AS depth, r.source_id, r.target_id, r.label, r.properties FROM {relation_table} r WHERE r.source_id = ANY(:ids) UNION ALL SELECT p.depth + 1, r.source_id, r.target_id, r.label, r.properties FROM PATH p JOIN {relation_table} r ON p.target_id = r.source_id WHERE p.depth < :depth ) (右上に続く) (左下から続く) SELECT e1.id AS e1_id, e1.name AS e1_name, e1.label AS e1_label, e1.properties AS e1_properties, p.label AS rel_label, p.properties AS rel_properties, e2.id AS e2_id, e2.name AS e2_name, e2.label AS e2_label, e2.properties AS e2_properties FROM PATH p JOIN {node_table} e1 ON p.source_id = e1.id JOIN {node_table} e2 ON p.target_id = e2.id ORDER BY p.depth LIMIT :limit; 再帰CTE (共通テーブル式)
(略) Here are some facts extracted from the provided text: 卒業証書 -> 記載 -> Artificial intelligence 学生 -> 独学 -> 問題なかった 学生 -> 意識 -> 進むべき道 (略) 授業の中でではなく、独学という形ではあったが、それでも問題なかった。この数年間、私は自分が進むべき道をはっきりと意識していた。 学部の卒業論文では、SHRDLUをリバースエンジニアリングした。私はこのプログラムを作ることが本当に好きだった。 (略) --------------------- Given the context information and not prior knowledge, answer the query. Query: 学生時代にしたことは? Answer: 検索・取得したトリプレット 検索・取得した文章チャンク 質問文
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RAG の種類 [1] Naive RAG • 初期に登場したシンプルな構成の RAG ◦ あらかじめ関連知識として与える文章を分割(チャンク化)→ベク](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![RAG の種類 [2] Advanced RAG • 関連知識の検索(Retrieval)に前処理と後処理を加え精度 を高める ◦ ハイブリッド検索、リランキングなど](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
![[1] RDF グラフ • RDF(Resource Description Framework) ◦ (元々は)ウェブ上のデータを一貫性のある方法で記述するための フレームワーク](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_12.jpg){kind=link}
![[2] プロパティグラフ • ノード・エッジ(リレーションシップ)・プロパティを使用 して情報を整理・表現するもの ◦ ノードにはラベルとプロパティを付与可能 ◦ エッジには方向性がありプロパティを付与可能 ▪](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_13.jpg){kind=link}
{kind=link}
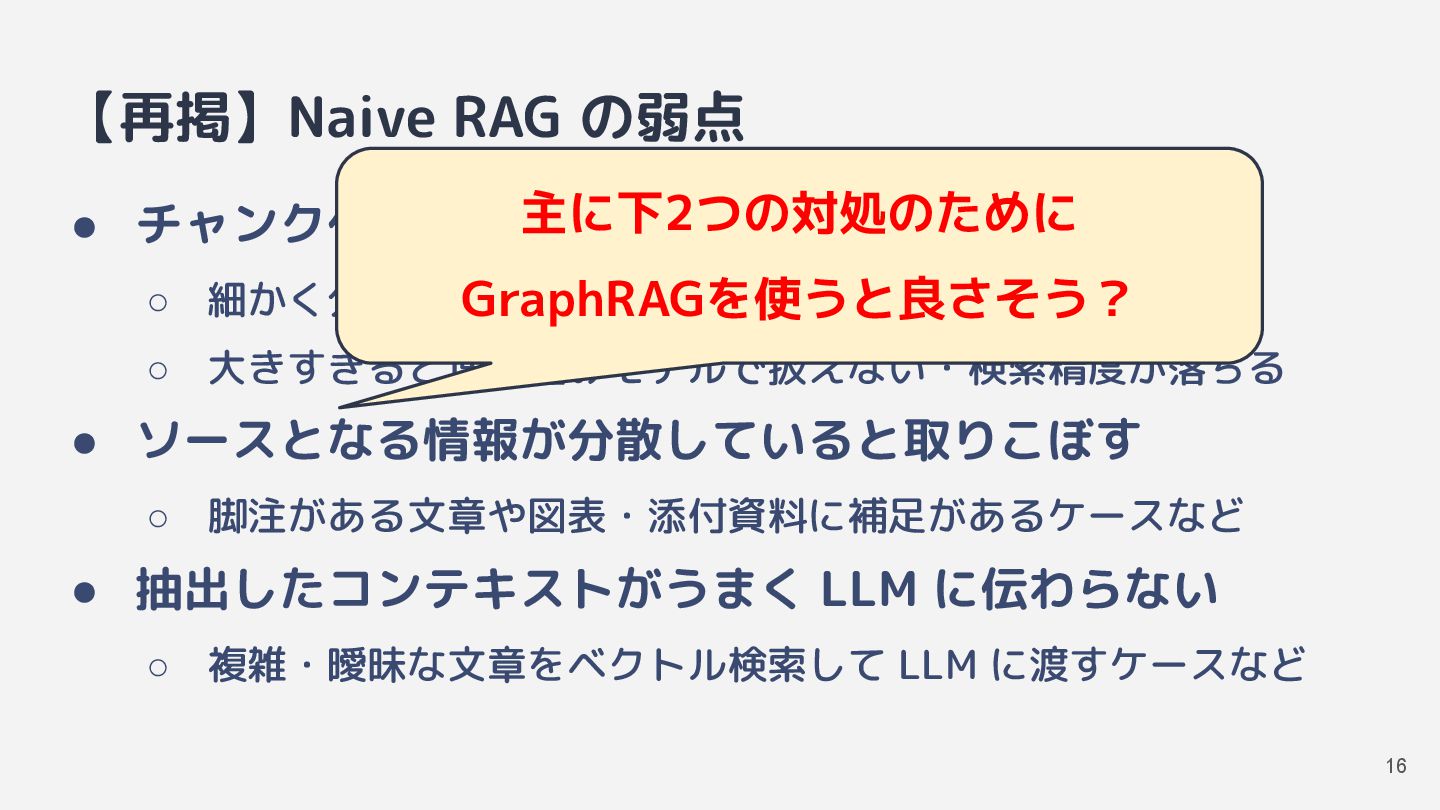{kind=link}
![ちなみに [1] • PostgreSQL のグラフ機能といえば ◦ PostGIS 関連の extension に](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_16.jpg){kind=link}
