイント
上回り高性能なコード性能を実現 Llama-3.1-Swallow-8B-v0.5の結果 より抜粋
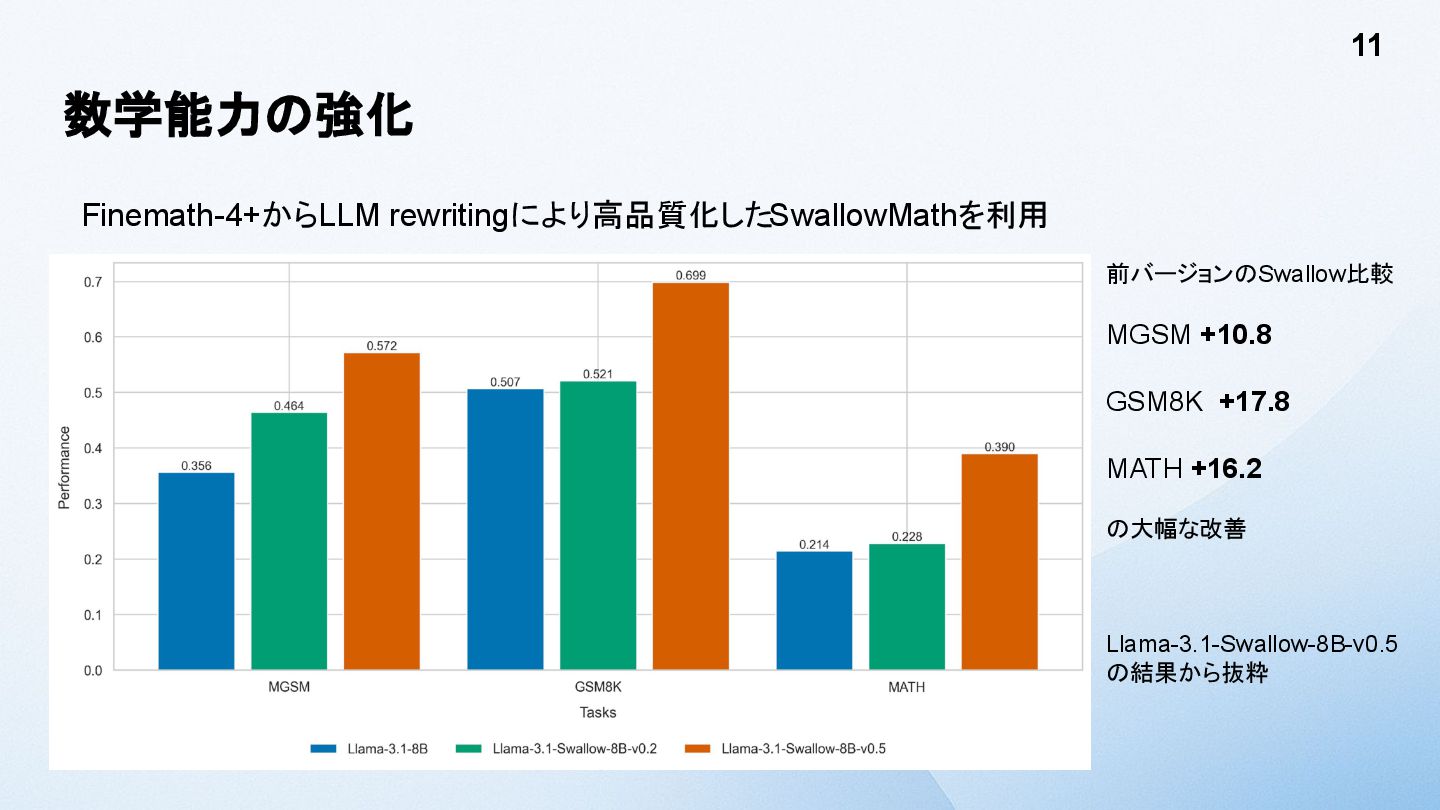
数学能力の強化 Finemath-4+からLLM rewritingにより高品質化したSwallowMathを利用 11 前バージョンのSwallow比較 MGSM +10.8 GSM8K +17.8 MATH
+16.2 の大幅な改善 Llama-3.1-Swallow-8B-v0.5 の結果から抜粋
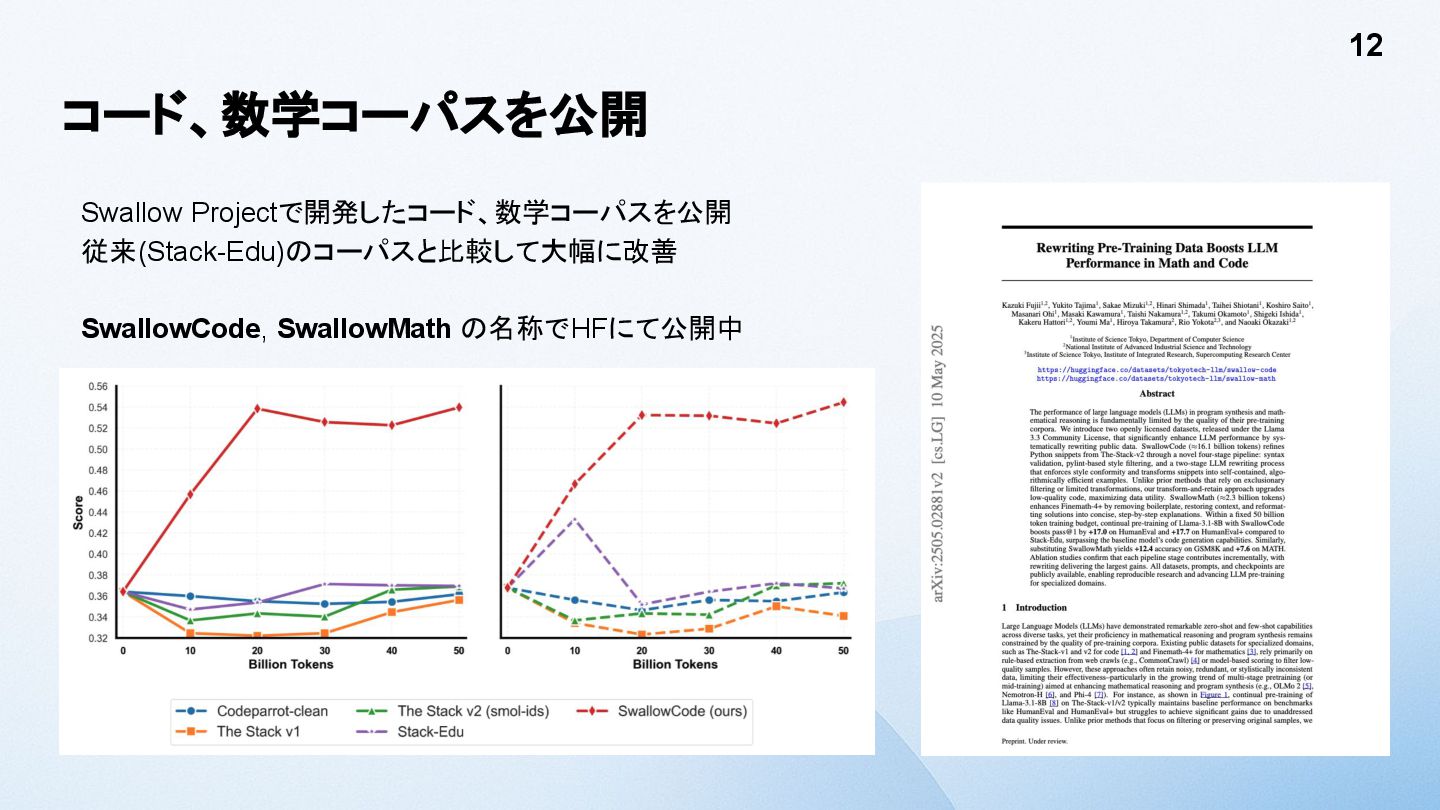
コード、数学コーパスを公開 Swallow Projectで開発したコード、数学コーパスを公開 従来(Stack-Edu)のコーパスと比較して大幅に改善 SwallowCode, SwallowMath の名称でHFにて公開中 12
AWSでの学習 Amazon SageMaker HyperPodを利用 (2025/1〜4) 13
