2026/3/12『Database Engineering Meetup #9: NewSQL』
プリンシパル分散システムエンジニア 上田 義明(bootjp)
P41の動画リンク
https://docs.google.com/file/d/1Eu8rRDMxl3LQy6KM6MRuJrvhobe3AF9c/preview
P42の動画リンク
https://docs.google.com/file/d/1XbJWAKTabMQJqrPPWn6LNi1IYA6omfGh/preview
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
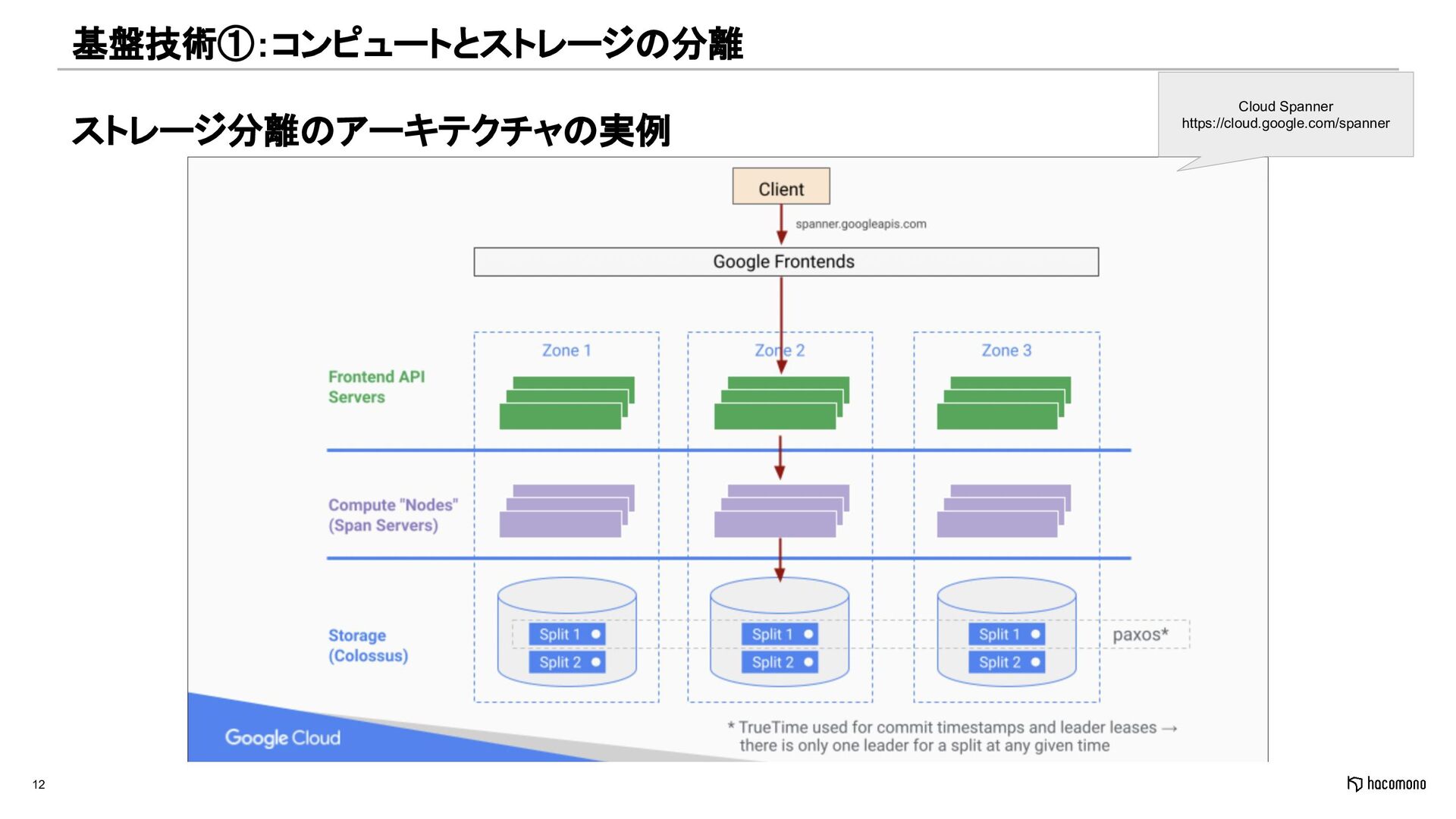