Algebra @ Technical University of Denmark Kazu Ghalamkari Current and Future Computational Approaches to Quantum Many-Body Systems 2026 (CompQMB2026), Okinawa, 5 Mar. 2026 @KazuGhalamkari Accepted in AISTATS 2026
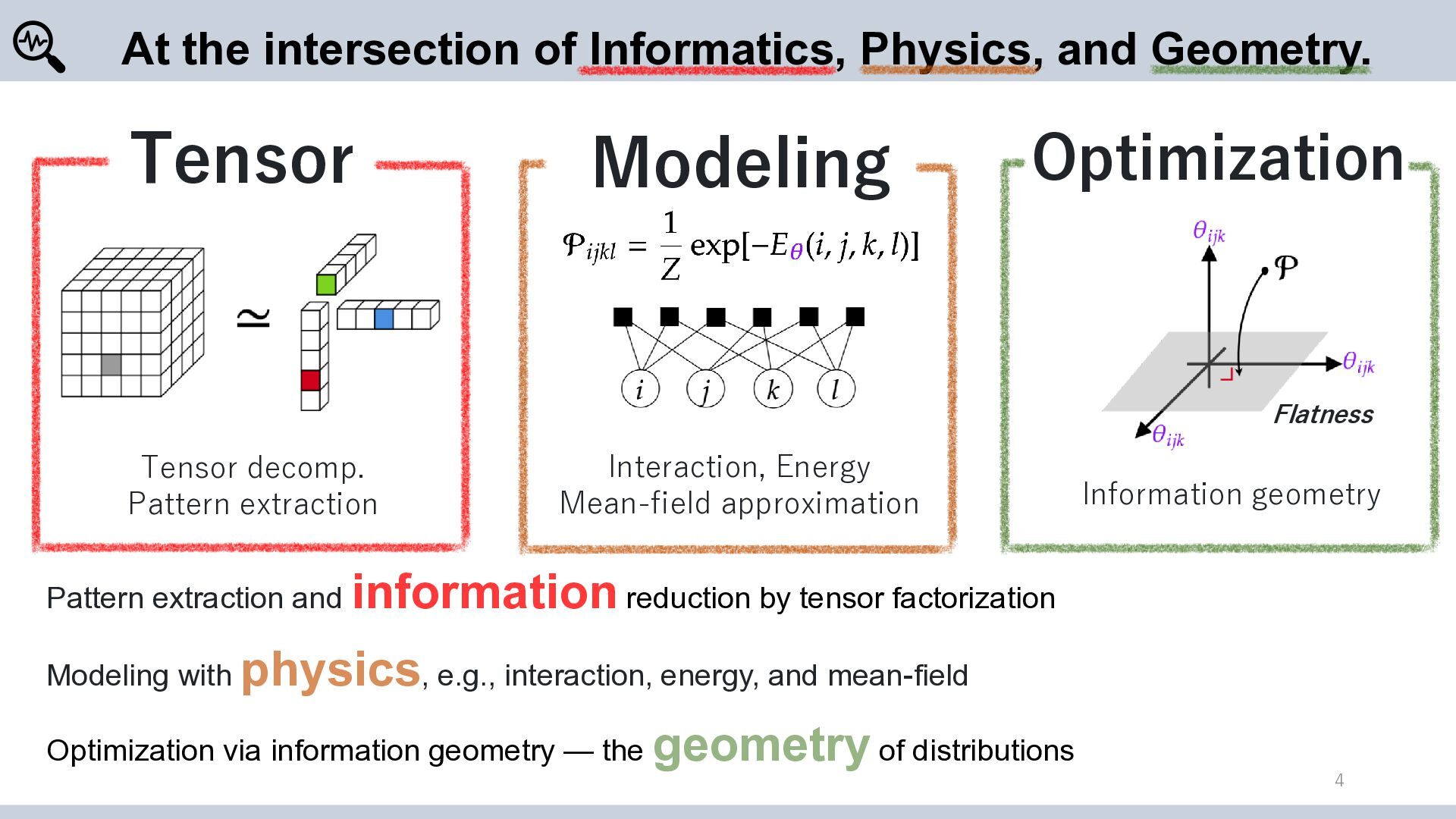
Modeling Optimization Information geometry At the intersection of Informatics, Physics, and Geometry. Pattern extraction and information reduction by tensor factorization Modeling with physics, e.g., interaction, energy, and mean-field Optimization via information geometry — the geometry of distributions Flatness
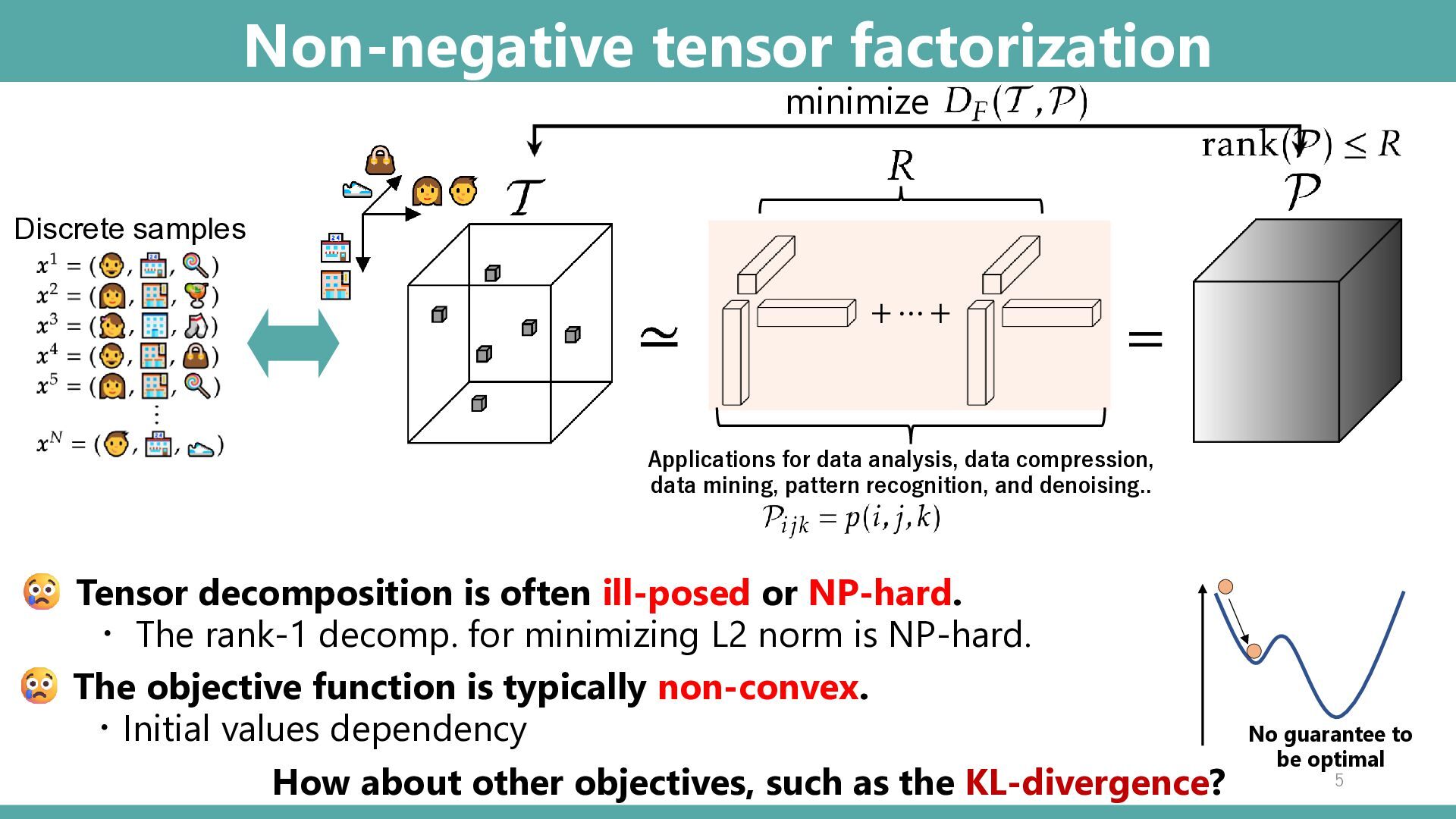
and denoising.. Non-negative tensor factorization 5 = minimize + ⋯ + Discrete samples How about other objectives, such as the KL-divergence? Tensor decomposition is often ill-posed or NP-hard. ・ The rank-1 decomp. for minimizing L2 norm is NP-hard. The objective function is typically non-convex. ・Initial values dependency No guarantee to be optimal
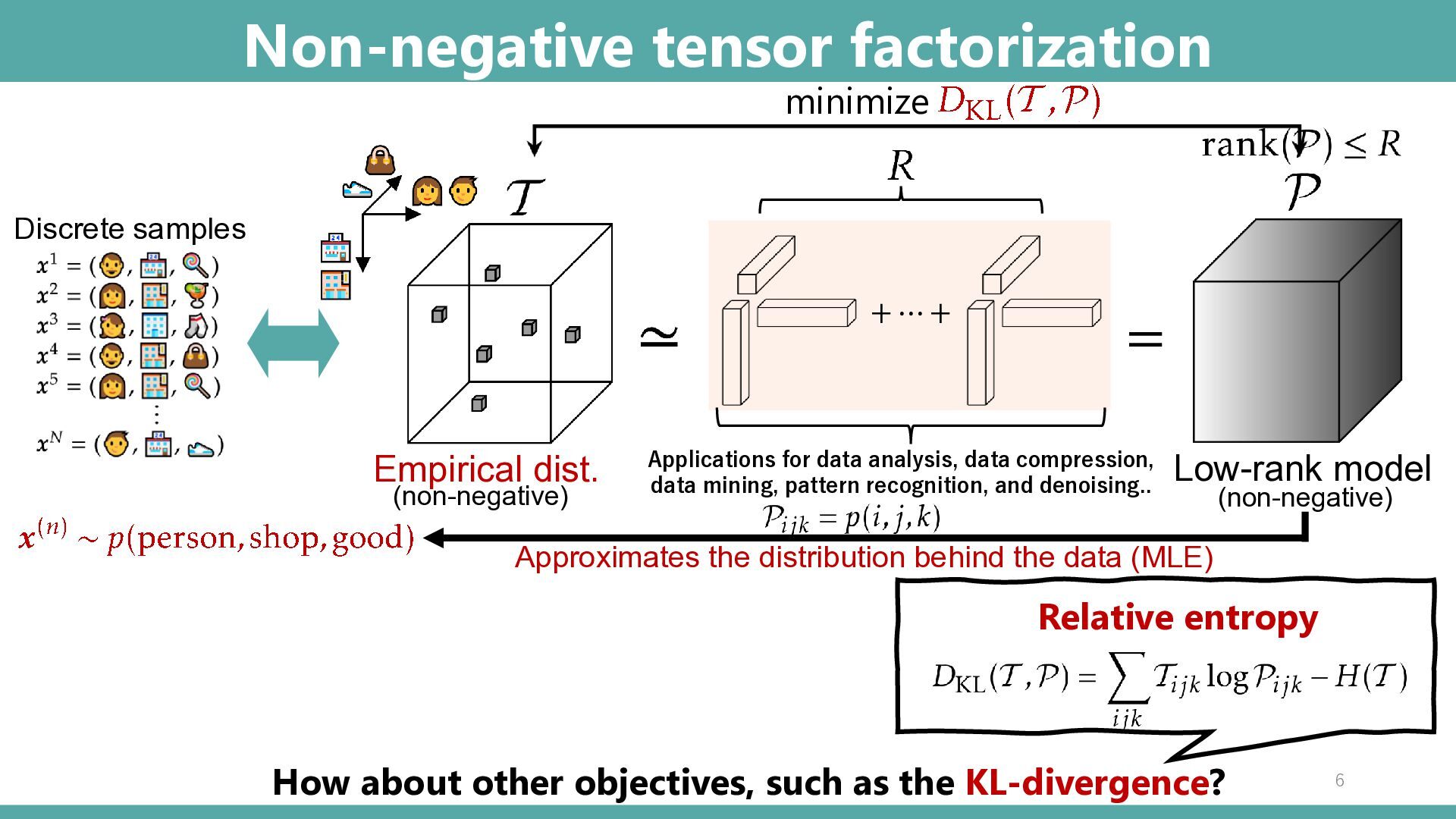
