前回の達成目標
今回の達成目標
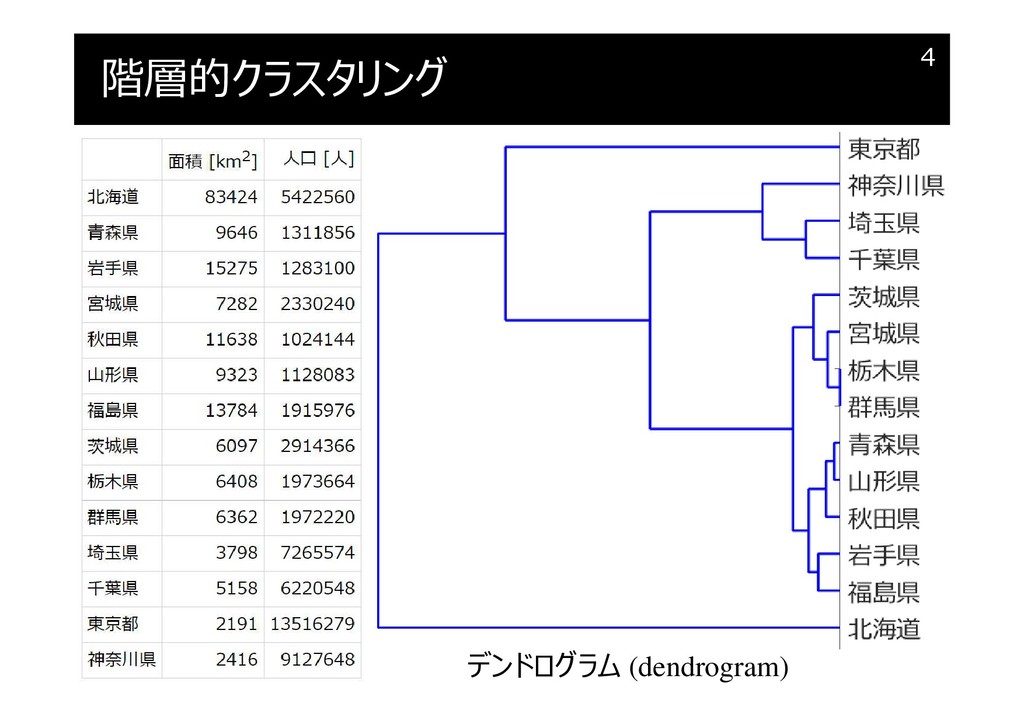
クラスタリング
階層的クラスタリング
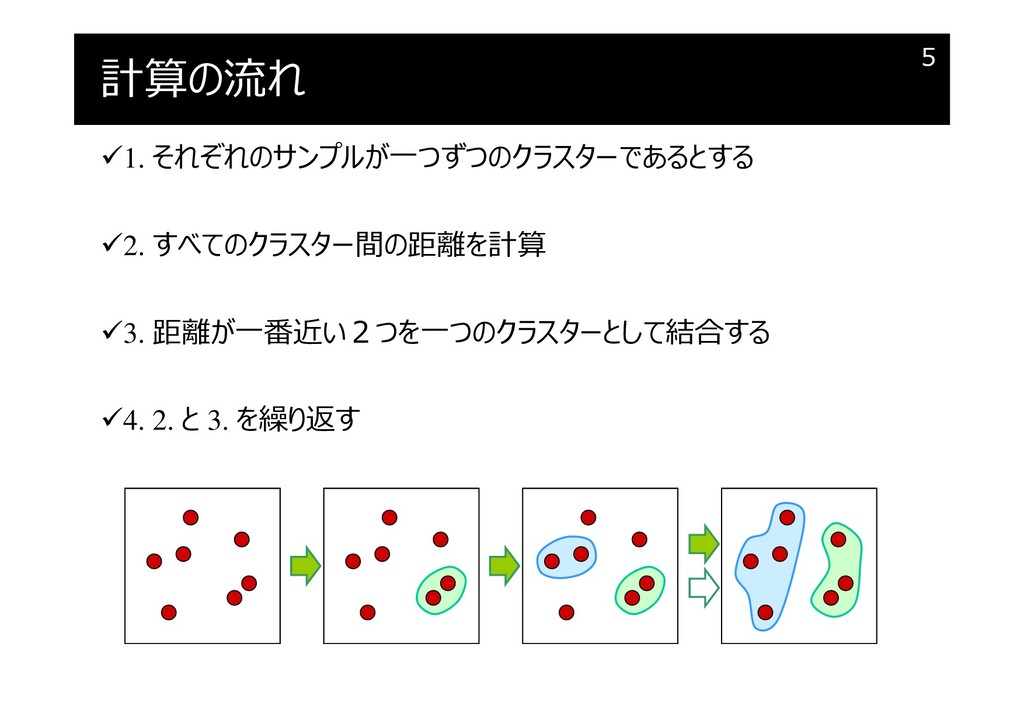
計算の流れ
クラスター間の距離をどうするか?
