Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
言語処理学会2024-継続事前学習による日本語に強い大規模言語モデルの構築
Search
Kazuki Fujii
December 14, 2025
Research
55
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
言語処理学会2024-継続事前学習による日本語に強い大規模言語モデルの構築
Kazuki Fujii
December 14, 2025
More Decks by Kazuki Fujii
See All by Kazuki Fujii
IHPCSS2025-Kazuki-Fujii
fujiikazuki2000
0
30
2024-02-Tokyo-Tech-大規模言語モデルの事前学習知見
fujiikazuki2000
0
39
情報処理学会-全国大会2024-大規模言語モデルの分散並列学習
fujiikazuki2000
0
37
AWS Summit Japan 2025 Amazon SageMaker HyperPodを利用した日本語LLM(Swallow)の構築 (CUS-02)
fujiikazuki2000
0
50
合成データパイプラインを利用したSwallowProjectに おけるLLM性能向上
fujiikazuki2000
1
300
論文では語られないLLM開発において重要なこと Swallow Projectを通して
fujiikazuki2000
8
2k
大規模言語モデルの学習知見
fujiikazuki2000
0
210
自然言語処理のための分散並列学習
fujiikazuki2000
1
720
Other Decks in Research
See All in Research
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
210
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
500
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
170
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
400
LLM Compute Infrastructure Overview
karakurist
2
1.5k
Cross-Media Information Spaces and Architectures
signer
PRO
0
310
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
150
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
150
Featured
See All Featured
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Why Our Code Smells
