plates • User oriented • App development • Product delivery • Model accuracy • Visualization of data • Notebooks • Data-driven • Mathematical computations
align their requirements ◦ Avoid high level planning ◦ Be very specific in resource requirements • “What data are we using?” • “Who will be using the data?”
SAD! • If there will be errors, make it straight to the point • Don’t expect 100% code quality from Data Scientists • Utilize language feature ◦ Type hints in python ◦ Data classes
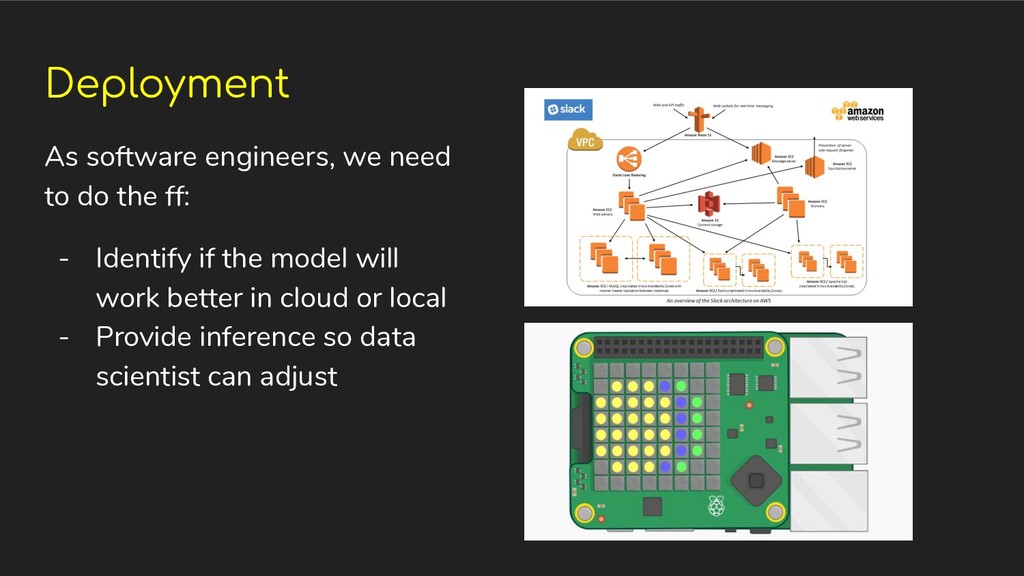
and memory limitations ◦ Storage options ◦ Multiprocessing vs multithreading • How models will be used by applications ◦ Interfaces ◦ Communication protocols
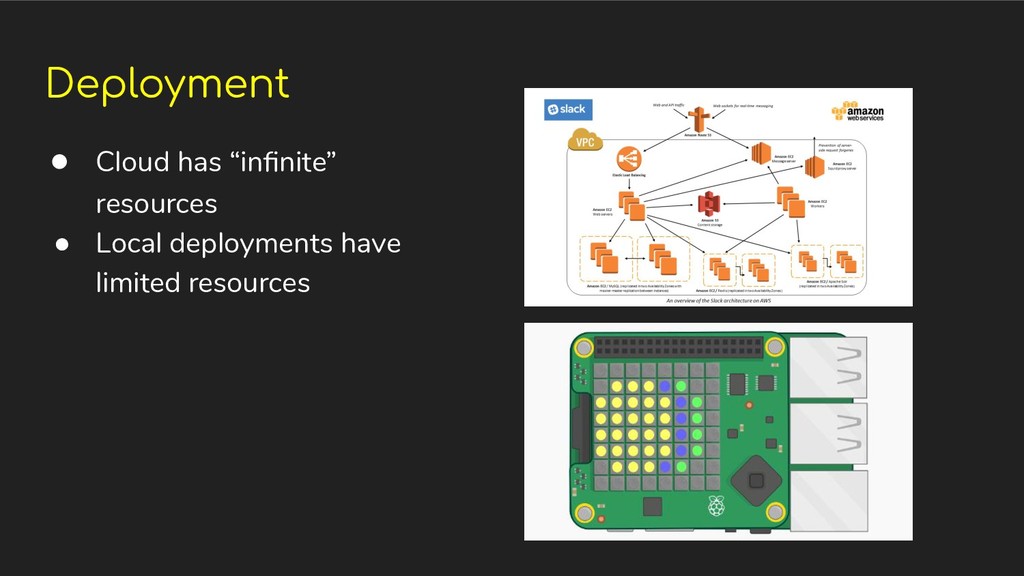
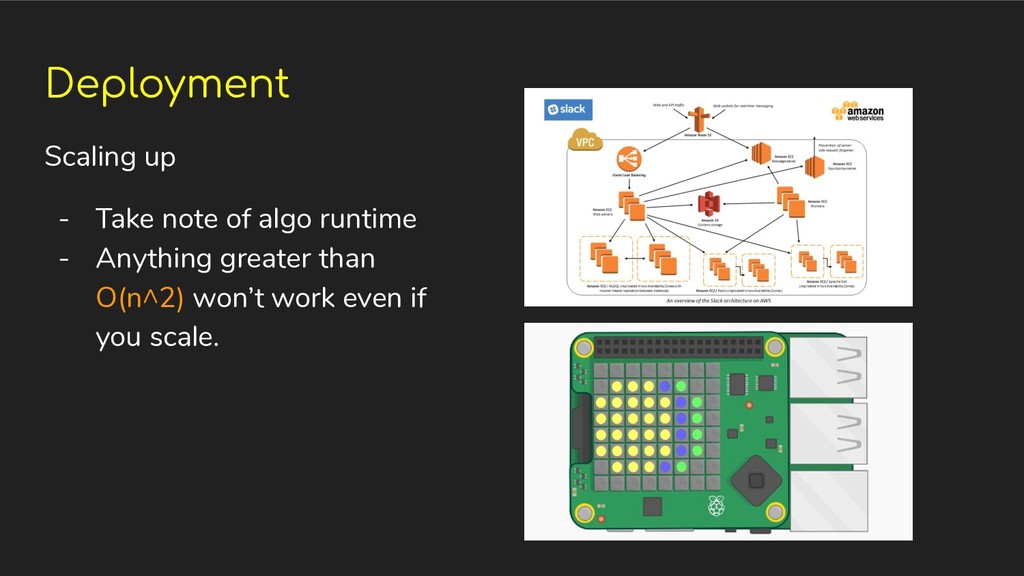
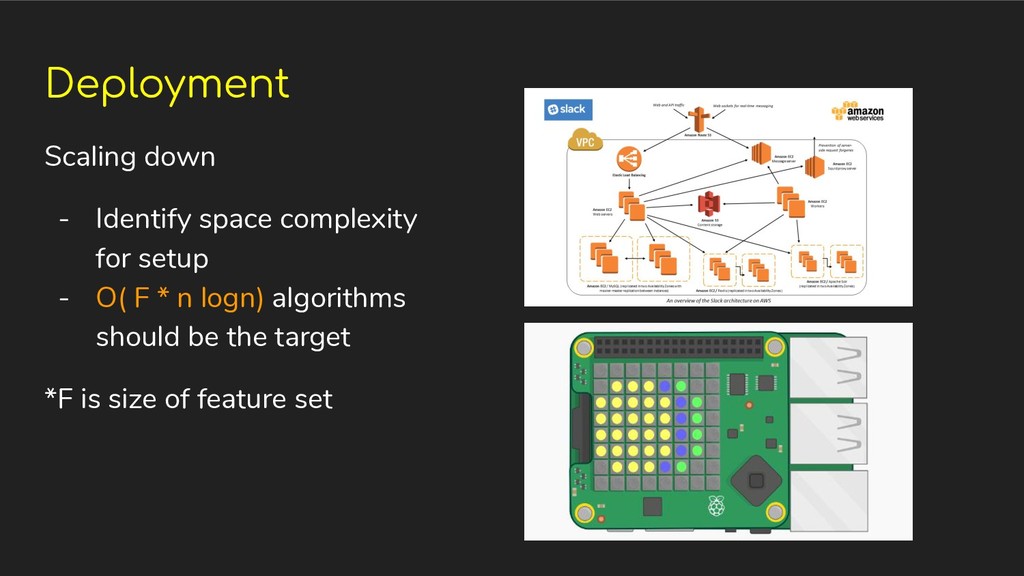
Mobile ◦ Micro Controllers, etc • Scaling up cloud deployments • Scaling down for local deployments (minimal resource environment) • Continuous Integration
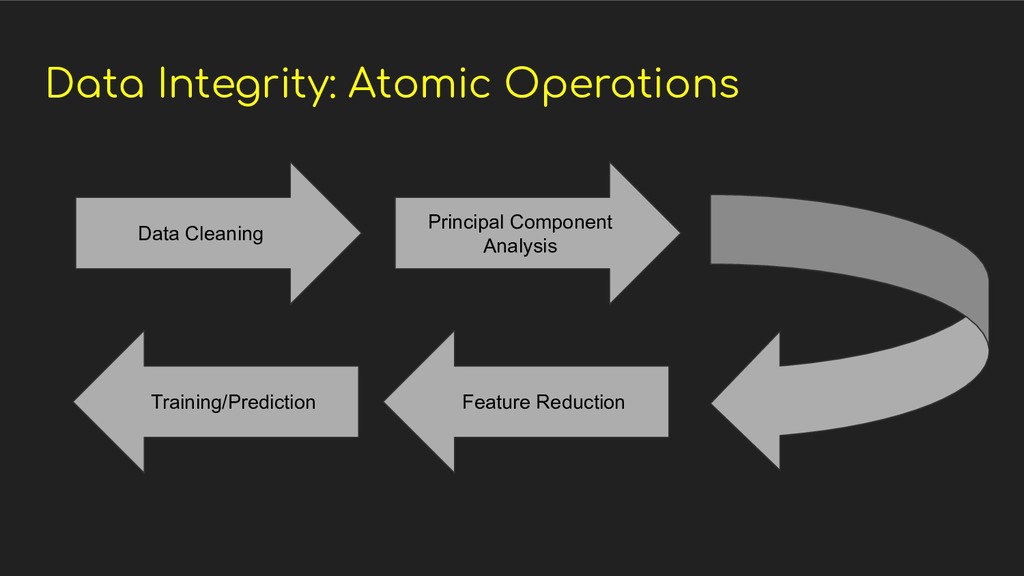