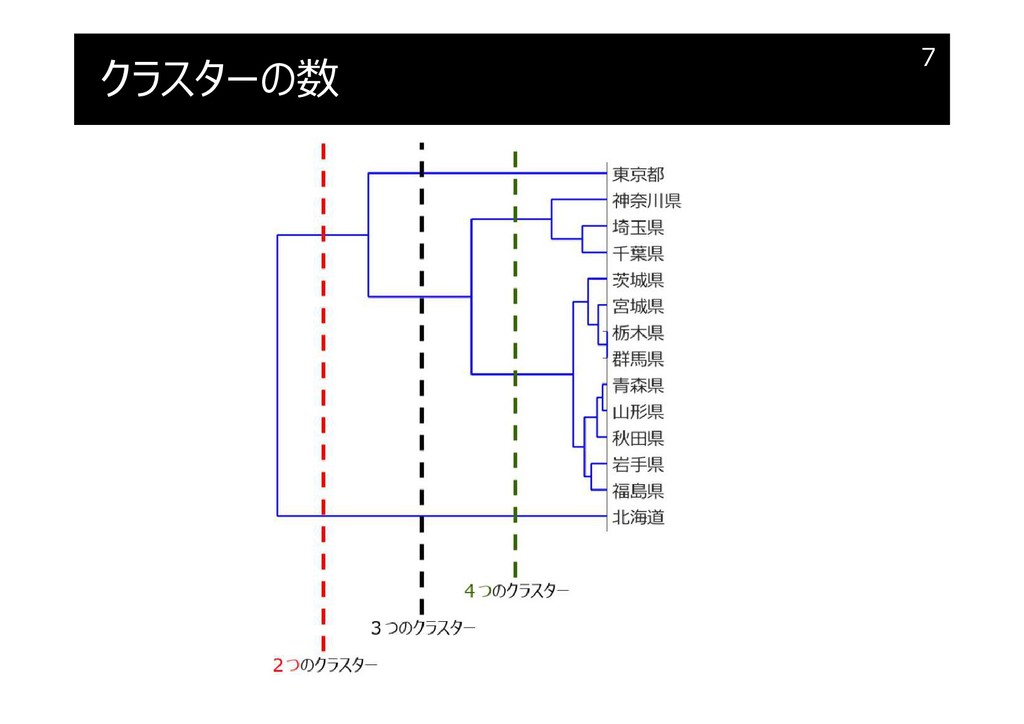
クラスターの数
クラスタリングを実行してみよう!
