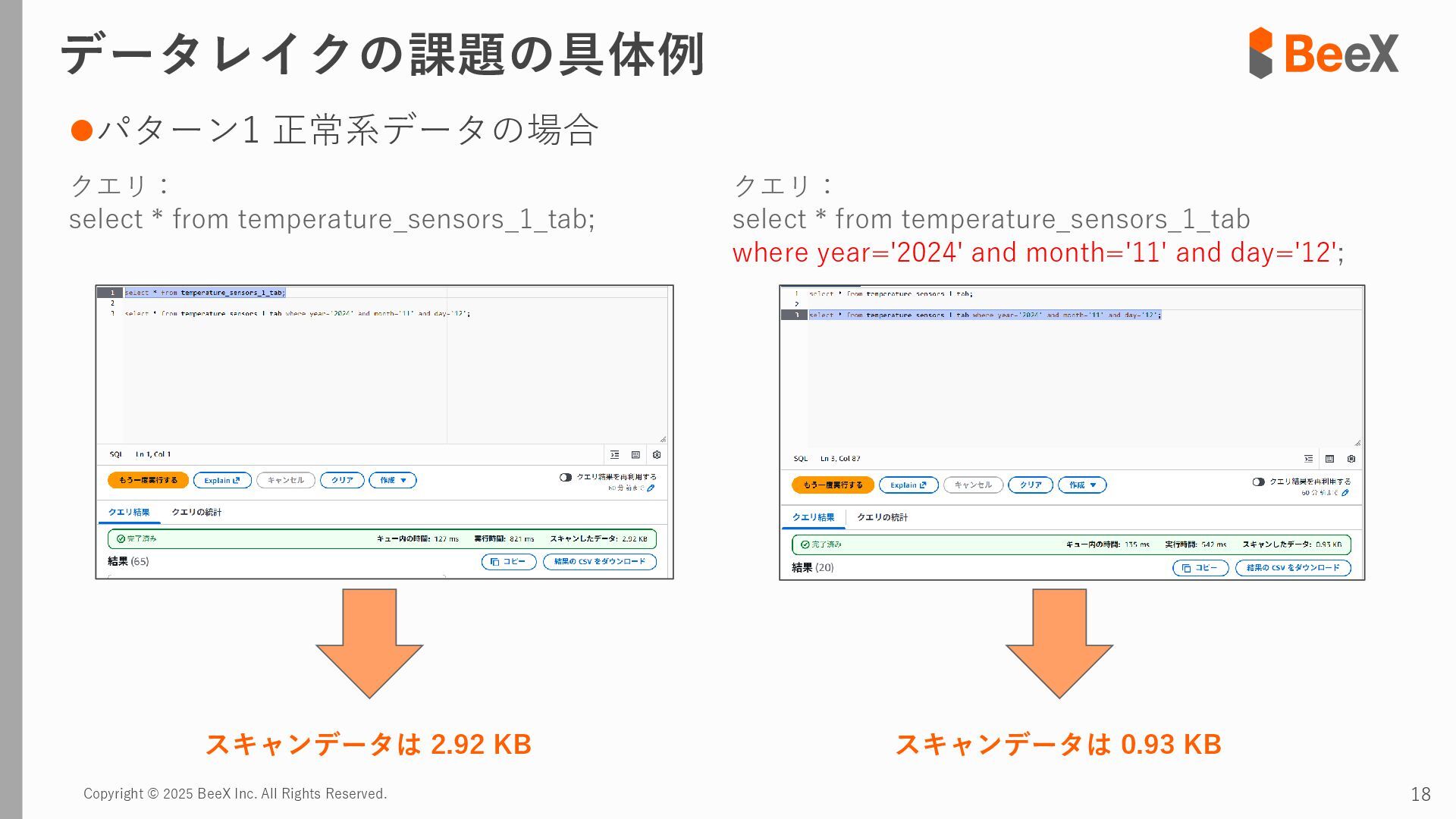
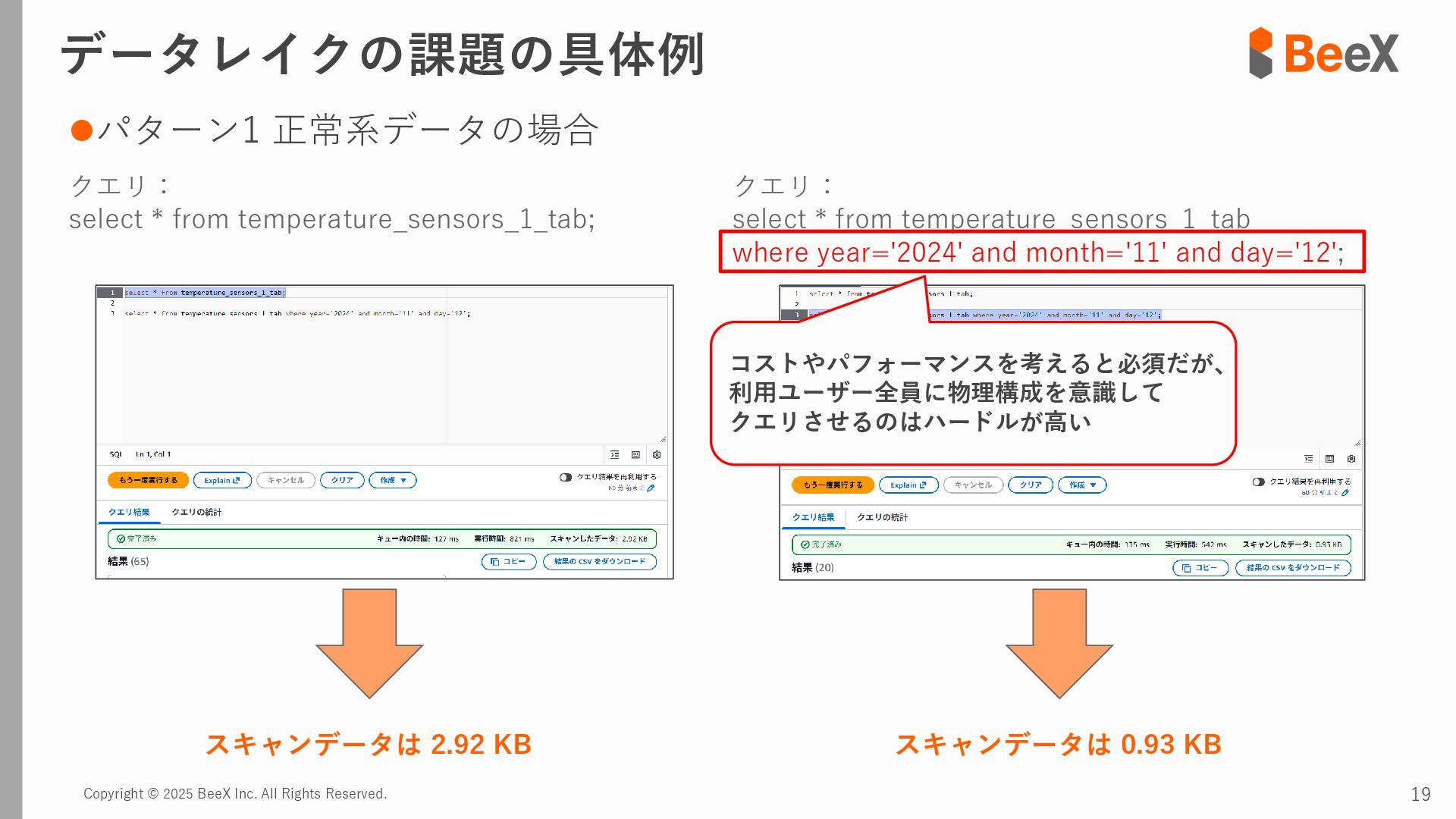
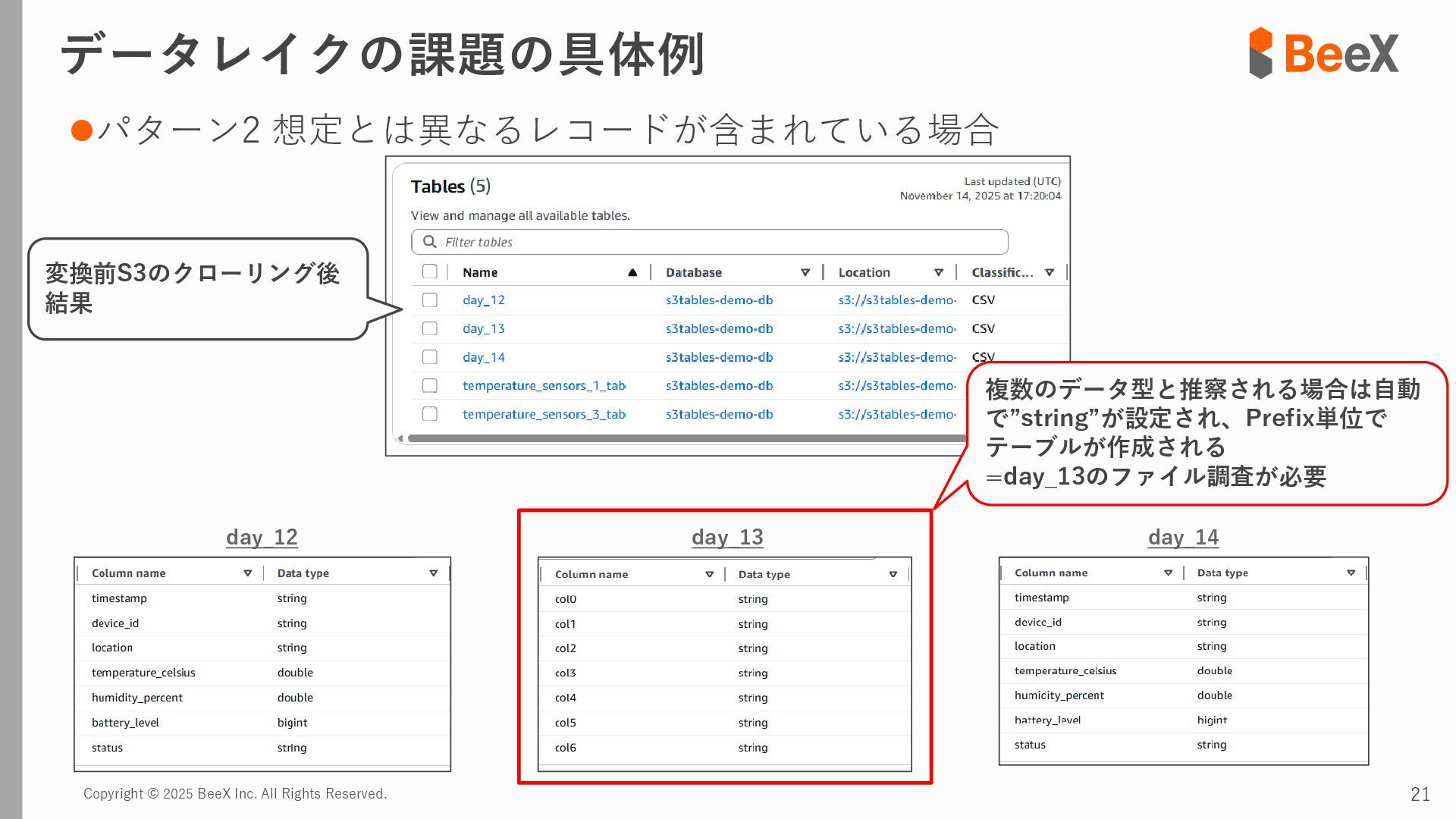
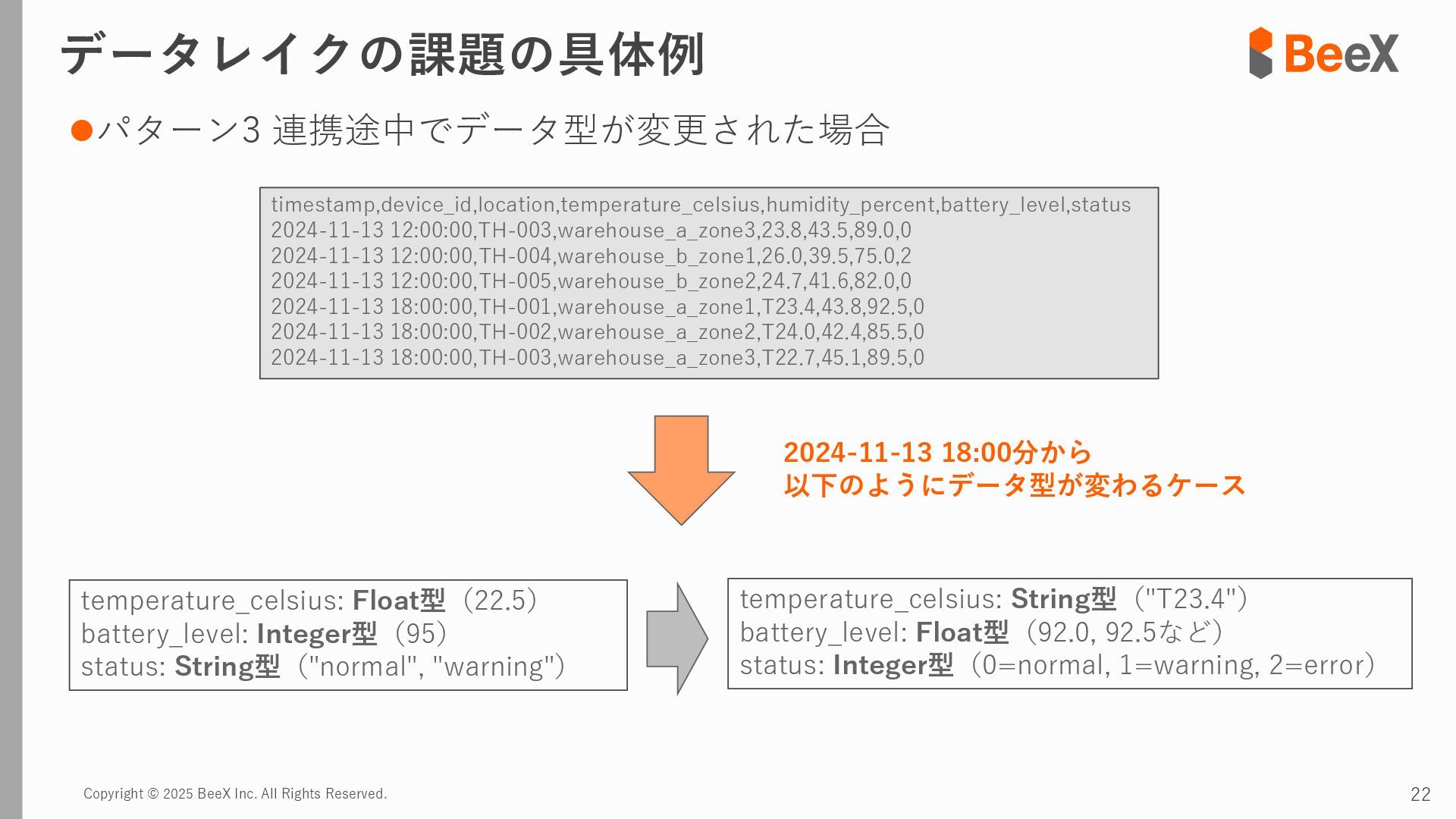
