⊂ X that provide a minimal loss with a classifier C(X, y, F ). Typically provide a smaller loss on a data sets then embedded and filter-based feature selection methods. F may vary depending on the choice of the classifier. examples: SVM-RFE, distributed wrapper, small loss + high complexity Embedded Methods Optimize the parameters of the classifier and the feature selection at the same time. θ∗ = arg min θ∈Θ {E[ (θ, D)] + Ω(θ)} = arg min θ∈Θ y − XTθ 2 2 + λ θ 1 examples: LASSO, Elastic-net, streamwise feature selection, online feature selection Filter Methods Find a subset of features F ⊂ X that maximize a function J(X) that is not tied to classification loss (classifier independent). Generally faster than wrapper and embedded methods, but we cannot assume F will produce minimal loss. examples: RELIEF, mRMR, Cond. likelihood maximization, submodular Big Feature Subset Selection (Extensions for Neyman-Pearson Feature Selection) Ditzler, Austen, Rosen & Polikar (CIDM 2014)
be selected for any arbitrary filter function J(X), and what about noisy data? What if there are a massive number of observations? Wrappers and embedded methods tie themselves to classifiers, which can make them overly complex and prone to overfitting. Not too many of those popular feature selection tools are built for massive data. Proposed Solution (Neyman-Pearson Feature Selection – NPFS) NPFS was designed to scale a generic filter subset selection algorithm to large data, while: detecting with relevant set size from an initial condition independent of what a user feels is “relevant” working with the decisions of a base-selection algorithm Scalability is important and NPFS models parallelism from a programatic perceptive Nicely fits into a MapReduce approach to parallelism How many parallel tasks does NPFS allow? How many slots are available? Concept: generate bootstrap data sets, perform feature selection, then reduce importance detections to a Neyman-Pearson hypothesis test Big Feature Subset Selection (Extensions for Neyman-Pearson Feature Selection) Ditzler, Austen, Rosen & Polikar (CIDM 2014)
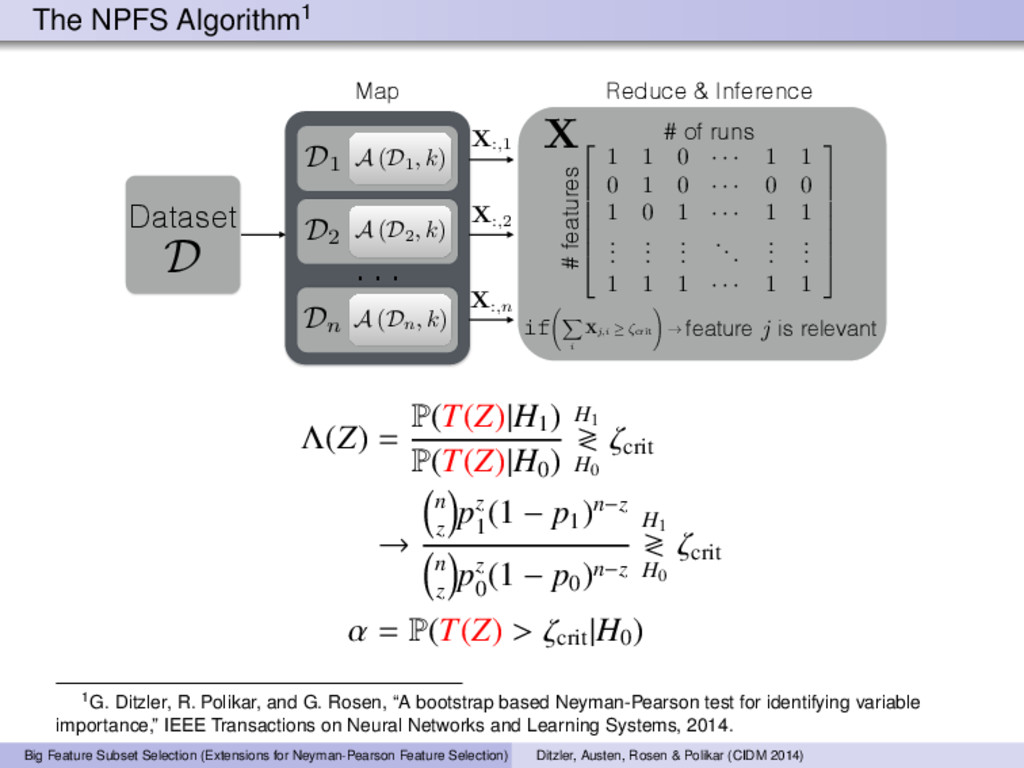
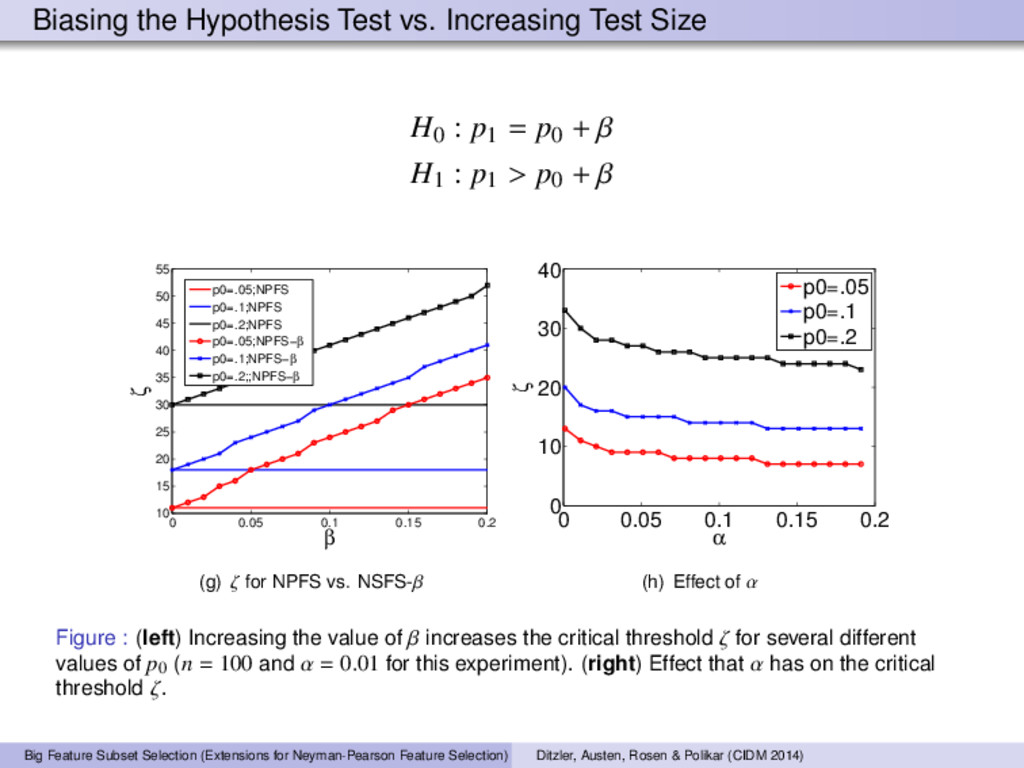
algorithm A on n independently sampled data sets. Form a matrix X ∈ {0, 1}K×n where {X}il is the Bernoulli random variable for feature i on trial l. 2 Compute ζ crit using equation (1), which requires n, p0, and the Binomial inverse cumulative distribution function. P(z > ζ crit |H0) = 1 − P(z ≤ ζ crit |H0) cumulative distribution function = α (1) 3 Let {z}i = n l=1 {X}il. If {z}i > ζ crit then feature belongs in the relevant set, otherwise the feature is deemed non-relevant. Concentration Inequality