bkeepers
PRO
340
58k
KATA
mclloyd
PRO
35
15k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Between Models and Reality
mayunak
4
370
Crafting Experiences
bethany
1
210
Technical Leadership for Architectural Decision Making
baasie
3
440
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Utilizing Notion as your number one productivity tool
mfonobong
4
360
How to build a perfect <img>
jonoalderson
1
5.8k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Transcript
継続事前学習による日本語に強い 大規模言語モデルの構築 東京工業大学 藤井一喜 中村泰士 Mengsay Loem 飯田大貴 大井聖也 服部翔 平井翔太 水木栄 横田理央 岡崎直観 A8-5
2 概要 • Llama 2をベースに日本語コーパスで継続事前学習 • 7B, 13B, 70B のモデル規模にて効果を確認
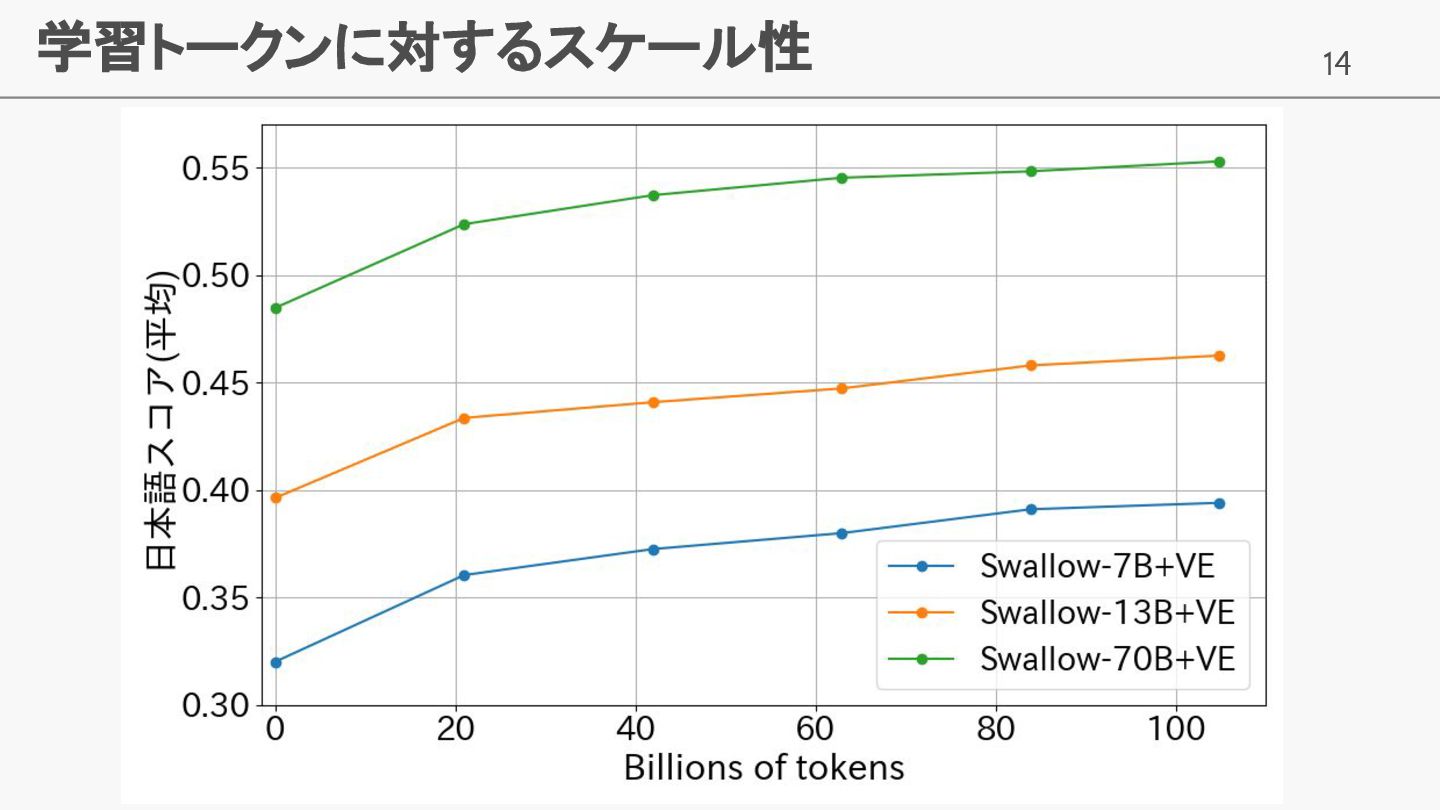