and denoising.. Non-negative tensor factorization 6 = minimize + ⋯ + Discrete samples Low-rank model Empirical dist. How about other objectives, such as the KL-divergence? Approximates the distribution behind the data (MLE) (non-negative) (non-negative) Relative entropy
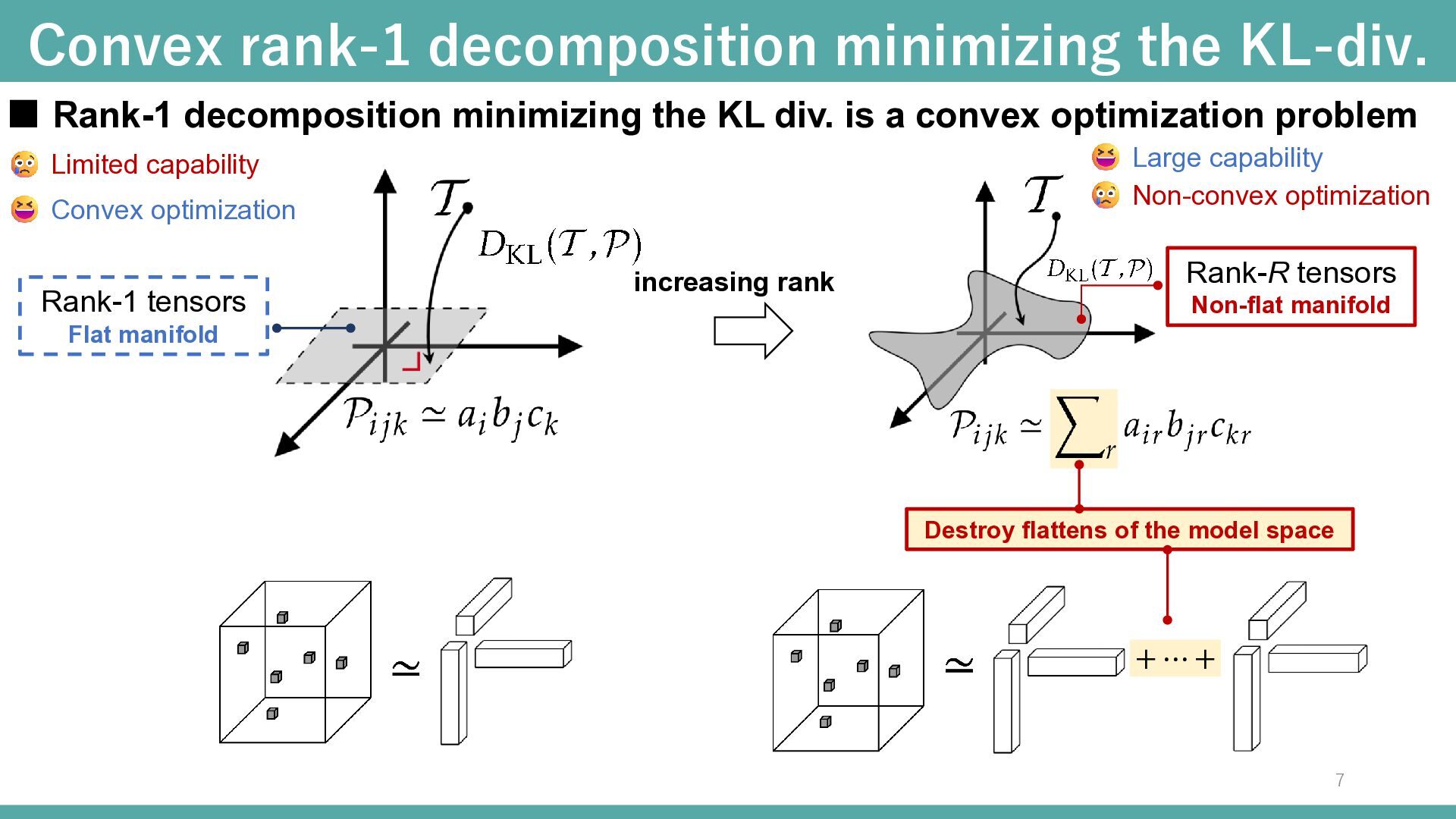
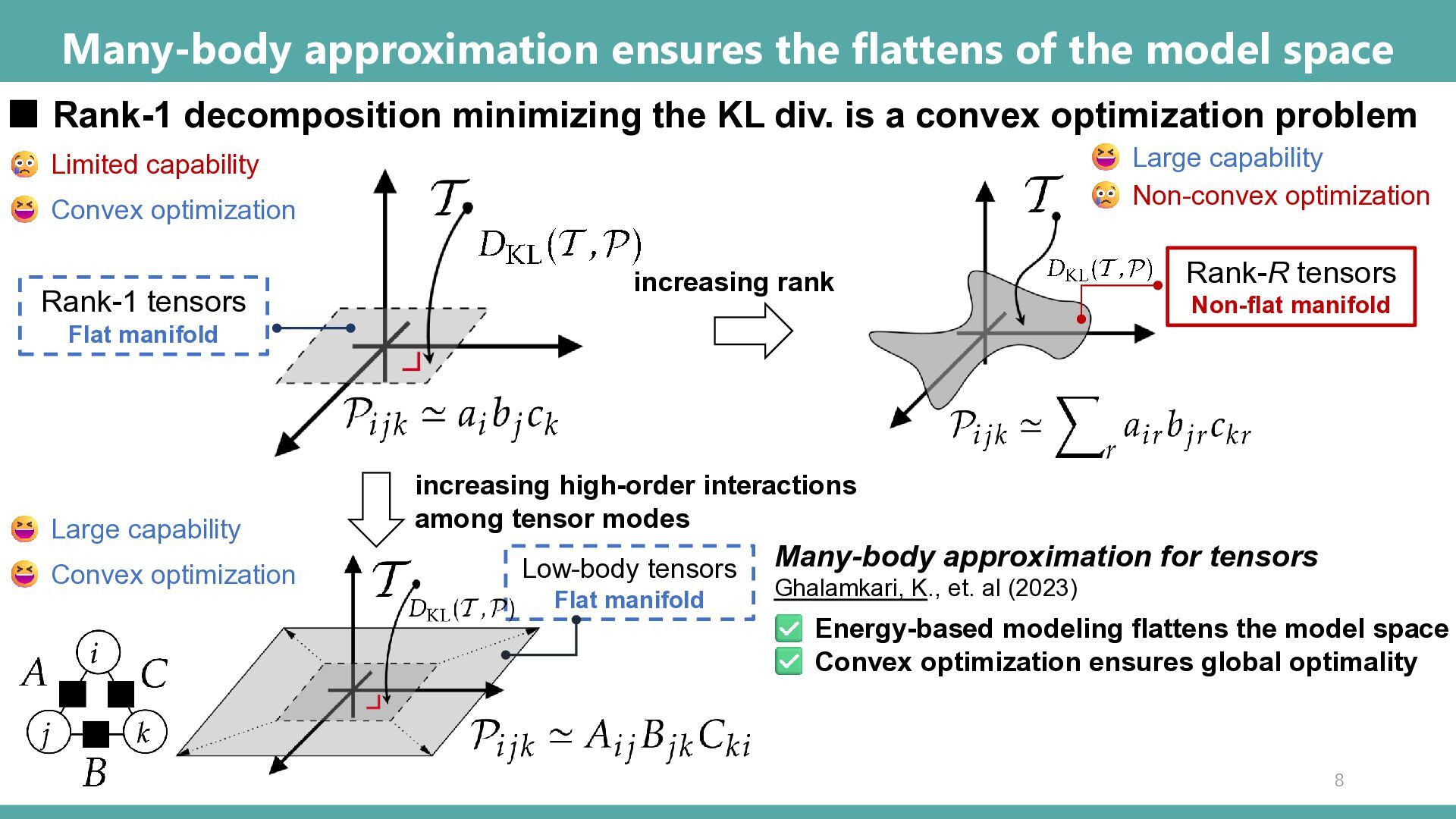
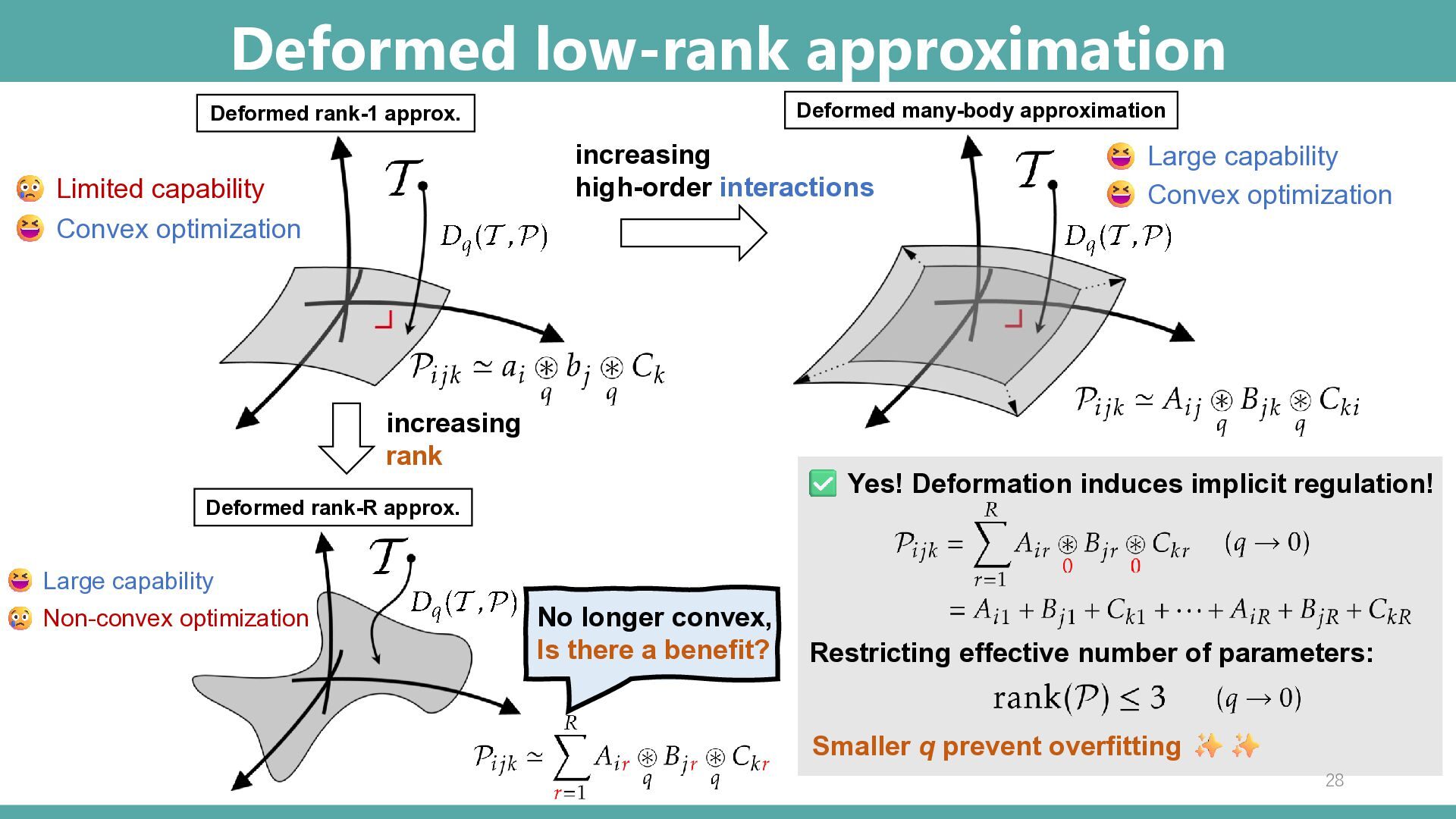
▪ Rank-1 decomposition minimizing the KL div. is a convex optimization problem Limited capability Convex optimization Large capability Non-convex optimization increasing rank Rank-R tensors Non-flat manifold + ⋯ + Destroy flattens of the model space 7
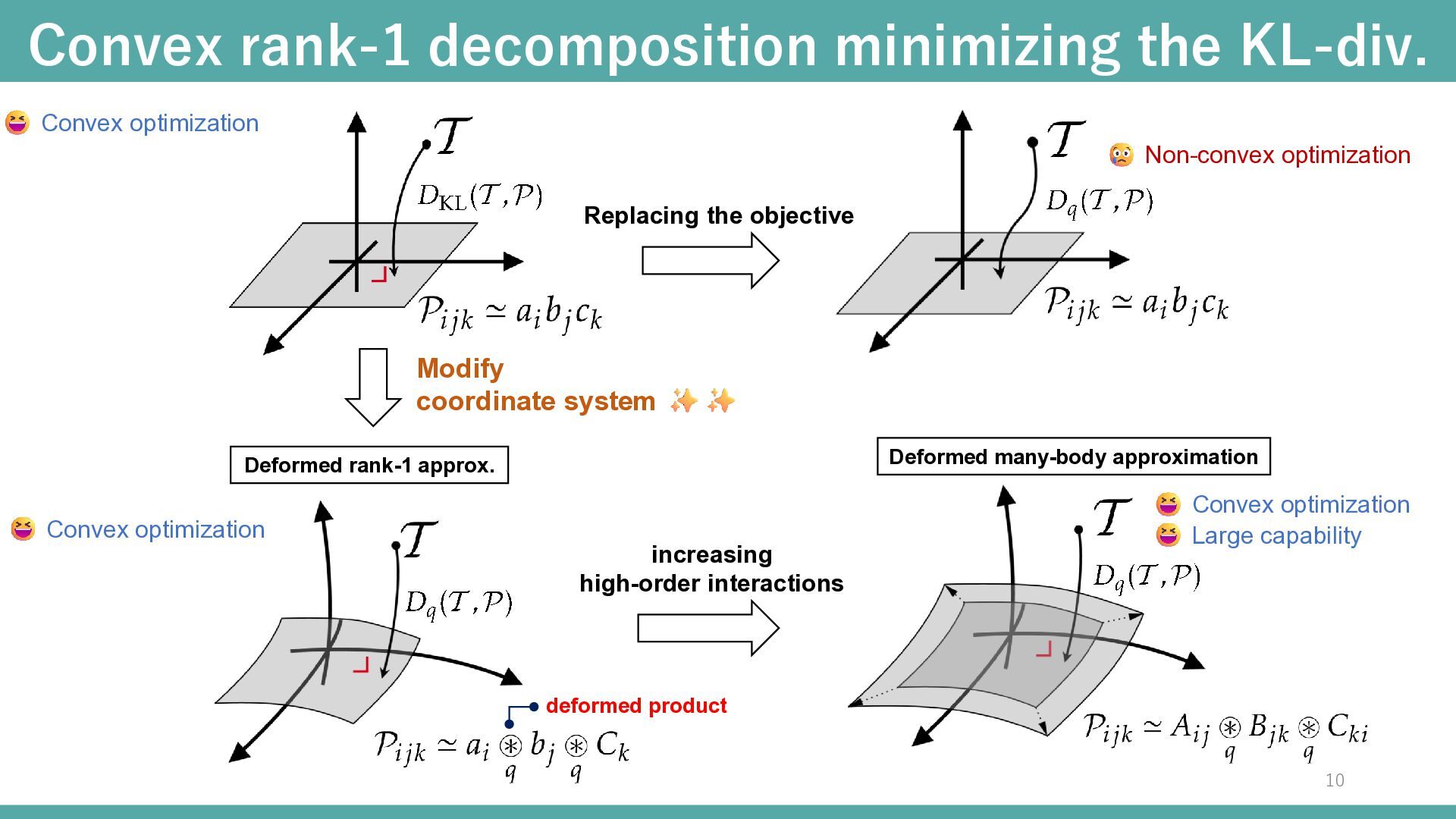
tensors Flat manifold ▪ Rank-1 decomposition minimizing the KL div. is a convex optimization problem Limited capability Convex optimization Large capability Non-convex optimization increasing rank increasing high-order interactions among tensor modes Large capability Convex optimization Low-body tensors Flat manifold Rank-R tensors Non-flat manifold Energy-based modeling flattens the model space Convex optimization ensures global optimality Many-body approximation for tensors Ghalamkari, K., et. al (2023) 8