{kind=link}
{kind=link}
{kind=link}
{kind=link}
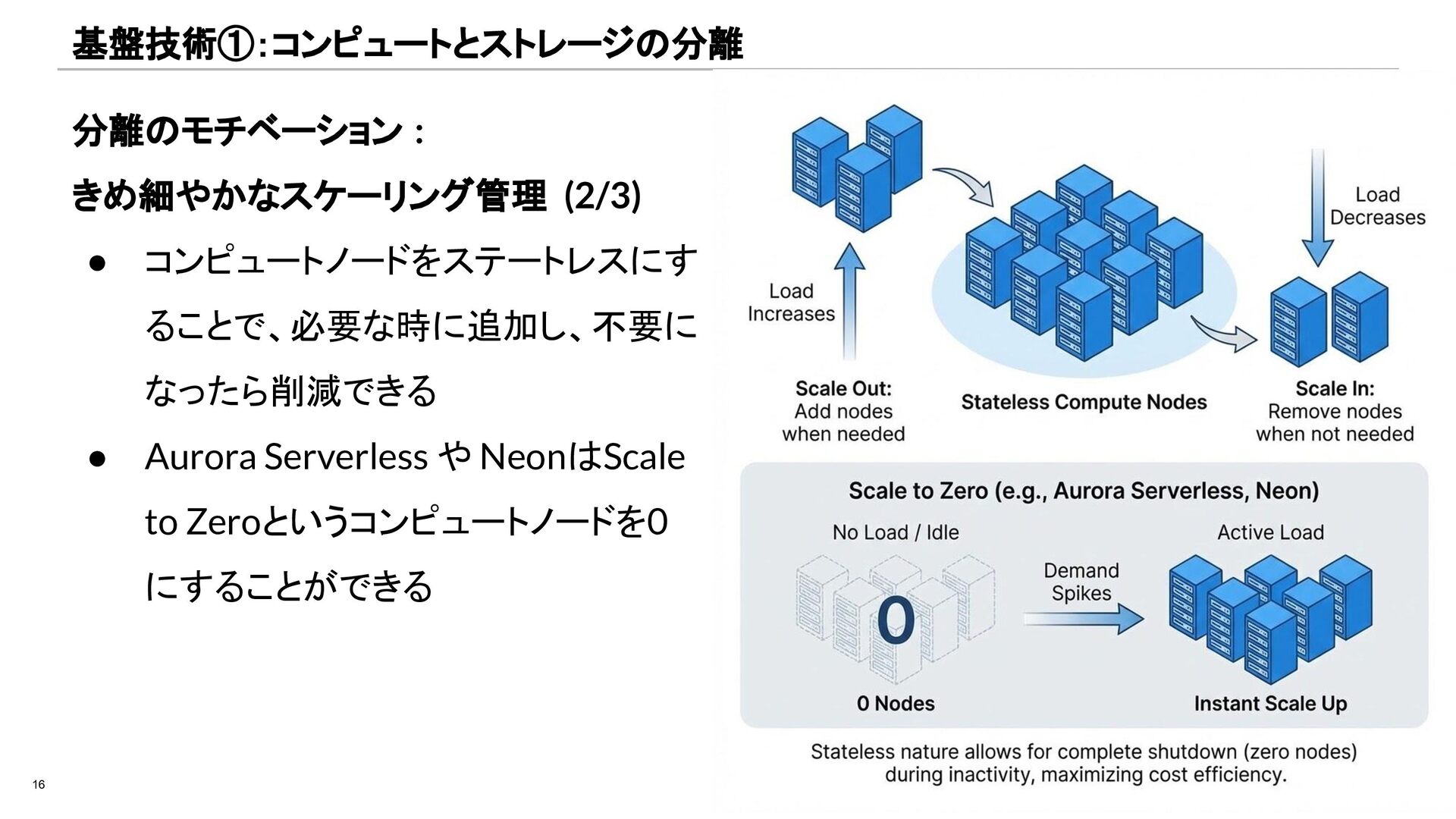{kind=link}
