【講演内容】
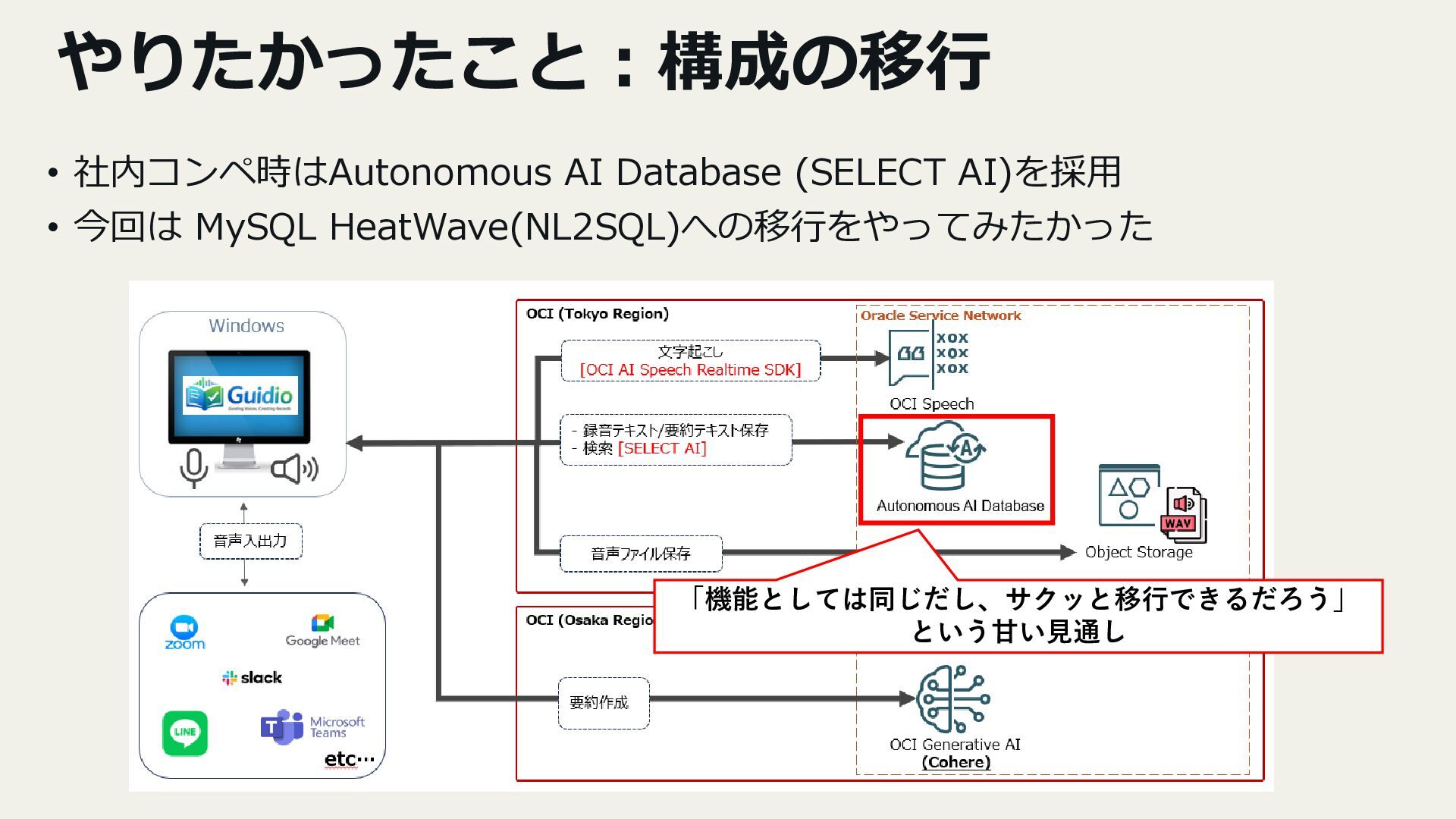
今年2月に社内のAIコンペがあり、出場作品として「先生が学生を指導したときの会話音声から学生指導記録を生成する」というツールを、
OCI Speech / OCI Generative AI といったサービスと連携させ開発しました。
