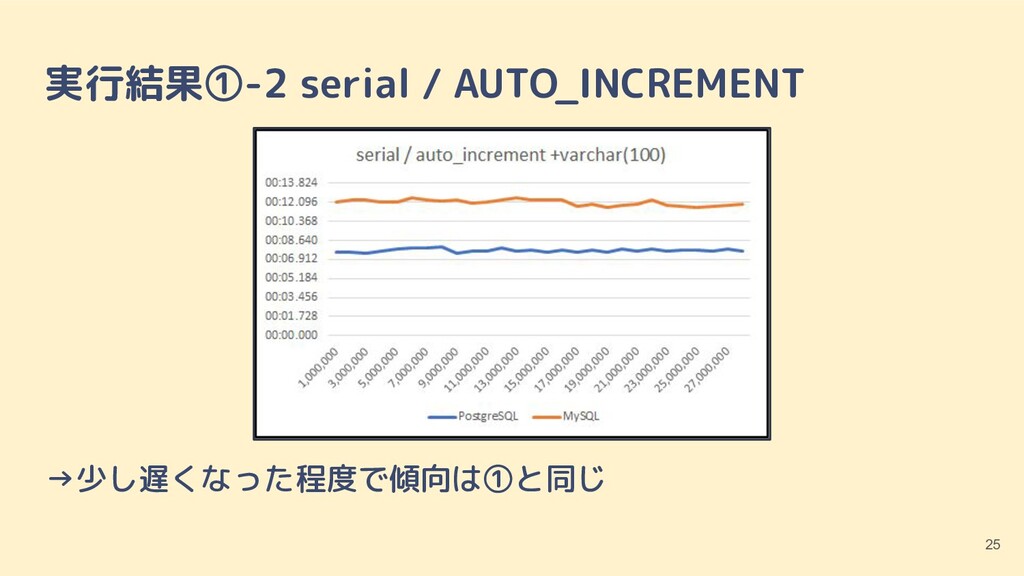
(12), (13), (14), (15), (16), (17), (18), (19); ※これを 12 万行 1 ファイル × 24 種類用意 ・UUIDv4(文字列) INSERT INTO btree_test3 (id, v1) VALUES ('23ce3e9f-16de-4e5c-a293-6104ca45b47a', 10), ('ccf75ce2-49e9-4585-8561-9c55acf9e954', 11), ('493ec339-a21c-4ae9-be52-8c313758dd77', 12), ('aee11198-7767-42a6-9363-a16556d936b7', 13), ('7133eb96-fe19-4d45-b2f7-62ddc719234d', 14), ('cc1ae2ee-d99e-4102-9288-877eaae3bddc', 15), ('67fc7a86-b3c8-46fa-a237-d6479ee693b5', 16), ('c2e663e1-0168-4084-97fb-97b7d4575cf6', 