クラスタリングとクラス分類
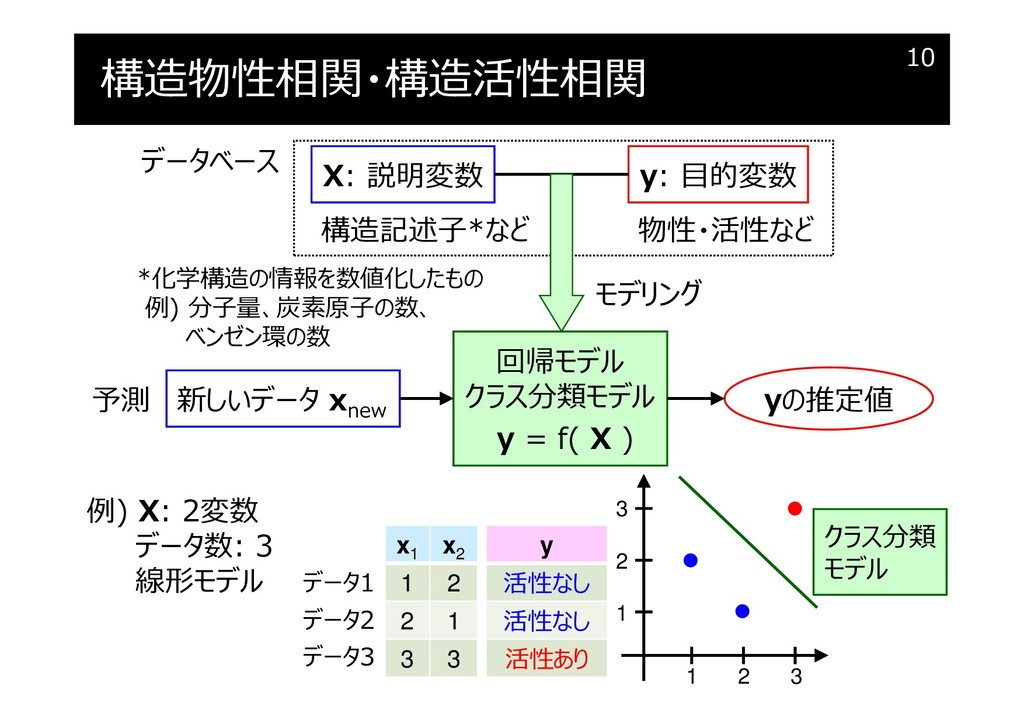
構造物性相関・構造活性相関
決定木 (Decision Tree, DT) とは?
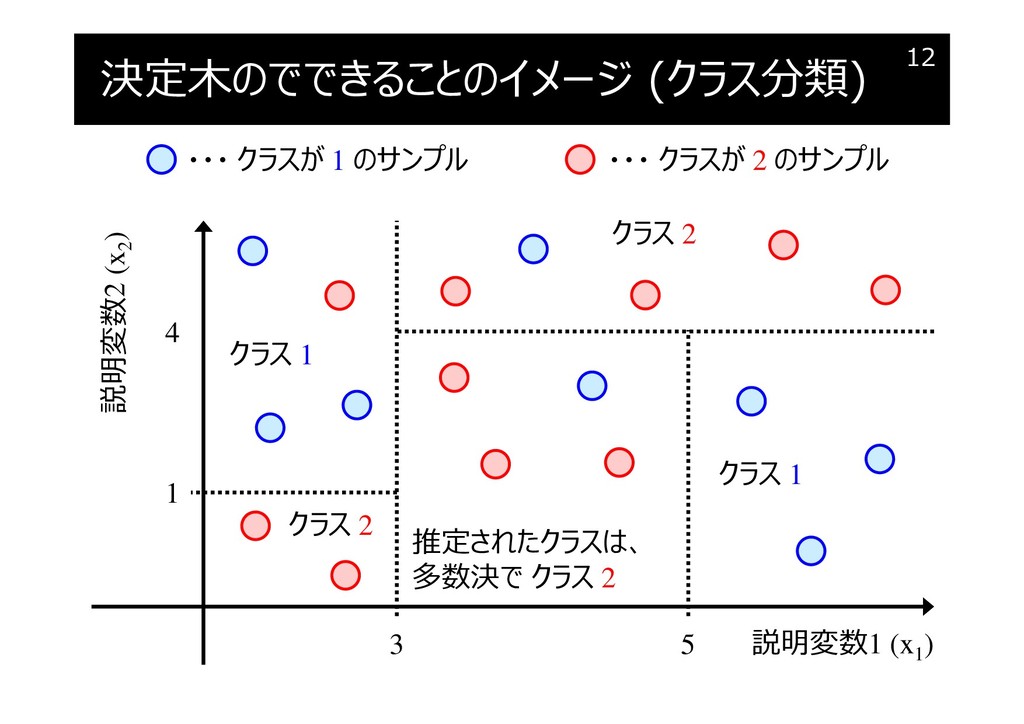