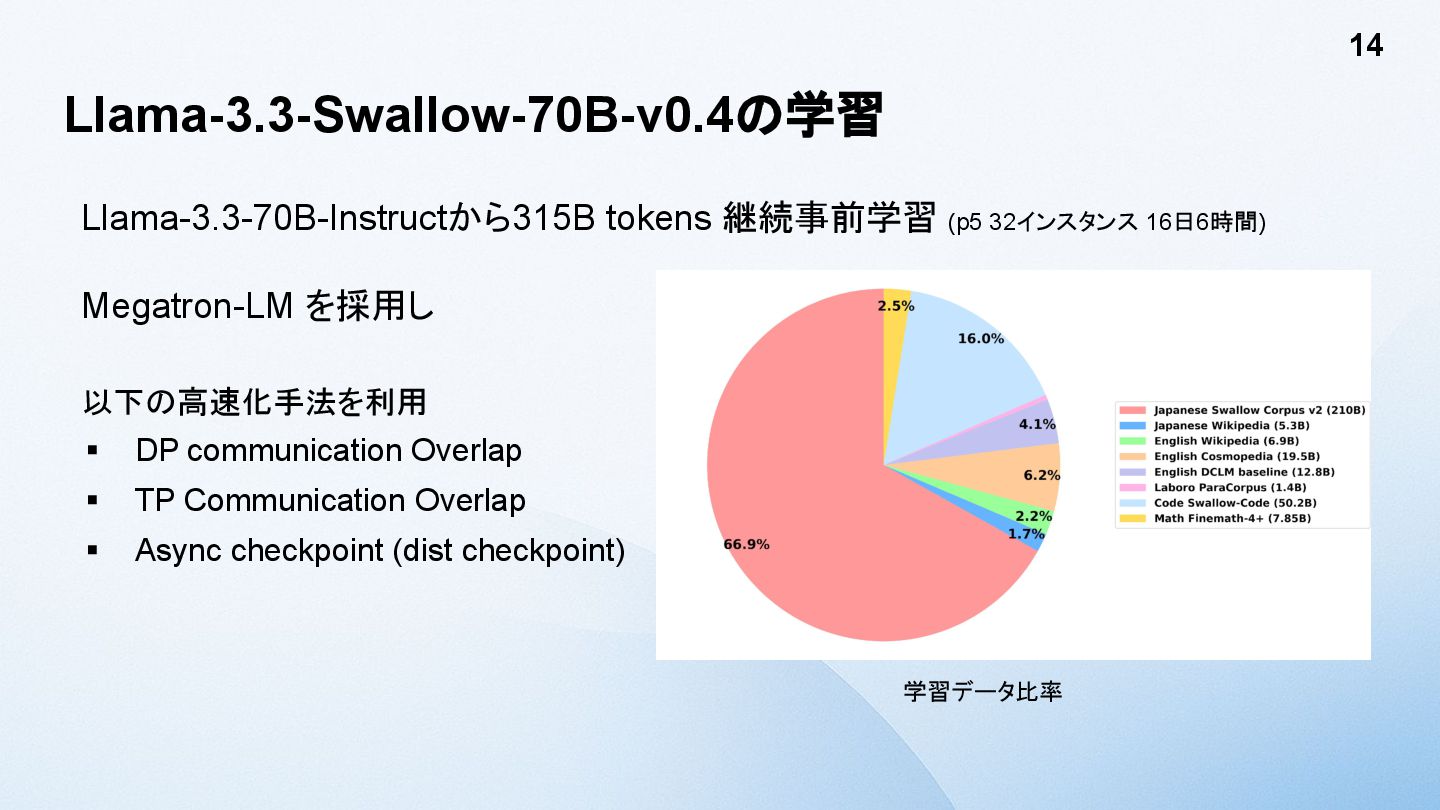
Llama-3.3-Swallow-70B-v0.4の学習 Llama-3.3-70B-Instructから315B tokens 継続事前学習 (p5 32インスタンス 16日6時間) Megatron-LM を採用し 以下の高速化手法を利用
▪ DP communication Overlap ▪ TP Communication Overlap ▪ Async checkpoint (dist checkpoint) 14 学習データ比率
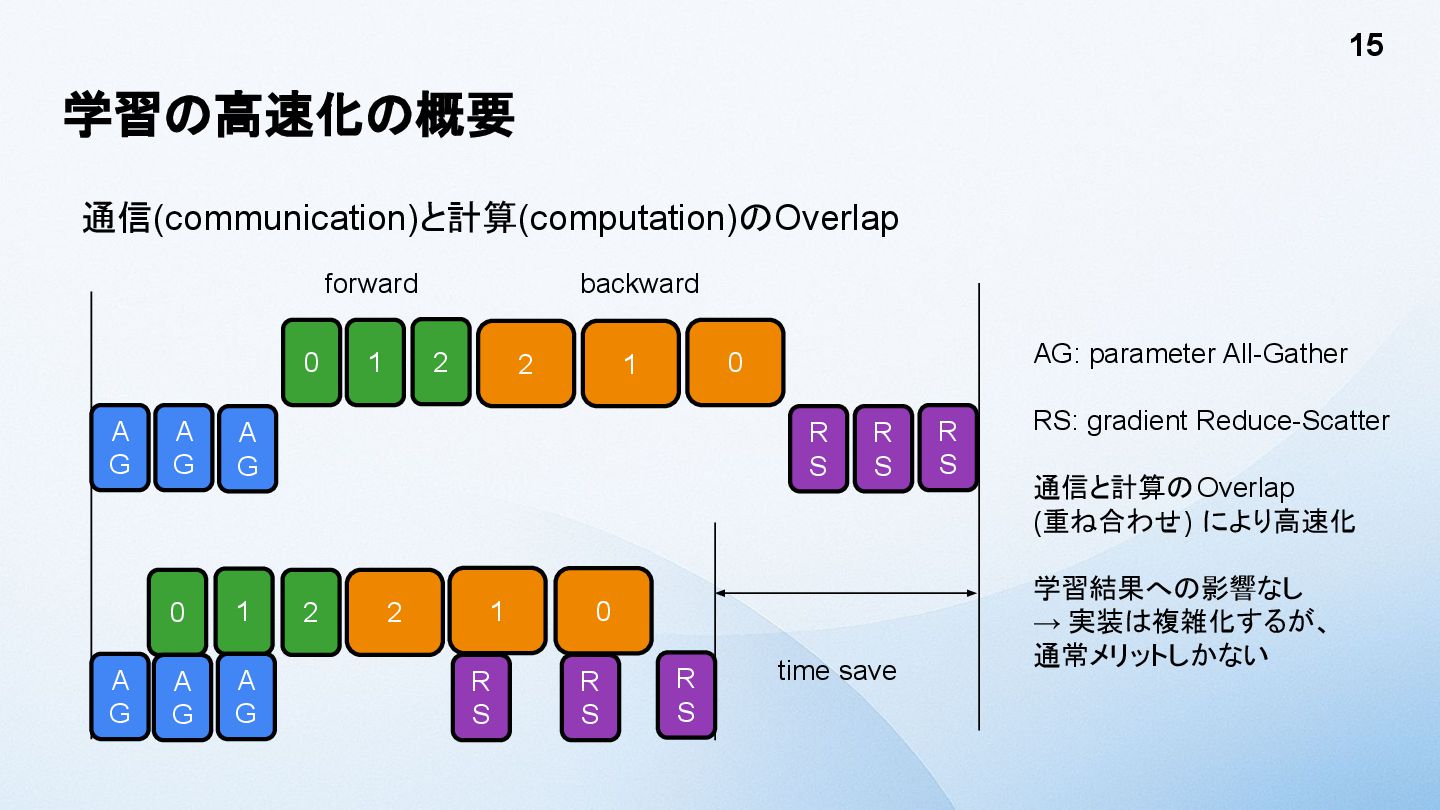
学習の高速化の概要 通信(communication)と計算(computation)のOverlap 15 A G A G A G 0
1 2 forward 2 1 0 R S R S R S backward A G 0 1 2 A G A G 2 R S 1 0 R S R S time save AG: parameter