on |ˆ p − p| (Hoeffding’s bound) If X1, . . . , Xn ∼ Bernoulli(p), then for any > 0, we have P(|ˆ p − p| ≥ ) ≤ 2e−2n 2 where ˆ p = 1 n Zn. 2Matlab code is available. http://github.com/gditzler/NPFS. Big Feature Subset Selection (Extensions for Neyman-Pearson Feature Selection) Ditzler, Austen, Rosen & Polikar (CIDM 2014)
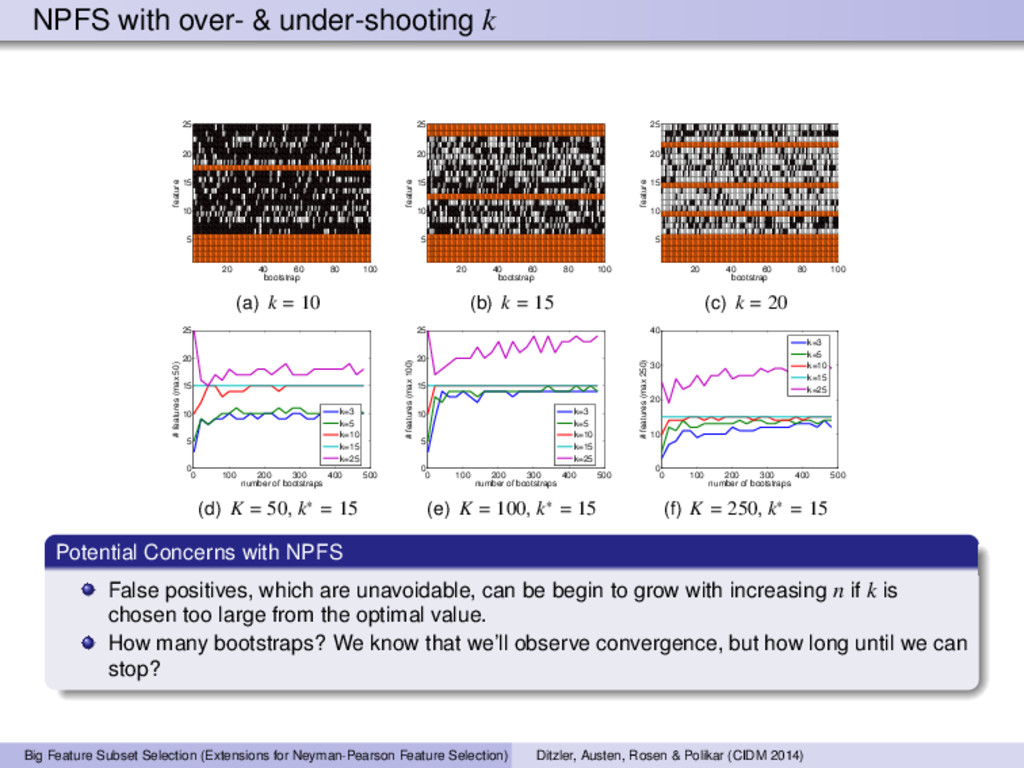
100 5 10 15 20 25 bootstrap feature (a) k = 10 20 40 60 80 100 5 10 15 20 25 bootstrap feature (b) k = 15 20 40 60 80 100 5 10 15 20 25 bootstrap feature (c) k = 20 0 100 200 300 400 500 0 5 10 15 20 25 number of bootstraps # features (max 50) k=3 k=5 k=10 k=15 k=25 (d) K = 50, k∗ = 15 0 100 200 300 400 500 0 5 10 15 20 25 number of bootstraps # features (max 100) k=3 k=5 k=10 k=15 k=25 (e) K = 100, k∗ = 15 0 100 200 300 400 500 0 10 20 30 40 number of bootstraps # features (max 250) k=3 k=5 k=10 k=15 k=25 (f) K = 250, k∗ = 15 Potential Concerns with NPFS False positives, which are unavoidable, can be begin to grow with increasing n if k is chosen too large from the optimal value. How many bootstraps? We know that we’ll observe convergence, but how long until we can stop? Big Feature Subset Selection (Extensions for Neyman-Pearson Feature Selection) Ditzler, Austen, Rosen & Polikar (CIDM 2014)
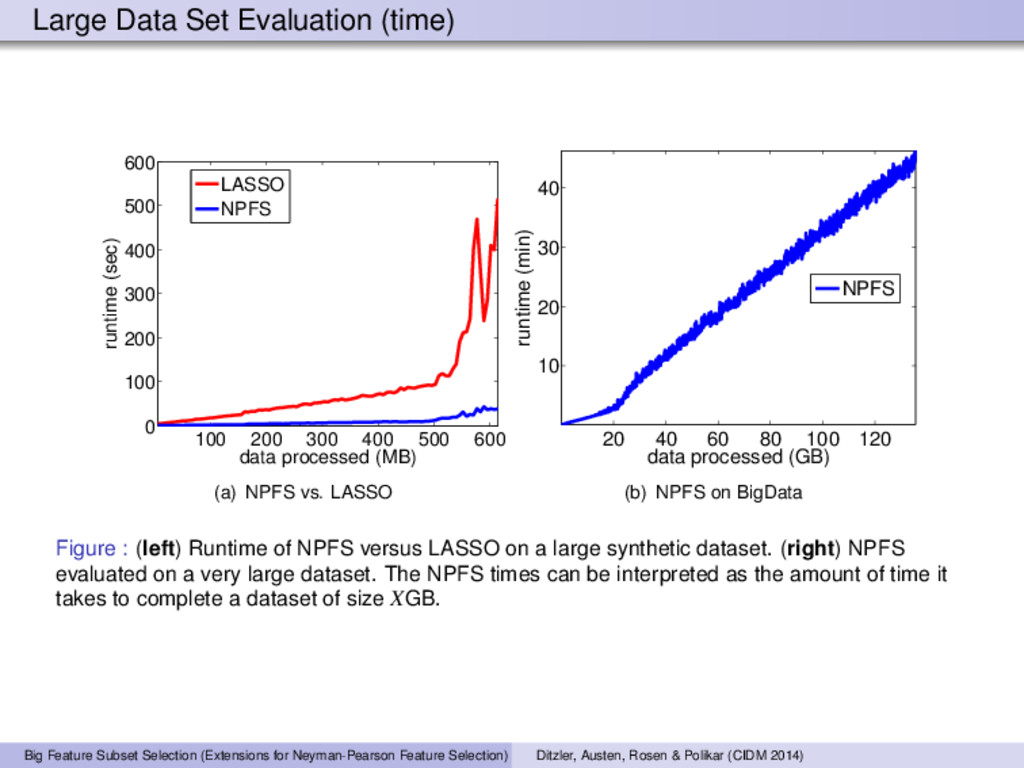