a large penalty if and , which induces overfitting to noise. noise Good fitting ignores noise Overfit to noise due to the nature of the KL-divergence. Large penalty for KL noise Alternative divergences, such as q-divergence, reduce this weakness. KL-divergence Data Model q-divergence Hyper-parameter (q>0) Fitting with q=1.0 Fitting with q=0.5 Fitting with q=0.1
approximation for non-negative tensors Natural parameter of deformed exponential family. Energy function Free energy Examples: Temperature parameter ❖ Tsallis deformation ❖ Kaniadakis deformation ⇒ ⇒ ⇒ ❖ Standard exponential function χ-exponential and logarithm function For any increasing function 14 (appeared in statistical mechanics) (appeared in theory of relativity) Without deformation
Examples: ⇒ ❖ Tsallis product ⇒ Deformed rank-1 approximation (deformed mean-field approximation) 16 ⇒ Intermediate between standard sum and standard product
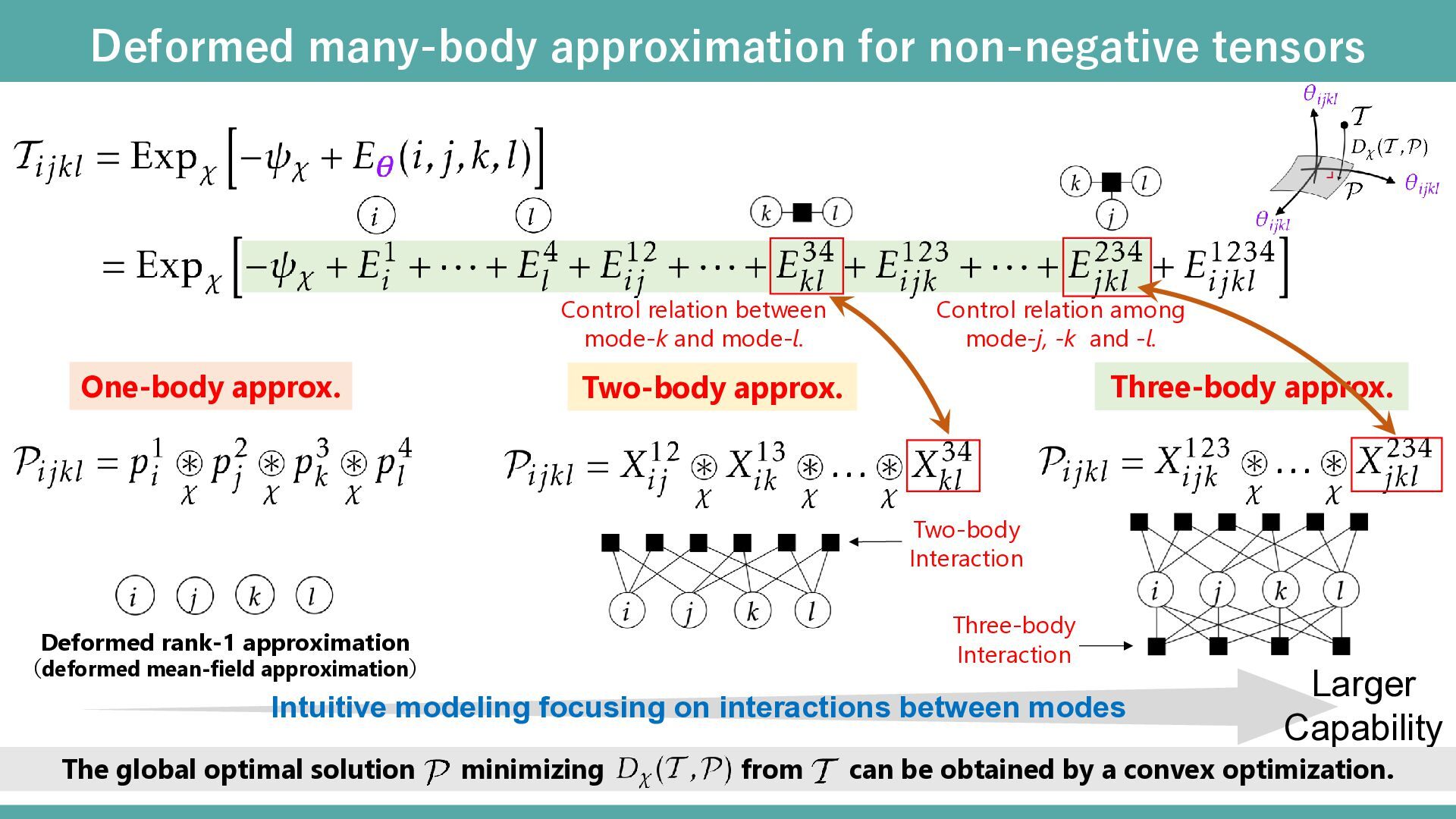