本セッションでは、MySQL HeatWave GenAIの機能の一つであるNL2SQL機能を実際に組み込んでみてのポイントや感想などをご紹介します。
1. 検証アプリと構成概要
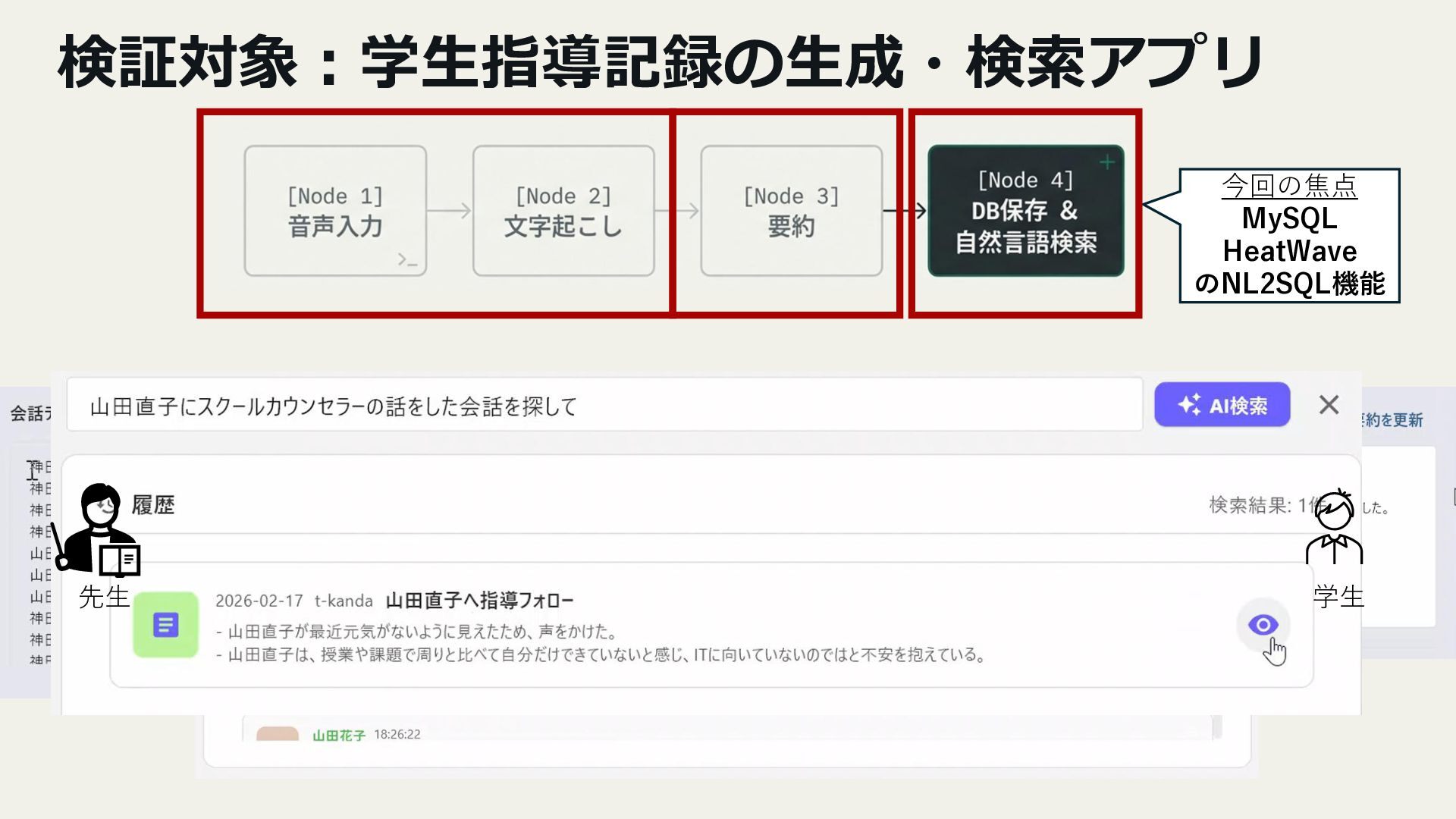
- 学生指導記録の生成・検索アプリ
- Autonomous Database(SELECT AI)からHeatWaveへの移行検証