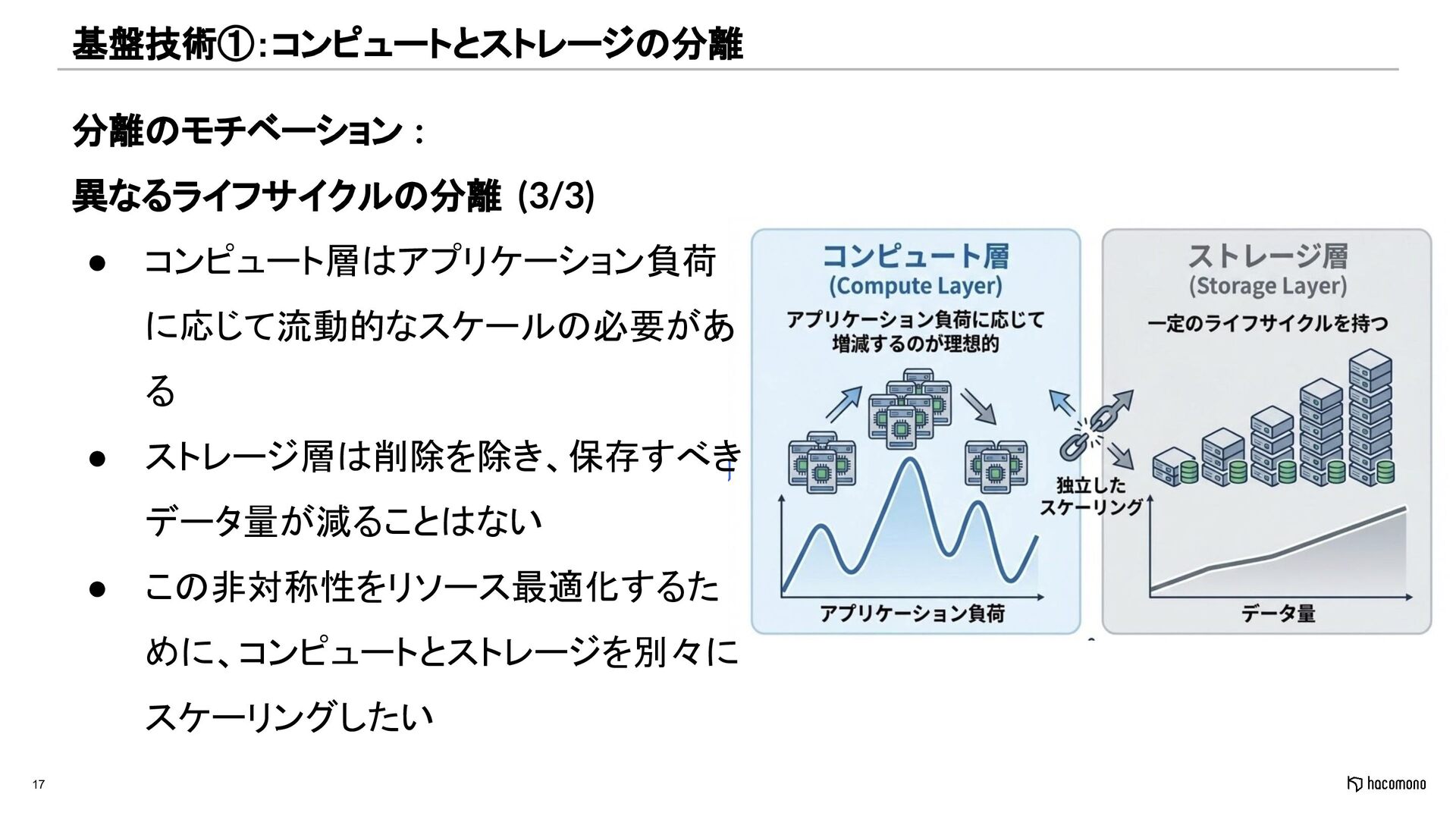{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