approx. The global optimal solution minimizing from can be obtained by a convex optimization. Control relation between mode-k and mode-l. Deformed rank-1 approximation (deformed mean-field approximation) Larger Capability
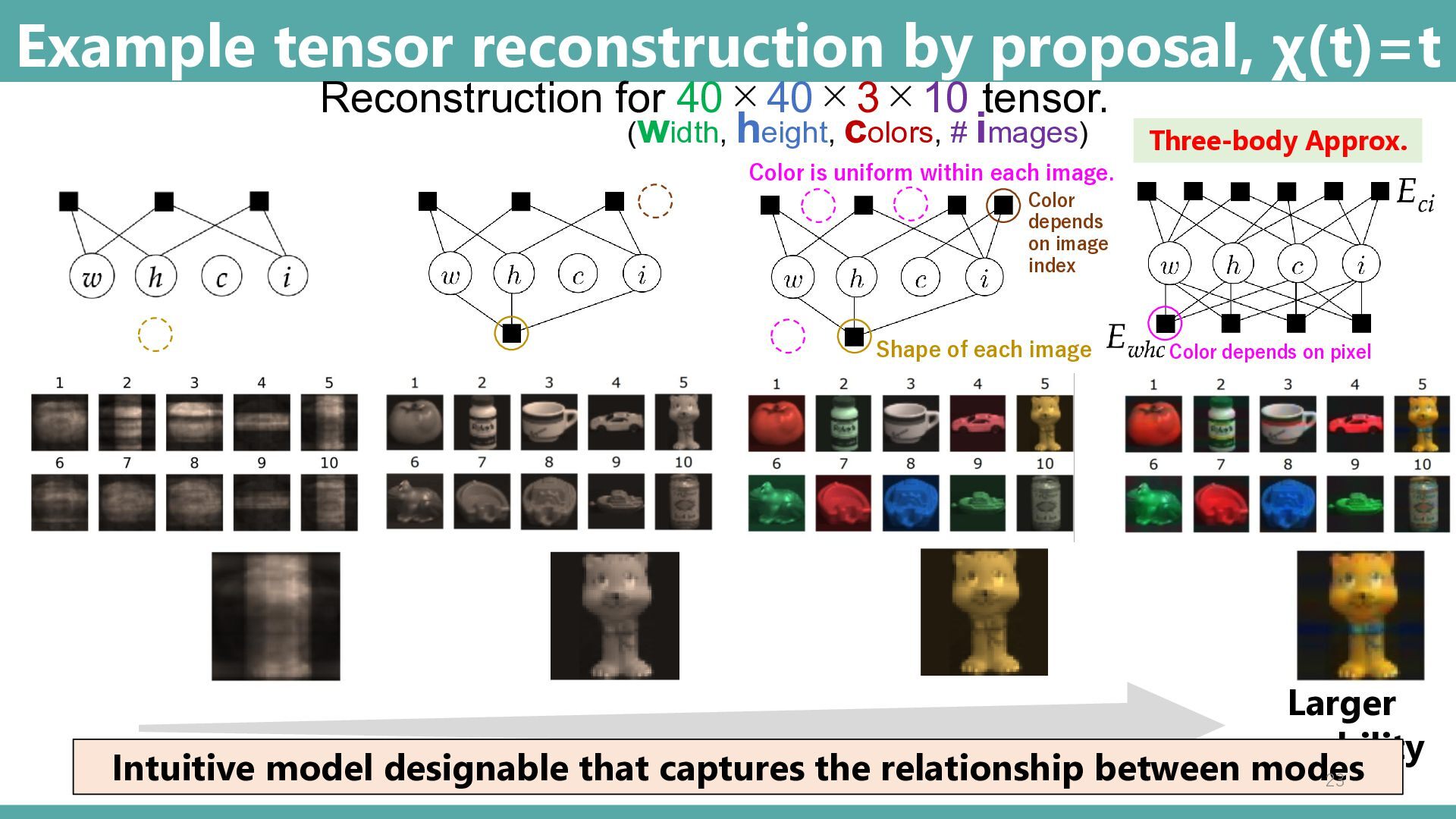
approx. Three-body approx. Larger Capability The global optimal solution minimizing from can be obtained by a convex optimization. Intuitive modeling focusing on interactions between modes Control relation between mode-k and mode-l. Control relation among mode-j, -k and -l. Two-body Interaction Three-body Interaction Deformed rank-1 approximation (deformed mean-field approximation)
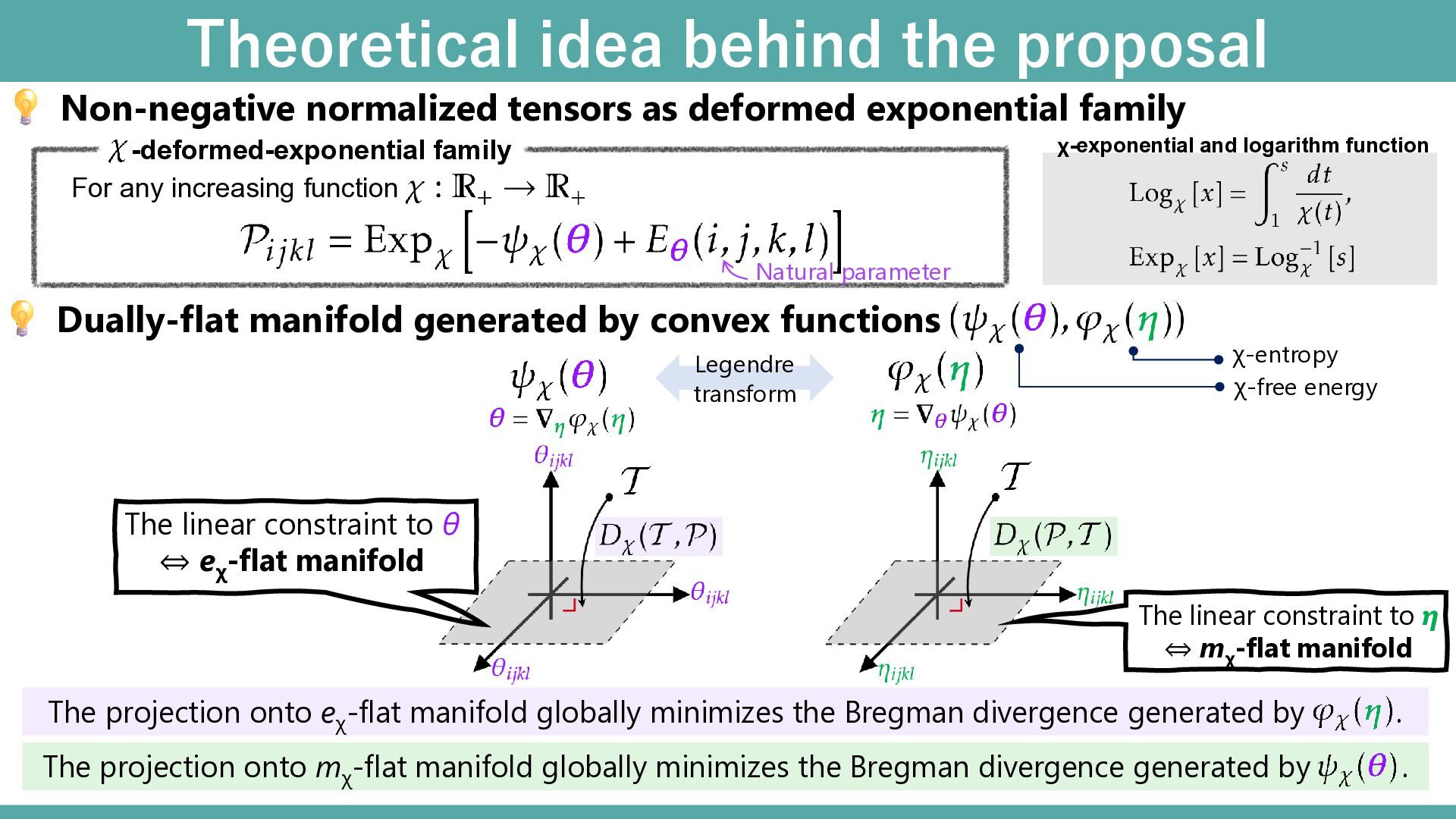
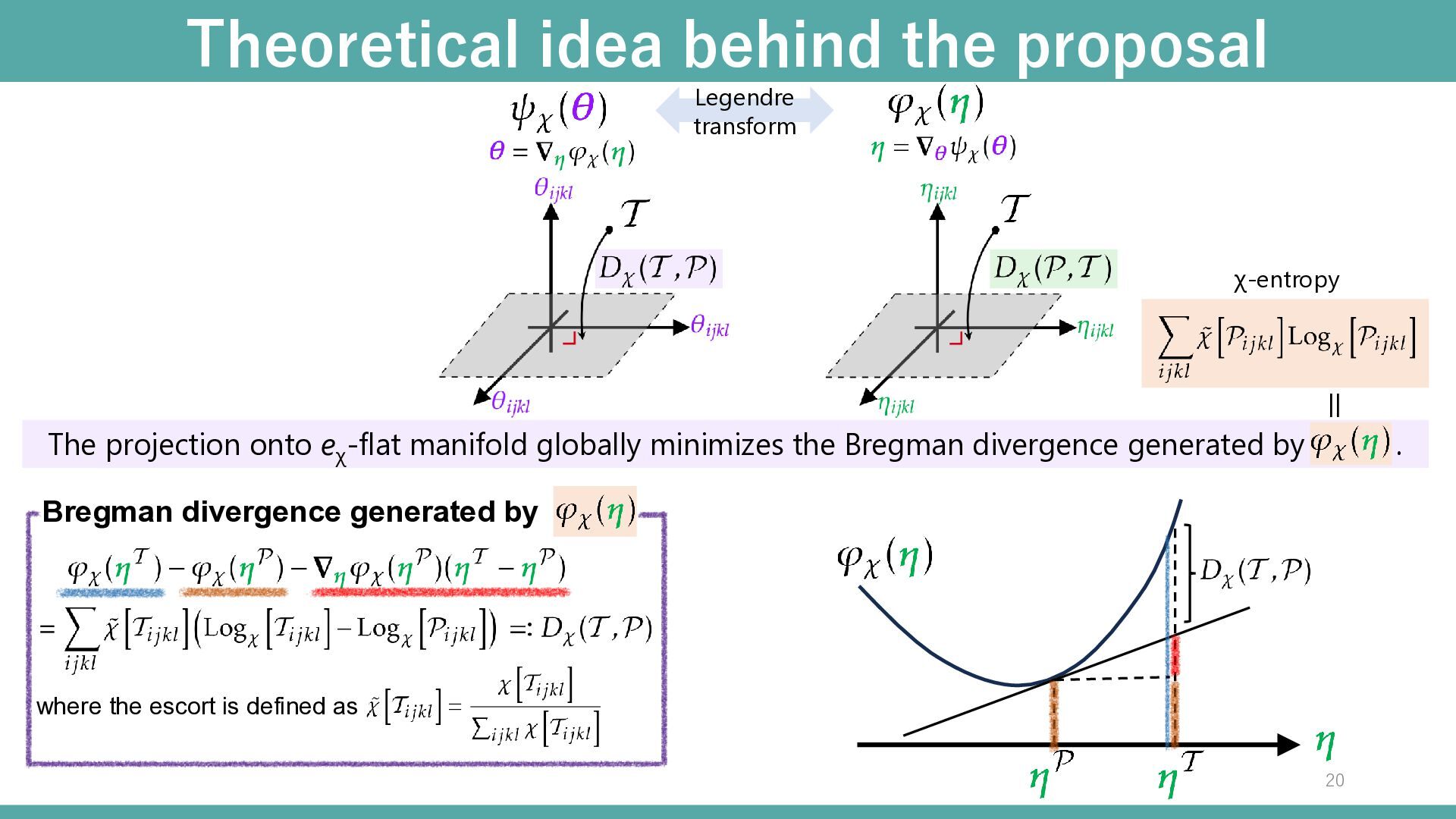
functions Non-negative normalized tensors as deformed exponential family For any increasing function χ-exponential and logarithm function -deformed-exponential family χ-free energy χ-entropy Legendre transform The linear constraint to θ ⇔ eχ -flat manifold The linear constraint to η ⇔ mχ -flat manifold The projection onto eχ -flat manifold globally minimizes the Bregman divergence generated by . The projection onto mχ -flat manifold globally minimizes the Bregman divergence generated by . Natural parameter