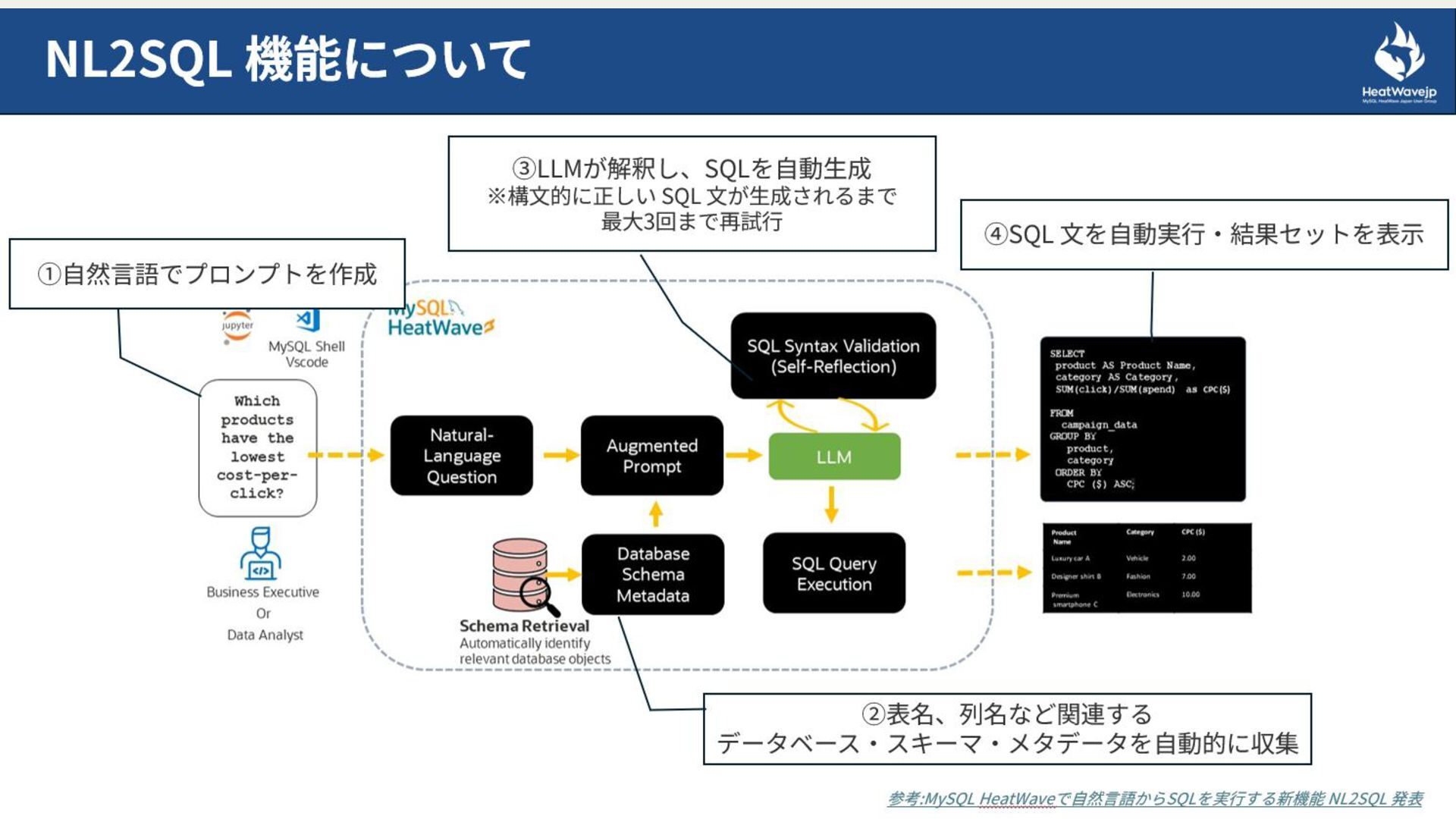
2. NL2SQL機能の概要と利用環境
- 自然言語からSQL生成・実行の仕組み
- 利用したモデル・HeatWave構成
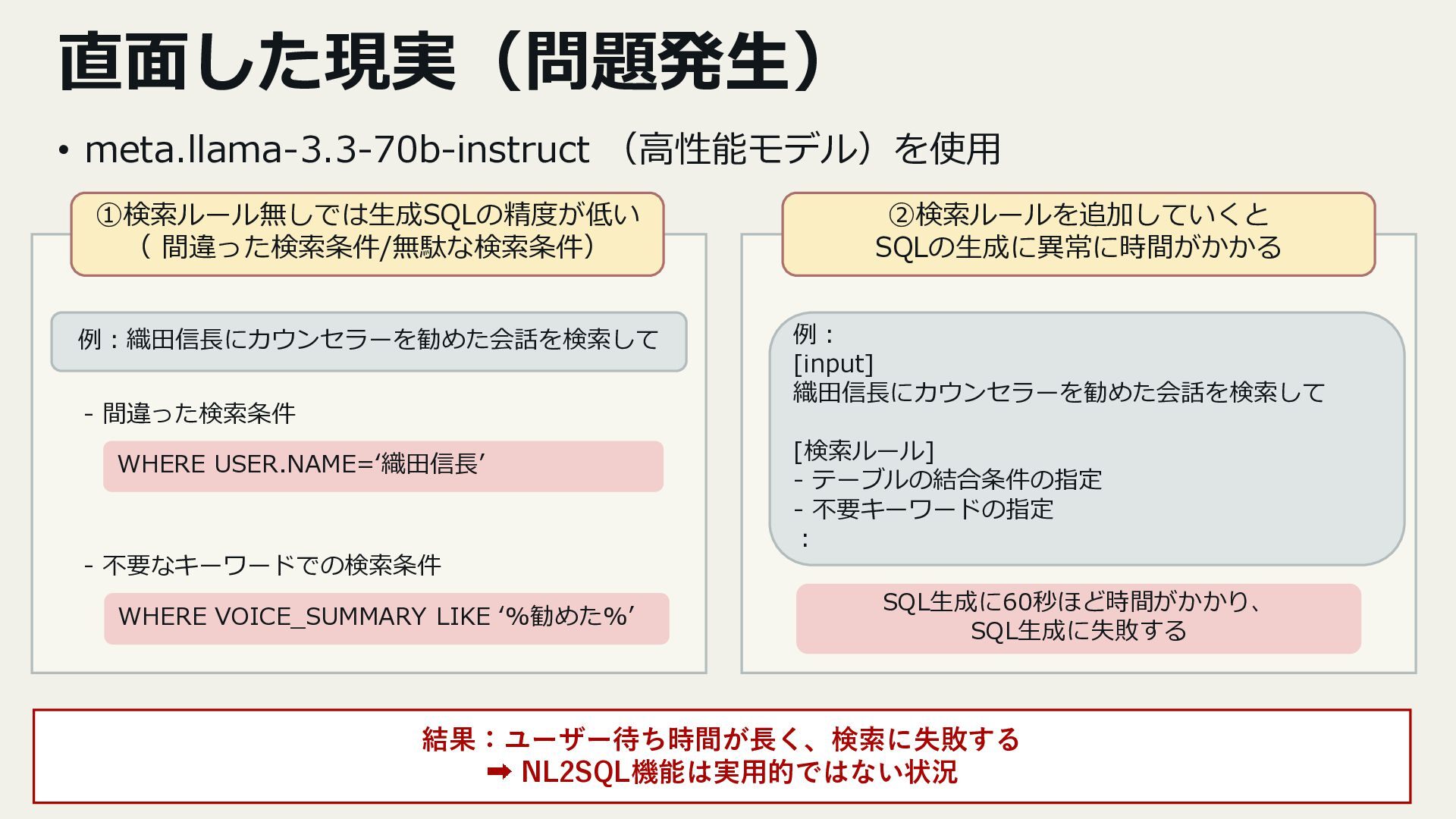
3. 実装で直面した課題