600 0 100 200 300 400 500 600 data processed (MB) runtime (sec) LASSO NPFS (a) NPFS vs. LASSO 20 40 60 80 100 120 10 20 30 40 data processed (GB) runtime (min) NPFS (b) NPFS on BigData Figure : (left) Runtime of NPFS versus LASSO on a large synthetic dataset. (right) NPFS evaluated on a very large dataset. The NPFS times can be interpreted as the amount of time it takes to complete a dataset of size XGB. Big Feature Subset Selection (Extensions for Neyman-Pearson Feature Selection) Ditzler, Austen, Rosen & Polikar (CIDM 2014)
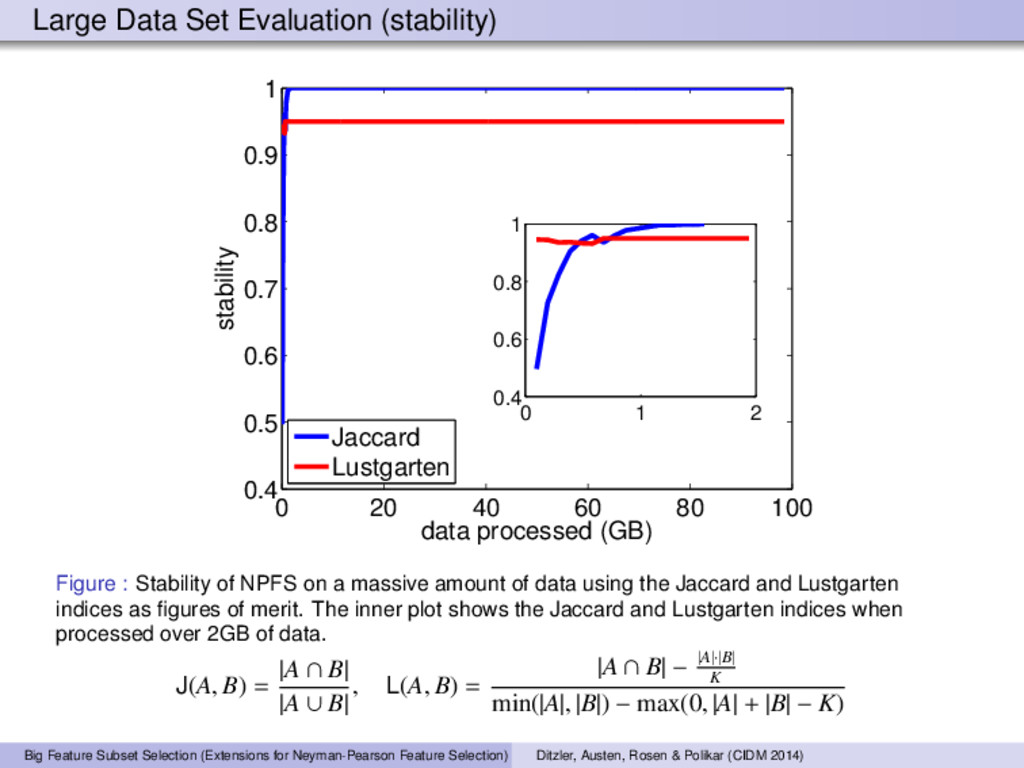
100 0.4 0.5 0.6 0.7 0.8 0.9 1 data processed (GB) stability Jaccard Lustgarten 0 1 2 0.4 0.6 0.8 1 Figure : Stability of NPFS on a massive amount of data using the Jaccard and Lustgarten indices as figures of merit. The inner plot shows the Jaccard and Lustgarten indices when processed over 2GB of data. J(A, B) = |A ∩ B| |A ∪ B| , L(A, B) = |A ∩ B| − |A|·|B| K min(|A|, |B|) − max(0, |A| + |B| − K) Big Feature Subset Selection (Extensions for Neyman-Pearson Feature Selection) Ditzler, Austen, Rosen & Polikar (CIDM 2014)
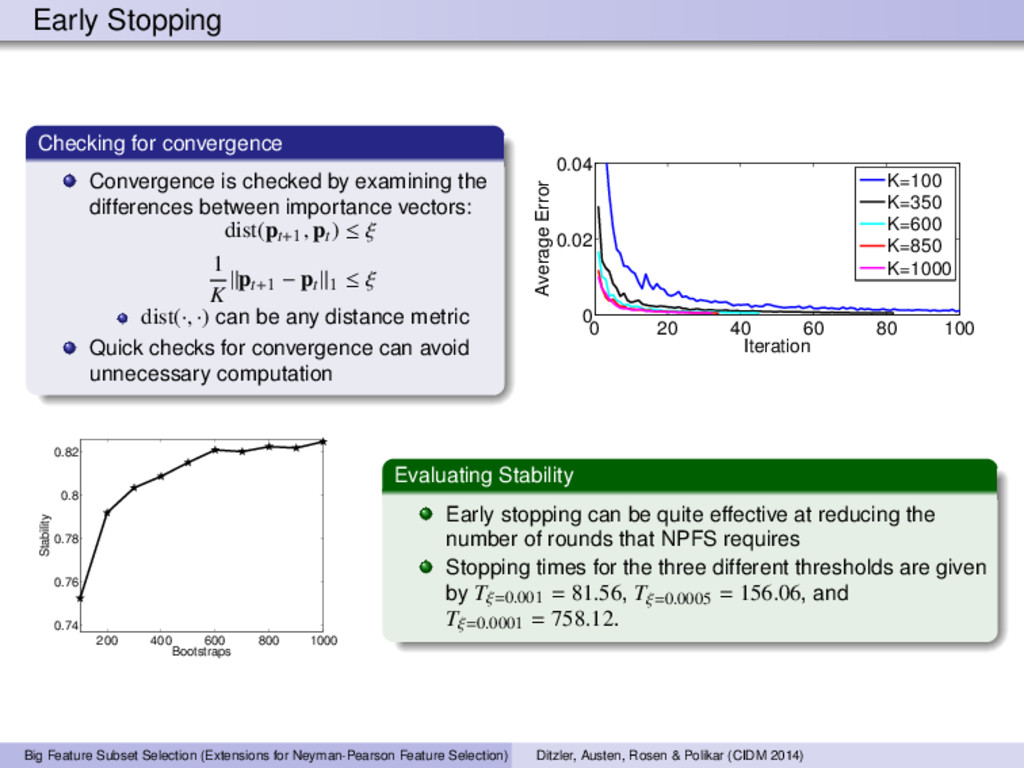
the differences between importance vectors: dist(pt+1 , pt) ≤ ξ 1 K pt+1 − pt 1 ≤ ξ dist(·, ·) can be any distance metric Quick checks for convergence can avoid unnecessary computation 0 20 40 60 80 100 0 0.02 0.04 Iteration Average Error