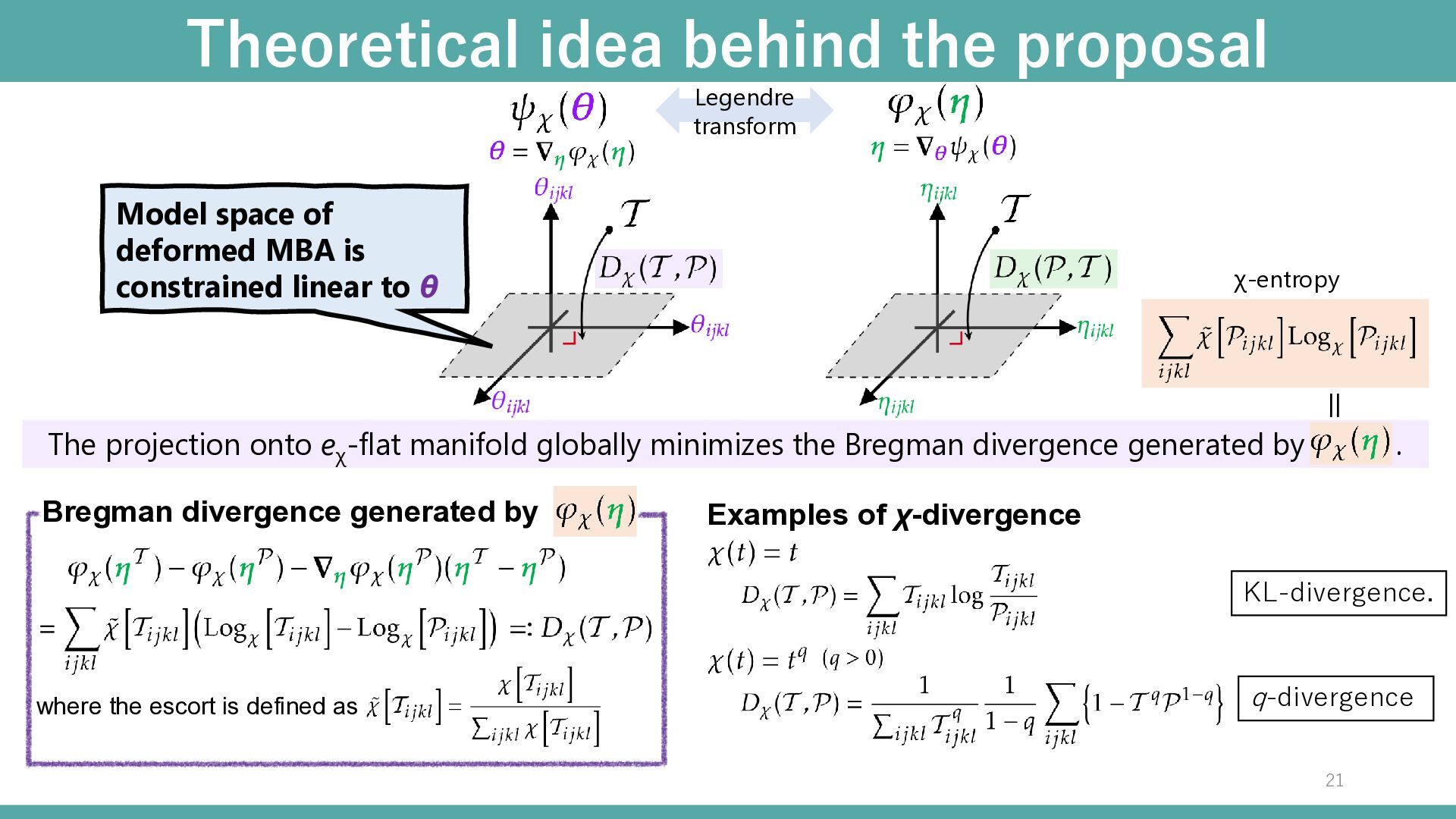
divergence generated by . Theoretical idea behind the proposal Legendre transform where the escort is defined as Bregman divergence generated by = χ-entropy 20
divergence generated by . Theoretical idea behind the proposal Legendre transform where the escort is defined as Bregman divergence generated by = χ-entropy Examples of χ-divergence KL-divergence. q-divergence Model space of deformed MBA is constrained linear to θ 21
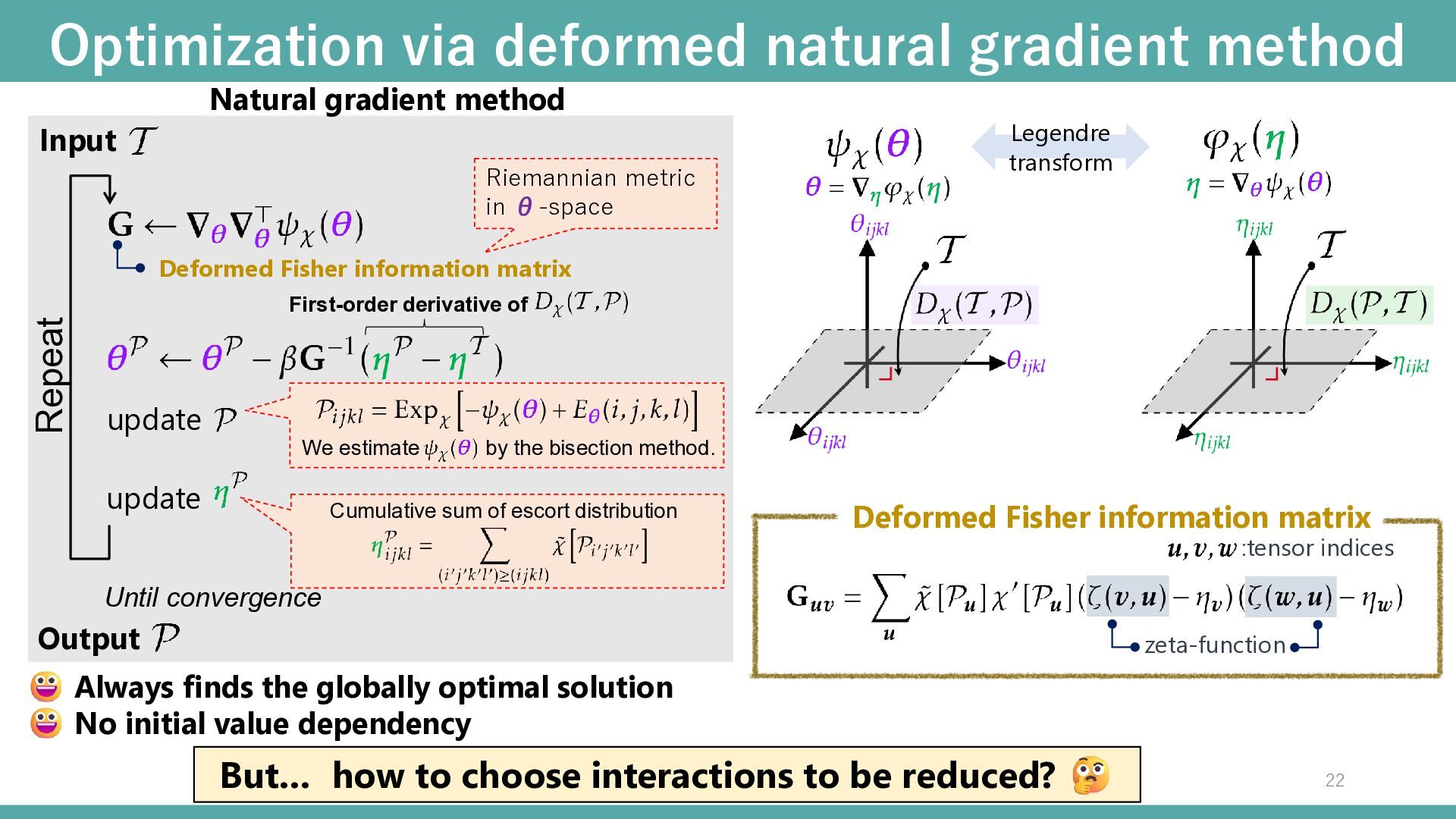
update Deformed Fisher information matrix Always finds the globally optimal solution No initial value dependency Legendre transform Repeat Until convergence Riemannian metric in θ-space First-order derivative of Cumulative sum of escort distribution We estimate by the bisection method. Input Output Deformed Fisher information matrix zeta-function :tensor indices But… how to choose interactions to be reduced? 22
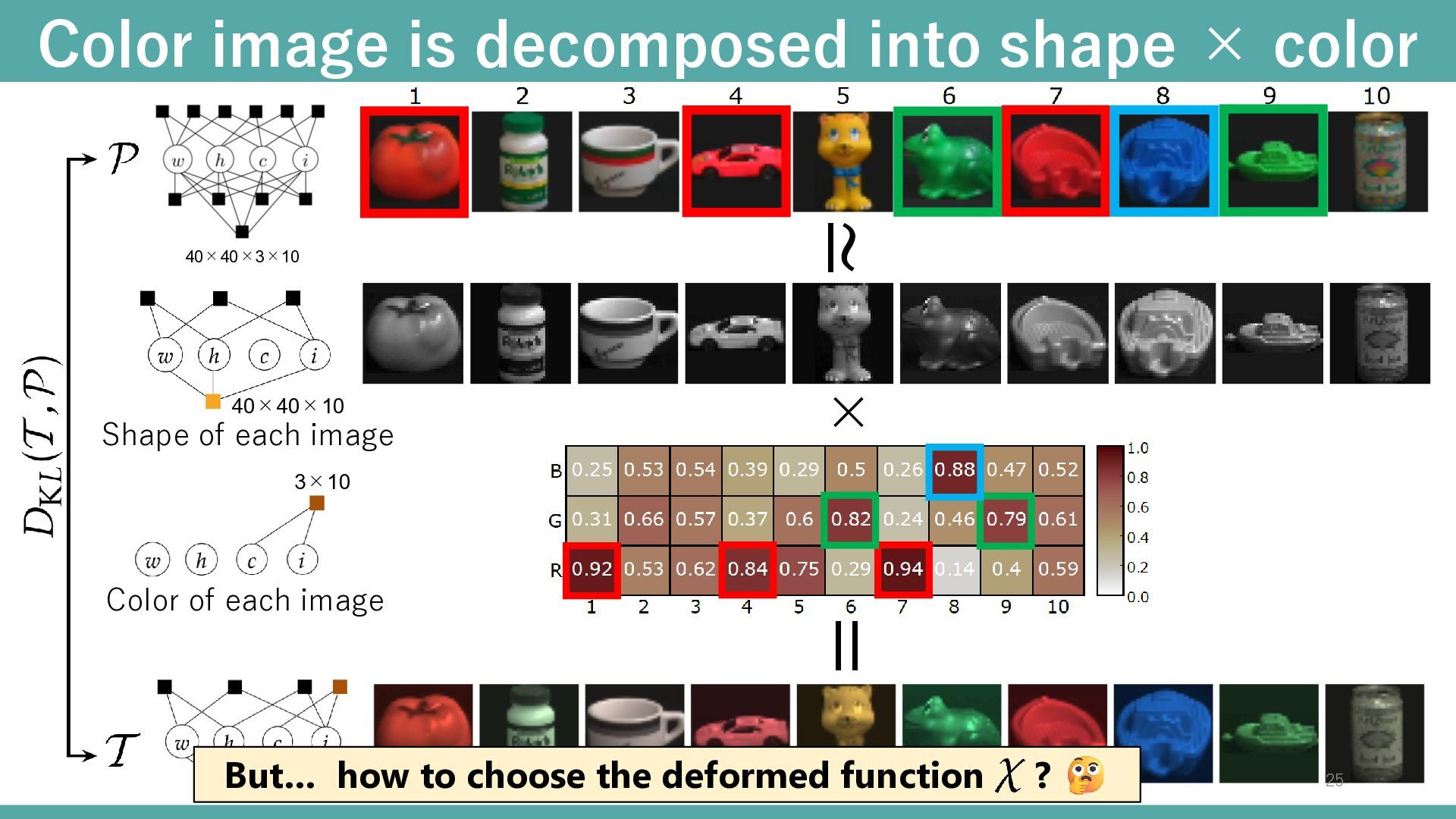
