前回の達成目標
今回の達成目標
データセットの可視化
とりあえず今日は実行できれば OK としよう!
主成分分析 (PCA) とは?
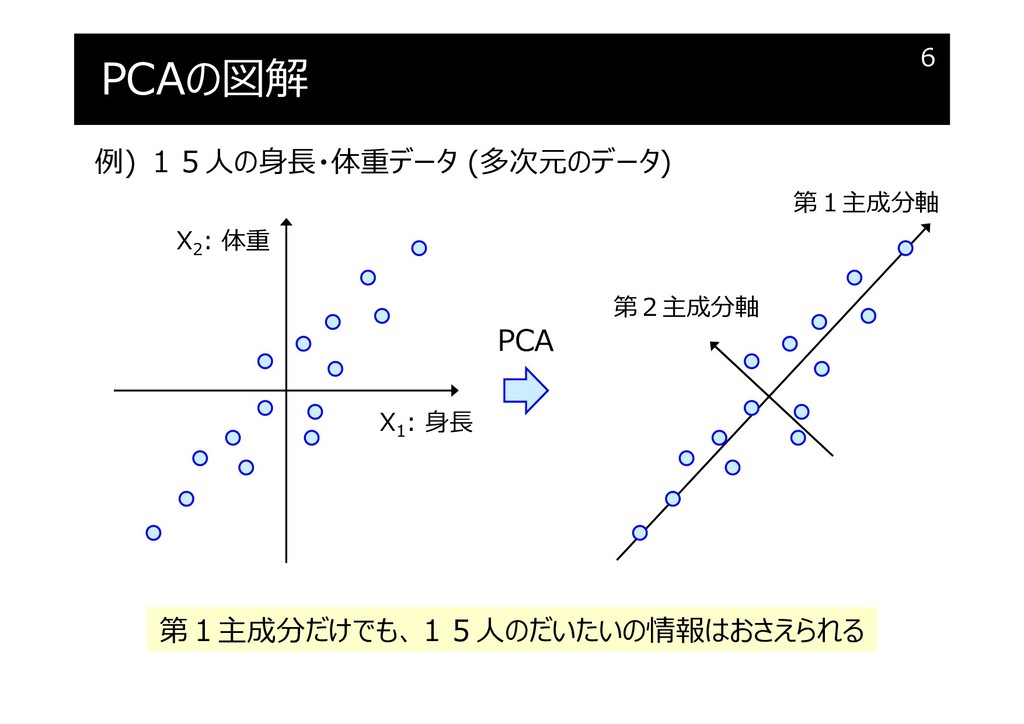
PCAの図解
PCAで できること
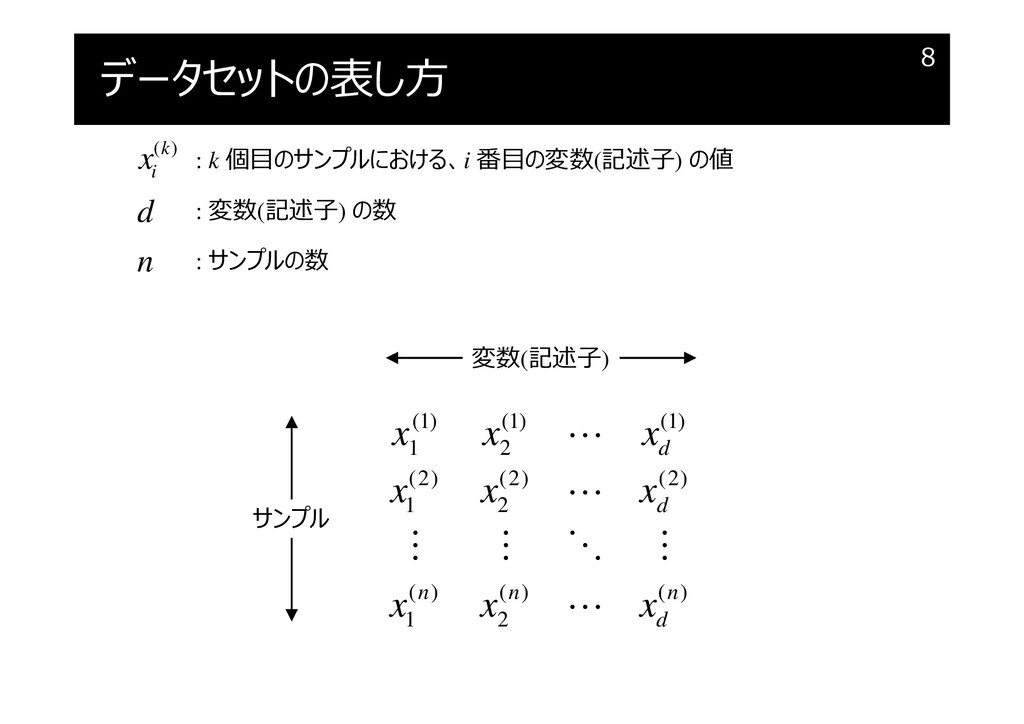
データセットの表し方
PCAの前に