• 学習データ量の増加に伴い日本語性能が向上することを確 認
3 発表構成 • 背景、貢献 • モデルの学習 • モデルの評価
4 背景 • 英語言語資源 >> 日本語言語資源 • Common Crawlでは推定 英語:日本語
= 9:1 • from scratchからの事前学習には膨大な計算資源が必要 • 仮に本実験をfrom scratchから行うと約 20倍の計算資源が必要 → 英語LLM (Llama 2)から継続事前学習を行う 能力や知識を日本語に転移することを狙う
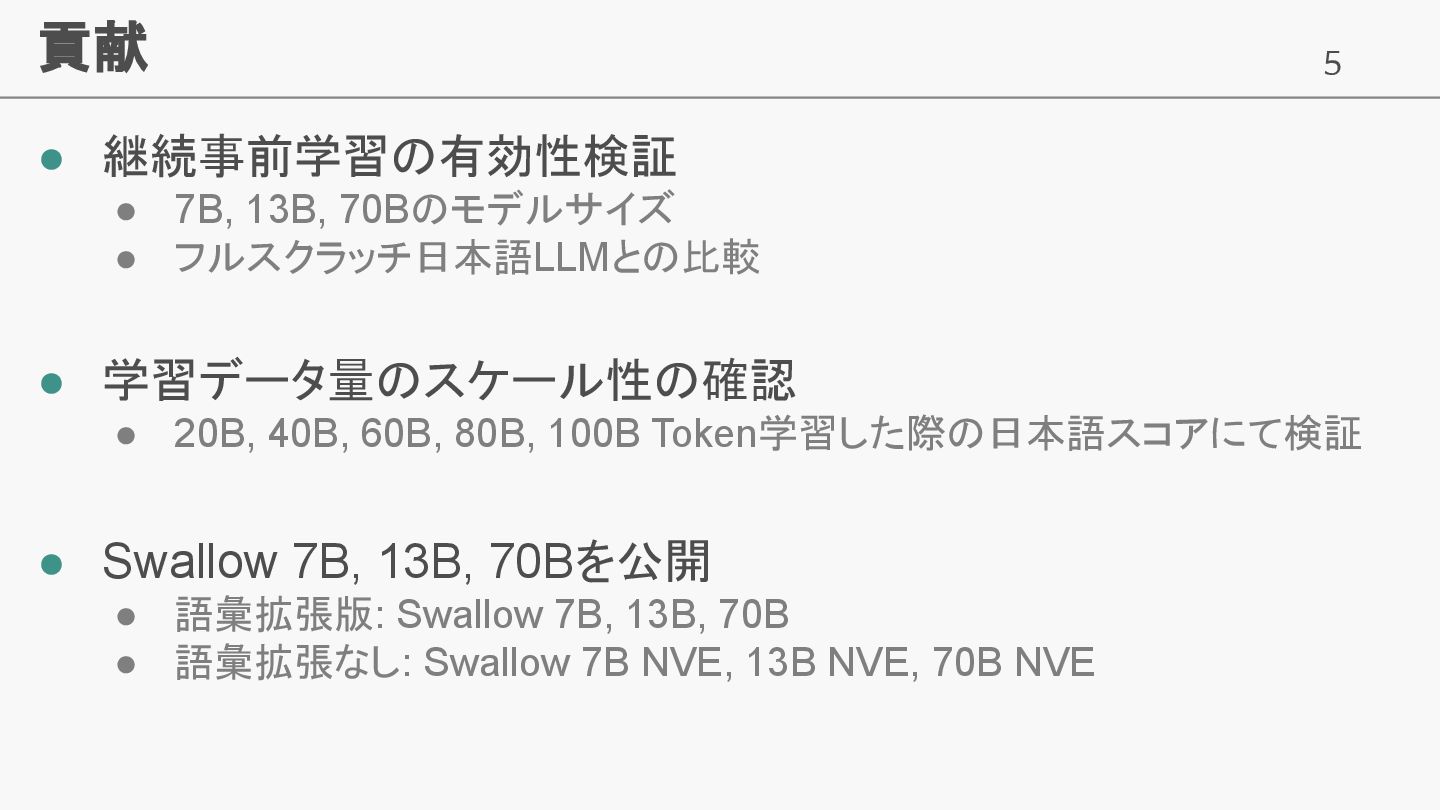
5 貢献 • 継続事前学習の有効性検証 • 7B, 13B, 70Bのモデルサイズ • フルスクラッチ日本語LLMとの比較
• 学習データ量のスケール性の確認 • 20B, 40B, 60B, 80B, 100B Token学習した際の日本語スコアにて検証 • Swallow 7B, 13B, 70Bを公開 • 語彙拡張版: Swallow 7B, 13B, 70B • 語彙拡張なし: Swallow 7B NVE, 13B NVE, 70B NVE
6 継続事前学習 Meta Llama 2 Swallow Swallow Corpus
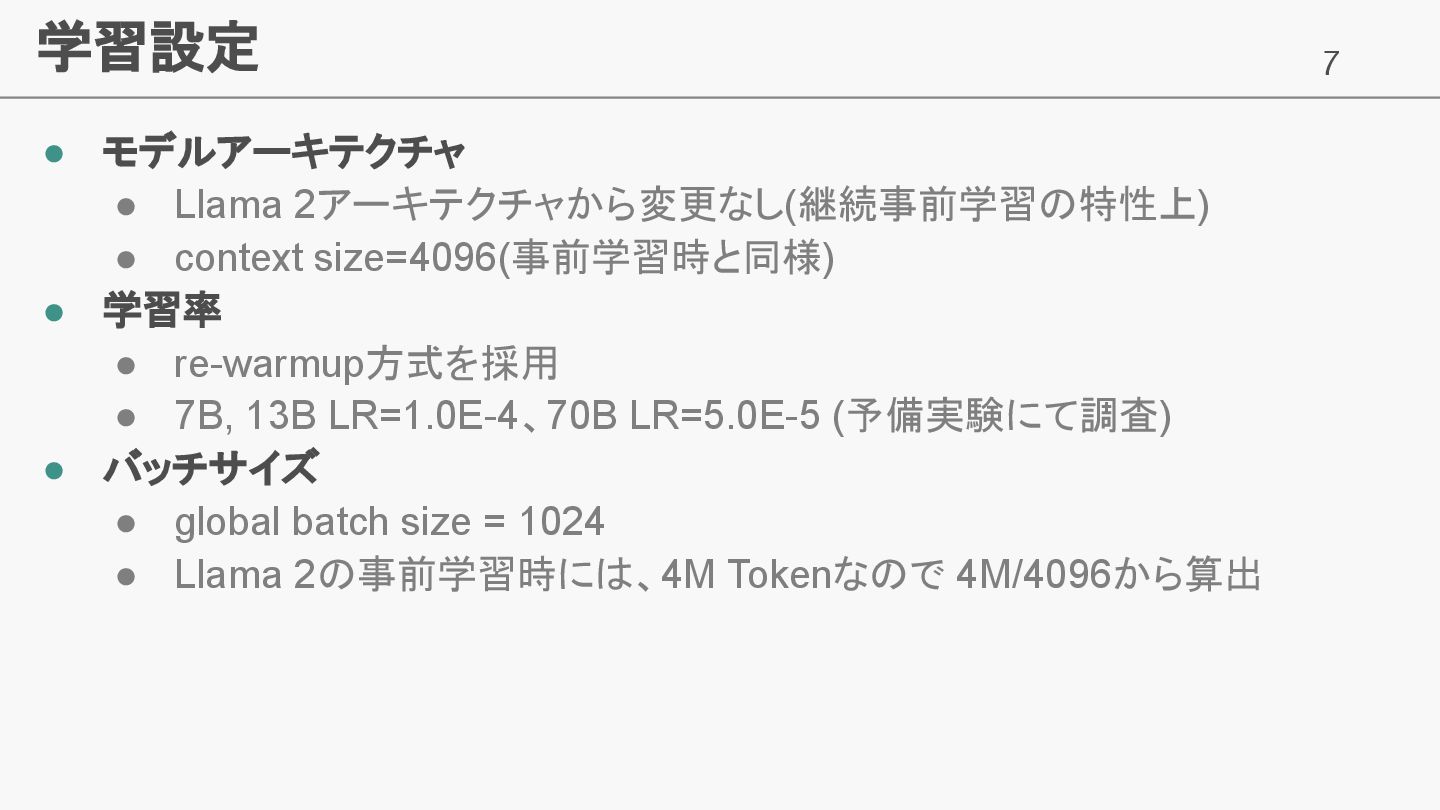
7 学習設定 • モデルアーキテクチャ • Llama 2アーキテクチャから変更なし(継続事前学習の特性上) • context size=4096(事前学習時と同様)