40×40×3×10 tensor. (width, height, colors, # images) Color depends on image index Shape of each image Color is uniform within each image. Intuitive model designable that captures the relationship between modes Color depends on pixel Three-body Approx. 23
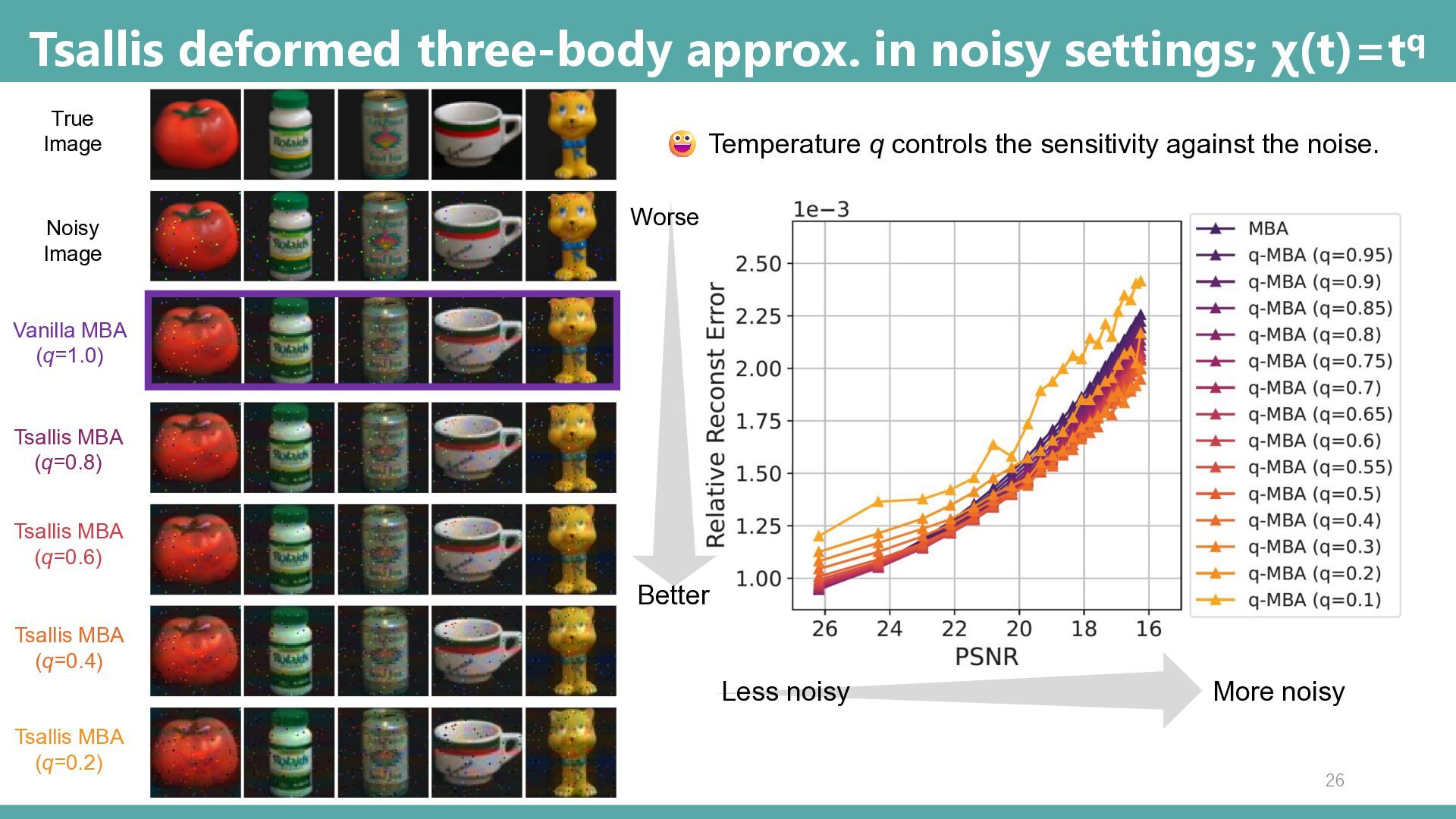
Less noisy Temperature q controls the sensitivity against the noise. Vanilla MBA (q=1.0) Tsallis MBA (q=0.8) Tsallis MBA (q=0.6) Tsallis MBA (q=0.4) Tsallis MBA (q=0.2) Noisy Image True Image Better Worse 26
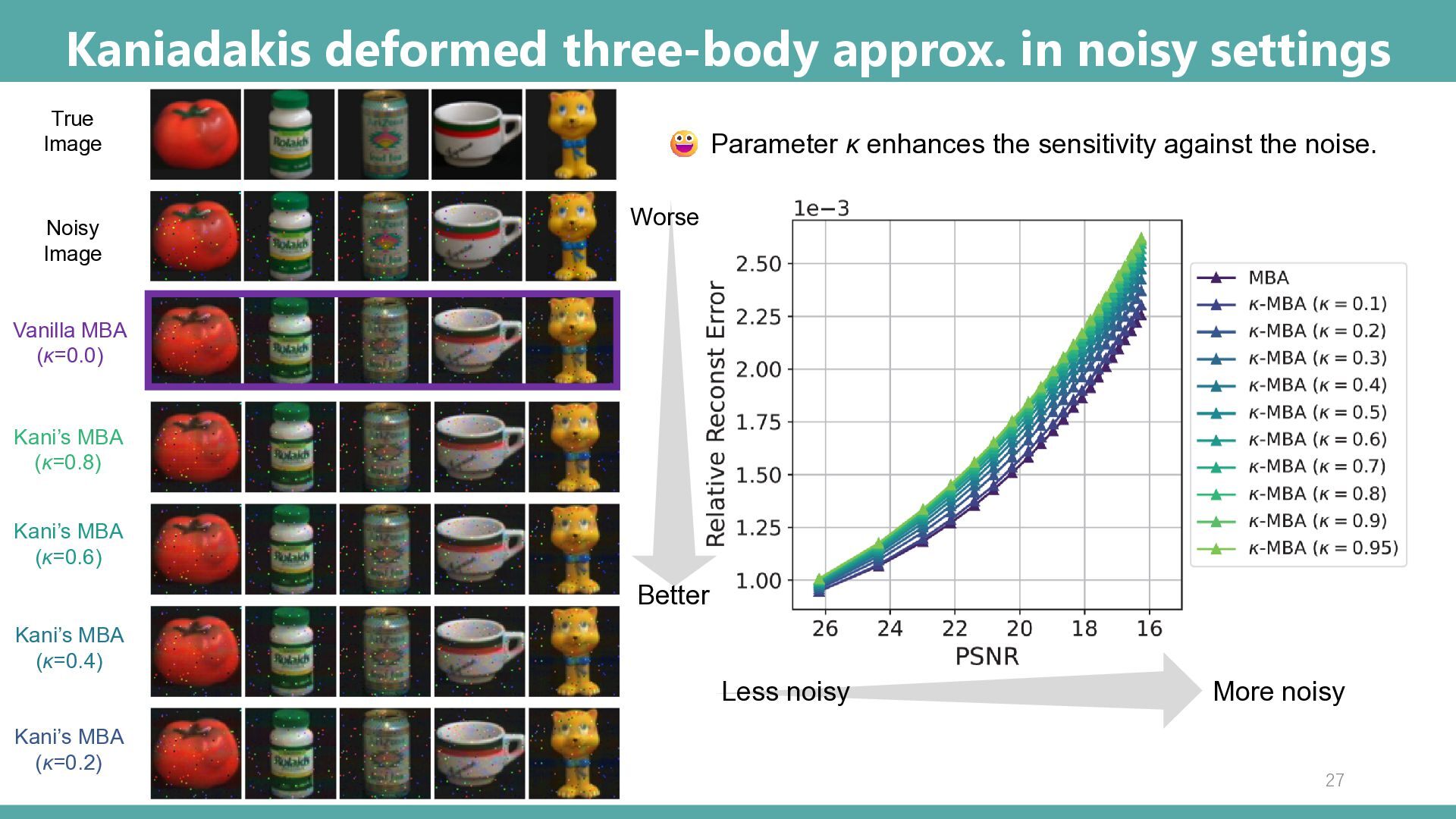
noisy Parameter κ enhances the sensitivity against the noise. Vanilla MBA (κ=0.0) Noisy Image True Image Kani’s MBA (κ=0.8) Kani’s MBA (κ=0.6) Kani’s MBA (κ=0.4) Kani’s MBA (κ=0.2) Better Worse 27
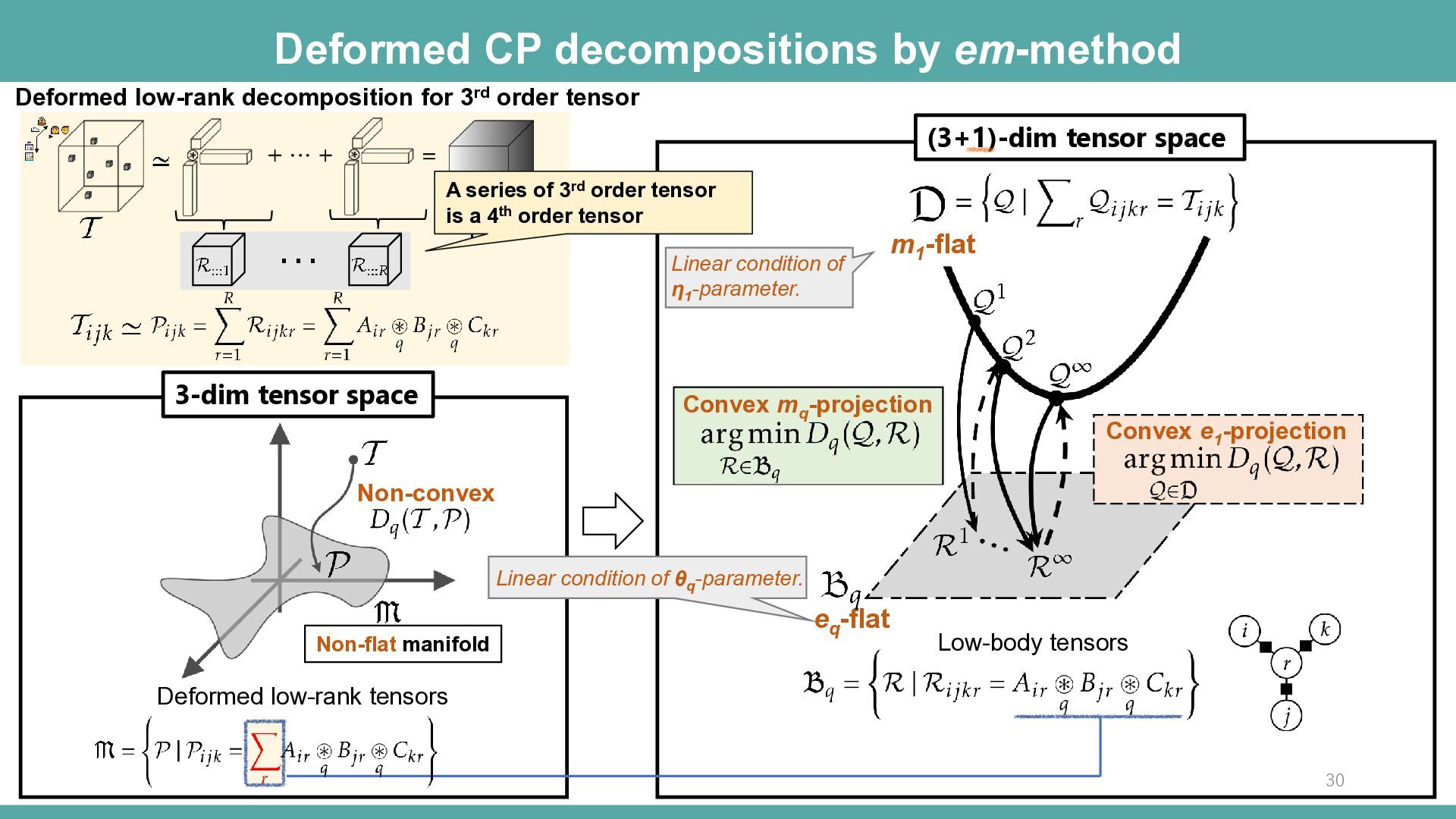
space Non-flat manifold Deformed low-rank tensors Deformed low-rank decomposition for 3rd order tensor Low-body tensors eq -flat (3+1)-dim tensor space Linear condition of θq -parameter. Convex mq -projection Linear condition of η1 -parameter. A series of 3rd order tensor is a 4th order tensor Convex e1 -projection m1 -flat
