Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
RDS_AuroraパフォーマンスインサイトのデータをAthenaとQuickSightで見る
Search
hmatsu47
PRO
May 31, 2021
Technology
630
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
RDS_AuroraパフォーマンスインサイトのデータをAthenaとQuickSightで見る
JAWS-UG 名古屋 データ分析を学ぶ 2021/05/31
hmatsu47
PRO
May 31, 2021
More Decks by hmatsu47
See All by hmatsu47
ゲームで挑戦!VPC の気持ちになって IPv4/v6 パケットをルーティングしよう!
hmatsu47
PRO
0
20
続・名古屋城とデータセンター
hmatsu47
PRO
0
20
【再演】IPv6 VPC の実装パターンをいくつか
hmatsu47
PRO
0
21
名古屋城とデータセンター
hmatsu47
PRO
0
32
IPv6 に関する話
hmatsu47
PRO
0
23
さいきんの光ファイバーの話
hmatsu47
PRO
0
50
低いほうのレイヤを見てみる話
hmatsu47
PRO
0
26
IPv6 VPC の実装パターンをいくつか
hmatsu47
PRO
0
44
光ファイバーと IPv6 絡みの話
hmatsu47
PRO
0
60
Other Decks in Technology
See All in Technology
_NIKKEI_Tech_Talk__勉強会は熱量では続かない___17回続いた輪読会の設計術.pdf
_awache
2
110
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
750
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
330
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
270
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
360
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
240
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
2
990
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
5
460
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
2
290
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.2k
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
290
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
4
350
Featured
See All Featured
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
The Curse of the Amulet
leimatthew05
2
13k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
My Coaching Mixtape
mlcsv
0
180
A Tale of Four Properties
chriscoyier
163
24k
Visualization
eitanlees
152
17k
The Invisible Side of Design
smashingmag
301
52k
Crafting Experiences
bethany
1
230
Amusing Abliteration
ianozsvald
1
240
Facilitating Awesome Meetings
lara
57
7k
Transcript