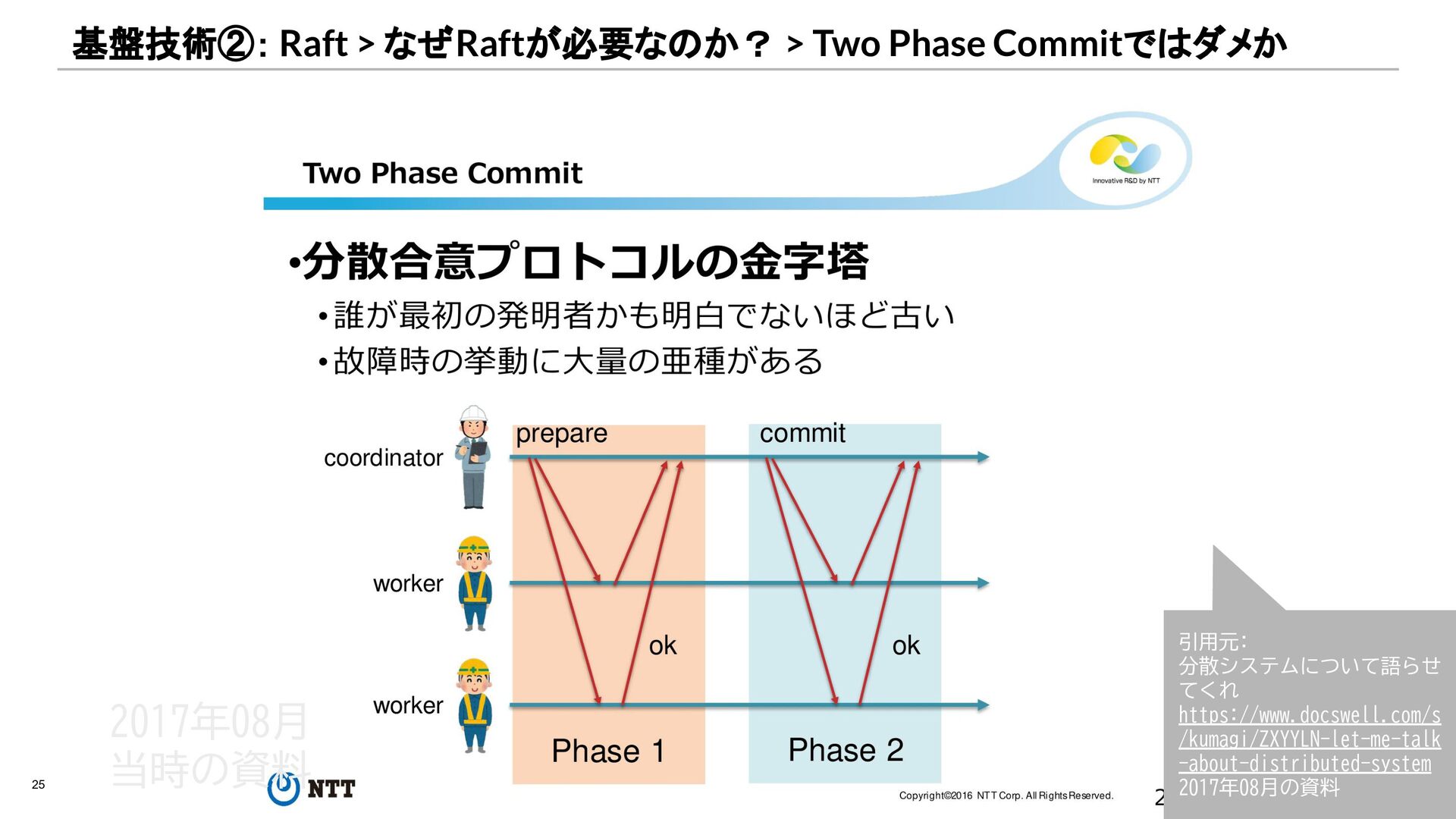{kind=link}
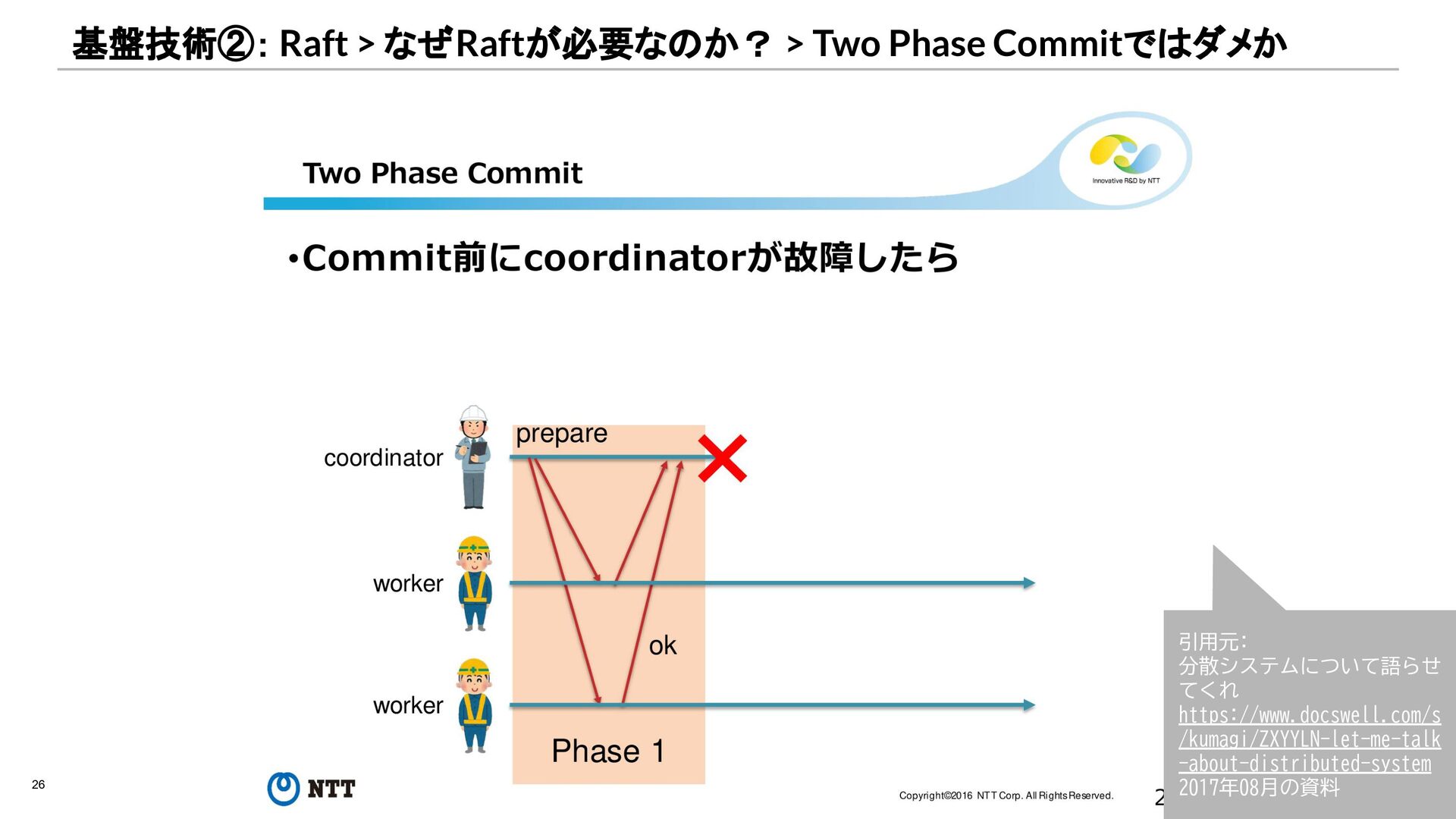{kind=link}
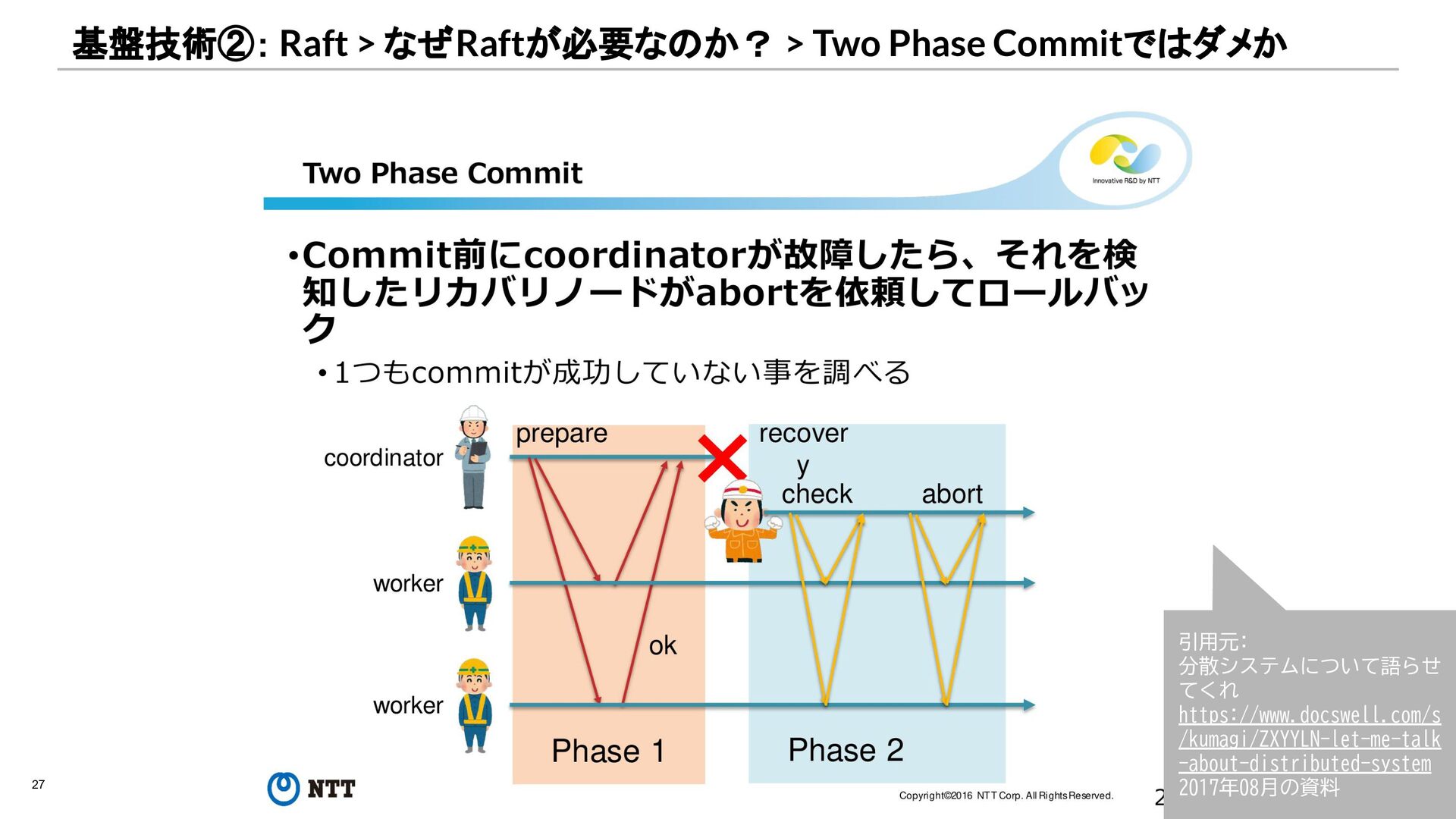