• 学習率 • re-warmup方式を採用 • 7B, 13B LR=1.0E-4、70B LR=5.0E-5 (予備実験にて調査) • バッチサイズ • global batch size = 1024 • Llama 2の事前学習時には、4M Tokenなので 4M/4096から算出
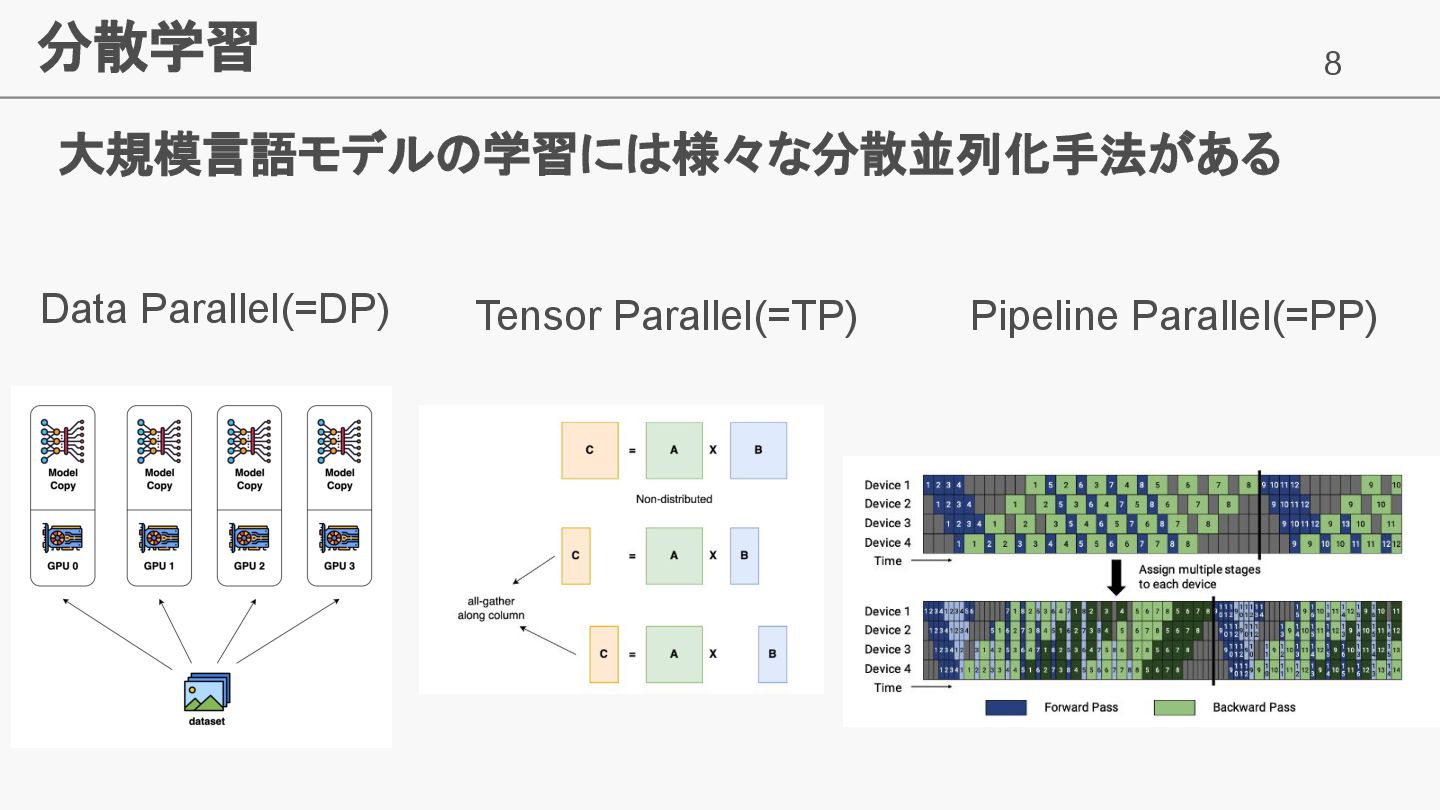
8 分散学習 大規模言語モデルの学習には様々な分散並列化手法がある Data Parallel(=DP) Tensor Parallel(=TP) Pipeline Parallel(=PP)
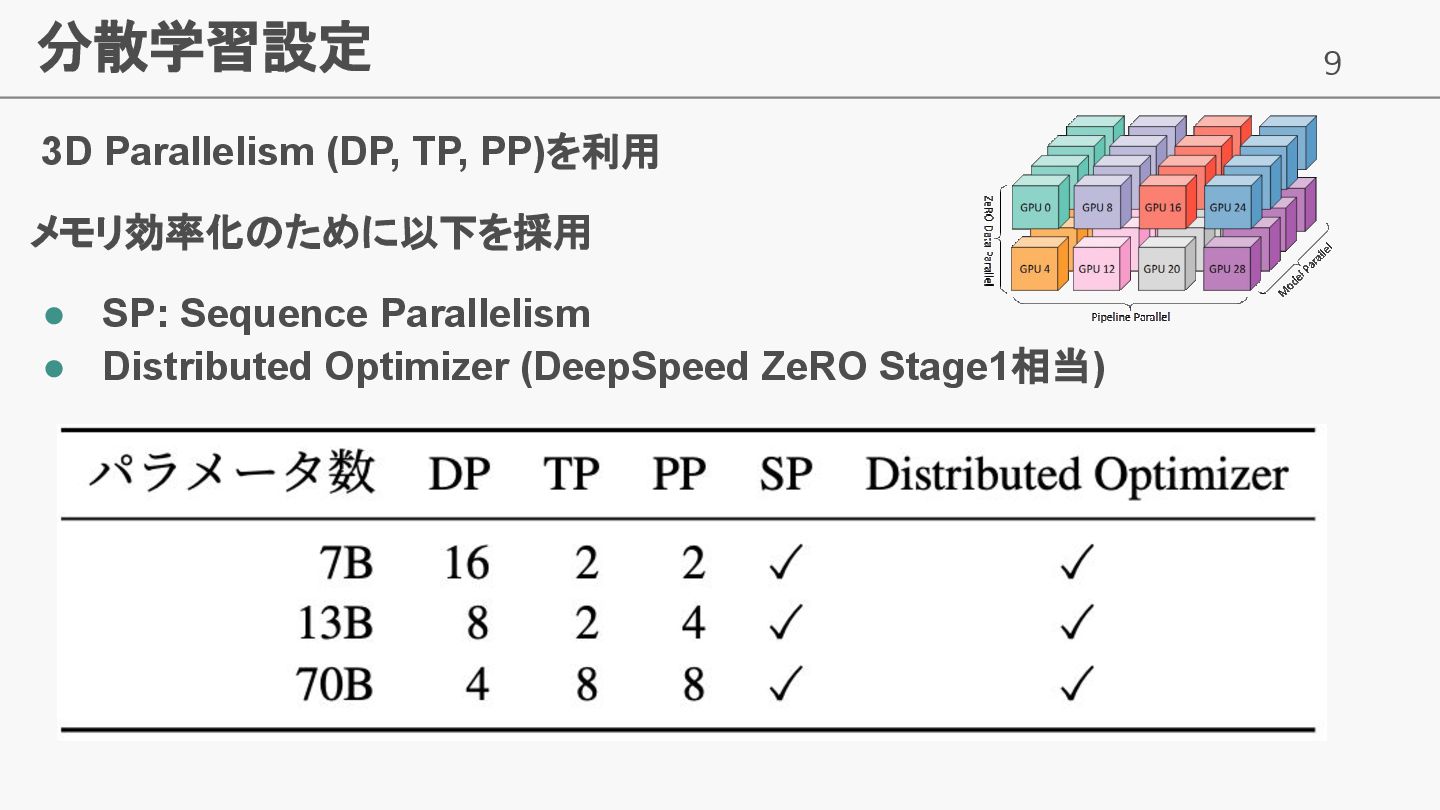
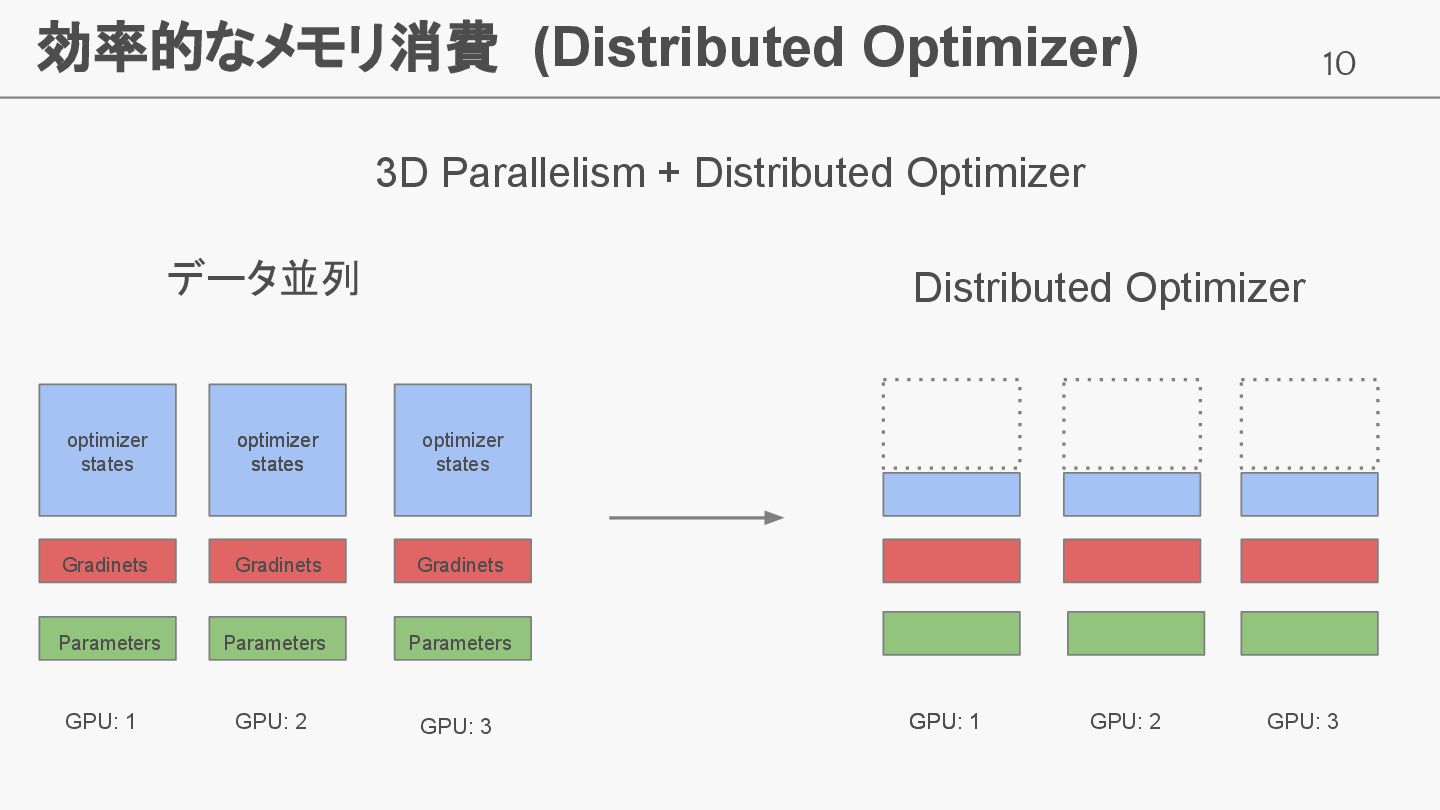
9 分散学習設定 3D Parallelism (DP, TP, PP)を利用 メモリ効率化のために以下を採用 • SP:
Sequence Parallelism • Distributed Optimizer (DeepSpeed ZeRO Stage1相当)
10 効率的なメモリ消費 (Distributed Optimizer) データ並列 Distributed Optimizer GPU: 1 GPU:
2 GPU: 3 GPU: 1 GPU: 1 GPU: 2 GPU: 3 3D Parallelism + Distributed Optimizer optimizer states optimizer states optimizer states Gradinets optimizer states Gradinets Gradinets Parameters Parameters Parameters
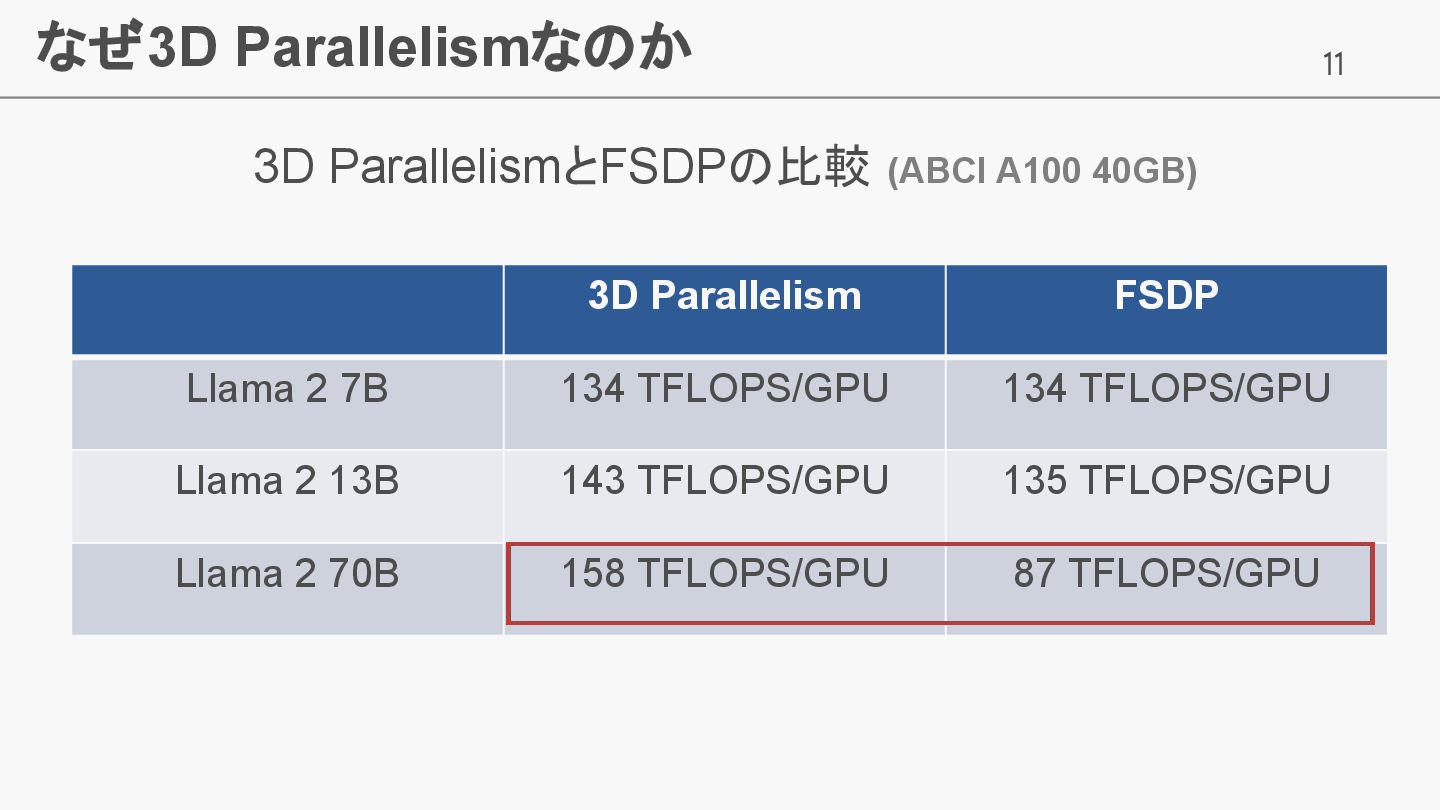
11 なぜ3D Parallelismなのか 3D ParallelismとFSDPの比較 (ABCI A100 40GB) 3D Parallelism
FSDP Llama 2 7B 134 TFLOPS/GPU 134 TFLOPS/GPU Llama 2 13B 143 TFLOPS/GPU 135 TFLOPS/GPU Llama 2 70B 158 TFLOPS/GPU 87 TFLOPS/GPU
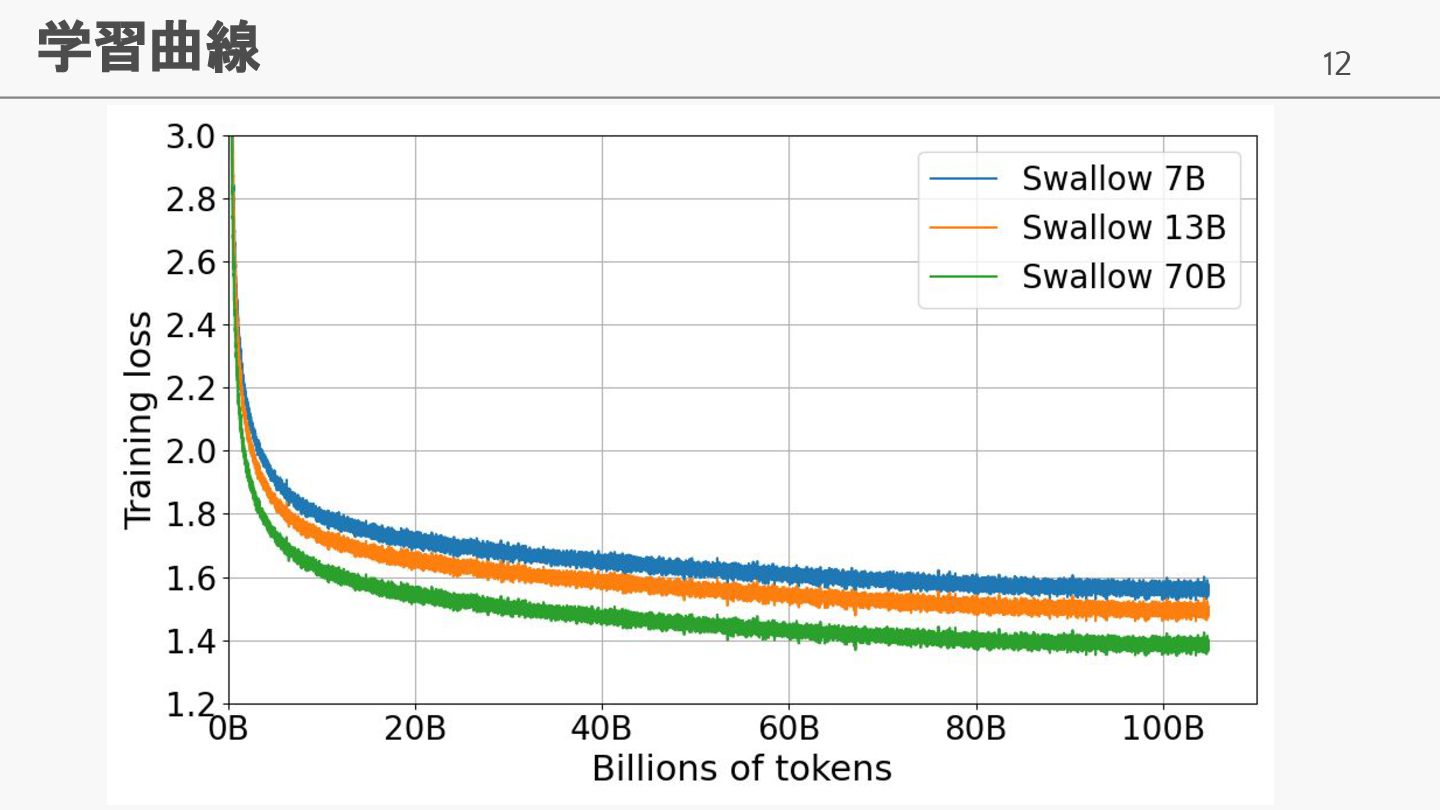
12 学習曲線
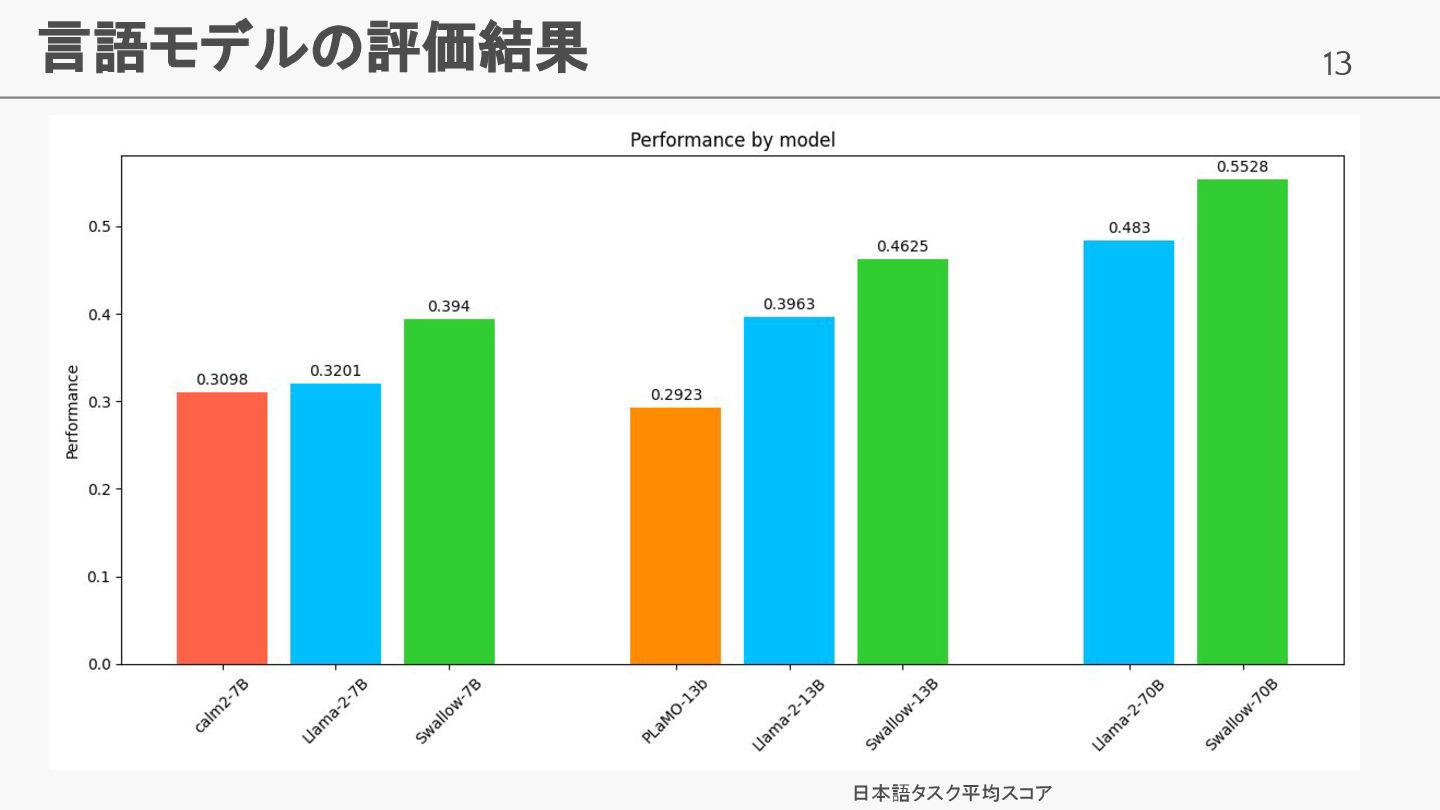
13 言語モデルの評価結果 日本語タスク平均スコア
14 学習トークンに対するスケール性
15 結論と今後の展望 • 結論 • 継続事前学習は有効 • 学習データ量に対するスケール性が存在 • 展望
• Llama 2以外のベースモデルからの継続事前学習 • 指示チューニングモデルの改善 • MoE(Mixture of Experts)モデルでの継続事前学習
補足資料
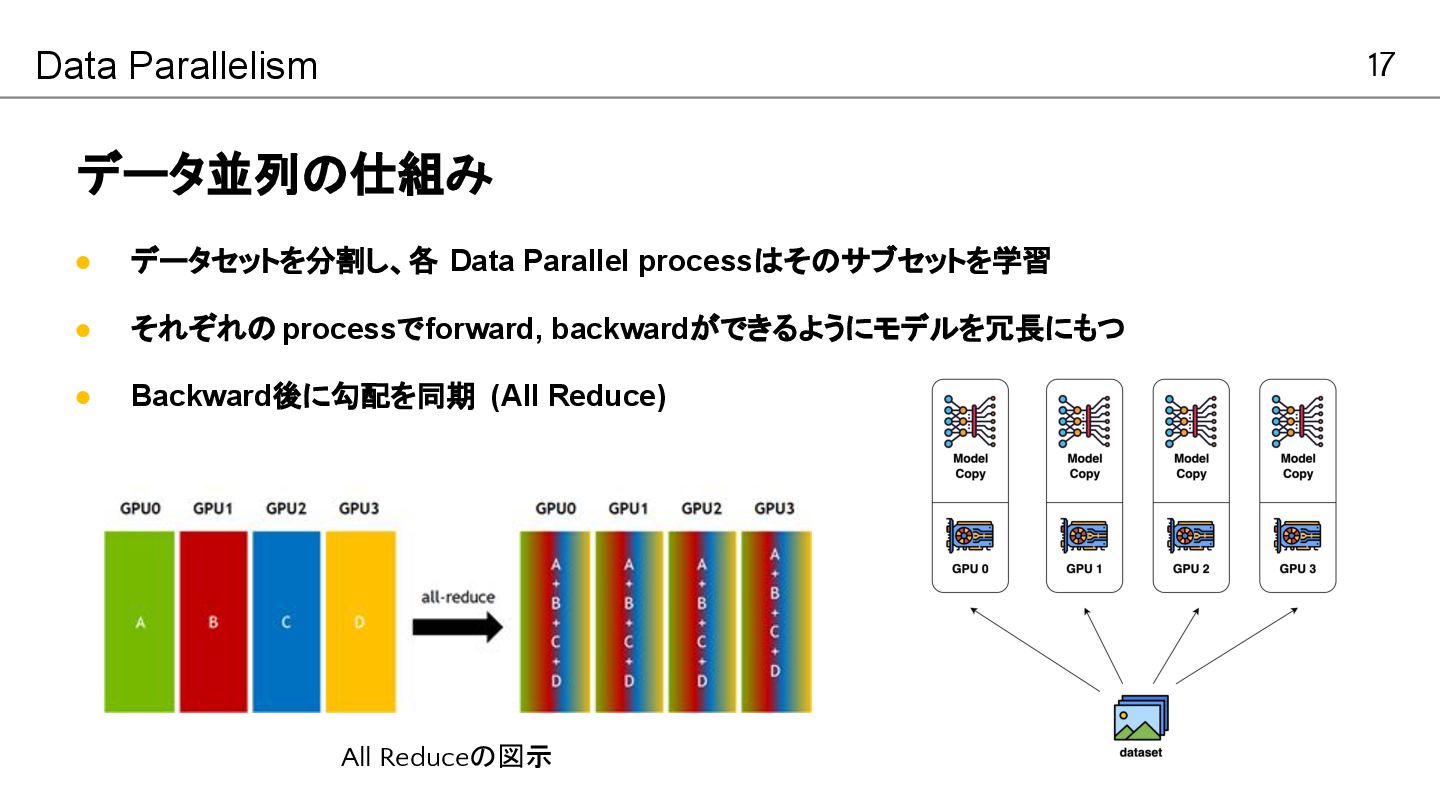