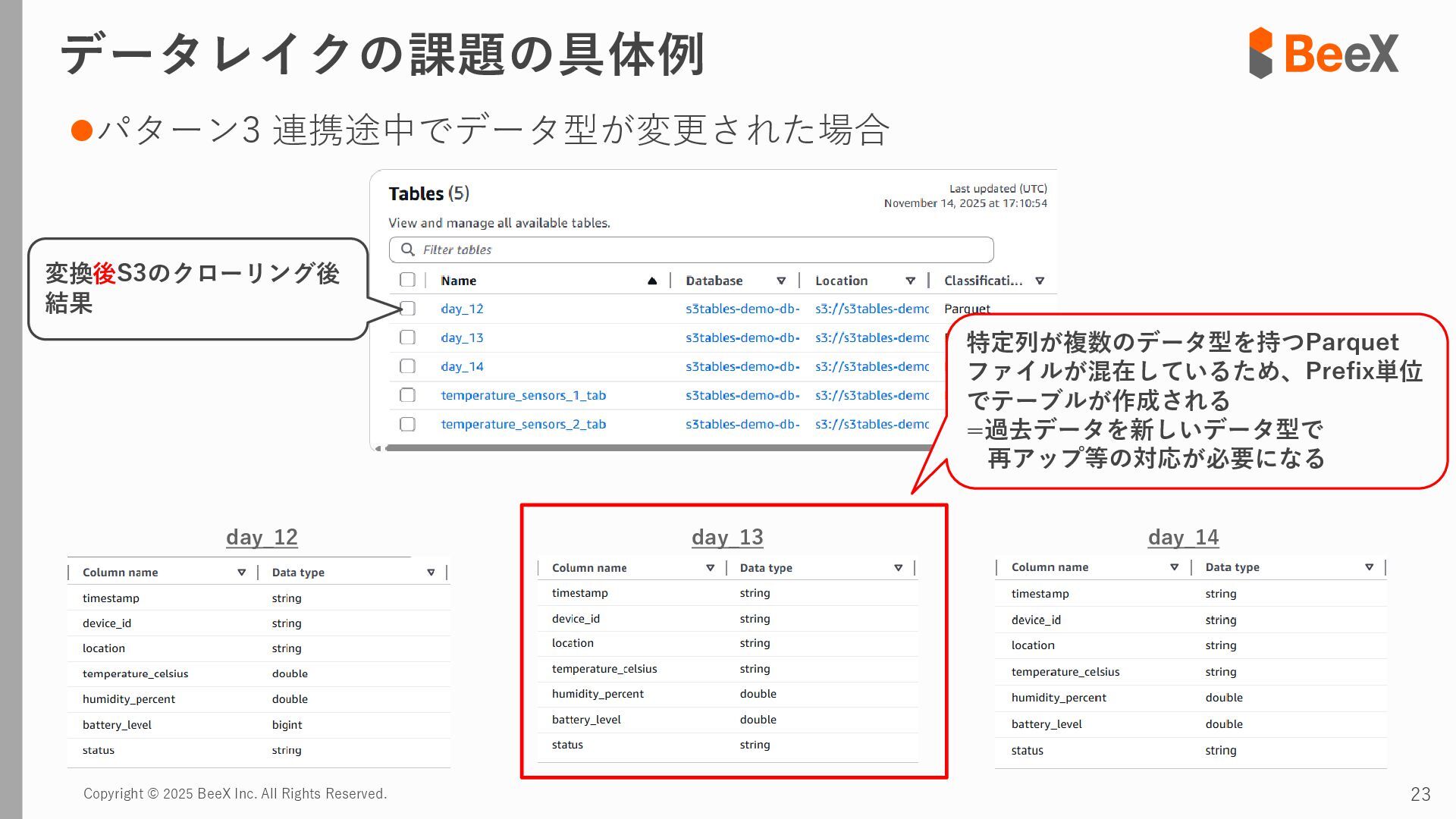
⚫パターン3 連携途中でデータ型が変更された場合 timestamp,device_id,location,temperature_celsius,humidity_percent,battery_level,status 2024-11-13 