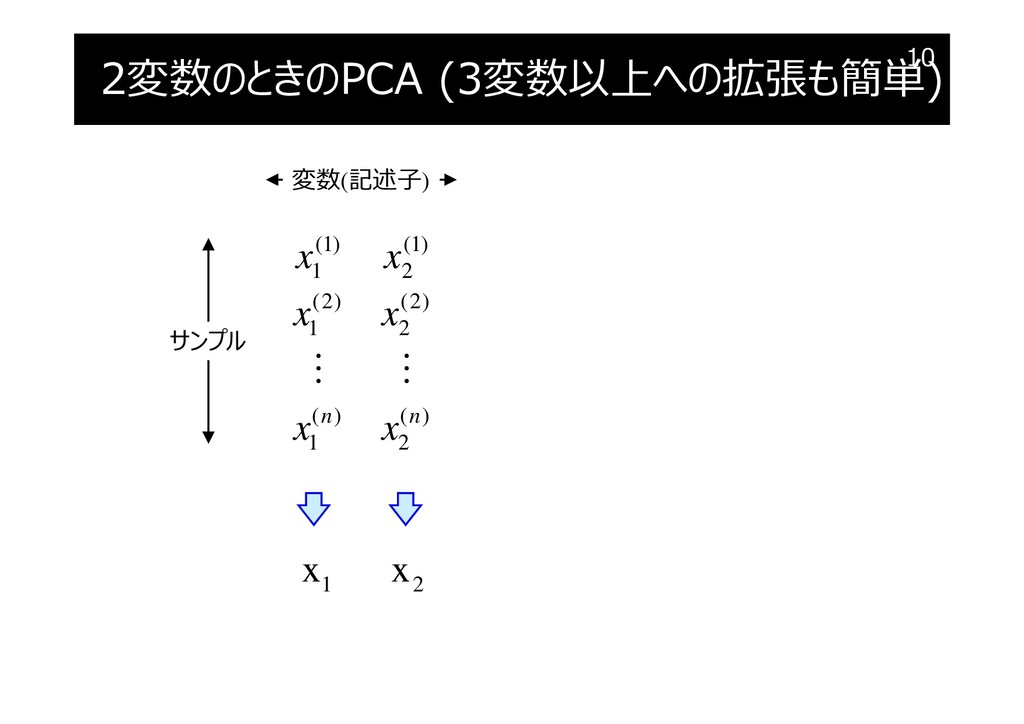
2変数のときのPCA (3変数以上への拡張も簡単)
主成分とローディング
行列で表すと・・・
第1主成分を考える
ローディングの規格化条件
主成分の分散を最大化
Sを最大化するローディングを求める
Lagrangeの未定乗数法
Gを偏微分して 0
行列で表す
固有値問題へ
寄与率
累積寄与率
PCA を実行してみよう!
t-SNE とは?
