Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
情報処理学会-全国大会2024-大規模言語モデルの分散並列学習
Search
Kazuki Fujii
December 14, 2025
Research
37
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
情報処理学会-全国大会2024-大規模言語モデルの分散並列学習
Kazuki Fujii
December 14, 2025
More Decks by Kazuki Fujii
See All by Kazuki Fujii
IHPCSS2025-Kazuki-Fujii
fujiikazuki2000
0
30
2024-02-Tokyo-Tech-大規模言語モデルの事前学習知見
fujiikazuki2000
0
39
言語処理学会2024-継続事前学習による日本語に強い大規模言語モデルの構築
fujiikazuki2000
0
55
AWS Summit Japan 2025 Amazon SageMaker HyperPodを利用した日本語LLM(Swallow)の構築 (CUS-02)
fujiikazuki2000
0
50
合成データパイプラインを利用したSwallowProjectに おけるLLM性能向上
fujiikazuki2000
1
300
論文では語られないLLM開発において重要なこと Swallow Projectを通して
fujiikazuki2000
8
2k
大規模言語モデルの学習知見
fujiikazuki2000
0
210
自然言語処理のための分散並列学習
fujiikazuki2000
1
720
Other Decks in Research
See All in Research
Harness Engineering and Al Agent
kzinmr
3
1.8k
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
370
事後確率分布の共分散について
koide3
0
170
「車1割削減、渋滞半減、公共交通2倍」を 熊本から岡山へ@RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
1
1.3k