![ちなみに [2] • Oracle Database 23c にはグラフを扱う機能がある ◦ SQL:2023 にはプロパティグラフ用の](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_17.jpg){kind=link}
{kind=link}
![[1] 環境構築 20](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[2] 試用 28](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_27.jpg){kind=link}
{kind=link}
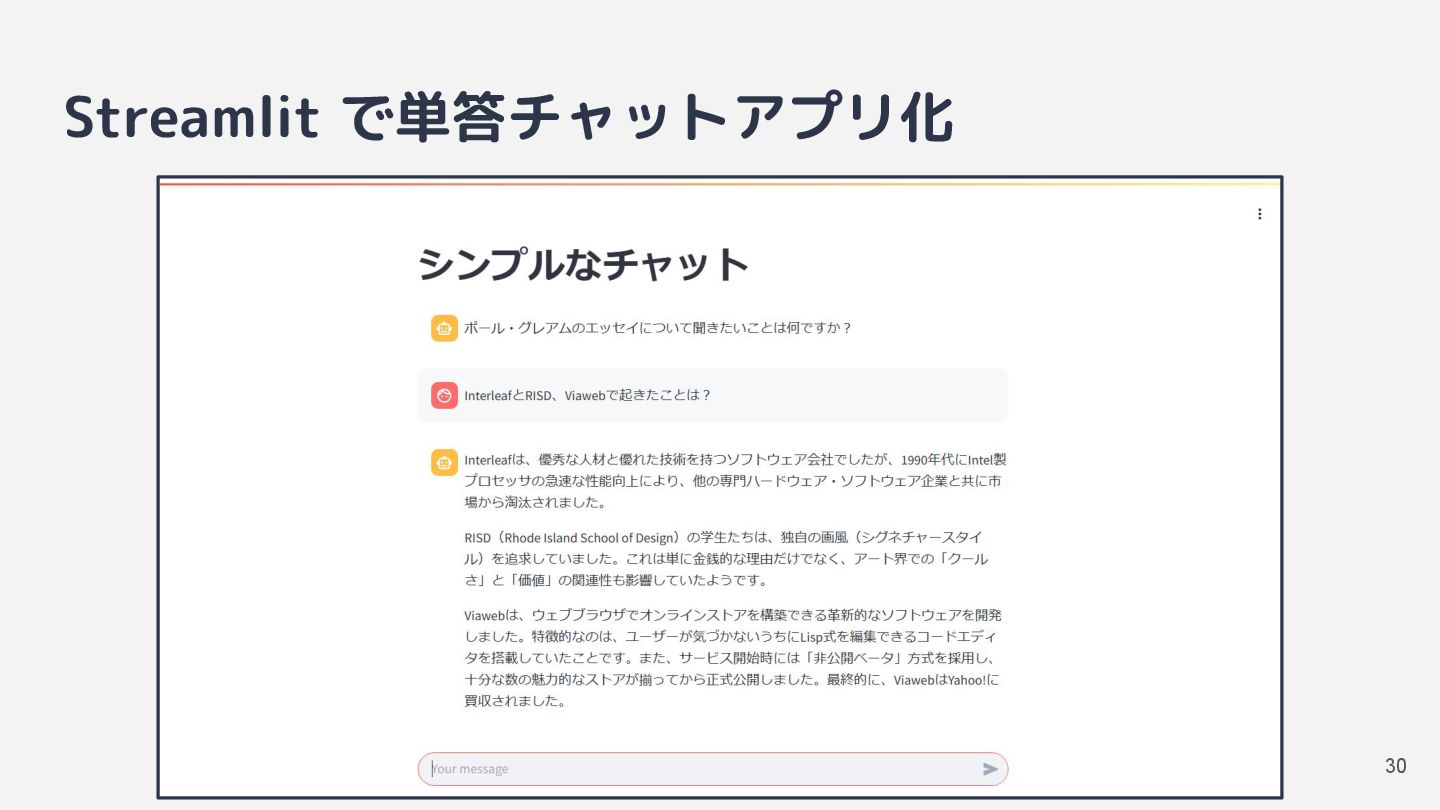{kind=link}
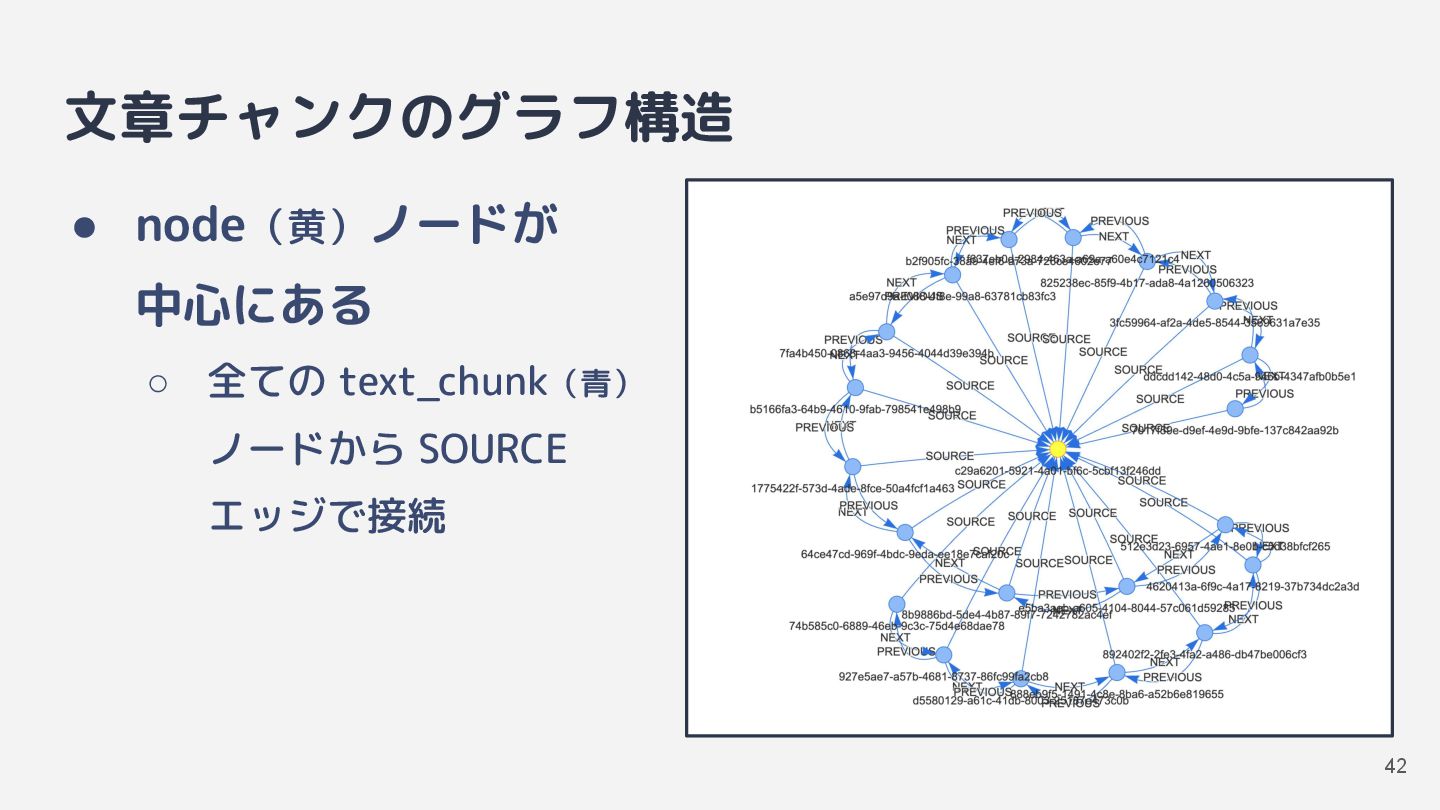
![インデックス生成 [1] 文書のチャンク化→グラフ化 • 1,000 文字前後(デフォルト)の文章に分割して保存 ◦ 1 文書あたり 1](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_30.jpg){kind=link}