17 データ並列の仕組み Data Parallelism • データセットを分割し、各 Data Parallel processはそのサブセットを学習 •
それぞれの processでforward, backwardができるようにモデルを冗長にもつ • Backward後に勾配を同期 (All Reduce) All Reduceの図示
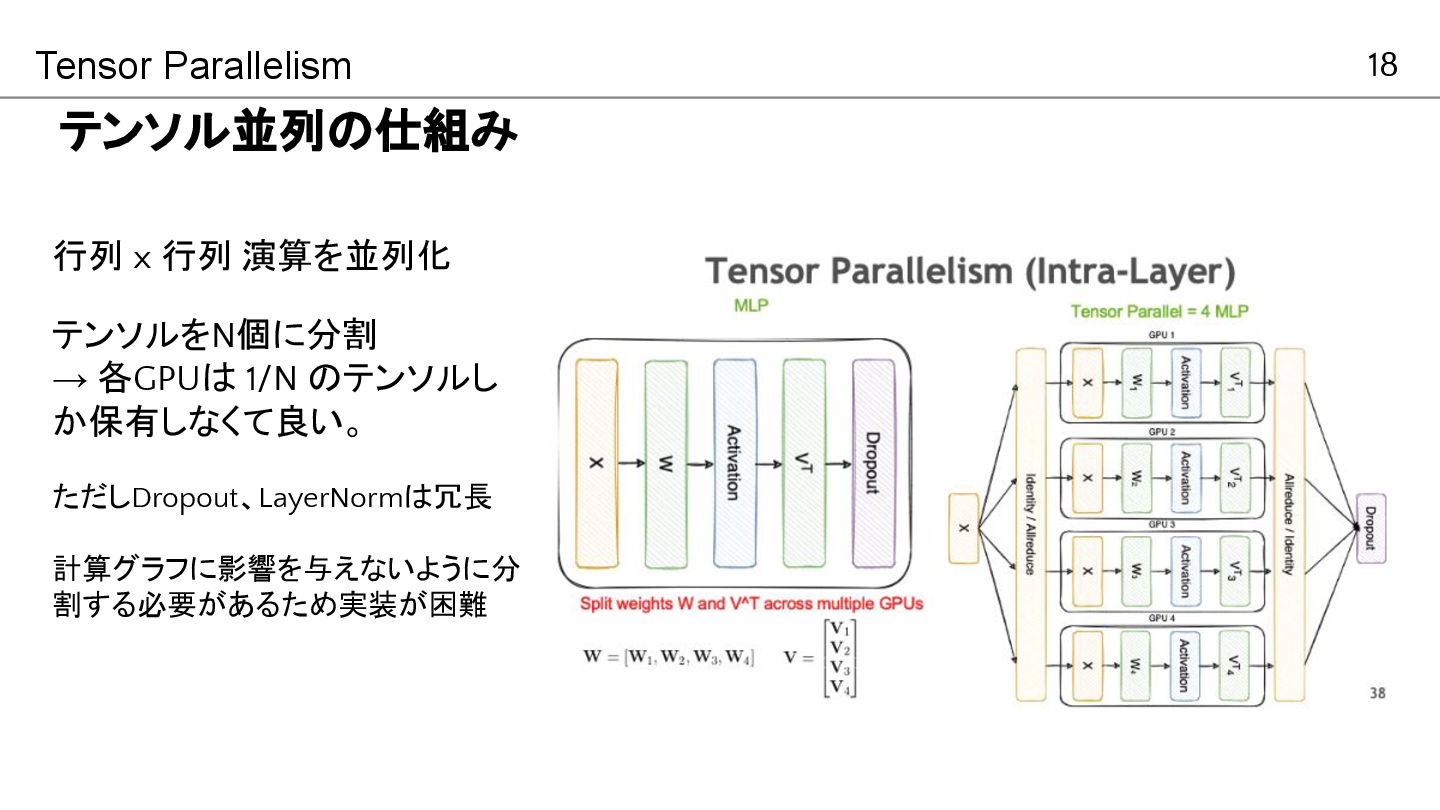
18 テンソル並列の仕組み Tensor Parallelism Dosovitskiy et al, ICLR2021, “An Image
is Worth 16x16 Words: Transformers for Image Recognition at Scale” 行列 x 行列 演算を並列化 テンソルをN個に分割 → 各GPUは 1/N のテンソルし か保有しなくて良い。 ただしDropout、LayerNormは冗長 計算グラフに影響を与えないように分 割する必要があるため実装が困難
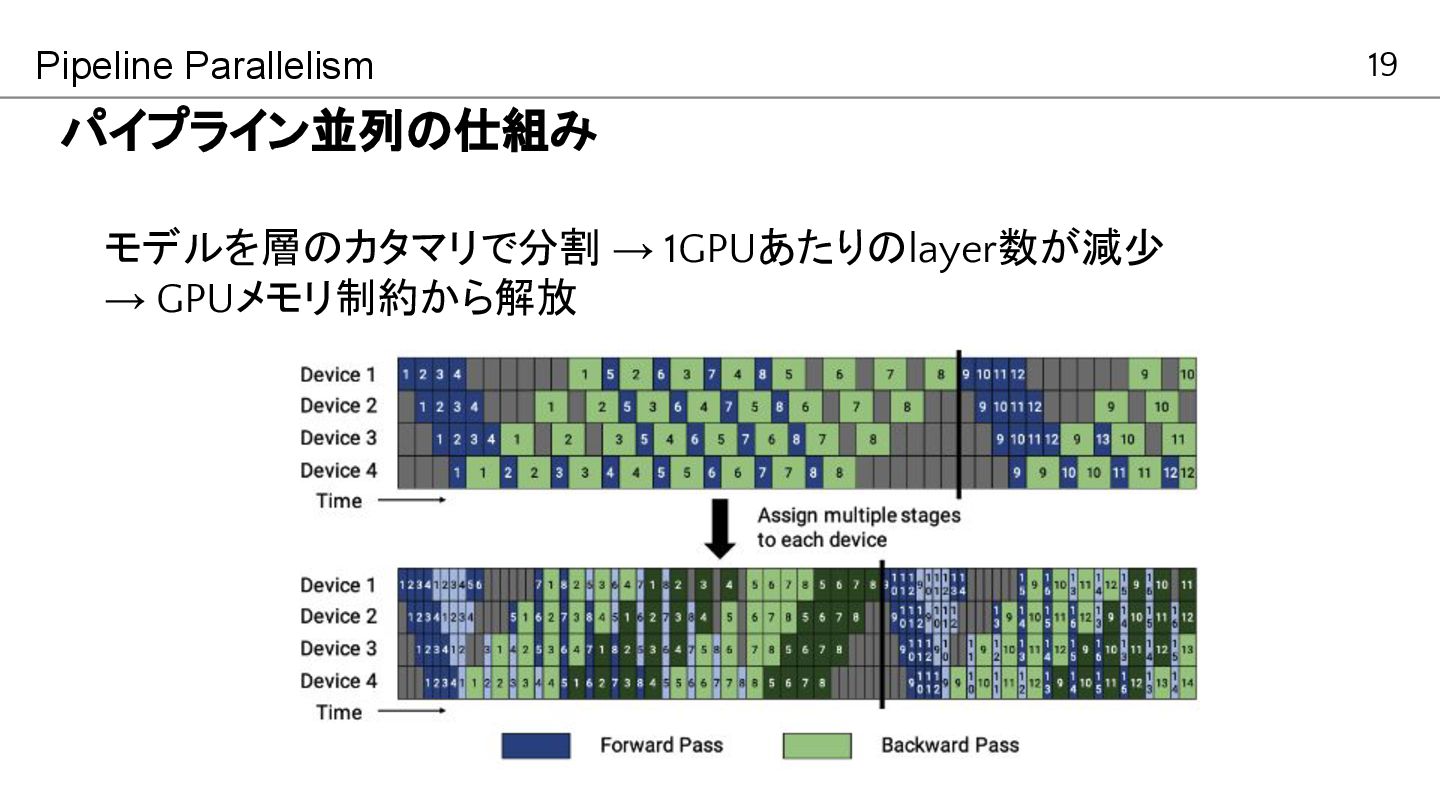
19 パイプライン並列の仕組み Pipeline Parallelism Dosovitskiy et al, ICLR2021, “An Image
is Worth 16x16 Words: Transformers for Image Recognition at Scale” モデルを層のカタマリで分割 → 1GPUあたりのlayer数が減少 → GPUメモリ制約から解放
