Authors: Kazu Ghalamkari, Jesper Løve Hinrich, Morten Mørup
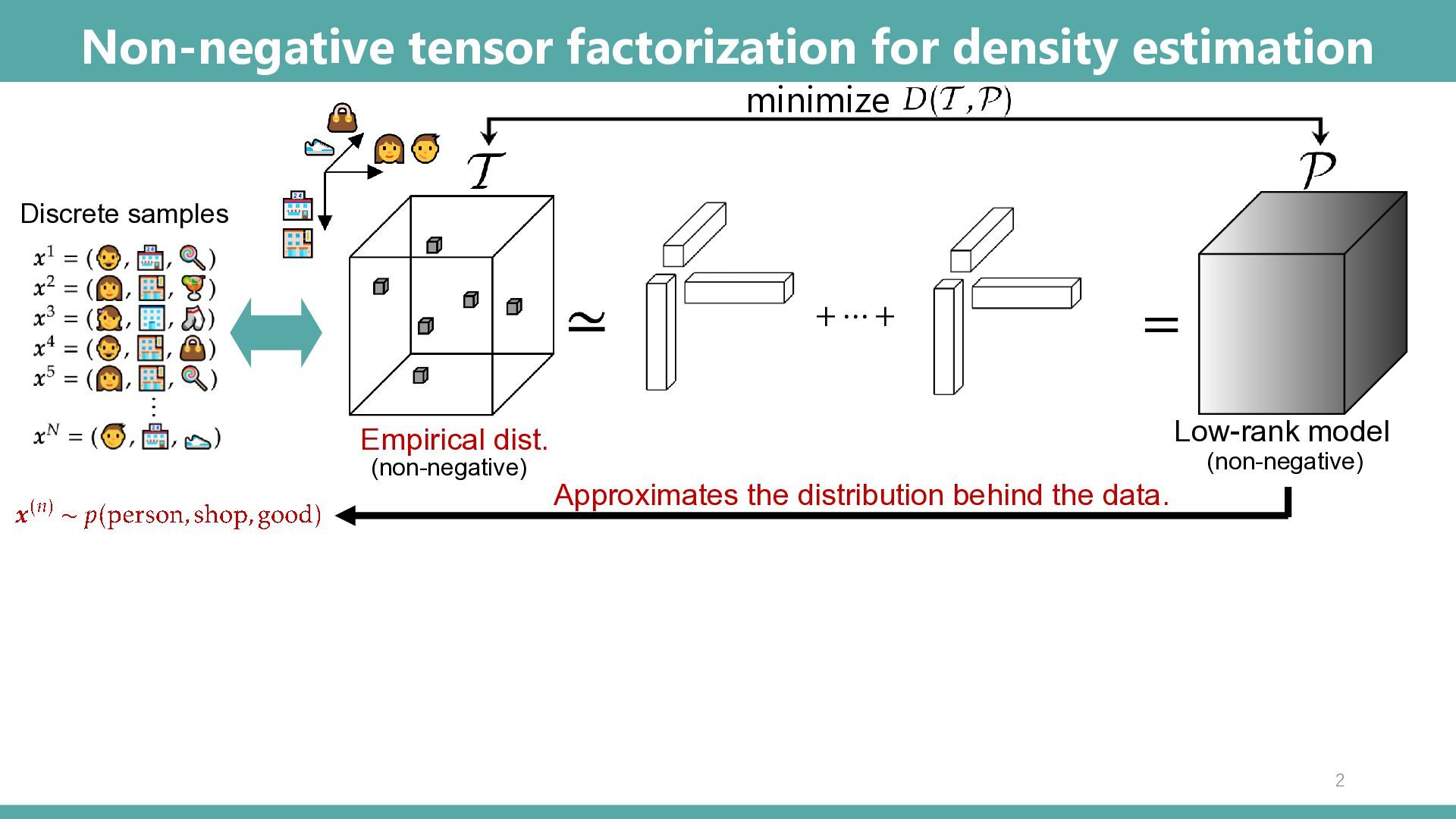
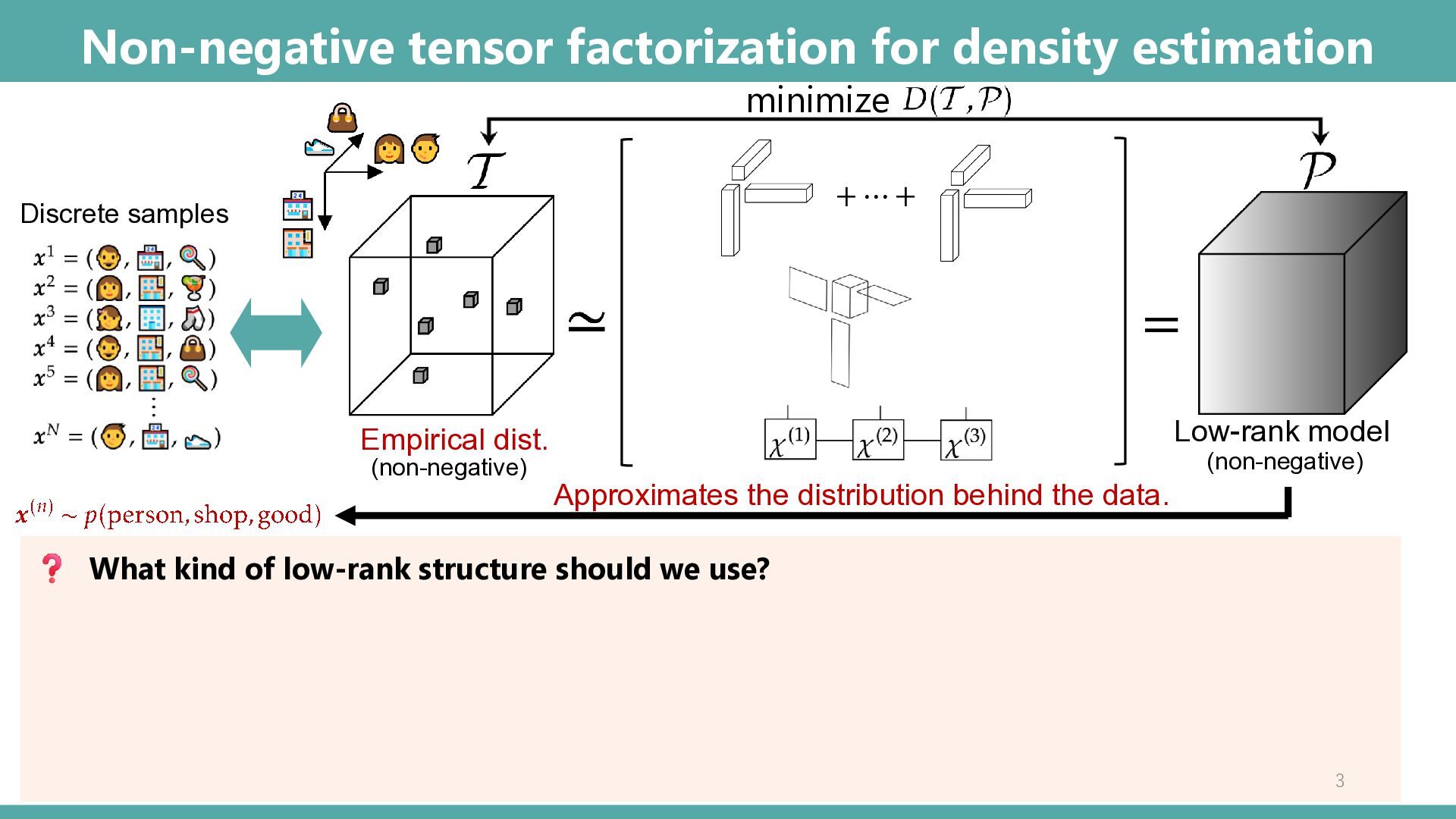
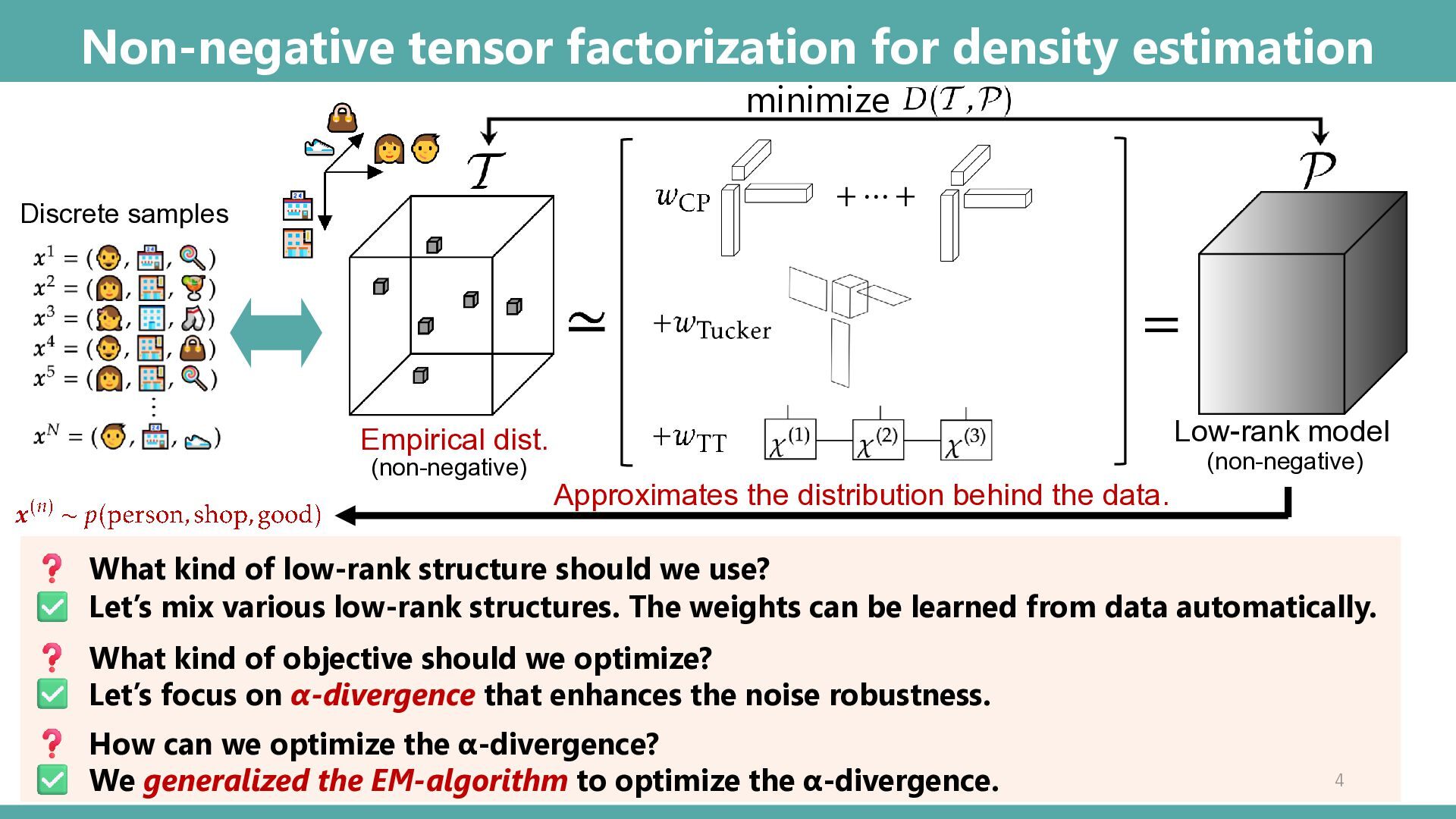
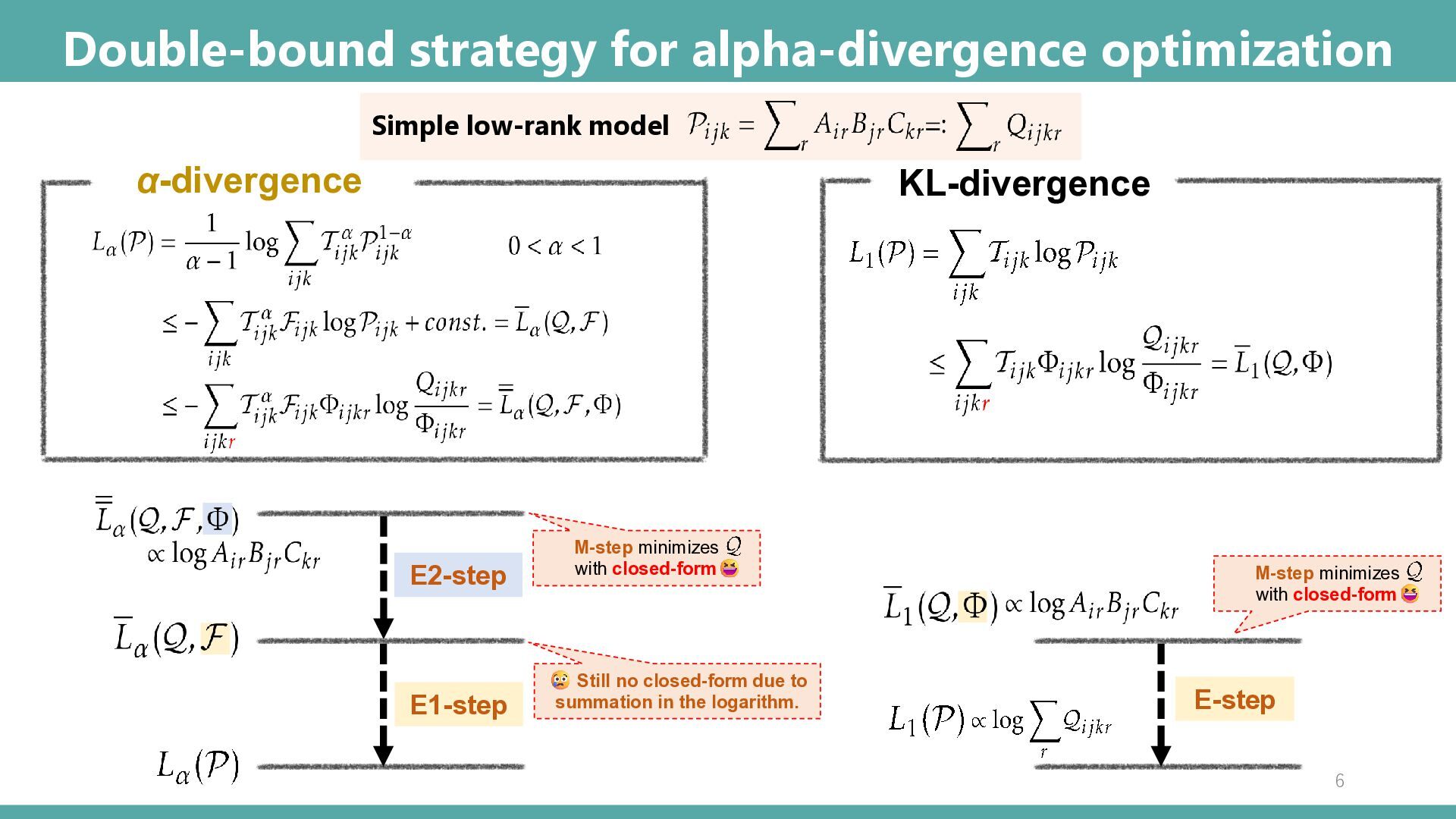
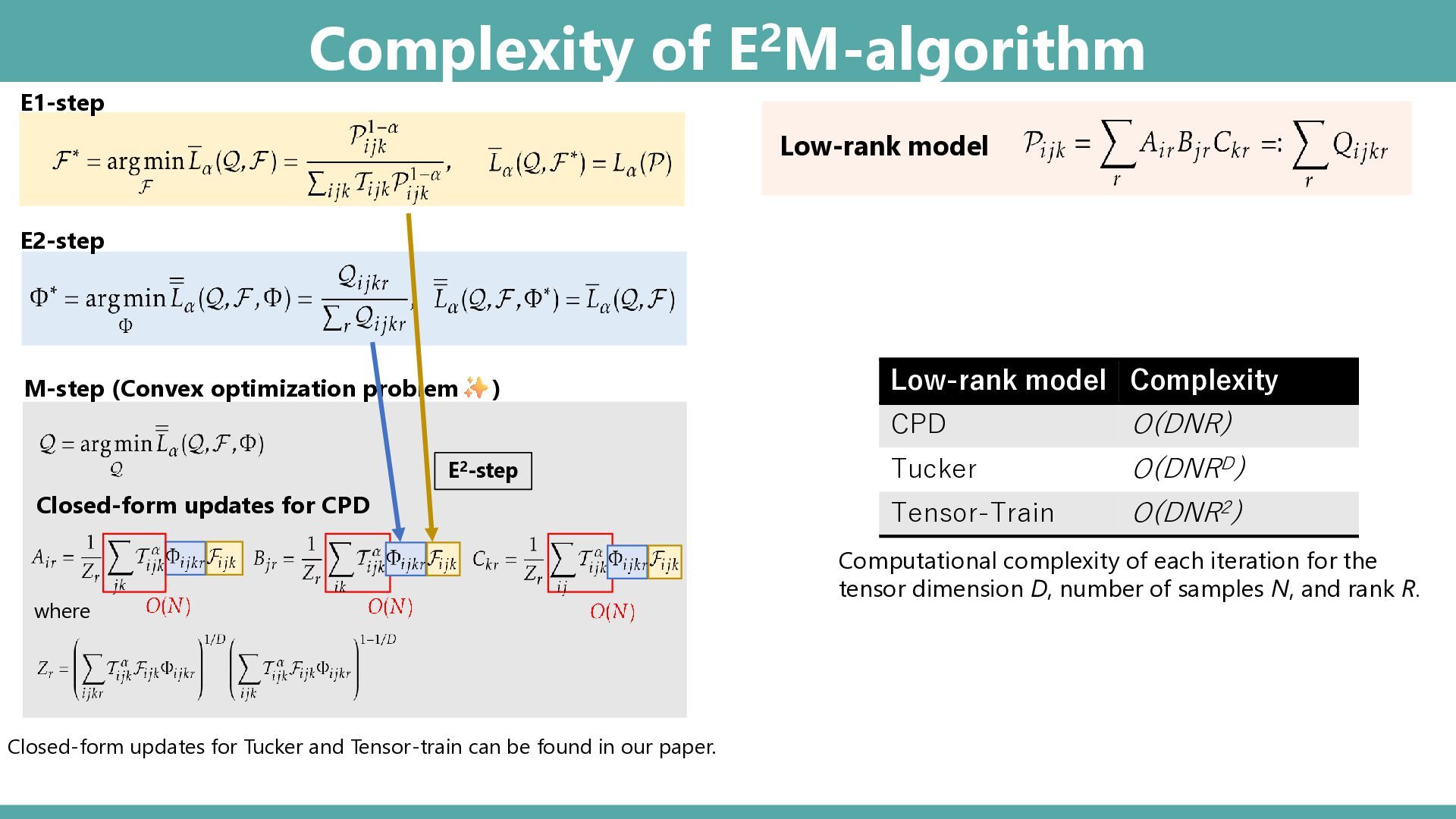