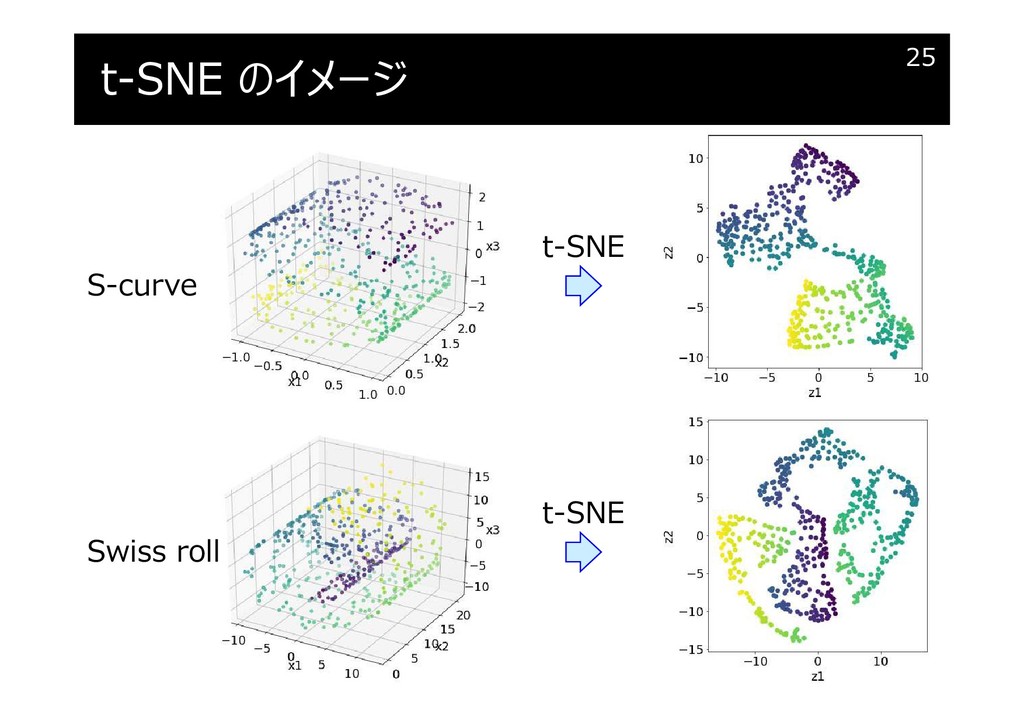
t-SNE のイメージ
文字の定義
データの前処理
t-SNEでは何をしているか?
p(x(i), x(j)) って何?
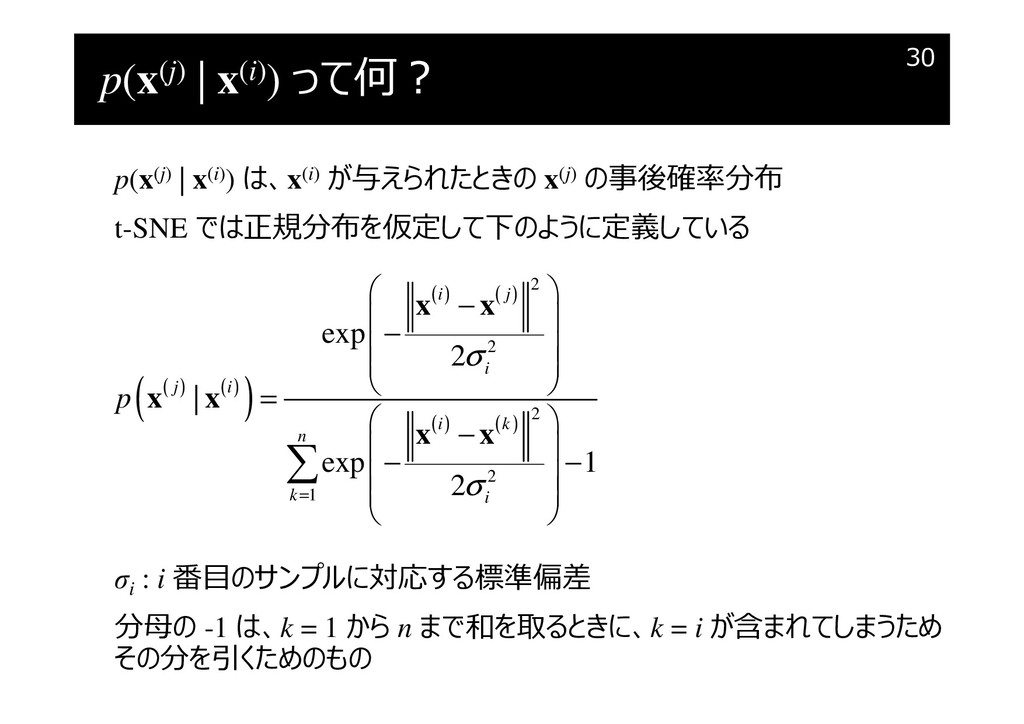
p(x(j) | x(i)) って何?
x(i) と x(j) の距離と p(x(i), x(j)) の関係
p(x(i) | x(j)) の σi はどうする?
p(z(i), z(j)) って何?
p(z(i), z(j)) の式
目的関数 C の最小化
z(i) の初期値
perplexity をどう決めるか?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![p(z(i), z(j)) の式 34 t-SNE では自由度1の (スチューデントの) t 分布 [1]](https://files.speakerdeck.com/presentations/76b2eca2542340629bc4be21b58371ff/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}