Using our influence and power for patient safety
helenbevan
0
370
AIで最適化を解けるか?
mickey_kubo
0
140
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
870
Fukui Shibiten 39 - AI Art
butchi
0
140
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
130
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
840
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
210
Featured
See All Featured
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Done Done
chrislema
186
16k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
410
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Tell your own story through comics
letsgokoyo
1
990
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
KATA
mclloyd
PRO
35
15k
Transcript
大規模言語モデルの分散並列学習 東京工業大学 藤井一喜 横田理央 5J-02
2 概要 • Llama 2をベースに日本語コーパスで継続事前学習 • 7B, 13B, 70B のモデル規模にて分散並列学習
• メモリ効率化のための工夫を行った3D Parallelism
3 継続事前学習 Meta Llama 2 Swallow Swallow Corpus
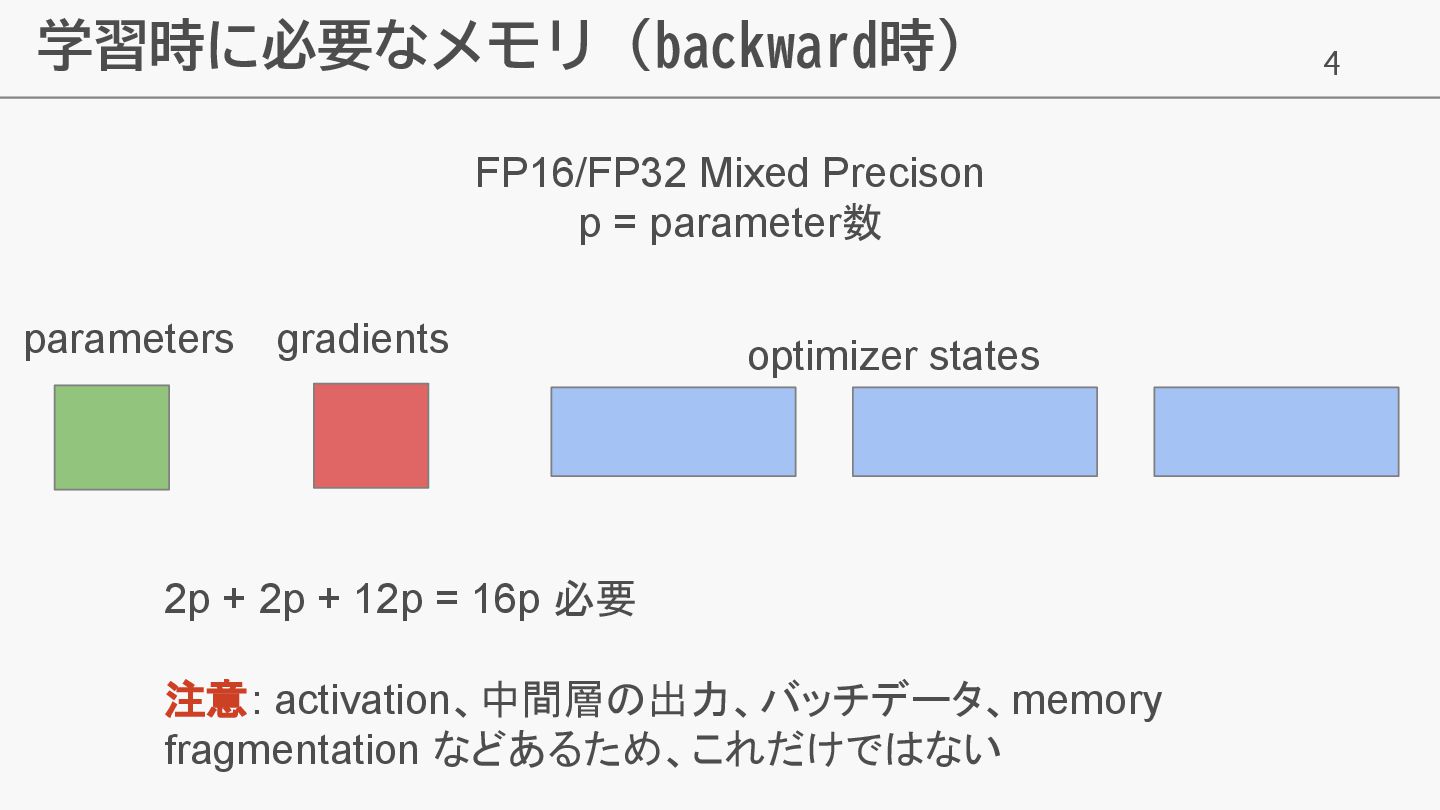
4 学習時に必要なメモリ (backward時) FP16/FP32 Mixed Precison p = parameter数 parameters