決定木のでできることのイメージ (クラス分類)
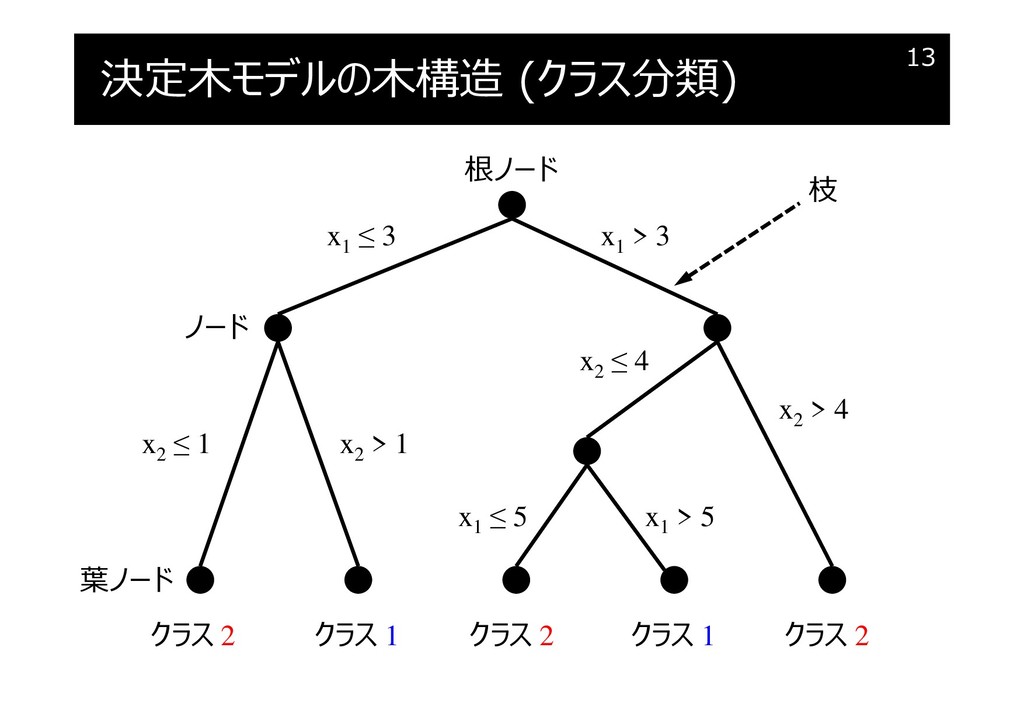
決定木モデルの木構造 (クラス分類)
決定木のアルゴリズム
クラス分類における評価関数 E
クラス分類の結果の評価
クラス分類の結果の評価 例
いつ木の成長を止めるか?