- SQL生成精度の低さと処理時間の課題
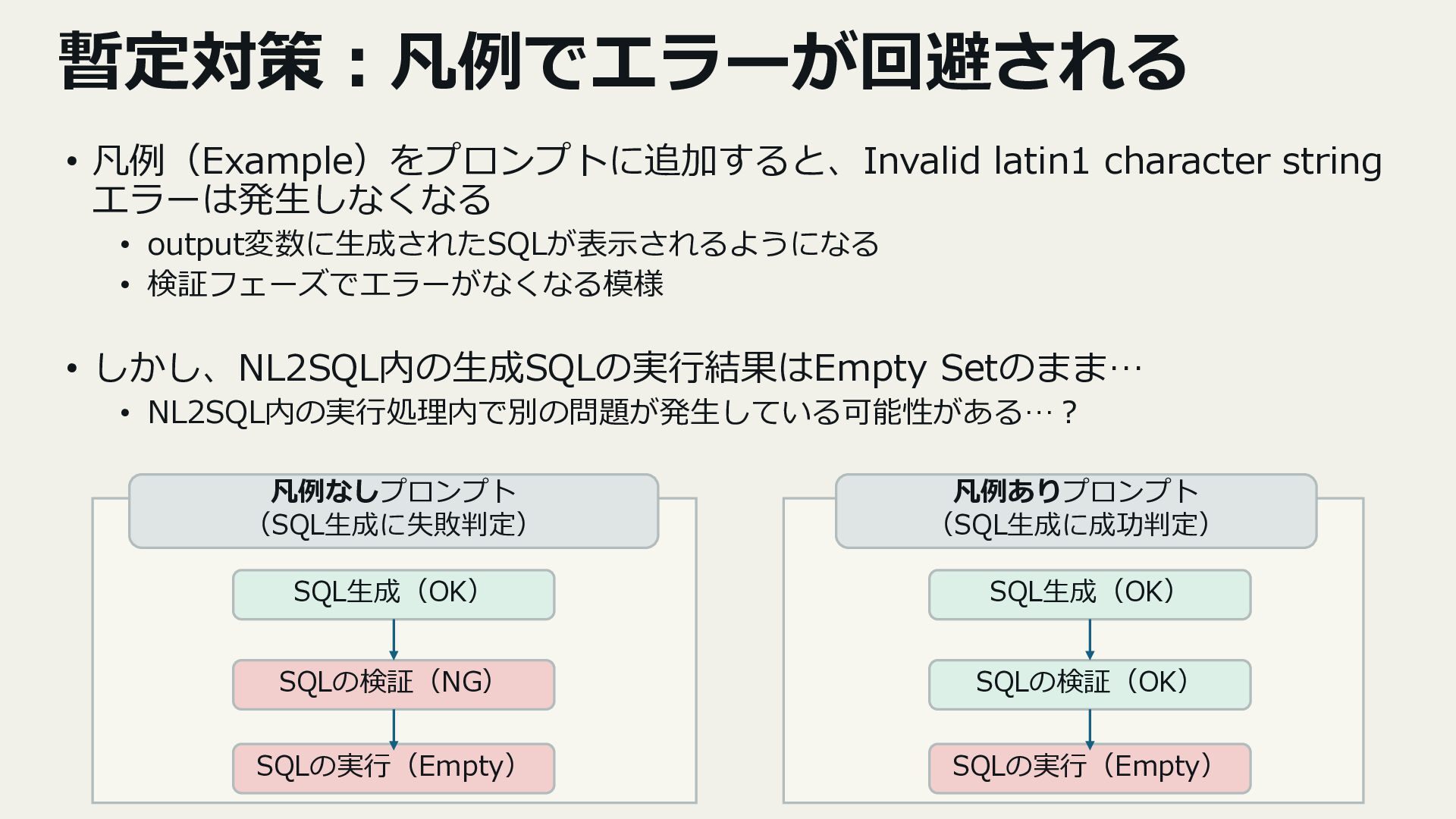
- 日本語検索時のエラー(文字コード問題など)
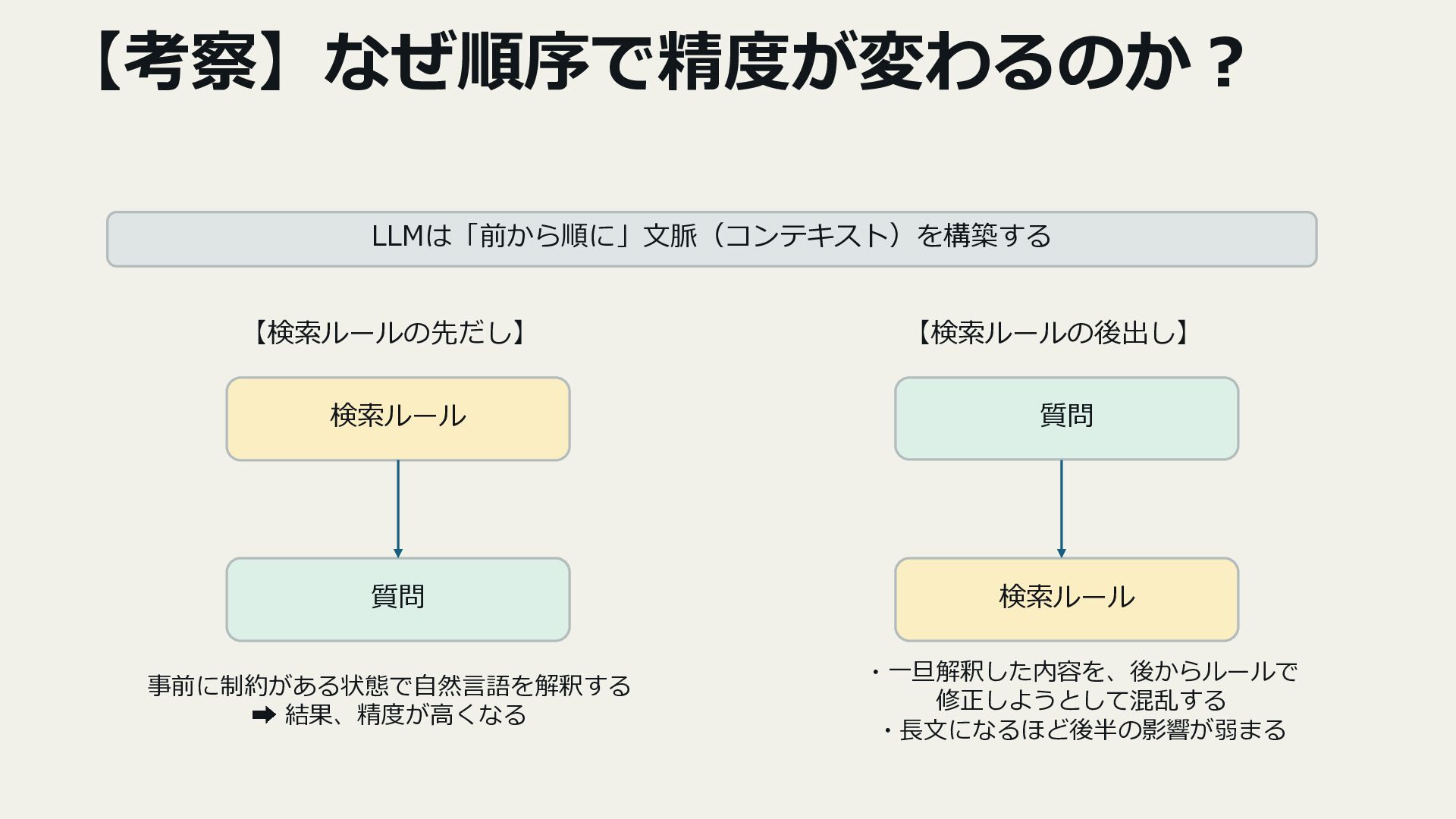
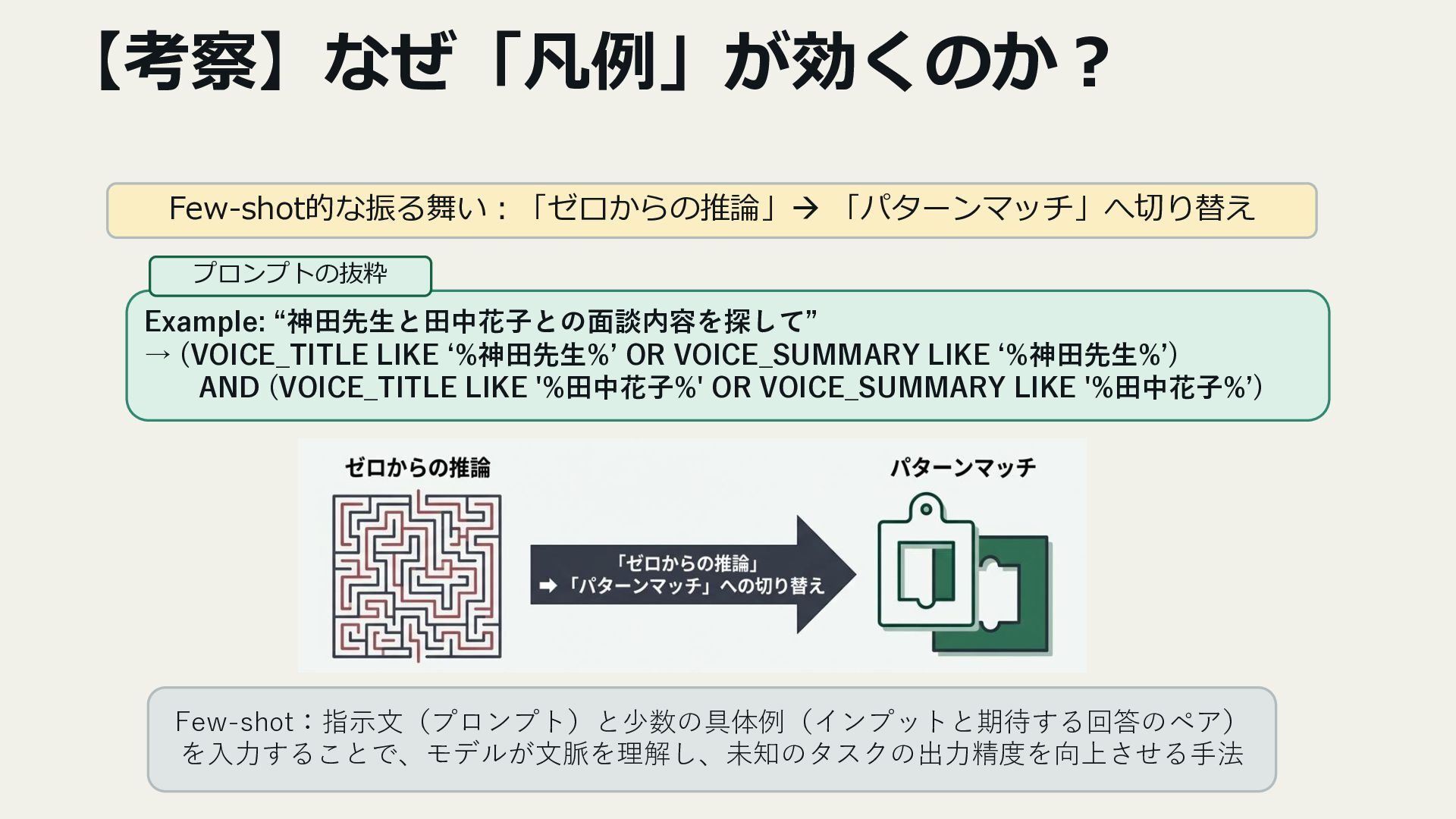