gradients optimizer states 2p + 2p + 12p = 16p 必要 注意: activation、中間層の出力、バッチデータ、memory fragmentation などあるため、これだけではない
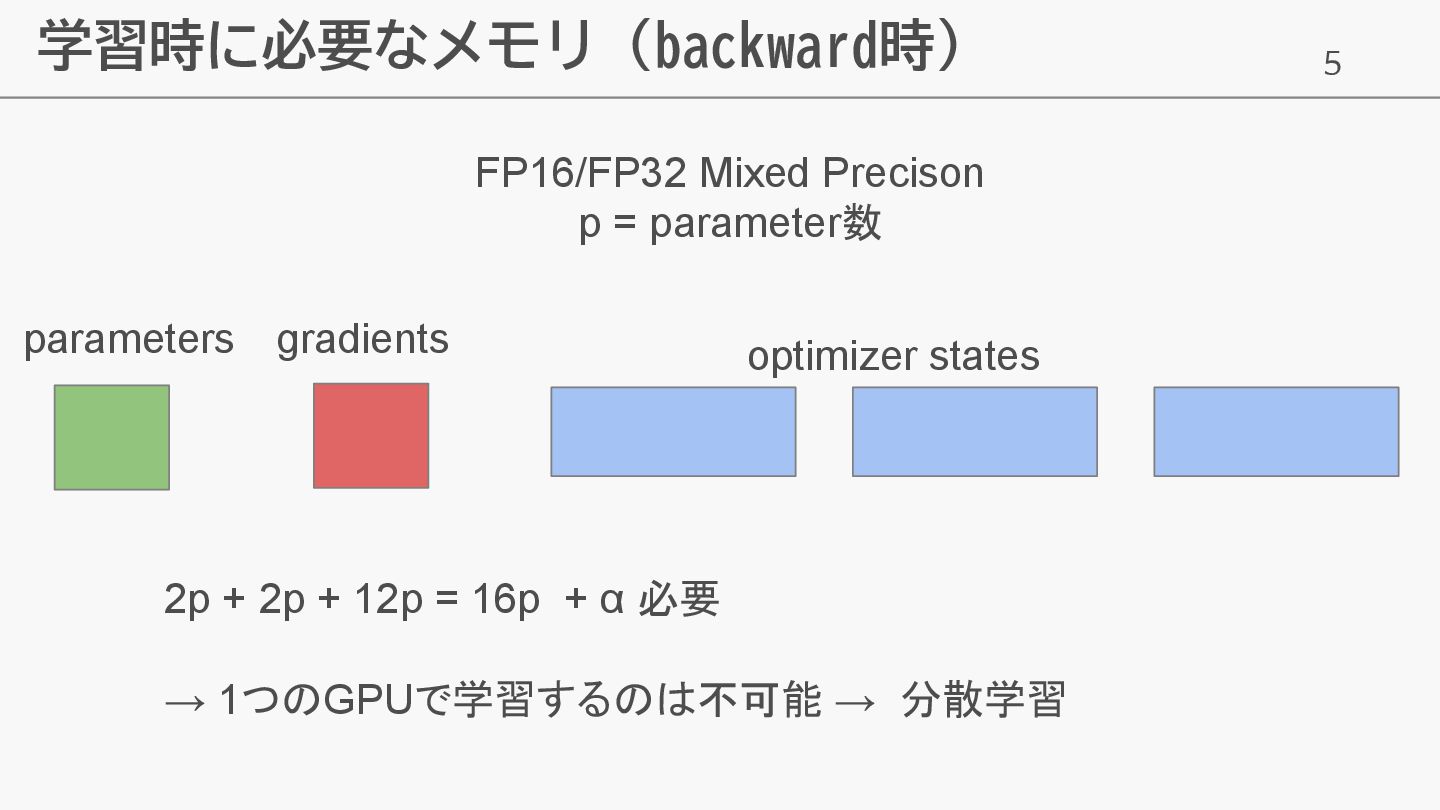
5 学習時に必要なメモリ (backward時) FP16/FP32 Mixed Precison p = parameter数 parameters
gradients optimizer states 2p + 2p + 12p = 16p + α 必要 → 1つのGPUで学習するのは不可能 → 分散学習
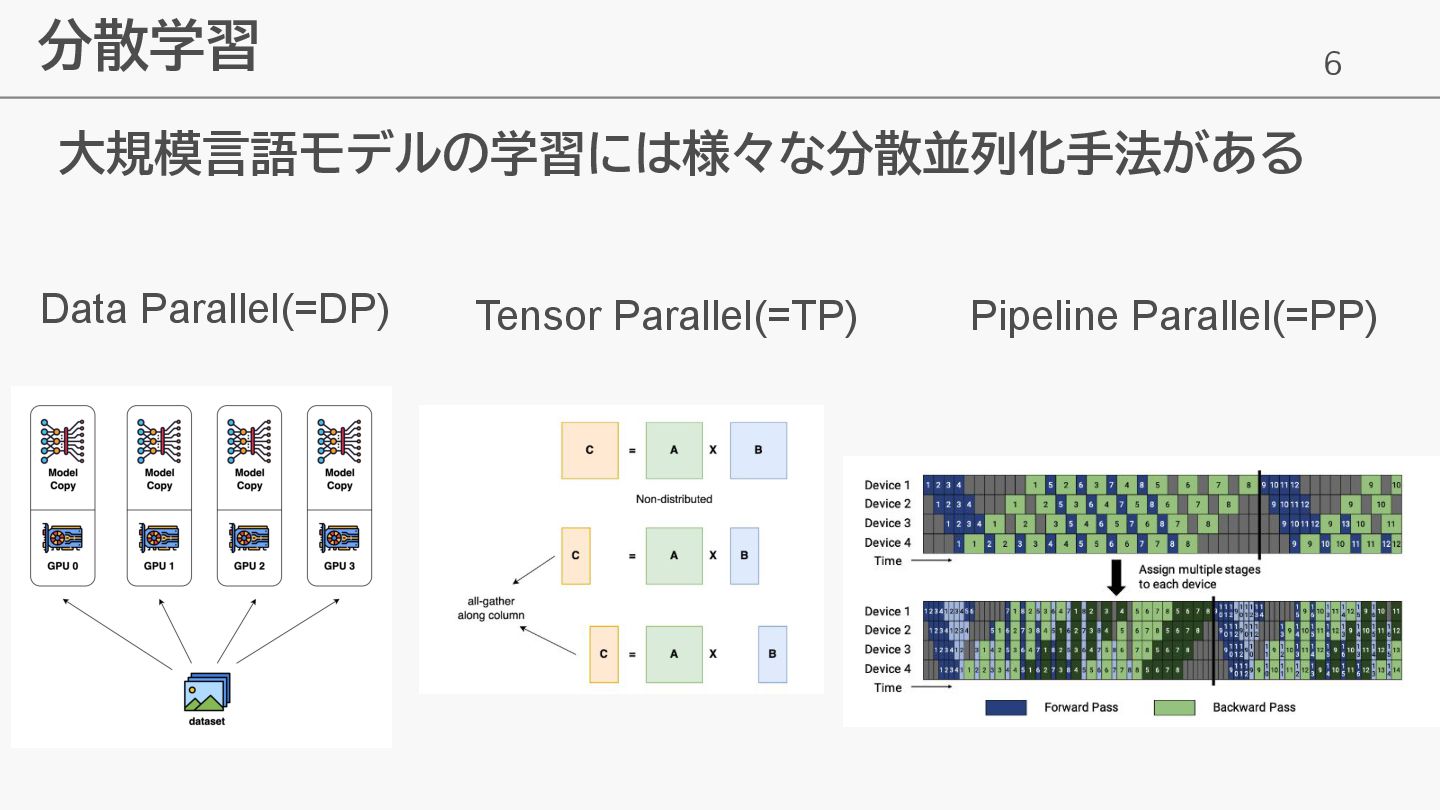
6 分散学習 大規模言語モデルの学習には様々な分散並列化手法がある Data Parallel(=DP) Tensor Parallel(=TP) Pipeline Parallel(=PP)
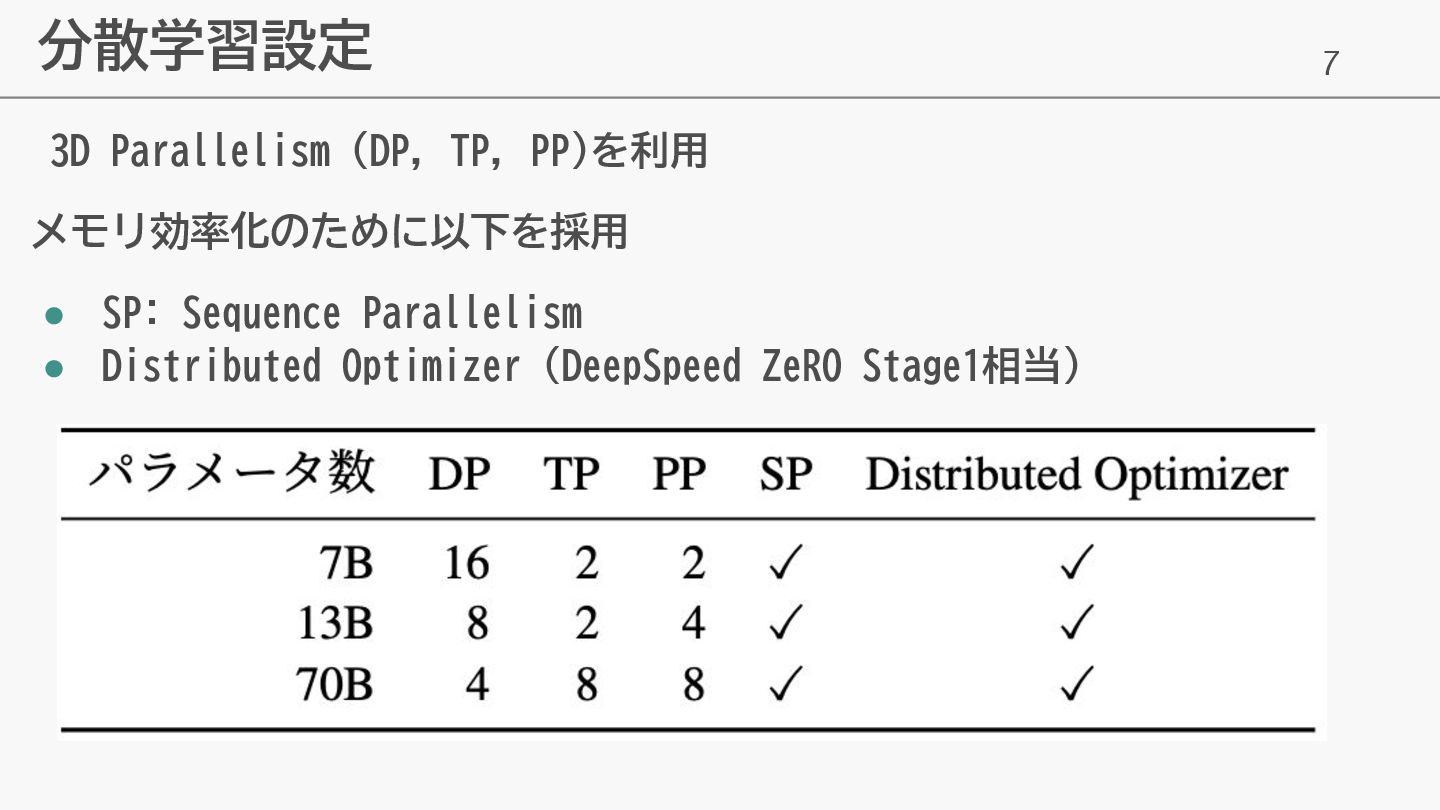
7 分散学習設定 3D Parallelism (DP, TP, PP)を利用 メモリ効率化のために以下を採用 • SP:
