High availability is becoming a de-facto requirement of today's applications. Customer-facing IT failures mean directly losing customer revenue and trust, as users have grown accustomed to easily switching service providers for more reliable ones. Lack of internal systems availability block employee productivity and add to the financial burden. Thus, it is critical to have a healthy, performant, resilient IT structure serving as a backbone of conducting your business. But there are no textbook solutions to achieving five 9s availability. Data redundancy, computing clusters, load balancing, fail-over mechanisms, each of these individually addresses one potential issue, but none treats systems in your organisation holistically for maximising business revenue.
Not everyone has the financial and technical ability to use the latest and greatest CDN and offload their high-availability requirements to such 3rd parties. This is where smartness comes into play, and my goal is to show you a different way of architecting an application, one that is centered around solving your own business needs without a huge additional cost. We have devised this solution while working on a very large US airline, using open-source technologies, to meed the Black Friday & Cyber Monday traffic requirements.
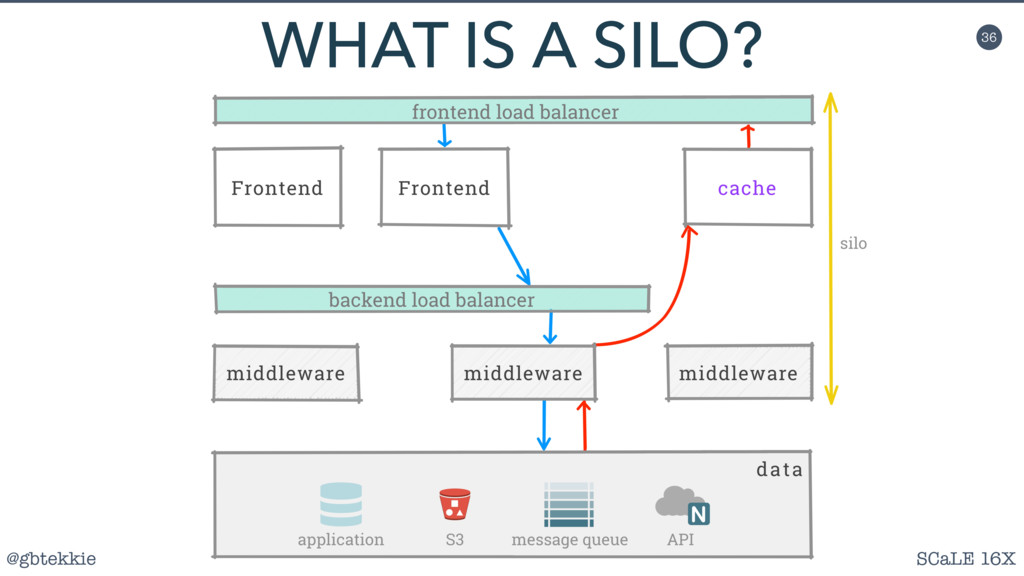
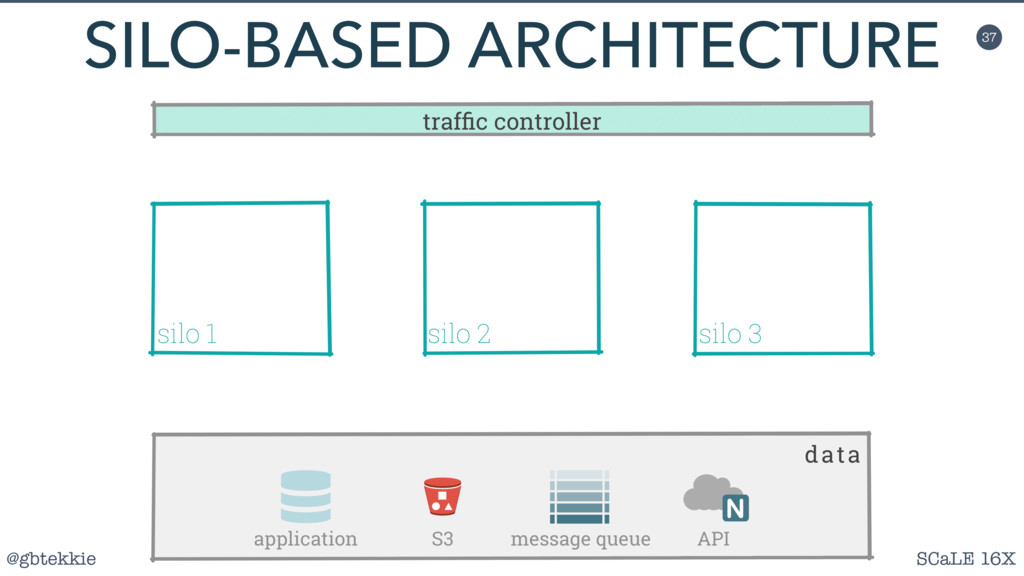
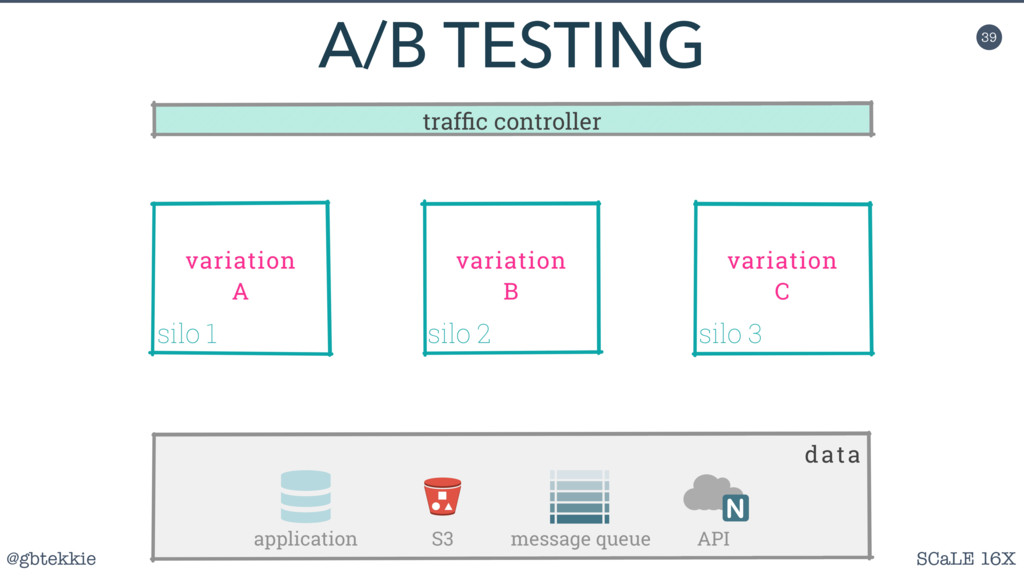
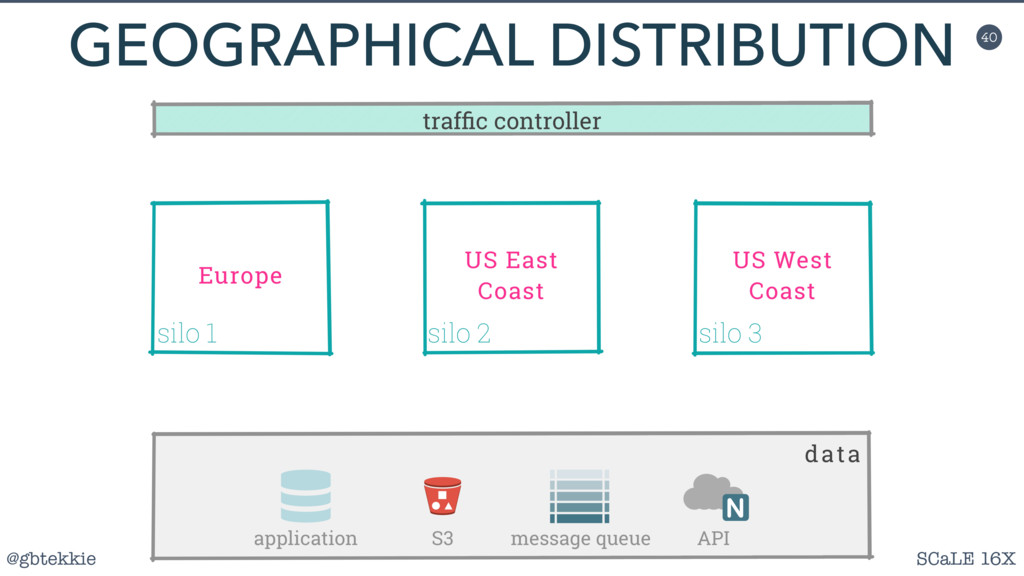
Silos are a clever method of grouping servers in such a way that they can be scaled both horizontally and vertically, depending on the actual application needs. Most importantly, it frees you from over-optimizing the architecture upfront, by allowing fine adjustments easy to integrate in your Agile workflow.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![‹#› Questions? } Efficient architecture. Performance oriented. AI enhanced. [email protected]](https://files.speakerdeck.com/presentations/cb91bd9c74b64c67aa38fc676dfdb9d6/slide_46.jpg){kind=link}