4. 改善アプローチとポイント
- プロンプト設計(検索ルールの先出し・Few-shot例)
- モデル選定による精度・速度改善
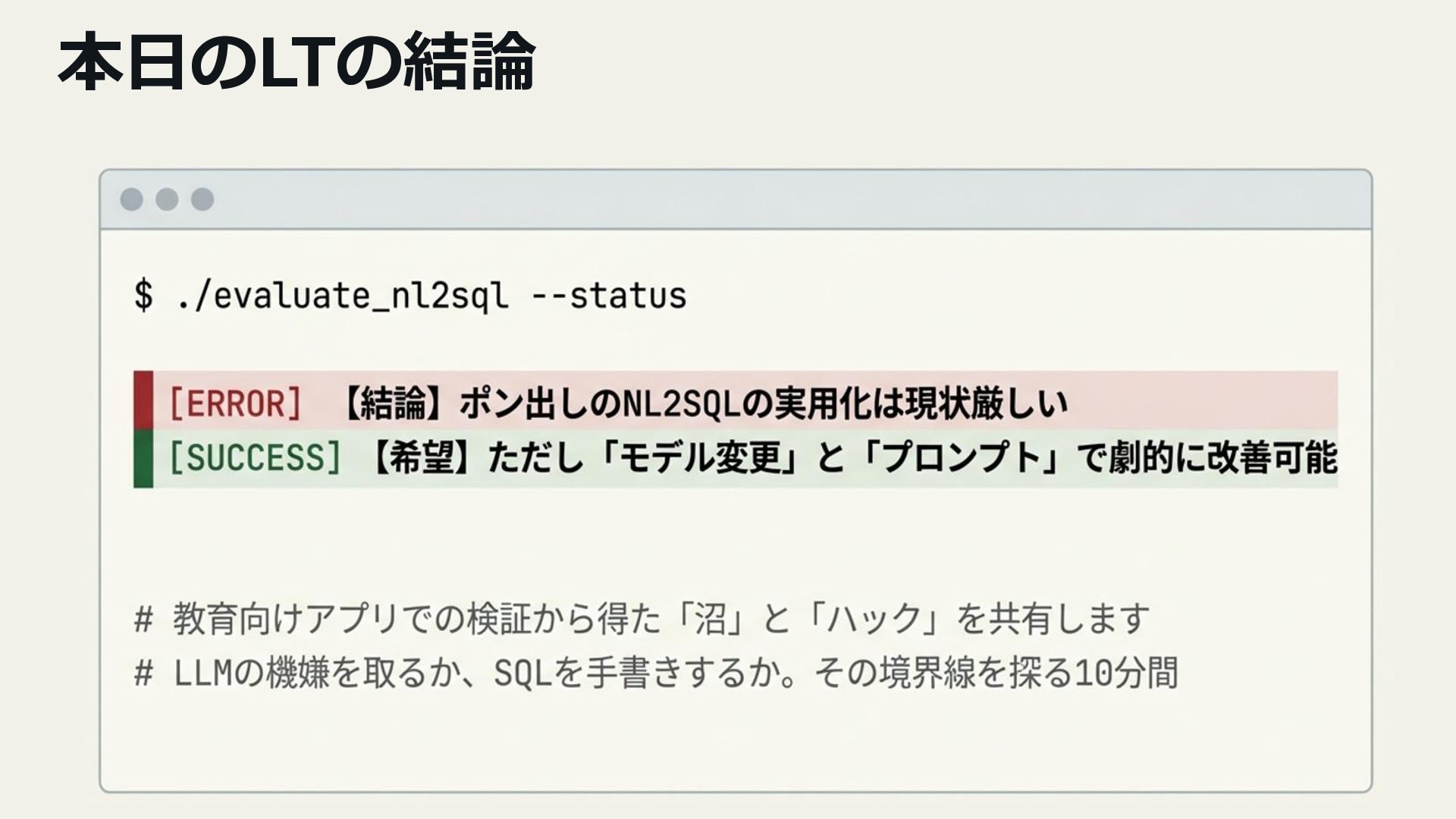
5. 検証結果と今後の展望
- NL2SQLの現状評価と実用性
- AI活用における設計・チューニングの重要性
【発表者】
株式会社パソナデータ&デザイン
データテクノロジー本部 データベース部
神田 智大 氏
【イベント情報】
HeatWavejp Meetup #18
https://heatwavejp.connpass.com/event/387800/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![改善策②:プロンプトの最適化 [Block 1] 検索ルール – 先だしの鉄則 [Block 2] 凡例(Few-shot Example)](https://files.speakerdeck.com/presentations/45c4d6963aba40e7af1f80612d33c239/slide_9.jpg){kind=link}
![[Search Rules] If the keyword is a person's name, do](https://files.speakerdeck.com/presentations/45c4d6963aba40e7af1f80612d33c239/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}