Sequence Parallelism • Distributed Optimizer (DeepSpeed ZeRO Stage1相当)
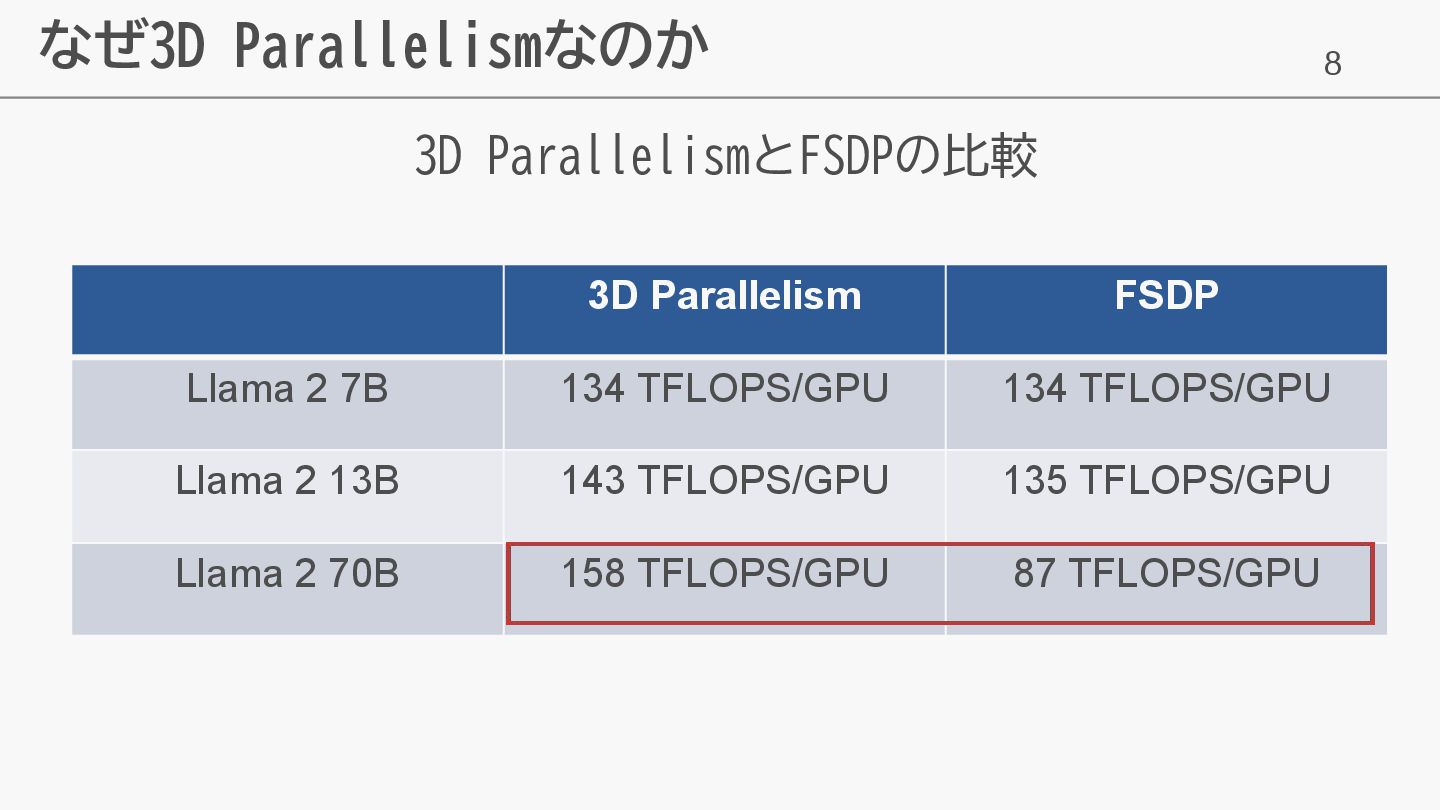
8 なぜ3D Parallelismなのか 3D ParallelismとFSDPの比較 3D Parallelism FSDP Llama 2
7B 134 TFLOPS/GPU 134 TFLOPS/GPU Llama 2 13B 143 TFLOPS/GPU 135 TFLOPS/GPU Llama 2 70B 158 TFLOPS/GPU 87 TFLOPS/GPU
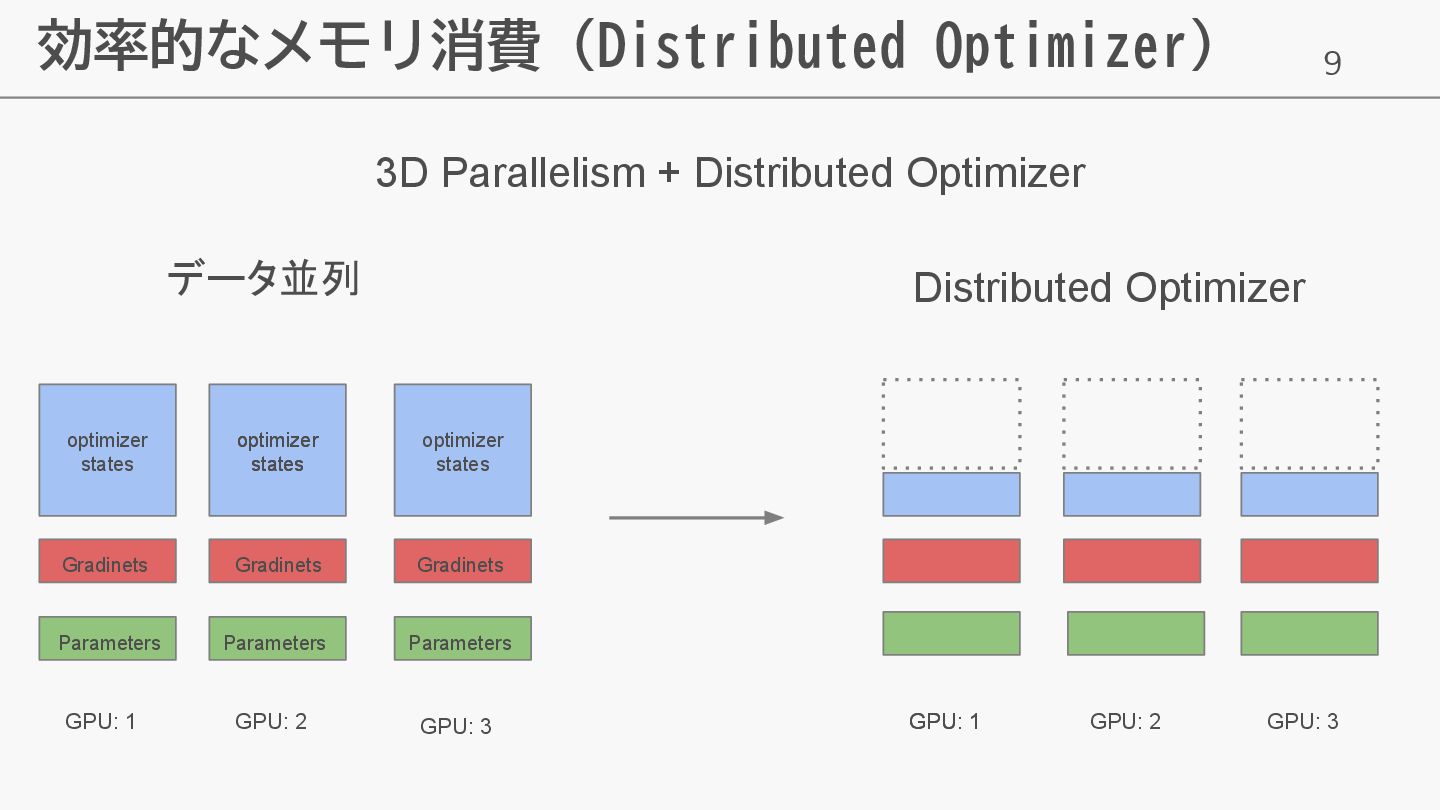
9 効率的なメモリ消費 (Distributed Optimizer) データ並列 Distributed Optimizer GPU: 1 GPU:
2 GPU: 3 GPU: 1 GPU: 1 GPU: 2 GPU: 3 3D Parallelism + Distributed Optimizer optimizer states optimizer states optimizer states Gradinets optimizer states Gradinets Gradinets Parameters Parameters Parameters