All-Gather RS: gradient Reduce-Scatter 通信と計算のOverlap (重ね合わせ) により高速化 学習結果への影響なし → 実装は複雑化するが、 通常メリットしかない
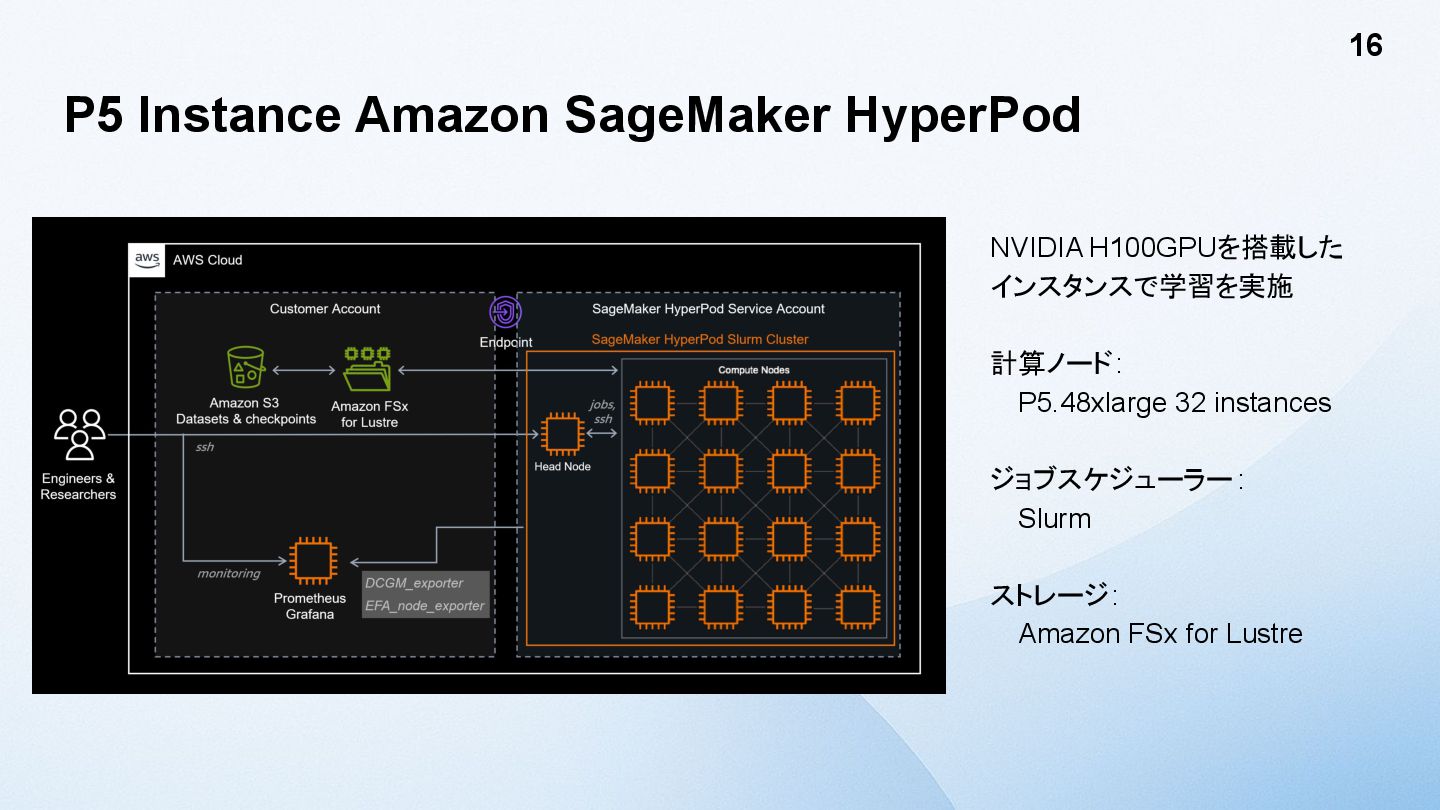
P5 Instance Amazon SageMaker HyperPod NVIDIA H100GPUを搭載した インスタンスで学習を実施 計算ノード: P5.48xlarge
32 instances ジョブスケジューラー : Slurm ストレージ: Amazon FSx for Lustre 16
Amazon Managed Grafanaによる監視基盤 Amazon Managed Service for PrometheusとAmazon Managed Grafanaによる監視基盤
学習時に発生する障害情報を収集 → エラー発生時の問題究明を迅速化 17 DCGM Exporter (GPU) EFA Exporter (EFA) 学習速度の低下や ジョブの停止の原因の 切り分けを容易に Down timeの最小化を実現