20 学習コーパス Swallow Corpus 継続事前学習データ 日:英=9:1 日本語データ (90%) • Swallow
Corpus • 日本語Wikipedia 英語データ (10%) • RefinedWeb • The Pile arXiv Swallow Corpusについては、JNLP2024 「Swallow コーパス: 日本語大規模ウェブコーパス」 を参照のこと
21 学習ライブラリ 1. 3D Parallelism をサポート 2. Llamaアーキテクチャに対応 3. HF
→ Megatron 変換コードあり 詳細 ↓
22 評価タスク 言語モデルの日本語評価ベンチマーク • llm-jp eval (v1.0.0) • JP Language
Model Evaluation Harness • llm-jp eval • JCommonsenseQA、JEMHopQA、NIILC、JSQuAD • Evaluation Harness • XL-Sum, MGSM、WMT 2020 Japanese ↔ English
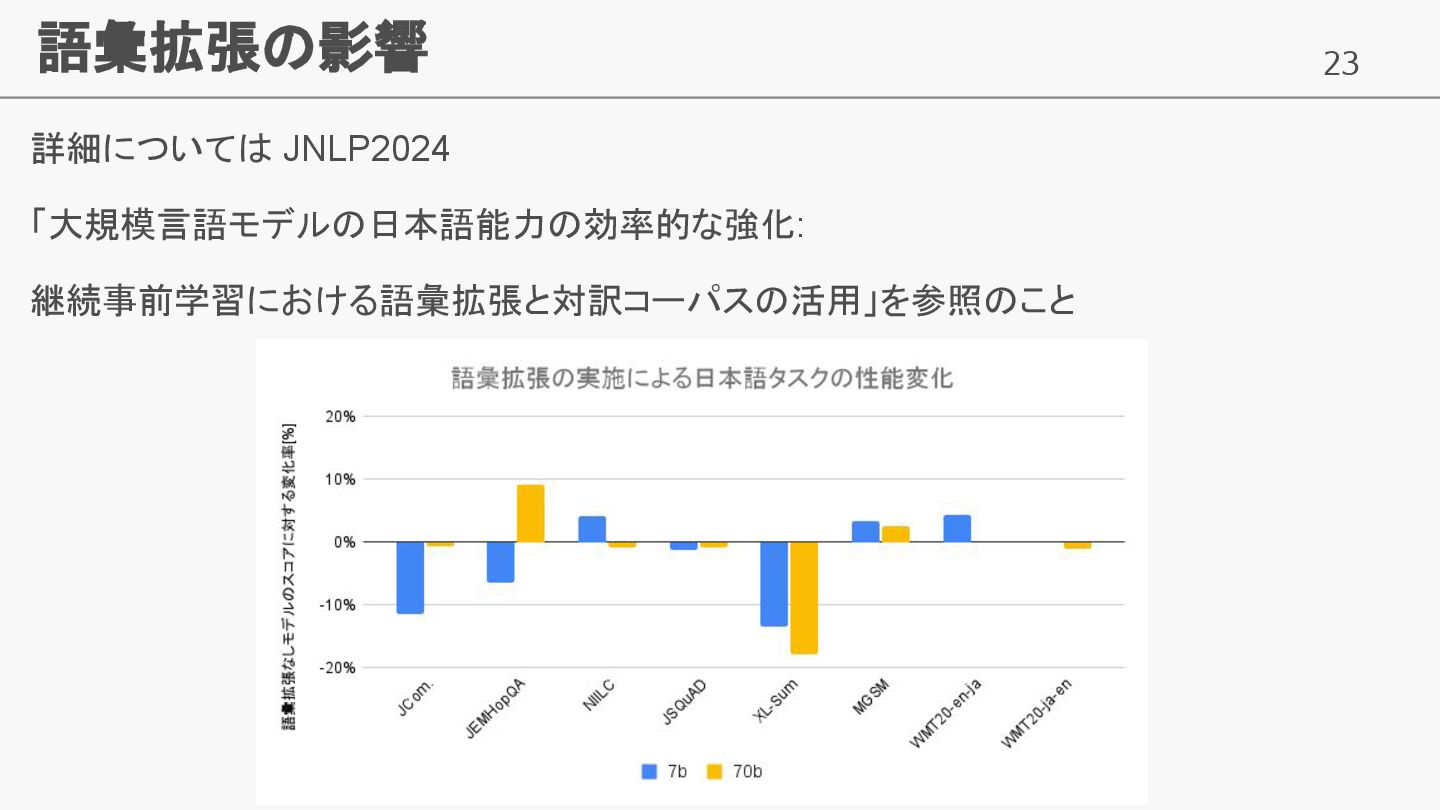
23 語彙拡張の影響 詳細については JNLP2024 「大規模言語モデルの日本語能力の効率的な強化: 継続事前学習における語彙拡張と対訳コーパスの活用」を参照のこと
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}