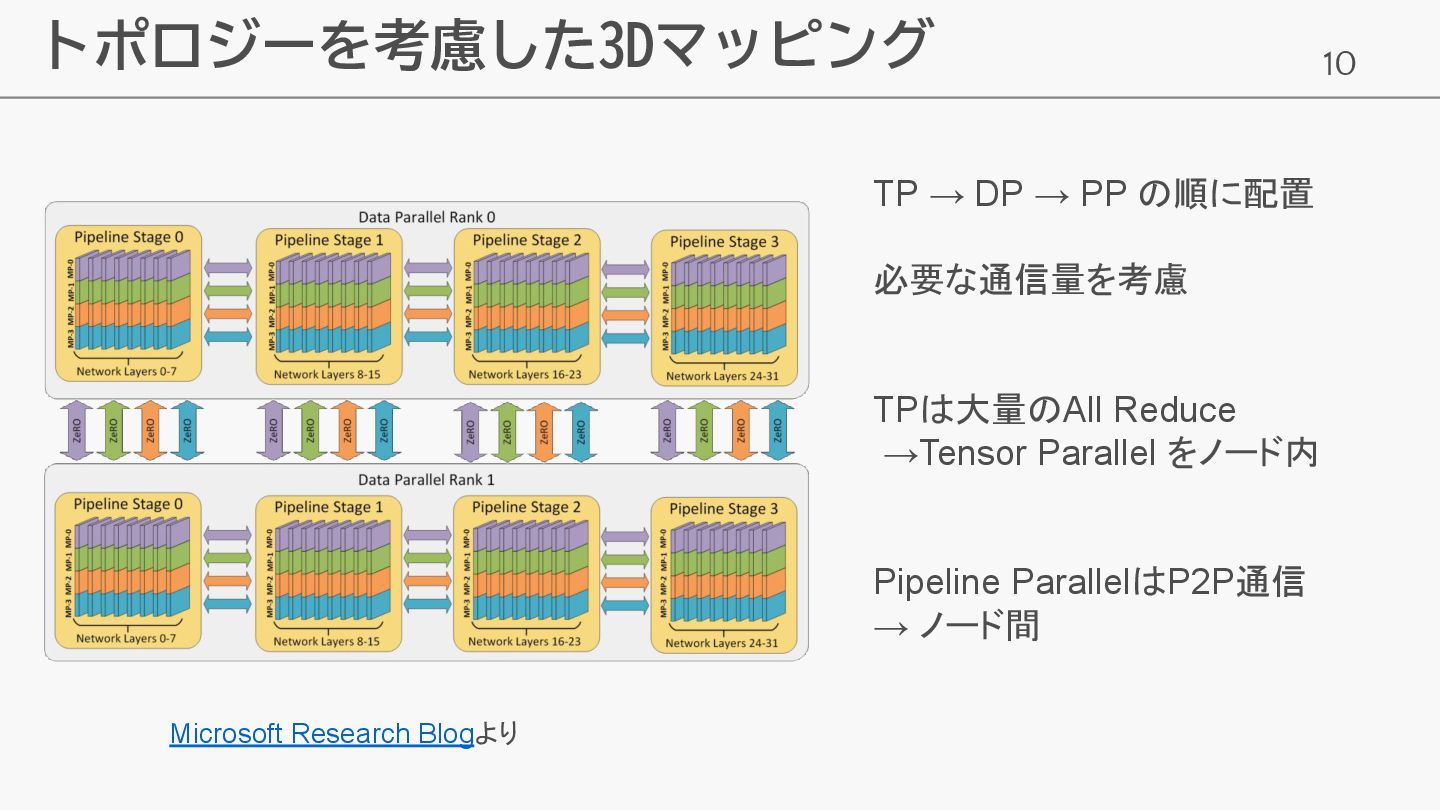
10 トポロジーを考慮した3Dマッピング TP → DP → PP の順に配置 必要な通信量を考慮 TPは大量のAll
Reduce →Tensor Parallel をノード内 Pipeline ParallelはP2P通信 → ノード間 Microsoft Research Blogより
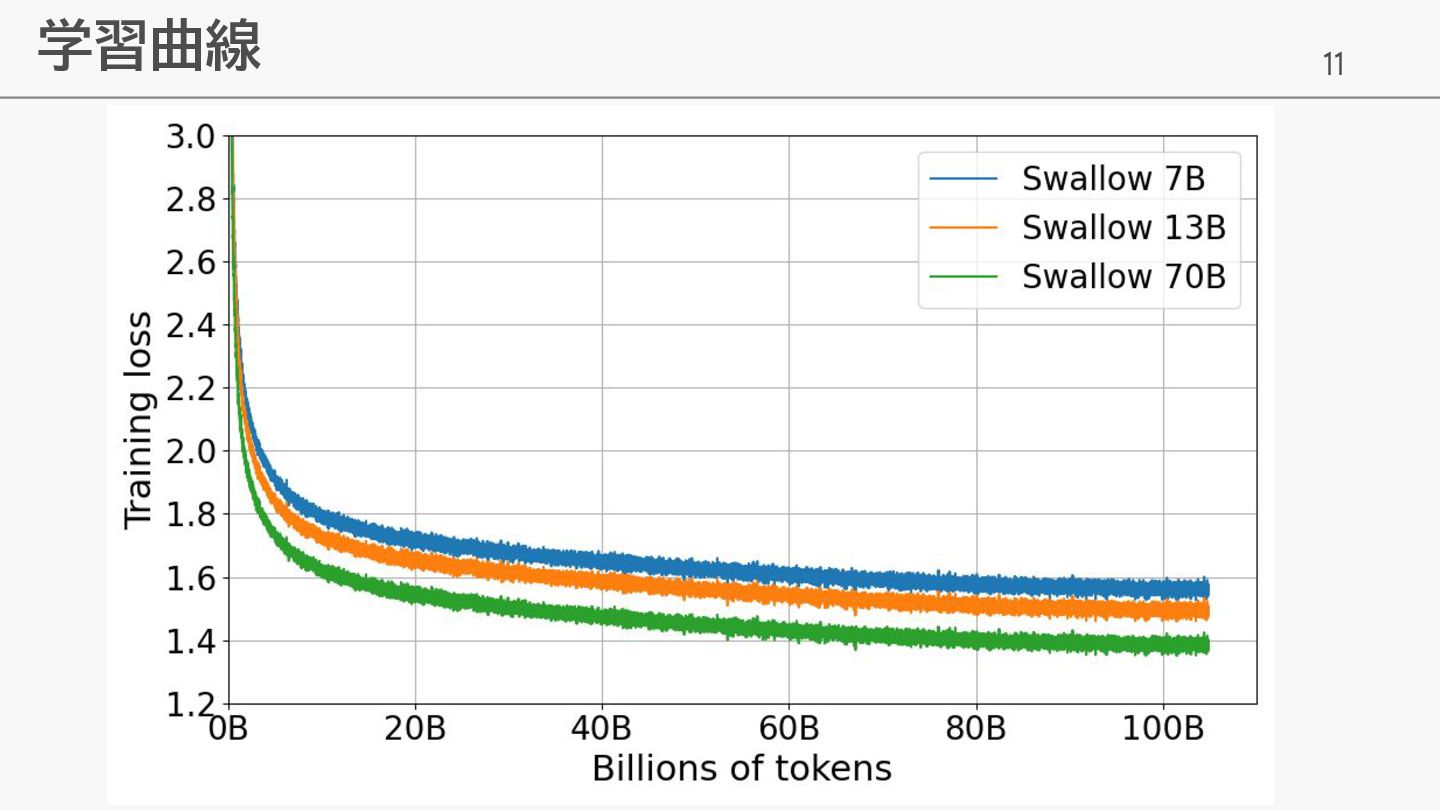
11 学習曲線
12 TFLOPS Swallow Project における TFLOPS Megatron-LM GPT-3 (175B) 51.4
% (=160TFLOPS)
補足資料
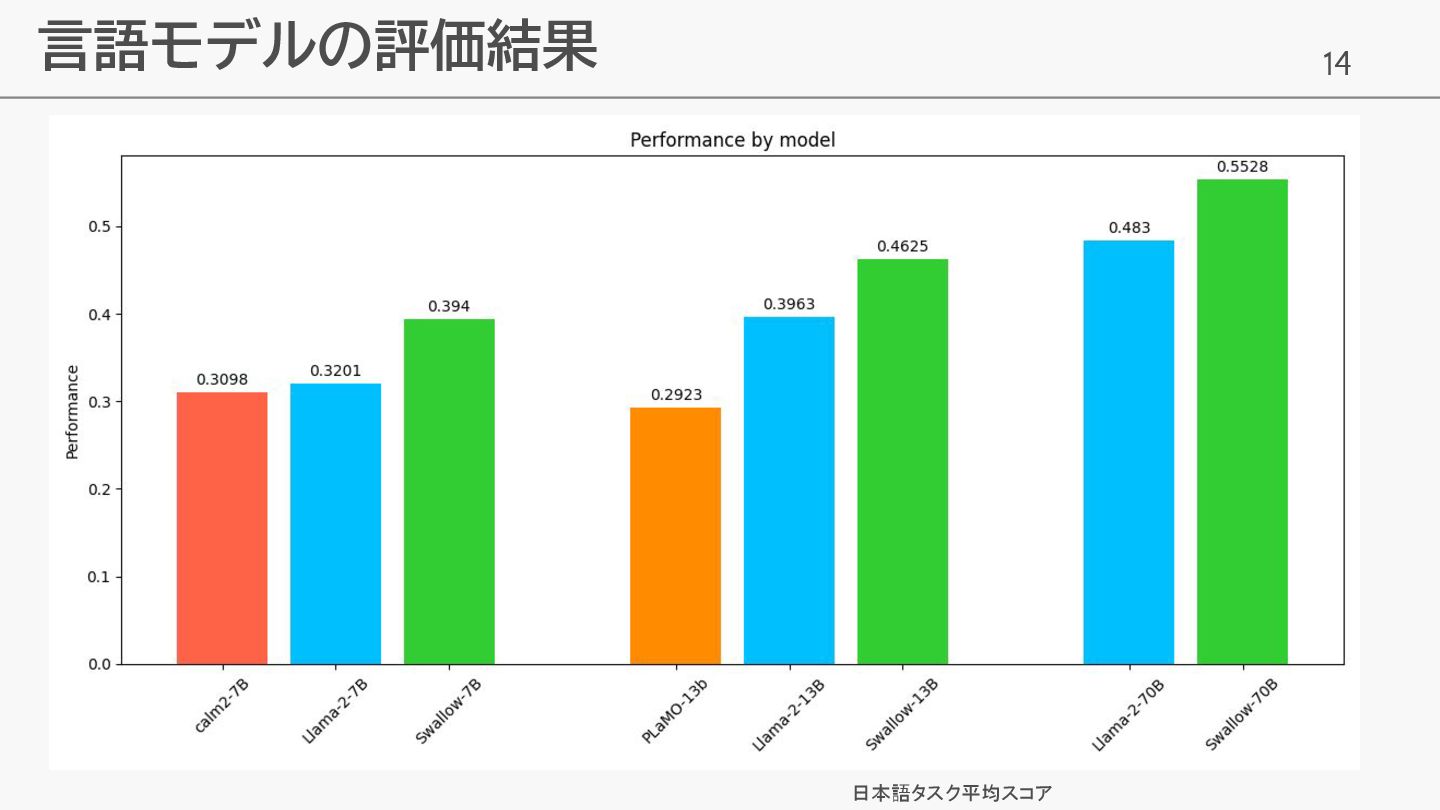
14 言語モデルの評価結果 日本語タスク平均スコア
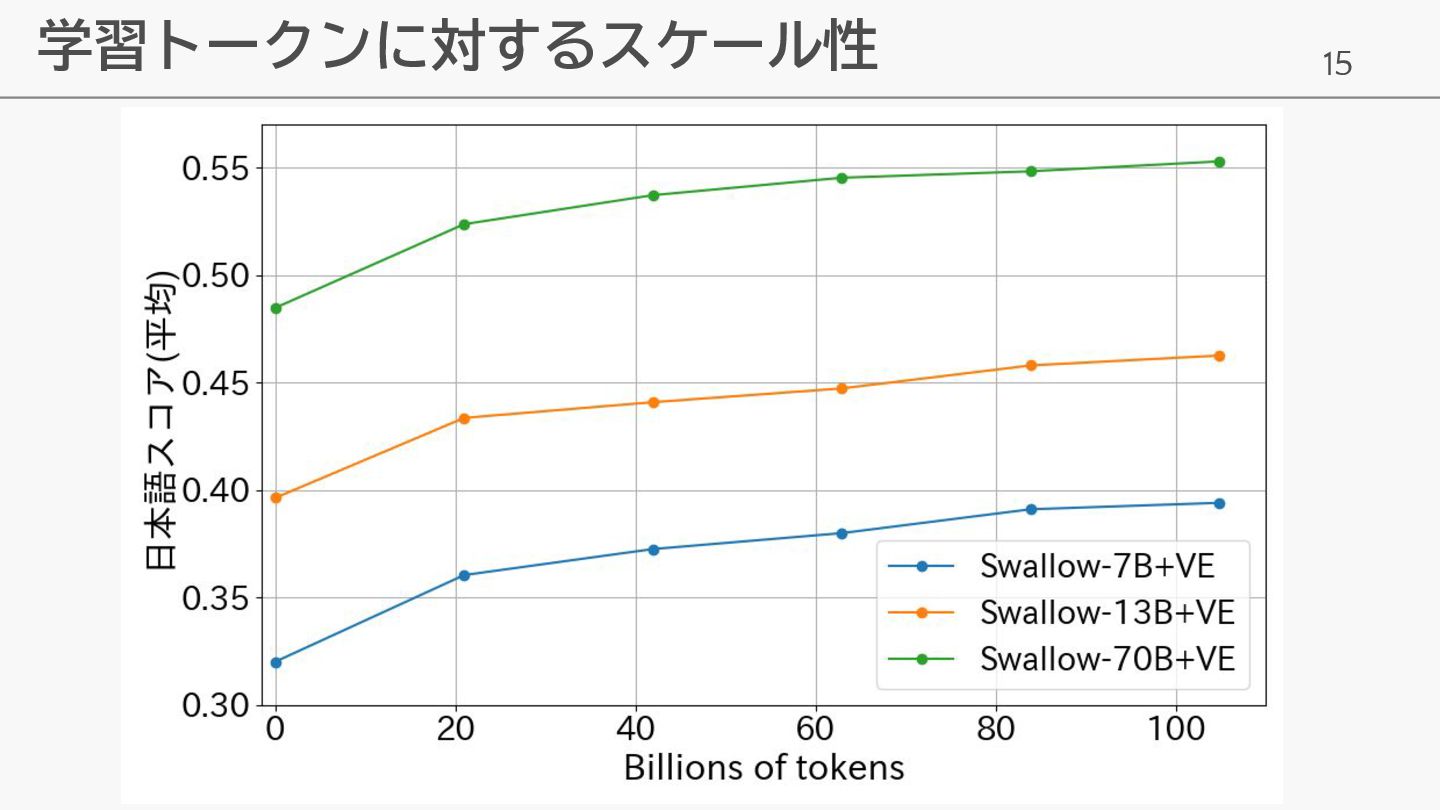
15 学習トークンに対するスケール性