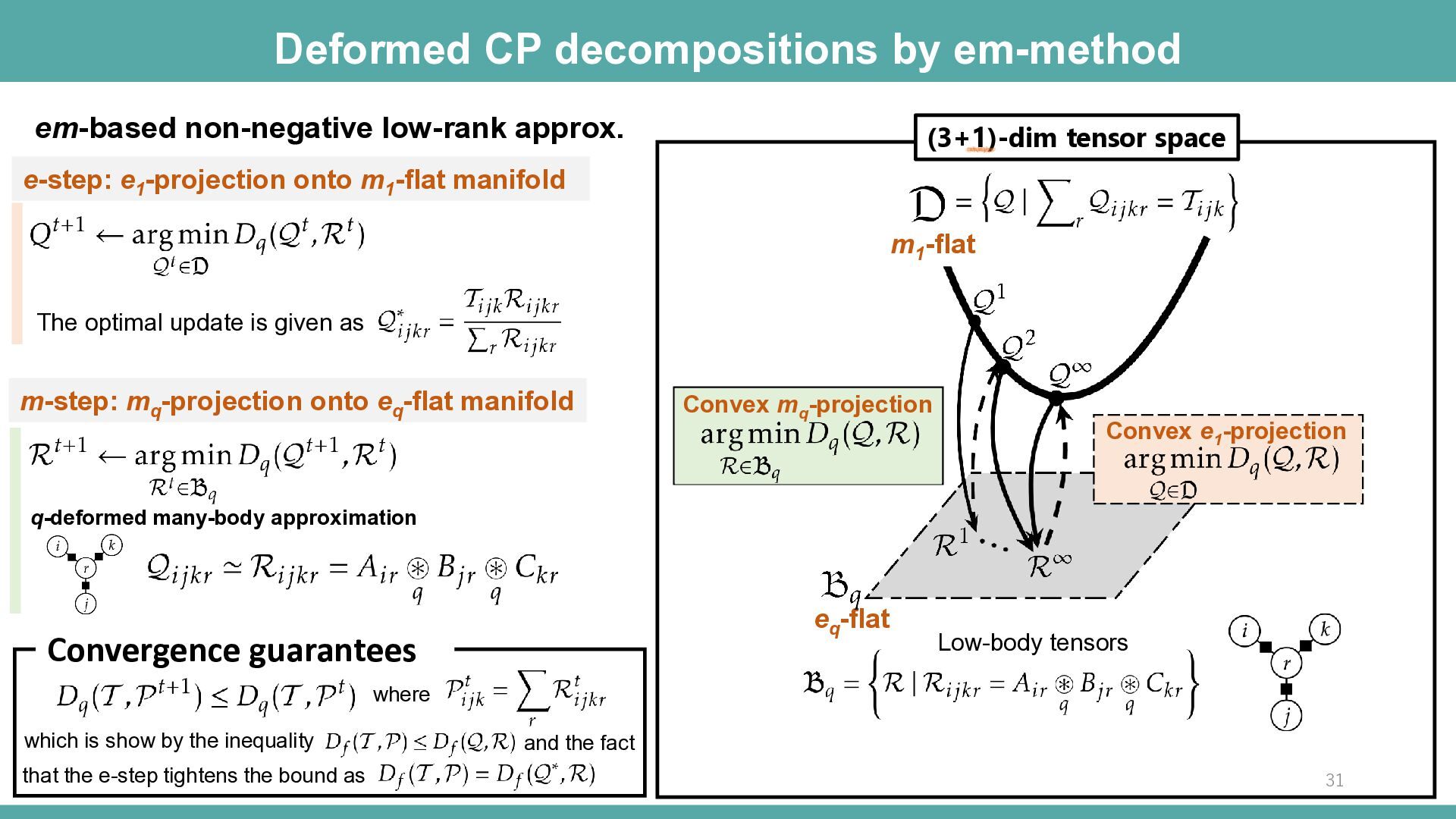
(3+1)-dim tensor space Convex mq -projection Convex e1 -projection m1 -flat em-based non-negative low-rank approx. e-step: e1 -projection onto m1 -flat manifold m-step: mq -projection onto eq -flat manifold q-deformed many-body approximation The optimal update is given as where which is show by the inequality that the e-step tightens the bound as and the fact Convergence guarantees
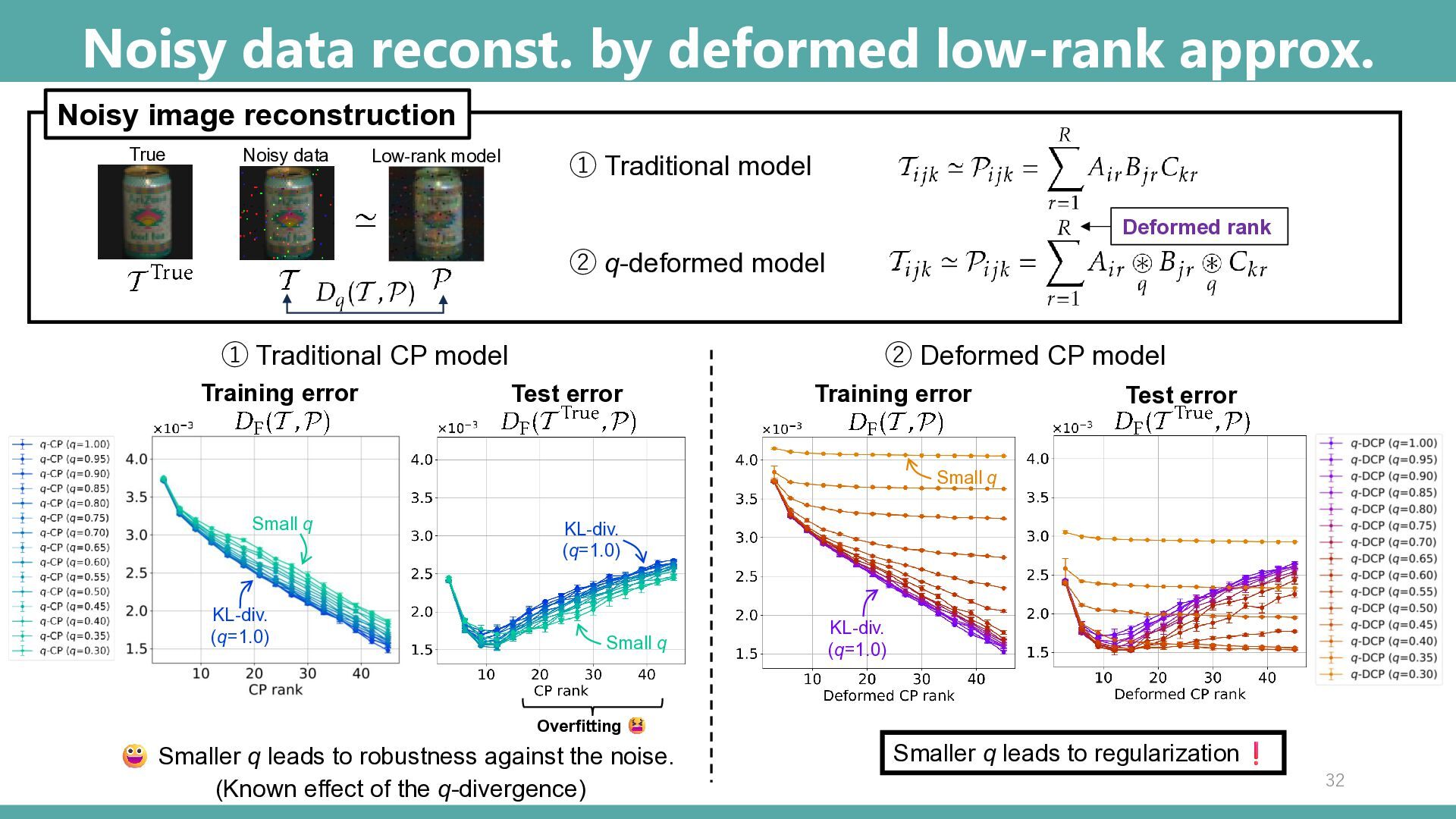
Training error True Noisy data Low-rank model Test error ② q-deformed model Noisy image reconstruction ① Traditional CP model ② Deformed CP model Training error Test error Smaller q leads to robustness against the noise. (Known effect of the q-divergence) Overfitting Smaller q leads to regularization KL-div. (q=1.0) KL-div. (q=1.0) Small q Small q KL-div. (q=1.0) Small q 32 Deformed rank
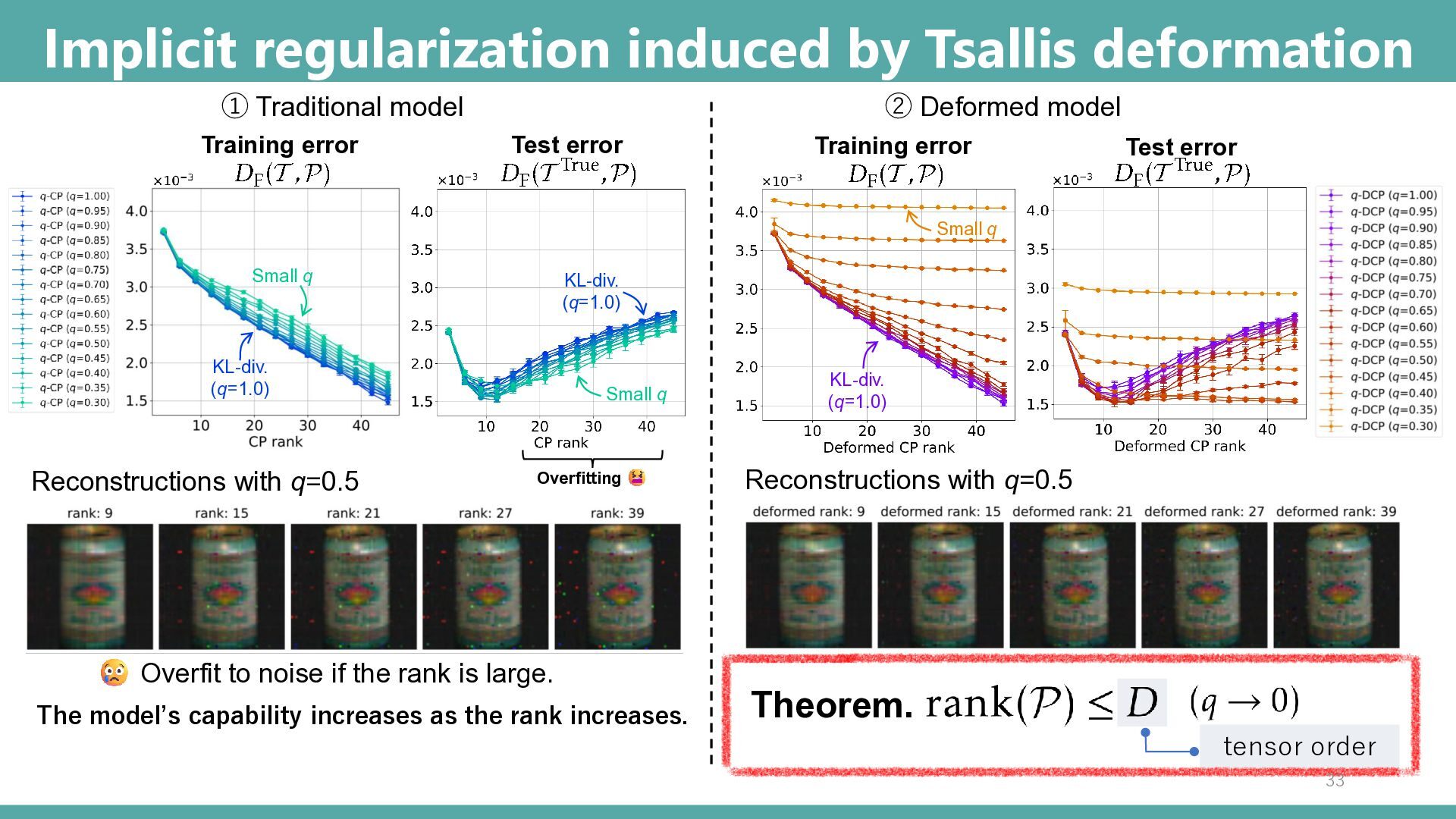
