Open source AI is being defined as I write this. What would that mean for innersource initiatives? Would the data to train the foundational models be themselves open source (internally atleast) and what are the consequences of doing that. This talk is a to expand the conversation the OSI is having with Open Source AI but with an Inner Source slant.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
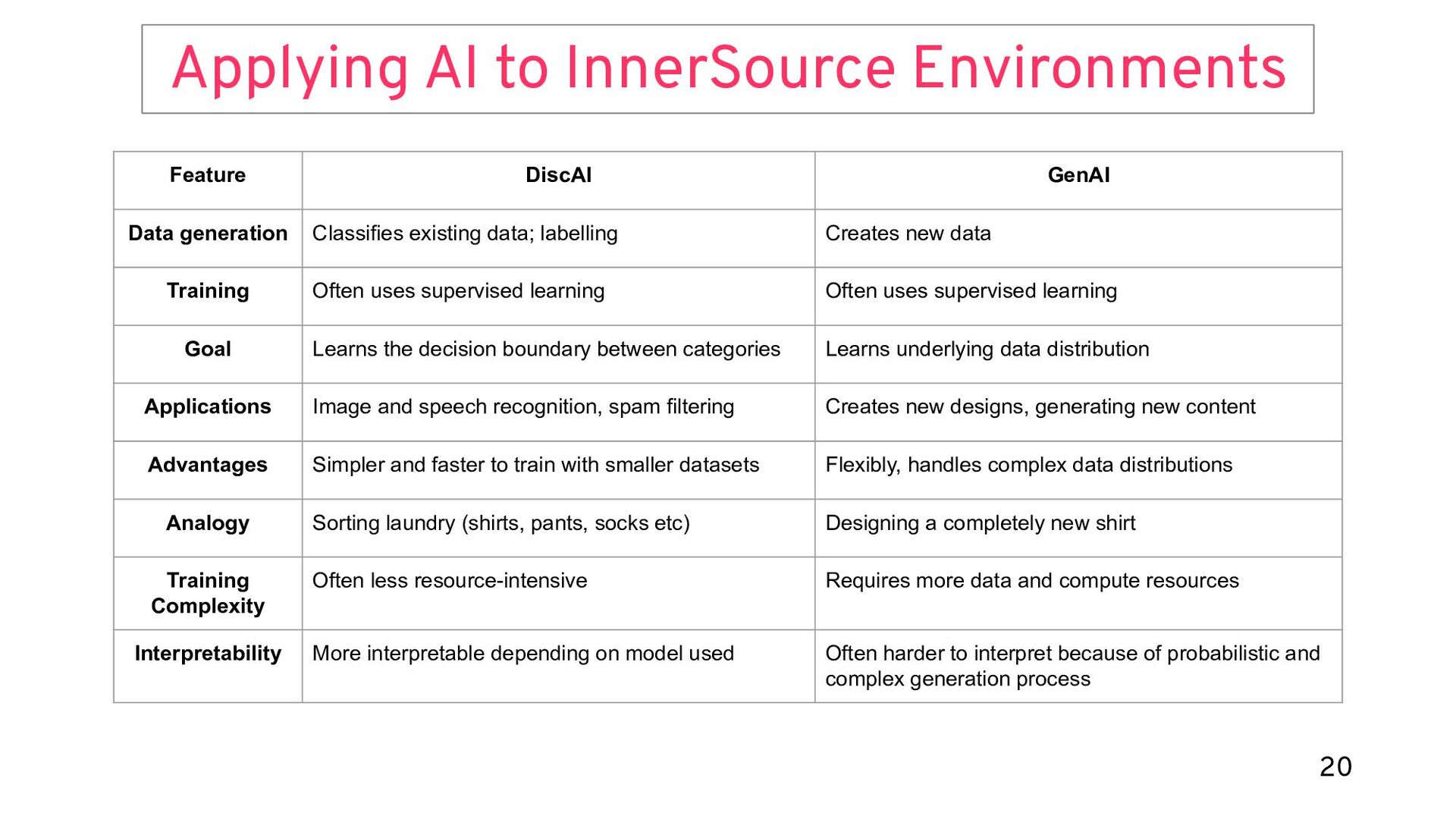{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Comments? Harish Pillay 9V1HP @harishpillay@floss.social, [email protected] Slides on speakerdeck.com](https://files.speakerdeck.com/presentations/5f8fcbd1537342b48f9a78eaa4fa1a78/slide_29.jpg){kind=link}