Amazon FSx for Lustre & Data Relation Amazon FSx for
LustreとAmazon S3間のデータ転送の簡便化 計算ノード(GPU)は高コストなためデプロイ後すぐに学習を開始したい = データ転送などでGPUがidleになるのは避けたい → 事前にAmazon S3にupload & DRA設定 18 DRAにより 転送ミス、デプロイ後の作業の肥 大化を回避 → 学習準備や計算ノードの デプロイに集中することが可能 Amazon FSx for Lutreへの 読み込みも高速
Swallow Projectの今後 フロンティアモデルへの挑戦と学習、推論の低コスト化に向けて 19
Swallow Projectの今後 ▪ モデルの高性能化 ▪ ベースモデル ▪ 事前学習モデルの数学、コード能力 のさらなる強化 ▪
ドメイン(金融、医療、法律)の知識の強化 ▪ チューニングモデル ▪ 強化学習 によるReasoning能力の強化 ▪ thinkモードとchatモードの動的切り替えの獲得 ▪ 学習、推論の低コスト化 ▪ 学習 ▪ 低精度学習 の実用化 (FP8, Blockwise Quantization) ▪ 推論 ▪ モデルアーキテクチャの変更 (SSM, Hybridモデル) 20
Swallow ProjectとAWS ▪ リリースモデルの学習 ▪ 学習データ、学習手法の検討は、大学の計算資源で行い大規模学習を AWS 等で実施 ▪ Llama-3.3-Swallow-70B-v0.4,
Llama-3.1-Swallow-8B-v0.5 など ▪ 最新世代GPUでの研究開発 ▪ MXFP8等の低精度を利用した推論、学習の高速化の研究開発で利用 (Blackwell) ▪ 大学のスパコンには導入されていないため ▪ TSUBAME 4.0 (H100) ▪ ABCI 3.0 (H200) 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}