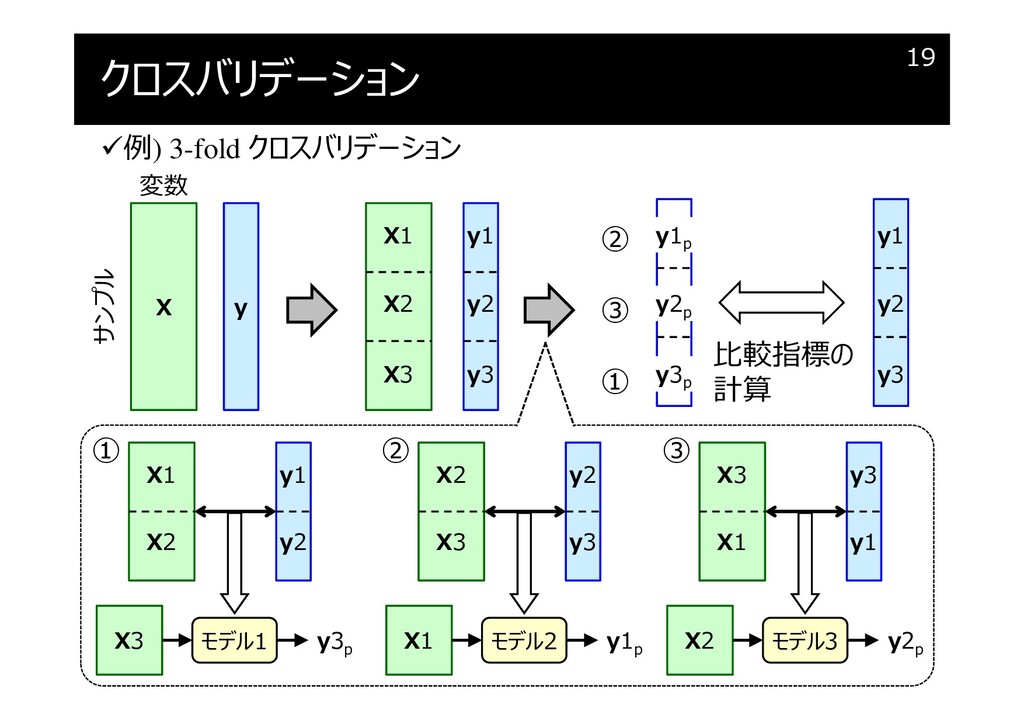
クロスバリデーション
決定木をしてみよう!
Random Forest (RF) とは?
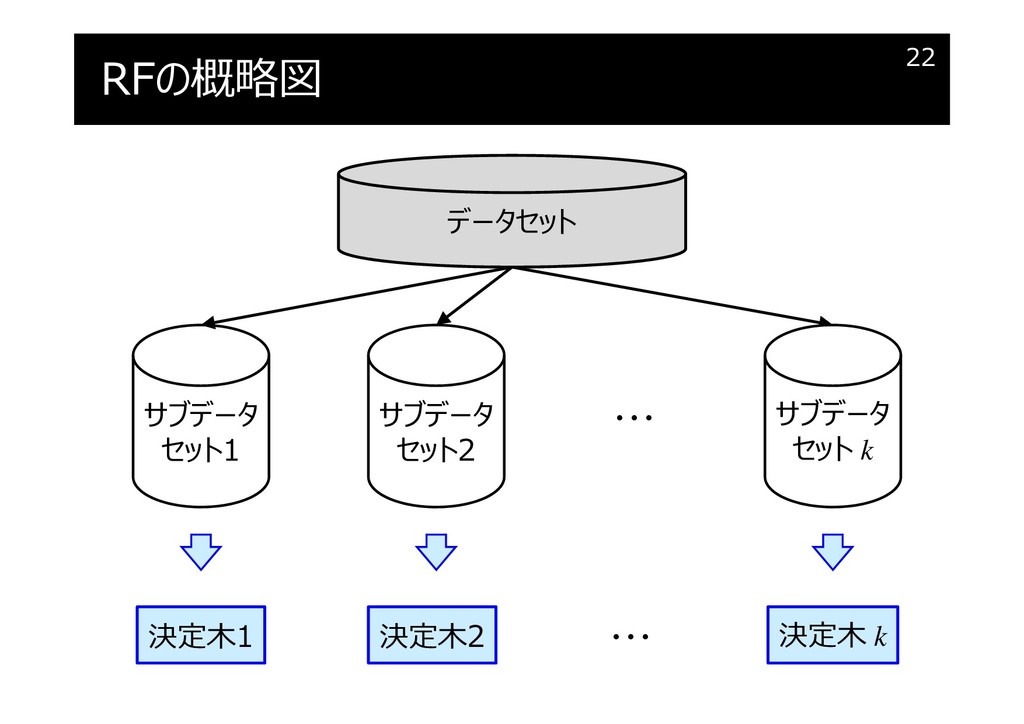
RFの概略図
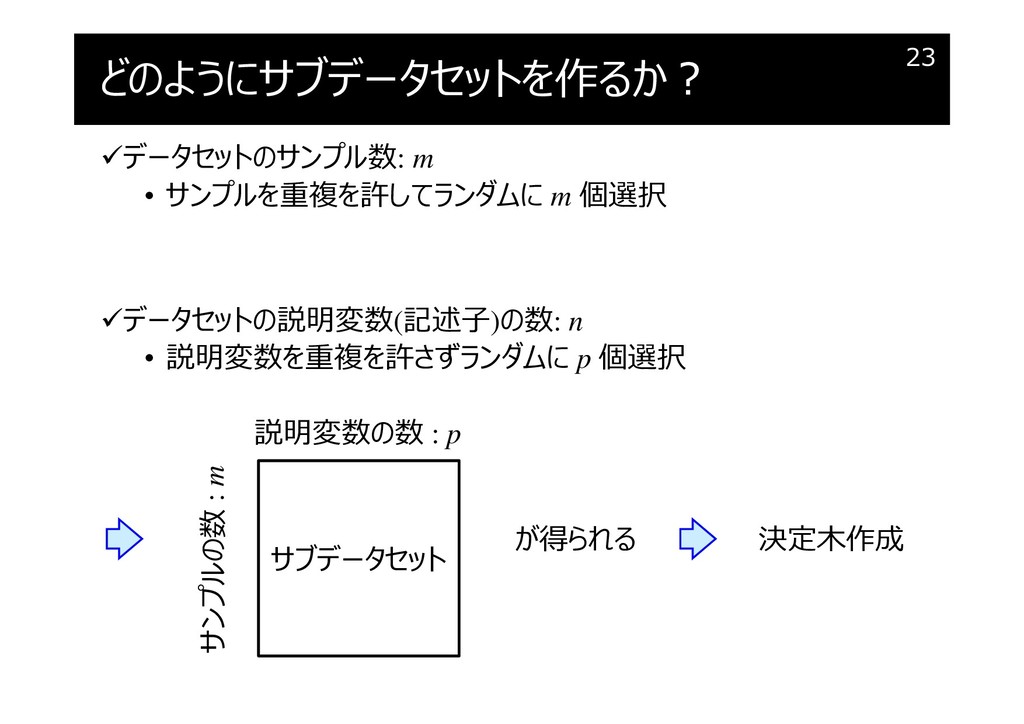
どのようにサブデータセットを作るか?
サブデータセットの数・説明変数の数はどうする?
どのように推定結果を統合するか?
Out-Of-Bag (OOB)
ランダムフォレストをしてみよう!
[補足] 説明変数 (記述子) の重要度
[補足] OOBを用いた説明変数 (記述子) の重要度
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] 説明変数 (記述⼦) の重要度 説明変数 (記述⼦) の重要度 Ij 28 ,](https://files.speakerdeck.com/presentations/5ede2f2d13ad40599819c25c07919769/slide_28.jpg){kind=link}
![[補足] OOBを用いた説明変数 (記述⼦) の重要度 説明変数 (記述⼦) の重要度 Ij 29 (](https://files.speakerdeck.com/presentations/5ede2f2d13ad40599819c25c07919769/slide_29.jpg){kind=link}