{kind=link}
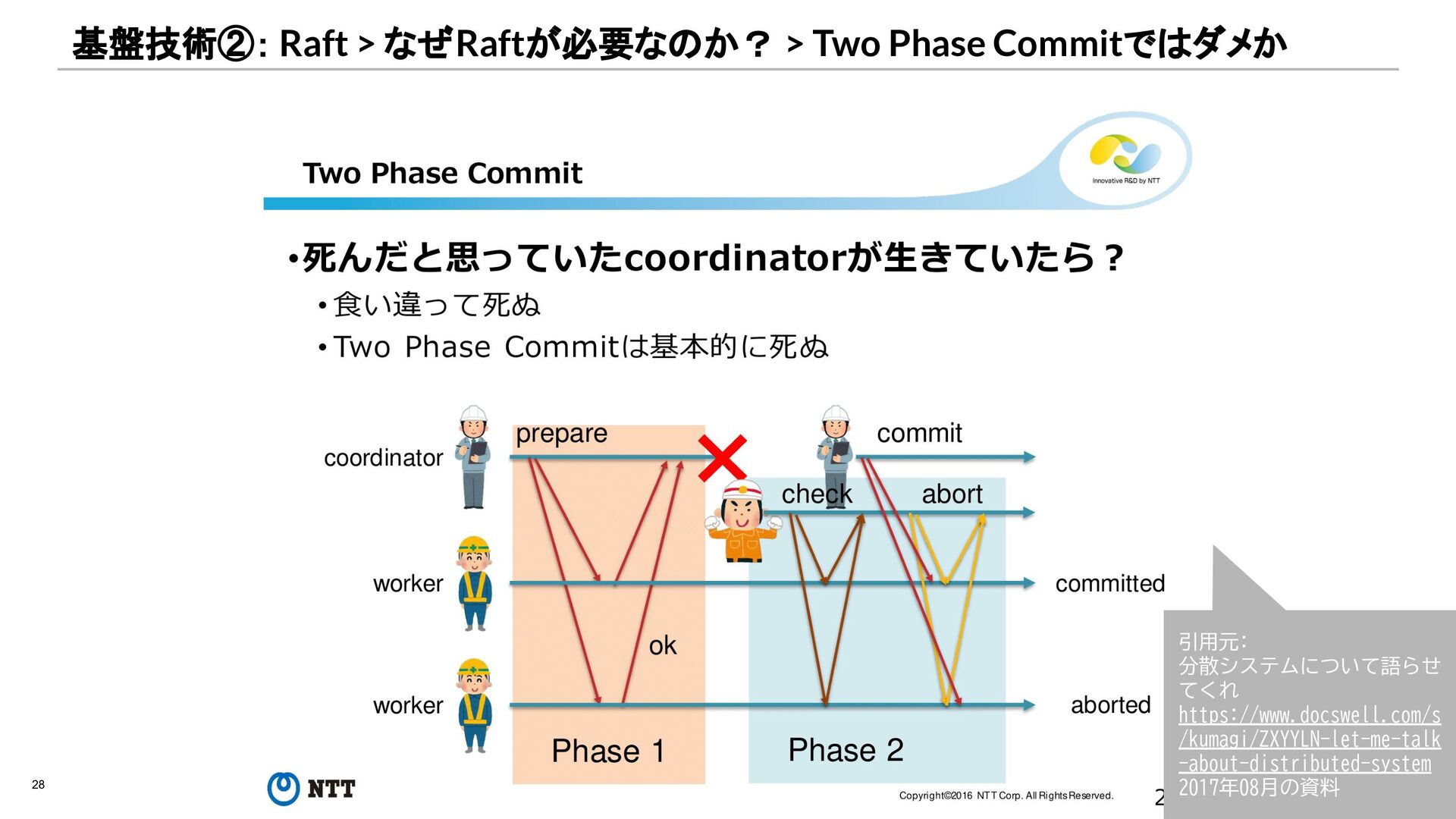{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