K=100 K=350 K=600 K=850 K=1000 200 400 600 800 1000 0.74 0.76 0.78 0.8 0.82 Bootstraps Stability Evaluating Stability Early stopping can be quite effective at reducing the number of rounds that NPFS requires Stopping times for the three different thresholds are given by Tξ=0.001 = 81.56, Tξ=0.0005 = 156.06, and Tξ=0.0001 = 758.12. Big Feature Subset Selection (Extensions for Neyman-Pearson Feature Selection) Ditzler, Austen, Rosen & Polikar (CIDM 2014)
were proposed to reduce the risk of over-shooting the optimal feature set size and quickly determine when stop running NPFS. Scalability on large data was demonstrated using the massively parallelizable framework of NPFS. (Thank You) Future Work: Large-Scale Feature Selection with Missing Data Big+Heterogenous data sources are being increasingly more abundant and many values are typically missing Developing a theoretical & scaleable approach to performing feature selection without interpolating missing values Big Feature Subset Selection (Extensions for Neyman-Pearson Feature Selection) Ditzler, Austen, Rosen & Polikar (CIDM 2014)
Award #1310496. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation. Big Feature Subset Selection (Extensions for Neyman-Pearson Feature Selection) Ditzler, Austen, Rosen & Polikar (CIDM 2014)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}