on: ◦ What are the data inputs for the algorithms? ◦ What are the data outputs/results? ◦ How will the data be transformed throughout its lifecycle • Python provides several libraries that can be utilized in data driven development like Data Classes
linters and automatic code formatting tools. - Conventions on function definitions and interfaces. - Code reviews - Use Type Hints and other tools that IDEs utilize
"""Version mismatch for algorithm""" class NotFittedException(Exception): """Model is not fitted""" class DataSizeException(Exception): """Invalid data size for training""" class NoTrainDataException(Exception): """No training data""" - Errors are clear and descriptive - Case to case basis
training • Memory needed for model storage • Consider the kind of algorithm the model uses • Sparse modeling usually performs well in smaller resource setup
(Decision Trees) ◦ Easy to implement, much simpler • Multiprocessing ◦ Provides more throughput ◦ Better for algorithms with high CPU consumption (NN) ◦ A lot more difficult to implement
-> None: self.model = RandomForestClassfier().fit(X, y) # Do some other stuff def predict(self, X: Iterable[FeatureData]) -> Iterable[LabelData]: result = self.model.predict(X) # Process result here return result
LOTS OF MATH! ◦ Grad school offers data science courses ◦ Usually one year straight courses • Find related jobs ◦ Internships ◦ Data engineering is not data science but close enough :P
import importlib.metadata, from concurrent.futures import ThreadPoolExecutor - Paradigm shifts - Functional support - Object oriented support - Rich library for application development - Micro service friendly structures
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Sample Interface class MyModel(ModelInterface): def fit(self, X: Iterable[FeatureData], y: Iterable[LabelData])](https://files.speakerdeck.com/presentations/e595e292ea434ba7ae0634114f3933cb/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}