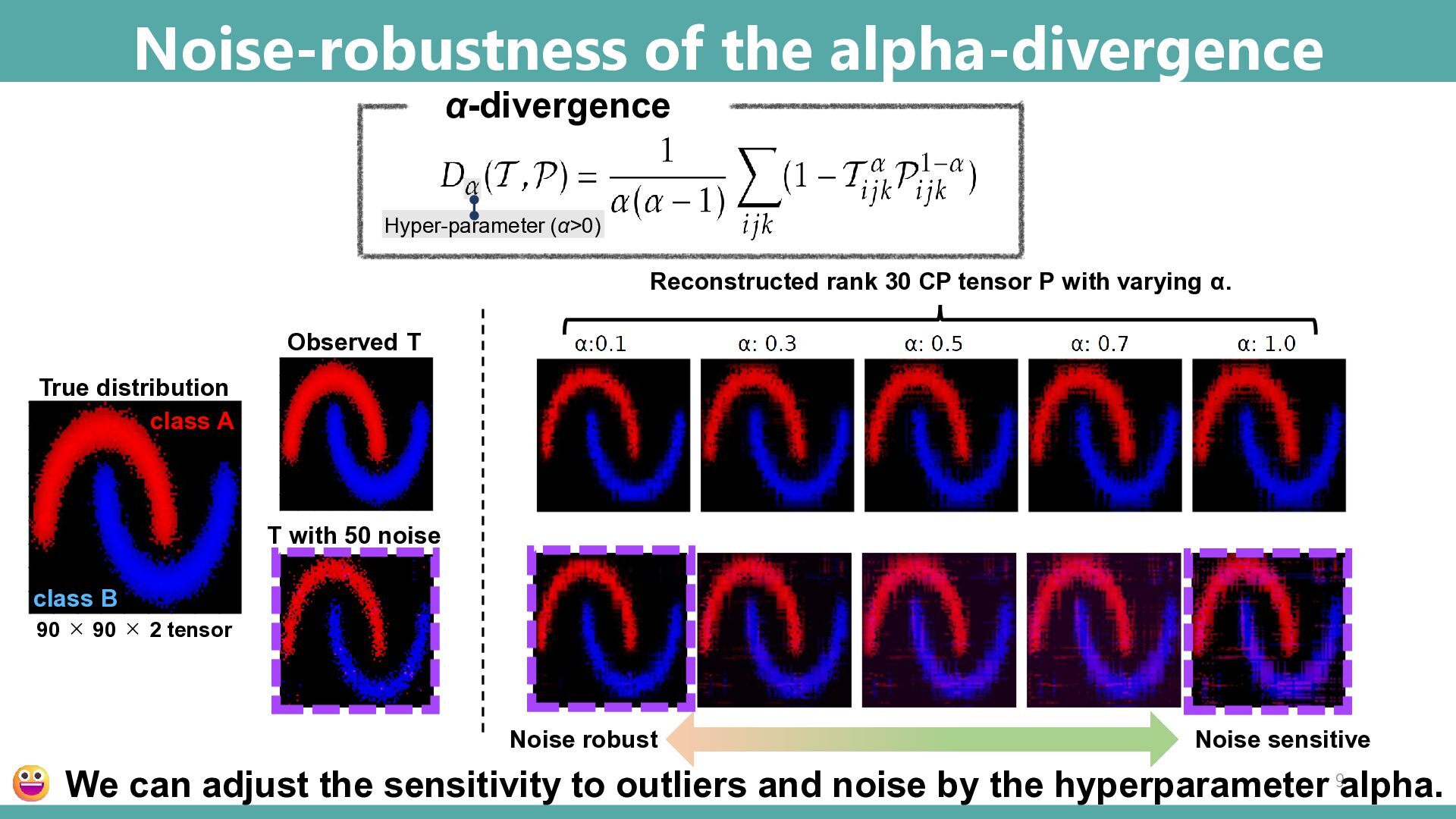
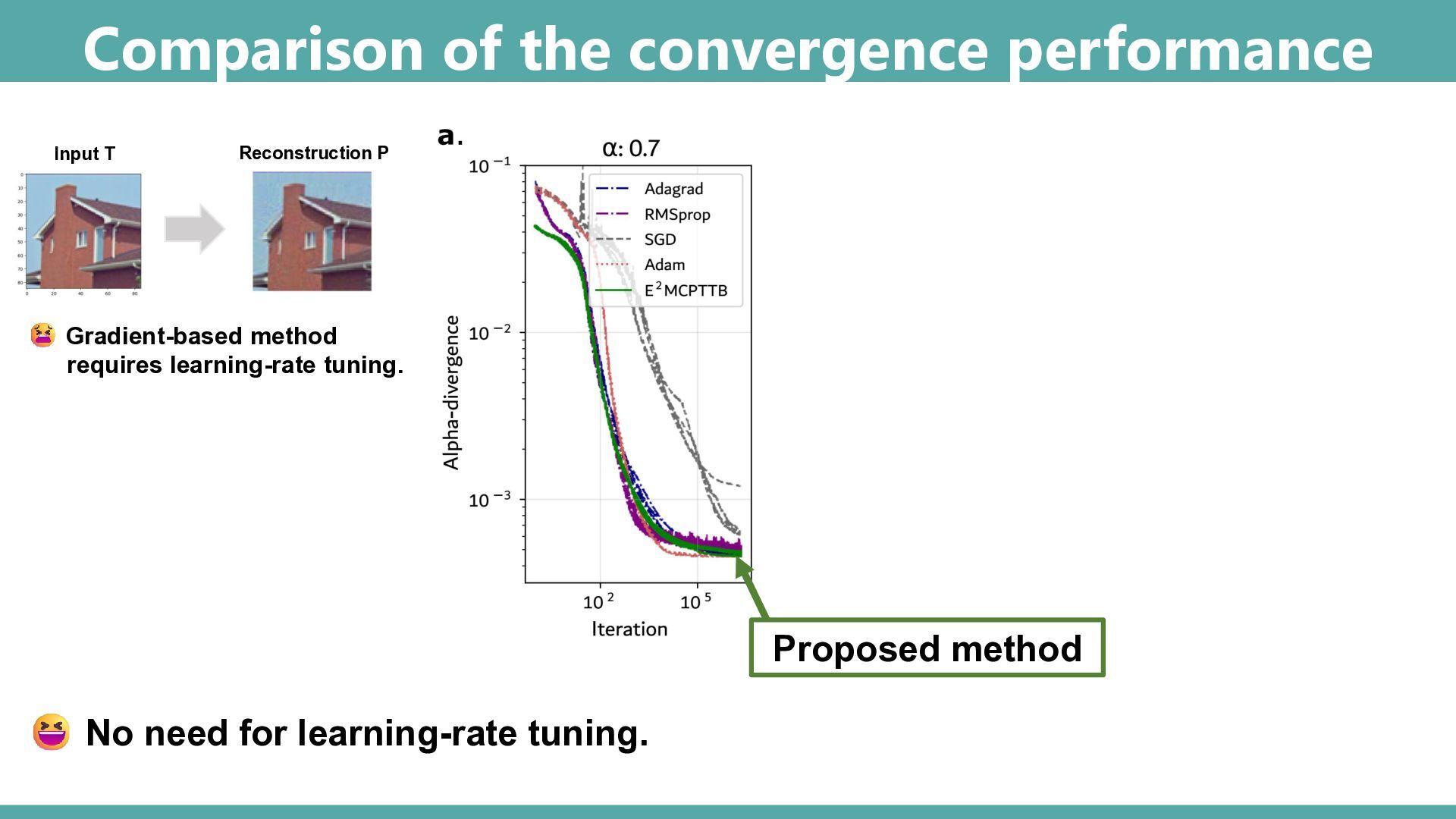
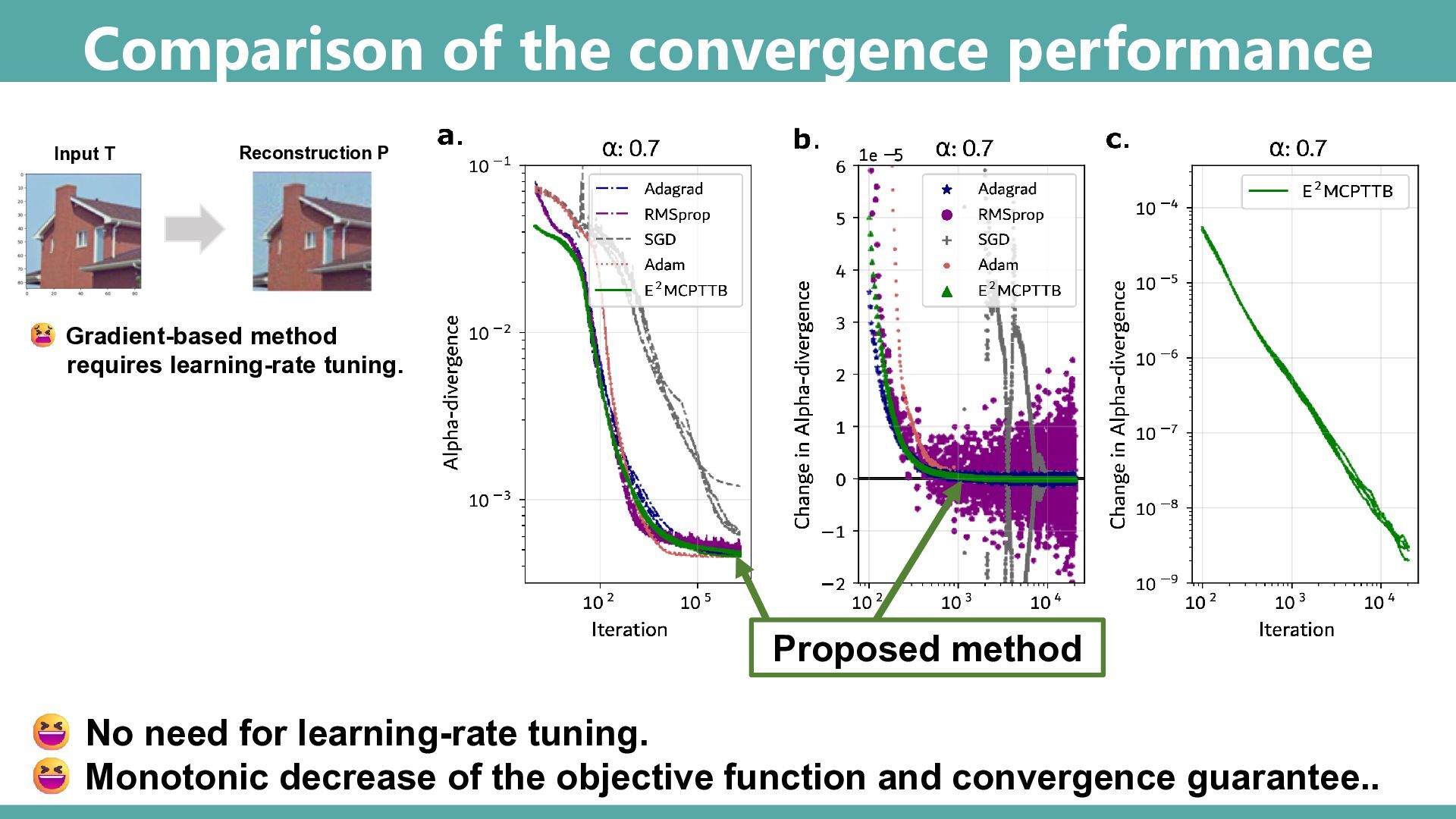
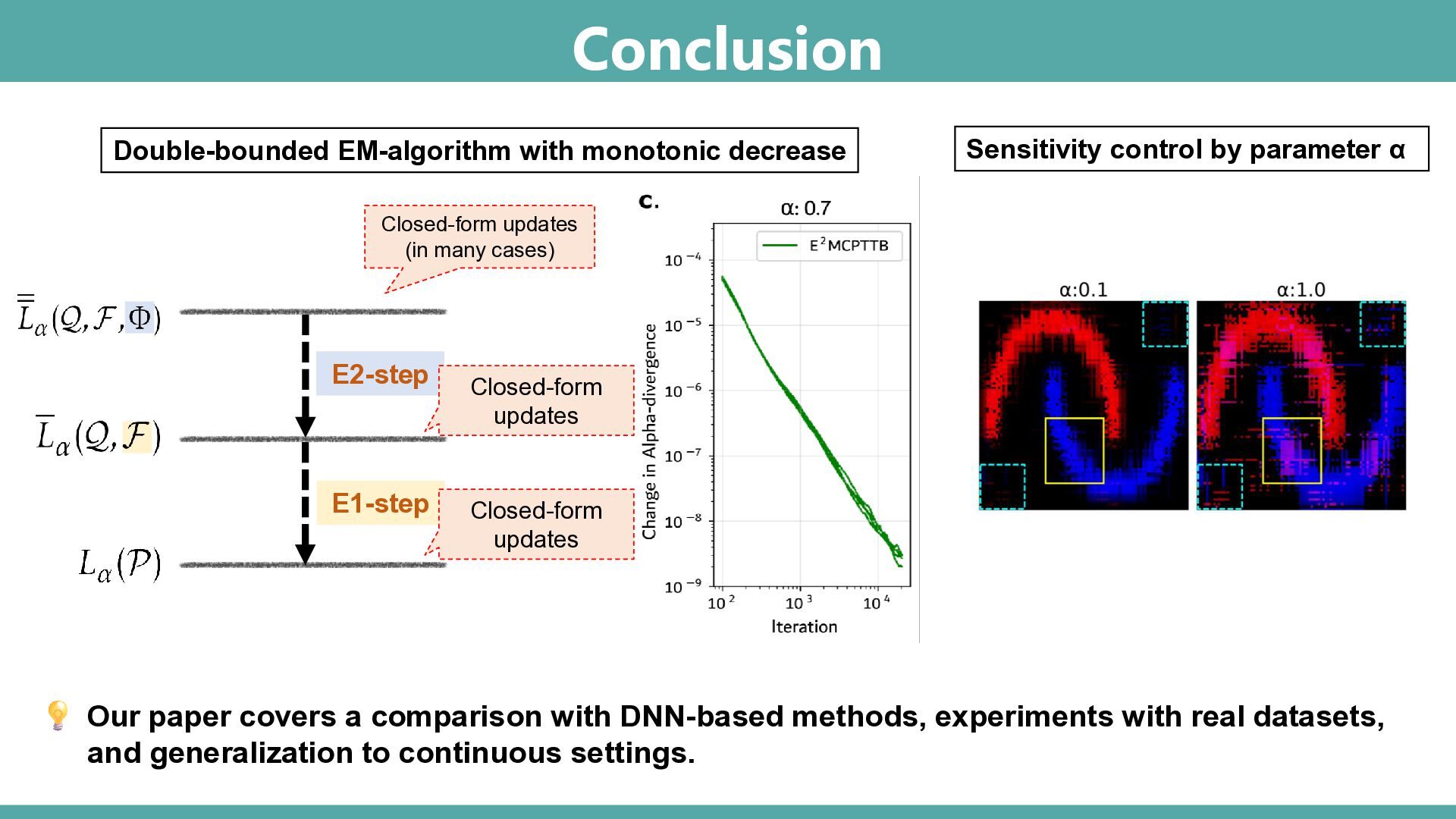
Abstract: Tensor-based discrete density estimation requires flexible modeling and proper divergence criteria to enable effective learning; however, traditional approaches using α-divergence face analytical challenges due to the α-power terms in the objective function, which hinder the derivation of closed-form update rules. We present a generalization of the expectation-maximization (EM) algorithm, called the E2M algorithm. It circumvents this issue by first relaxing the optimization into the minimization of a surrogate objective based on the Kullback–Leibler (KL) divergence, which is tractable via the standard EM algorithm, and subsequently applying a tensor many-body approximation in the M-step to enable simultaneous closed-form updates of all parameters. Our approach offers flexible modeling for not only a variety of low-rank structures, including the CP, Tucker, and Tensor Train formats, but also their mixtures, thus allowing us to leverage the strengths of different low-rank structures. We evaluate the effectiveness of our approach on synthetic and real datasets, highlighting its superior convergence to gradient-based procedures, robustness to outliers, and favorable density estimation performance compared to prominent existing tensor-based methods.
Published in Transactions on Machine Learning Research (TMLR) with Featured Certification in 2026
[Video]
https://www.youtube.com/watch?v=adXhQ8roDGA
[Paper]
https://openreview.net/forum?id=954CjhXSXL
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}