17), ('602f2007-76f4-45d7-8a0f-e51430943afe', 18), ('f2b1ce06-db4a-48c4-b089-94198d3ddbe9', 19); ※これを(異なる UUID で)12 万行 1 ファイル × 24 種類用意 ・UUIDv4(uuid 型/PostgreSQL) INSERT INTO btree_test4 (id, v1) VALUES ('23ce3e9f-16de-4e5c-a293-6104ca45b47a'::uuid, 10), ('ccf75ce2-49e9-4585-8561-9c55acf9e954'::uuid, 11), ('493ec339-a21c-4ae9-be52-8c313758dd77'::uuid, 12), ('aee11198-7767-42a6-9363-a16556d936b7'::uuid, 13), ('7133eb96-fe19-4d45-b2f7-62ddc719234d'::uuid, 14), ('cc1ae2ee-d99e-4102-9288-877eaae3bddc'::uuid, 15), ('67fc7a86-b3c8-46fa-a237-d6479ee693b5'::uuid, 16), ('c2e663e1-0168-4084-97fb-97b7d4575cf6'::uuid, 17), ('602f2007-76f4-45d7-8a0f-e51430943afe'::uuid, 18), ('f2b1ce06-db4a-48c4-b089-94198d3ddbe9'::uuid, 19); ※同上 テスト用の SQL 文(一部分のみ抜粋) 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
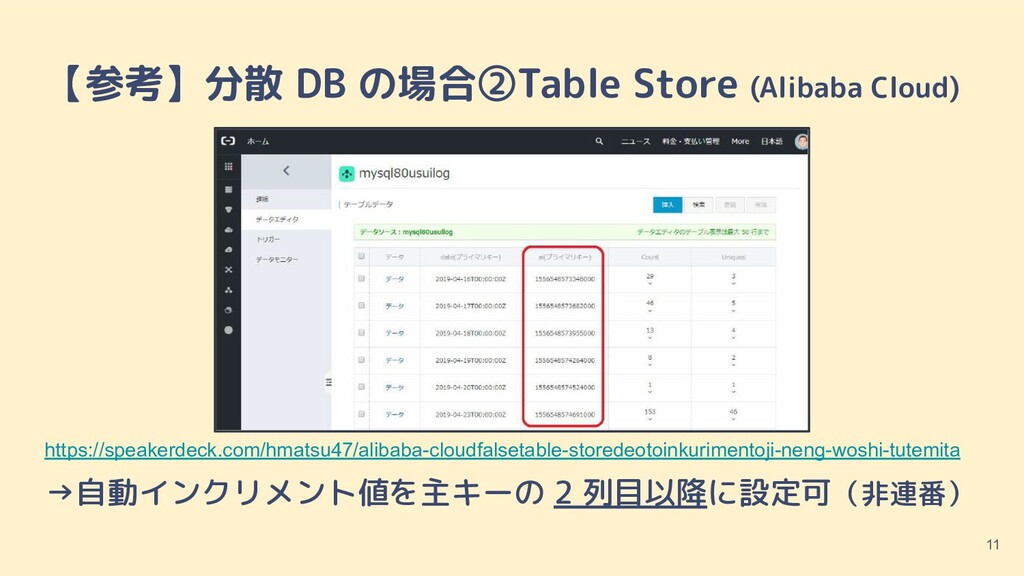{kind=link}
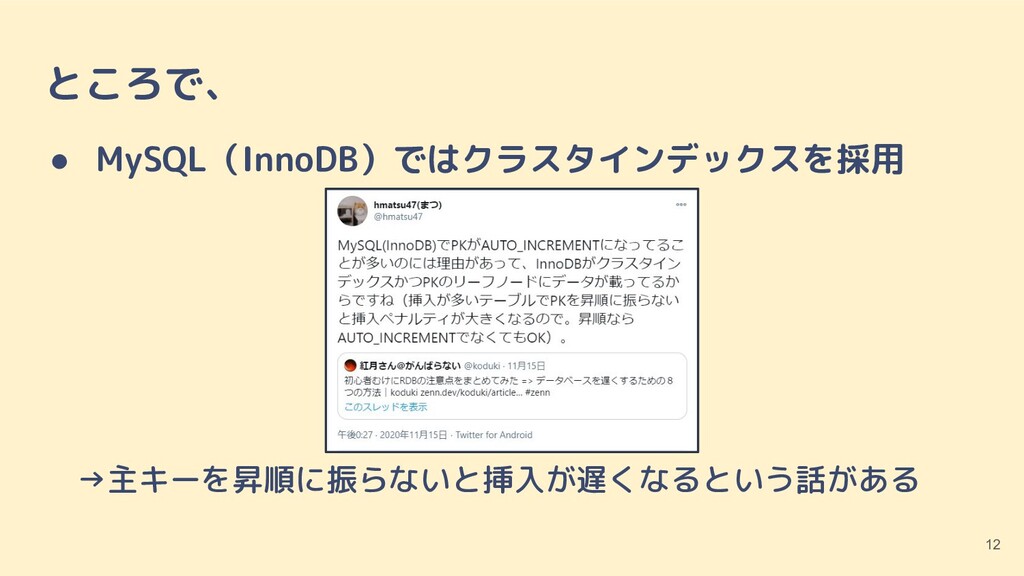{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
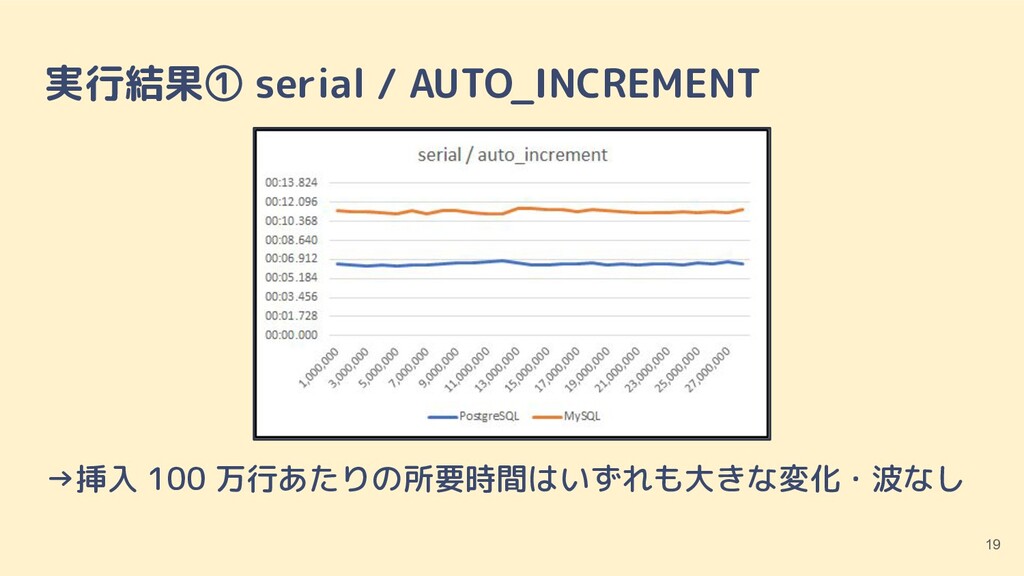{kind=link}
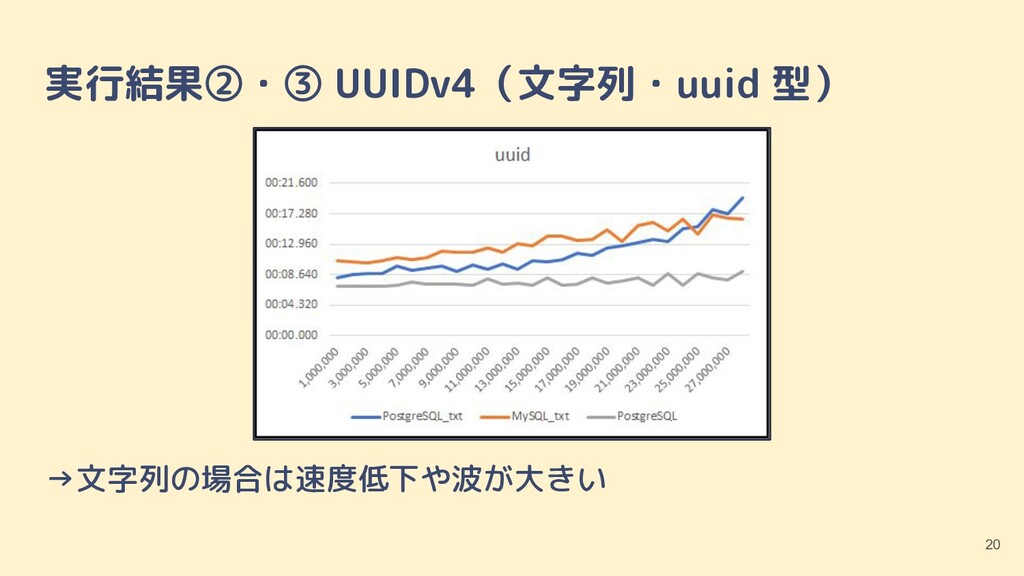{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}