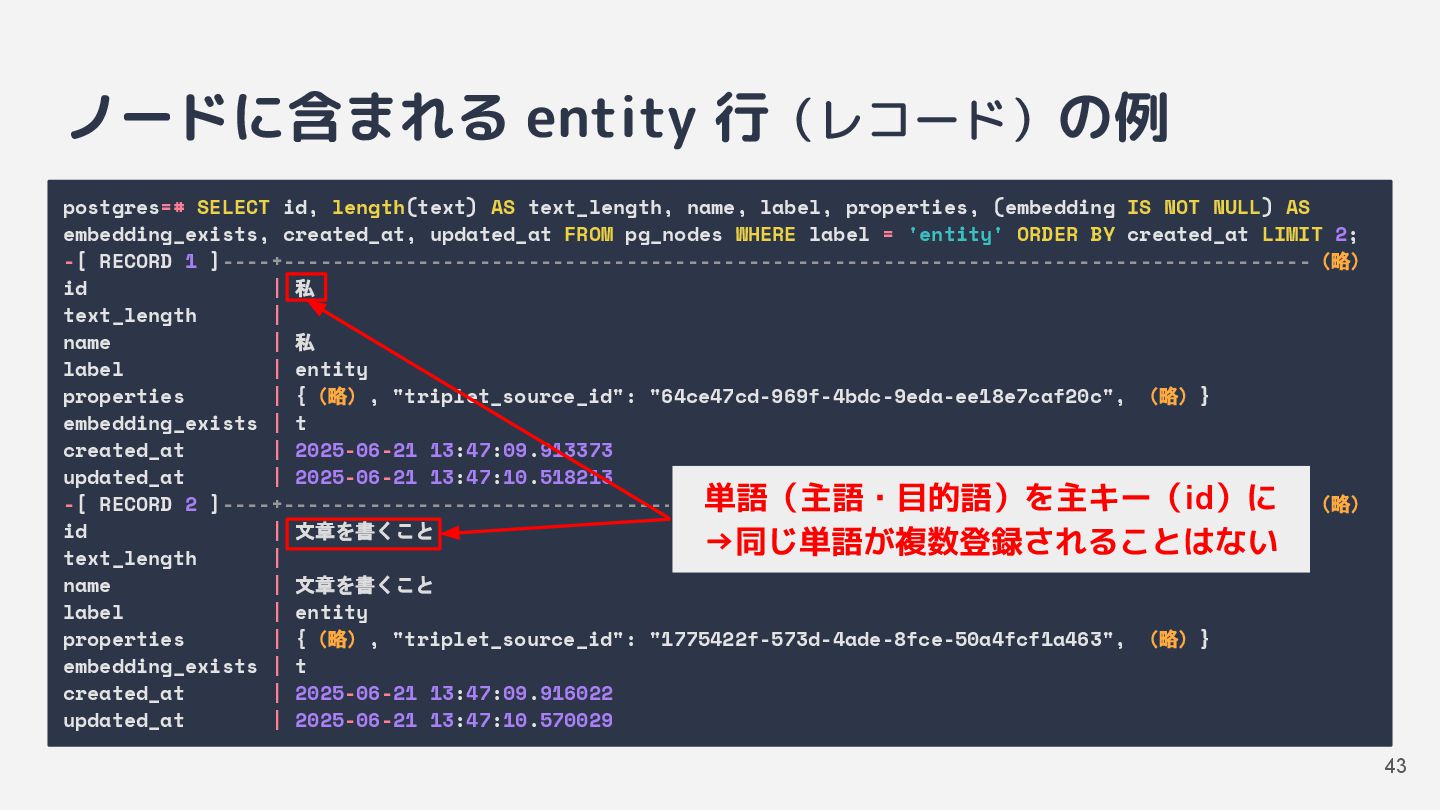
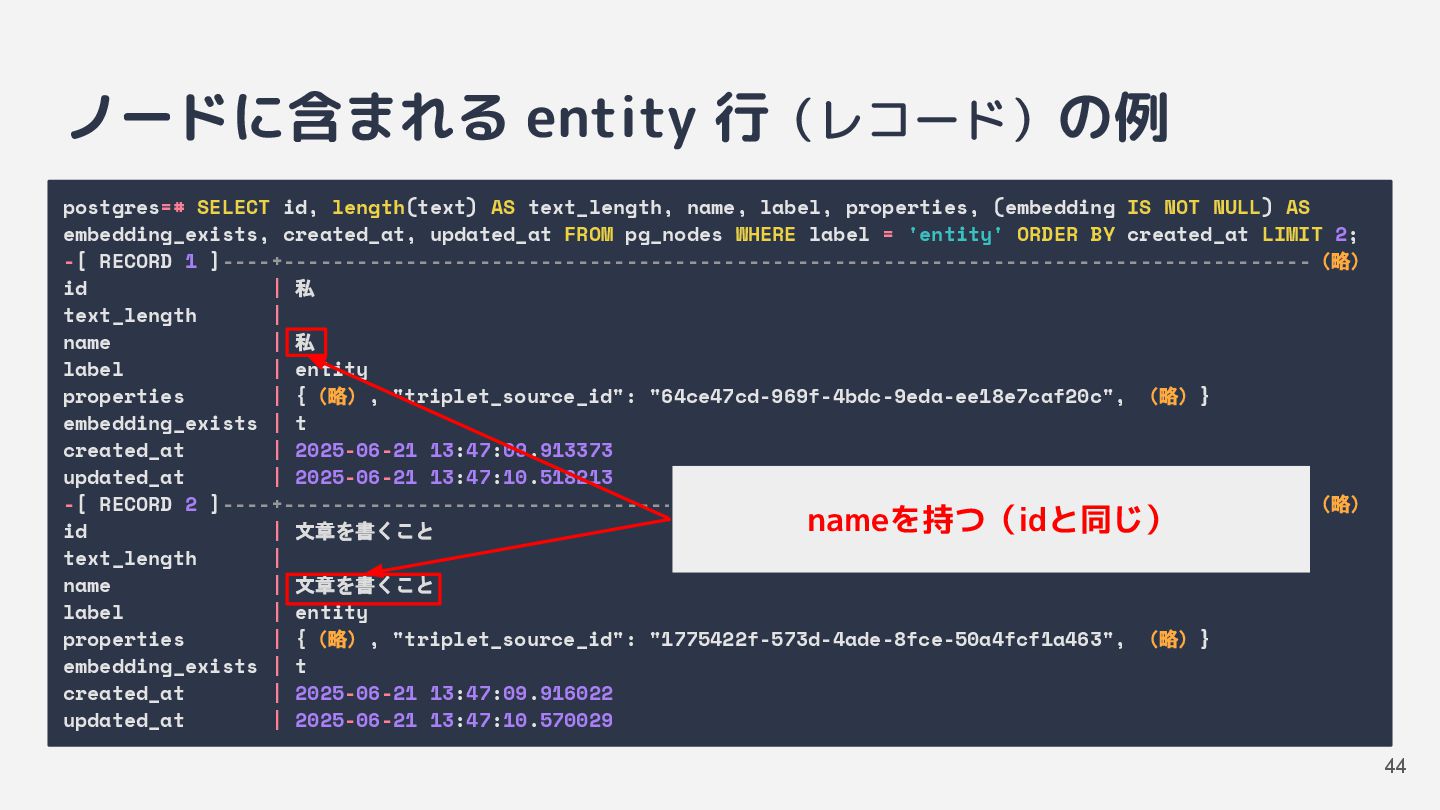
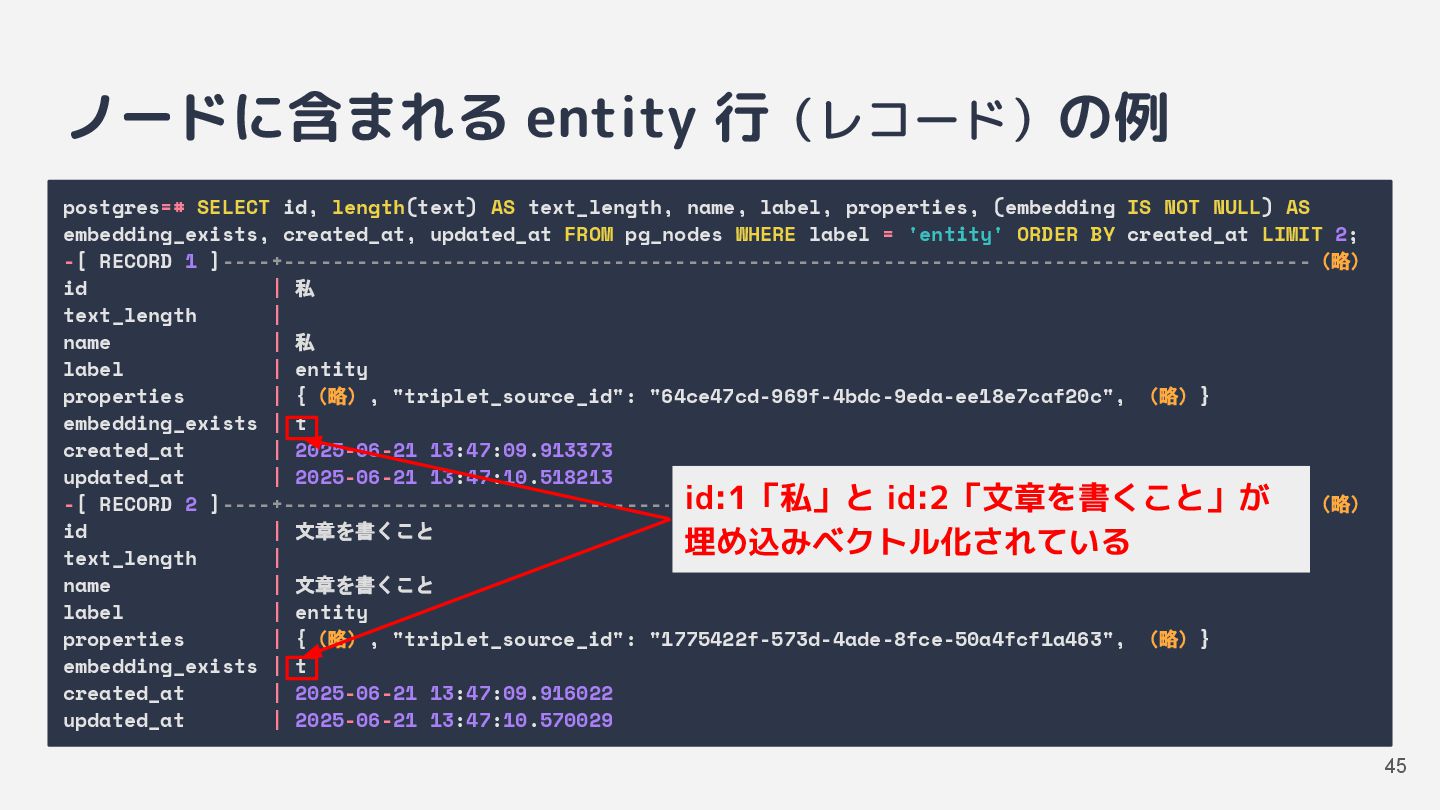
![インデックス生成 [2] トリプレットの抽出 • チャンク化した文章から「主語+述語+目的語」の組み 合わせをいくつか抽出 ◦ 主語と目的語を entity ノードとして個別に保存](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_31.jpg){kind=link}
![インデックス生成 [3] 各ノードにベクトルを保存 • ベクトル検索用の埋め込みベクトルを保存 ◦ text_chunk ノードには文章チャンクの埋め込みベクトル ◦ entity](https://files.speakerdeck.com/presentations/6dc82016a42e448e804610a0f6a60428/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}