② Deformed model Training error Test error Overfitting KL-div. (q=1.0) KL-div. (q=1.0) Small q Small q KL-div. (q=1.0) Small q Reconstructions with q=0.5 Reconstructions with q=0.5 No noise even with larger ranks Overfit to noise if the rank is large. The model’s capability increases as the rank increases. For small 𝑞, the model capacity remains limited despite a large deformed rank. Theorem. tensor order ① Traditional model 33
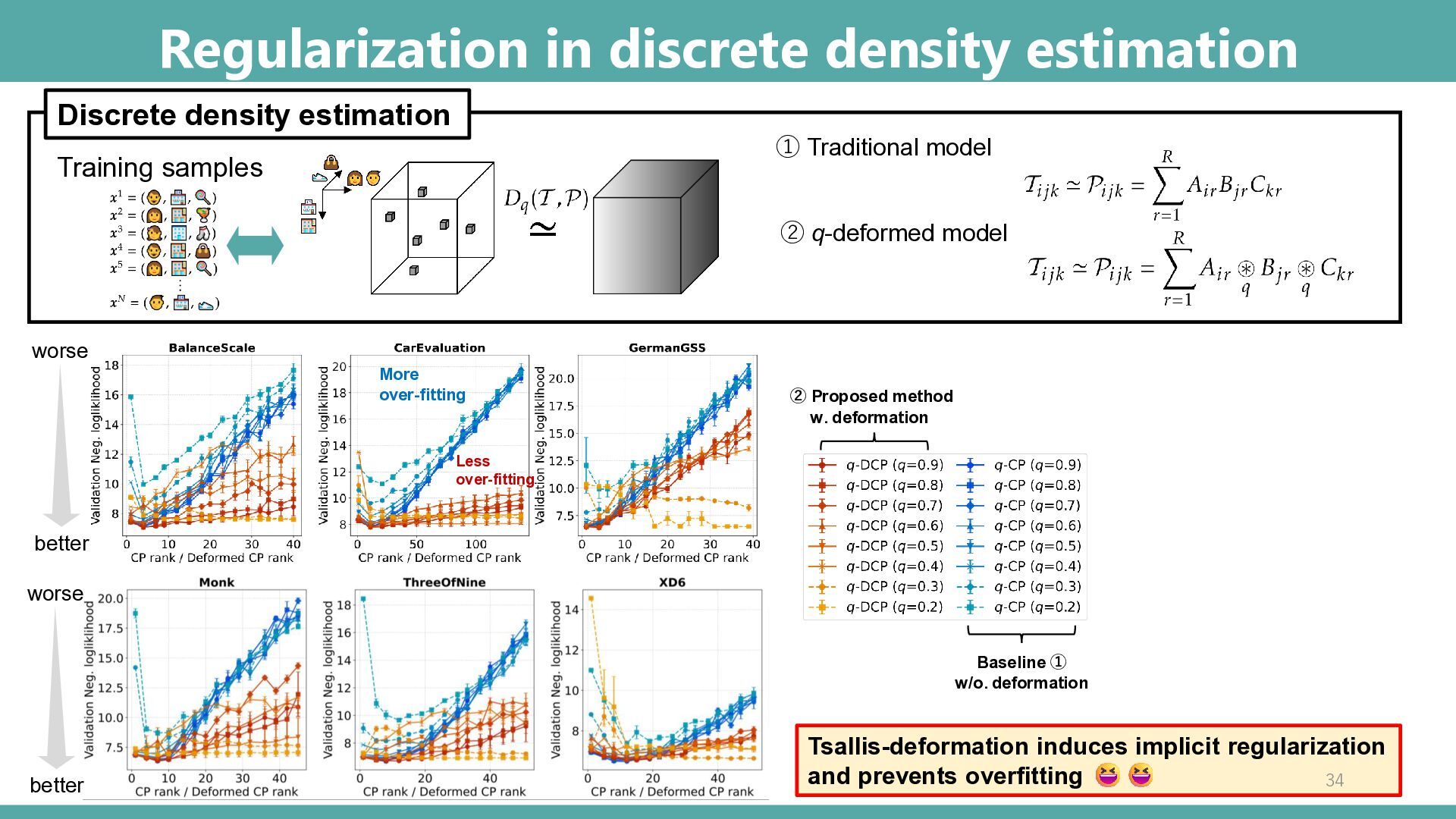
① Traditional model ② q-deformed model Baseline ① w/o. deformation ② Proposed method w. deformation better worse better worse More over-fitting Less over-fitting Tsallis-deformation induces implicit regularization and prevents overfitting 34
non-negative tensors Global optimization of a wide family of divergences, χ-divergence One-body Approx. Three-body Approx. Two-body Approx. Noise sensitive Noise robust Non-flat manifold Non-convex 37 Visit high-dimensional space to seek flatness. The deformation flexibly adjusts the model’s behavior. Smaller q leads to implicit regularization Visit high-dimensional space to seek flatness. m-step e-step flat manifold flat manifold e-step
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}