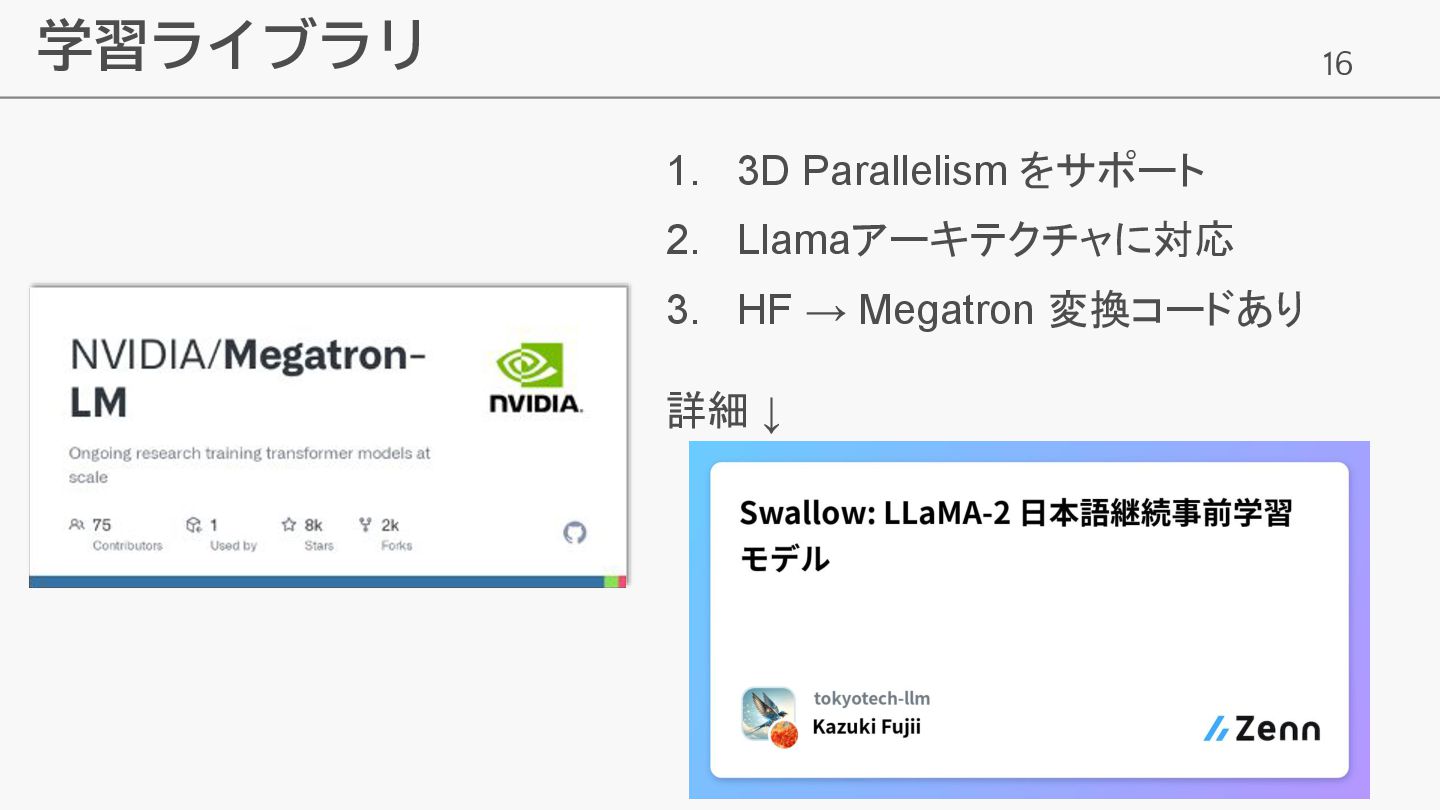
16 学習ライブラリ 1. 3D Parallelism をサポート 2. Llamaアーキテクチャに対応 3. HF
→ Megatron 変換コードあり 詳細 ↓
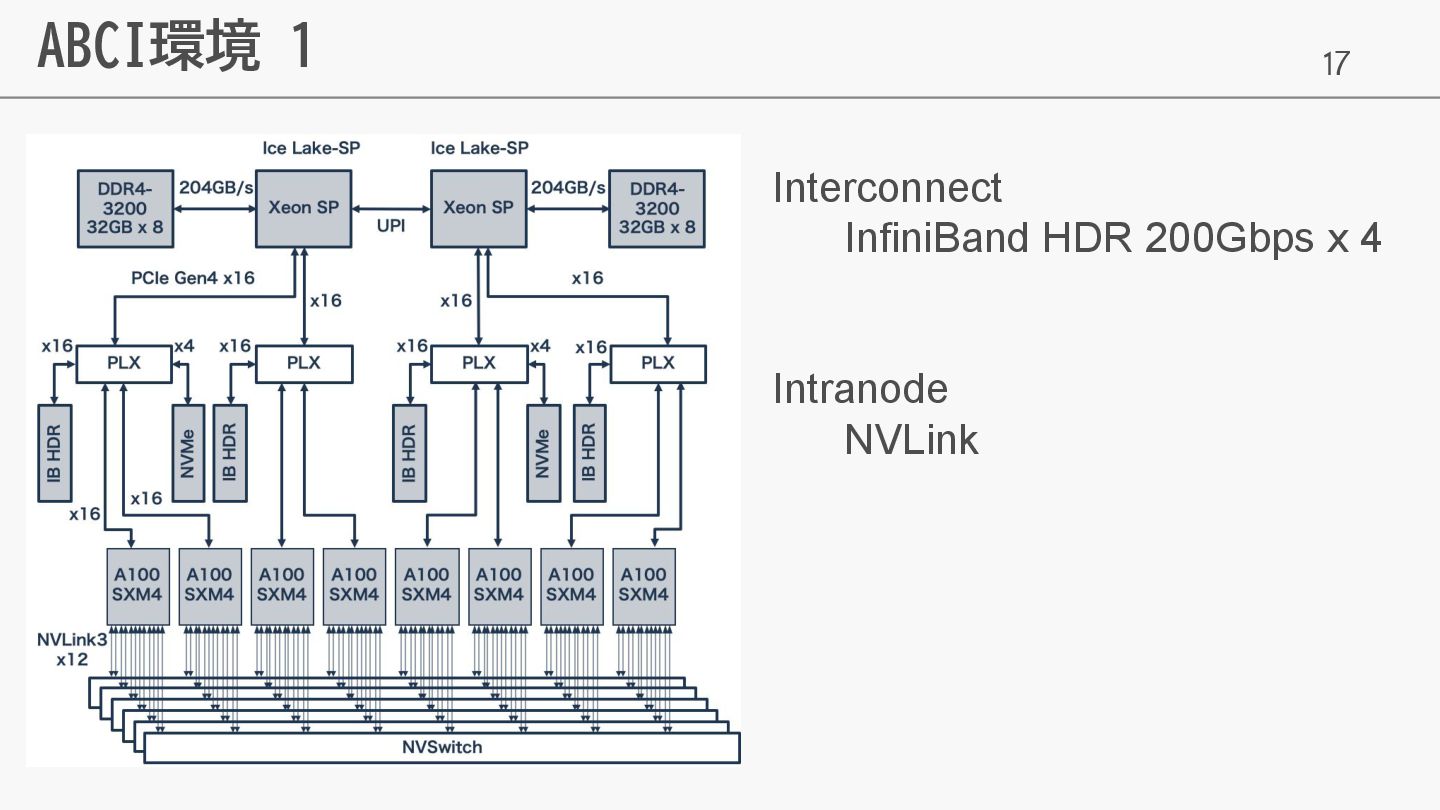
17 ABCI環境 1 Interconnect InfiniBand HDR 200Gbps x 4 Intranode
NVLink
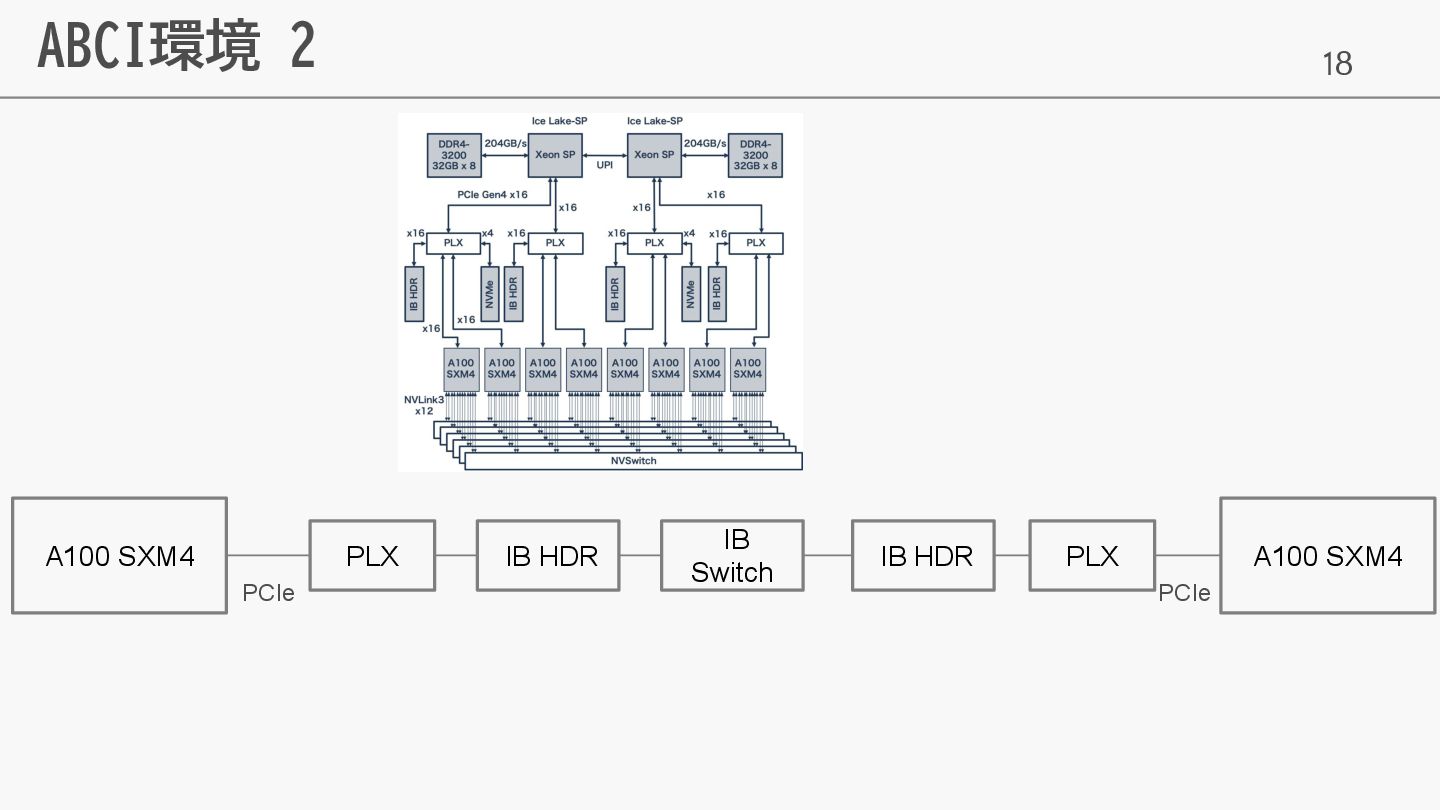
18 ABCI環境 2 A100 SXM4 PLX PCIe IB HDR PLX
A100 SXM4 IB HDR IB Switch PCIe
19 ABCI環境 3 学習に使用したAノード(A100)は フルバイセクションバンド幅のFat Tree → 通信帯域幅のボトルネックは解消されている FSDP <
3D Parallelism であることは変わりないがABCIの環境では FSDPでも致命的に遅くはならない
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}