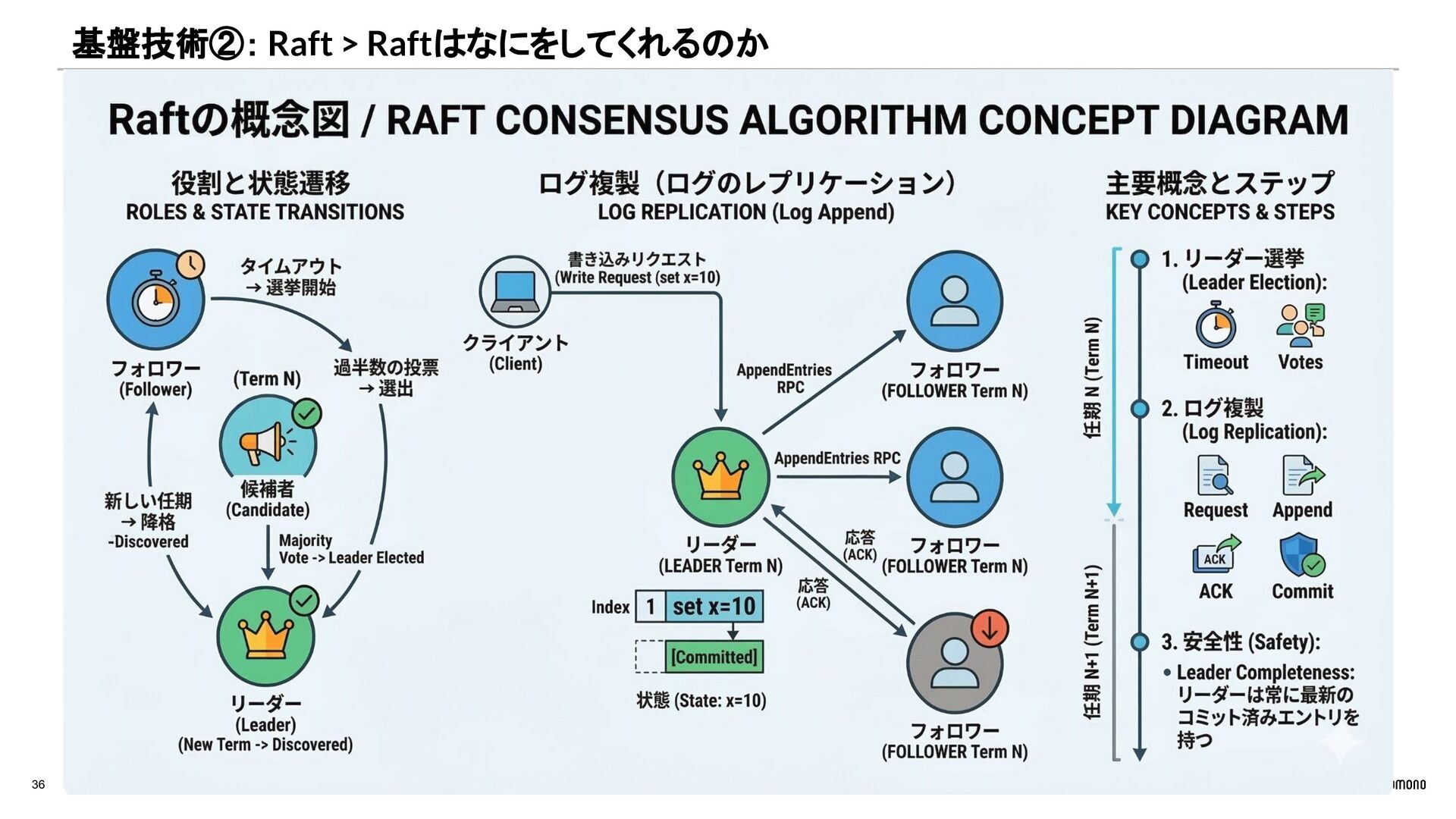{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}