12:00:00,TH-003,warehouse_a_zone3,23.8,43.5,89.0,0 2024-11-13 12:00:00,TH-004,warehouse_b_zone1,26.0,39.5,75.0,2 2024-11-13 12:00:00,TH-005,warehouse_b_zone2,24.7,41.6,82.0,0 2024-11-13 18:00:00,TH-001,warehouse_a_zone1,T23.4,43.8,92.5,0 2024-11-13 18:00:00,TH-002,warehouse_a_zone2,T24.0,42.4,85.5,0 2024-11-13 18:00:00,TH-003,warehouse_a_zone3,T22.7,45.1,89.5,0 temperature_celsius: Float型(22.5) battery_level: Integer型(95) status: String型("normal", "warning") temperature_celsius: String型("T23.4") battery_level: Float型(92.0, 92.5など) status: Integer型(0=normal, 1=warning, 2=error) 2024-11-13 18:00分から 以下のようにデータ型が変わるケース
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
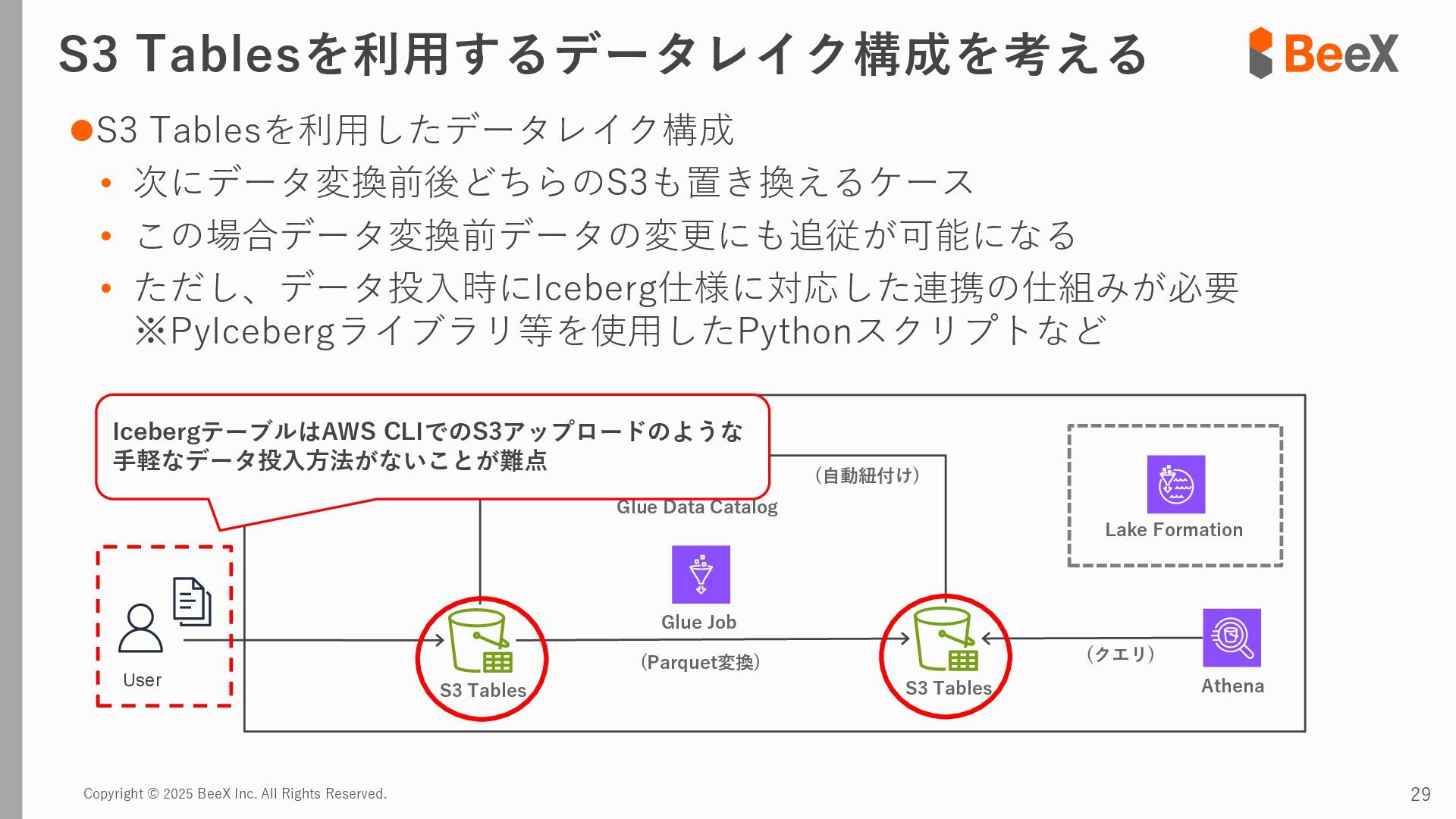{kind=link}
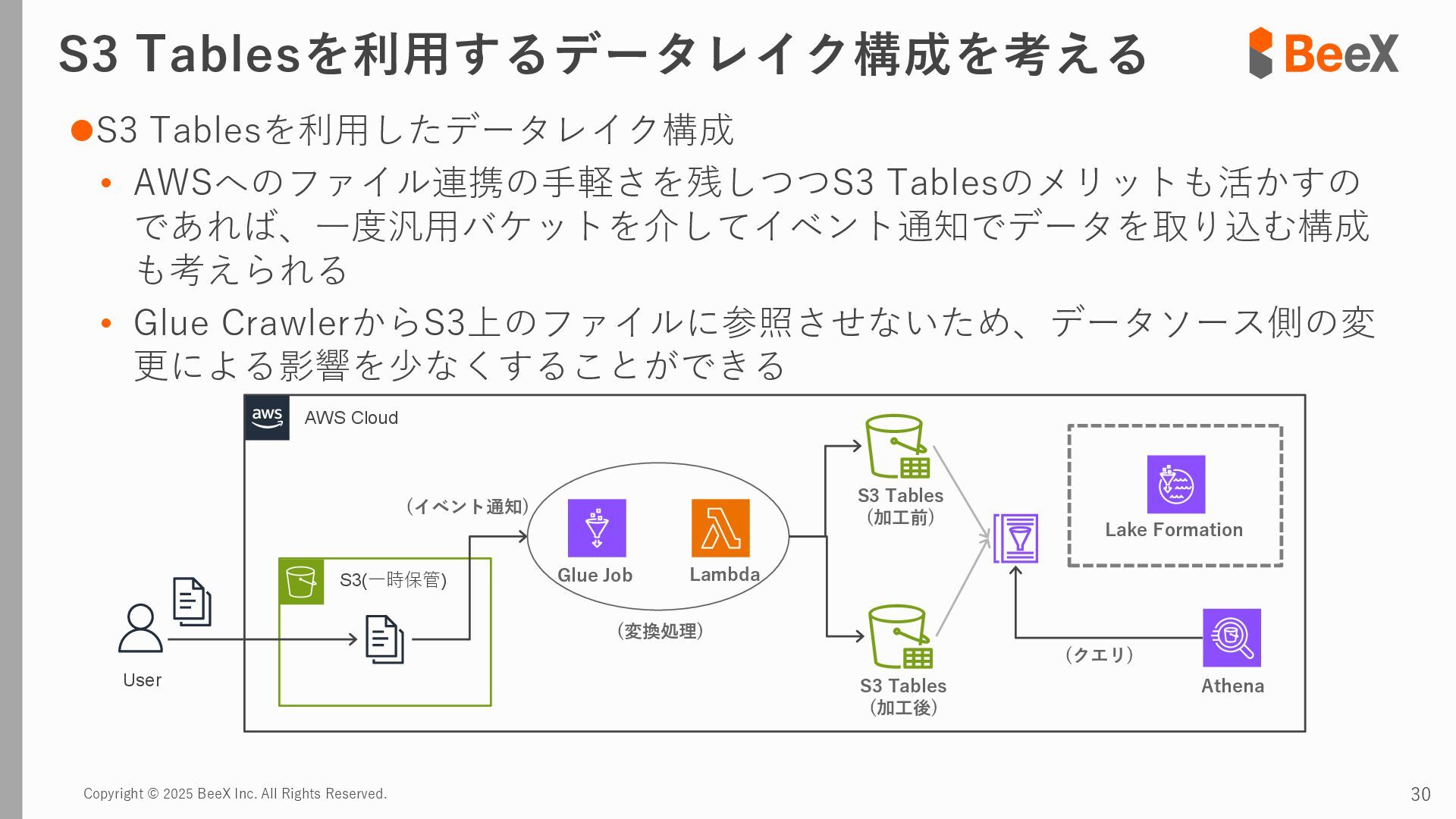{kind=link}
{kind=link}
{kind=link}
{kind=link}