RDS / Aurora パフォーマンスインサイトの データを Athena と QuickSight で見る JAWS-UG
名古屋 データ分析を学ぶ 2021/05/31 まつひさ(hmatsu47)
自己紹介 松久裕保(@hmatsu47) https://qiita.com/hmatsu47 名古屋で Web インフラのお守り係をしています (ほかに書くことがなくなったので省略) 2
今日の内容 • パフォーマンスインサイトとその問題点のおさらい • API 経由で S3 にデータを書き出してみる ◦ Lambda(Python)で
S3 へ • Glue クローラを使って Athena へ ◦ Athena でクエリを実行してみる • Athena から QuickSight へ ◦ QuickSight でグラフ化してみる 3
パフォーマンスインサイトとは • RDS / Aurora の負荷とその内訳を示すもの ◦ https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/USER_ PerfInsights.Overview.html •
カウンターメトリクス ◦ 性能に関係するカウンター値を個別にグラフ表示 • データベースのロード ◦ 負荷の高さと内訳をグラフ表示 4
パフォーマンスインサイトとは • RDS / Aurora の負荷とその内訳を示すもの ◦ https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/USER_ PerfInsights.Overview.html •
カウンターメトリクス ◦ 性能に関係するカウンター値を個別にグラフ表示 • データベースのロード ◦ 負荷の高さと内訳をグラフ表示 5
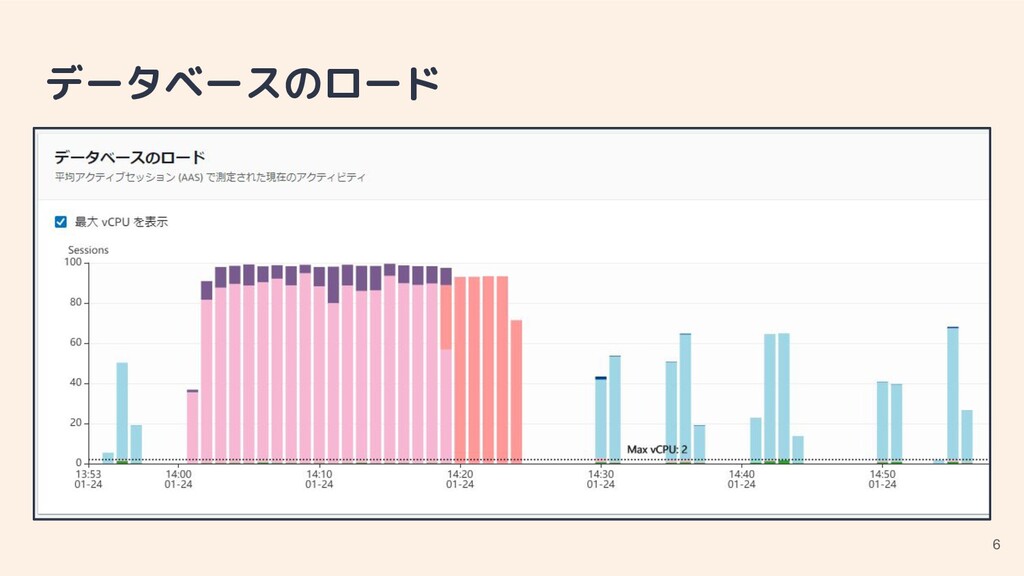
データベースのロード 6
データベースのロード • 合計:単位時間あたり平均コネクション数 • 内訳:待機イベント毎の所要時間 ◦ 上位 9 個(※)+ CPU
時間(緑)で計 10 個 (※)「上位 9 個」は選択期間内における上位 9 個 ◦ 正規化した SQL(文)上位 10 個の待機イベント内訳も表示可能 ▪ SQL(文)正規化 ≠ DB(テーブル)正規化 ▪ 空白・クォート等を揃え、 パラメータを「?」に置き換え • トークン化 7
待機イベント 8 時間が掛かる処理 • ログの書き出し ◦ MySQL の場合バイナリログもある • なんらかのロック・mutex(排他制御の待ち時間)
• データの書き出し • データの読み取り(ストレージから>メモリから) • クライアントの接続
問題点 • 選択期間内の上位 10 個 ≠ 対象時間の上位 10 個の場合 (※)待機イベントの場合は
CPU を含めて 10 個 ◦ 一部の待機イベント・SQL(文)が漏れる ◦ 合計値が本来より低くなる ▪ 一般的なワークロードでは SQL(文)が数十種類以上になるはず • 待機別よりも SQL 別のスライスのほうが実際の合計値から乖離しやすい 9
対策 : API 経由で書き出したものを分析する • API で値を取得する方法 ◦ https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/USER_PerfInsights. API.html
• 今回は Lambda Python で Boto3 低レベルクライアント (PI)を使って S3 に(正規化した)SQL(文)を転送 ◦ https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/pi.html ◦ S3 に転送したデータを Glue 経由で Athena から参照 ▪ さらに QuickSight でグラフ化 10
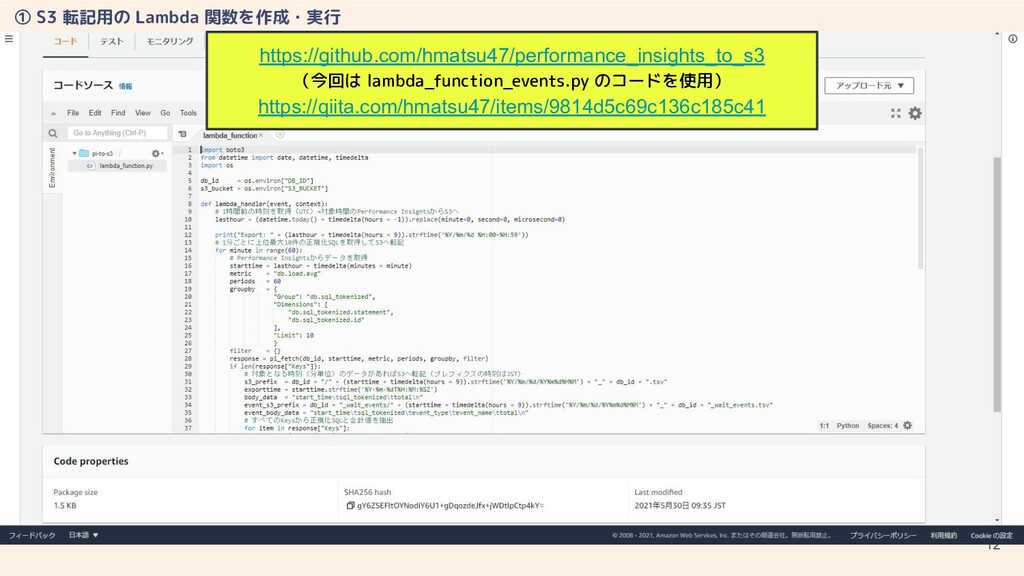
11 ① S3 転記用の Lambda 関数を作成・実行
12 https://github.com/hmatsu47/performance_insights_to_s3 (今回は lambda_function_events.py のコードを使用) https://qiita.com/hmatsu47/items/9814d5c69c136c185c41 ① S3 転記用の Lambda
関数を作成・実行
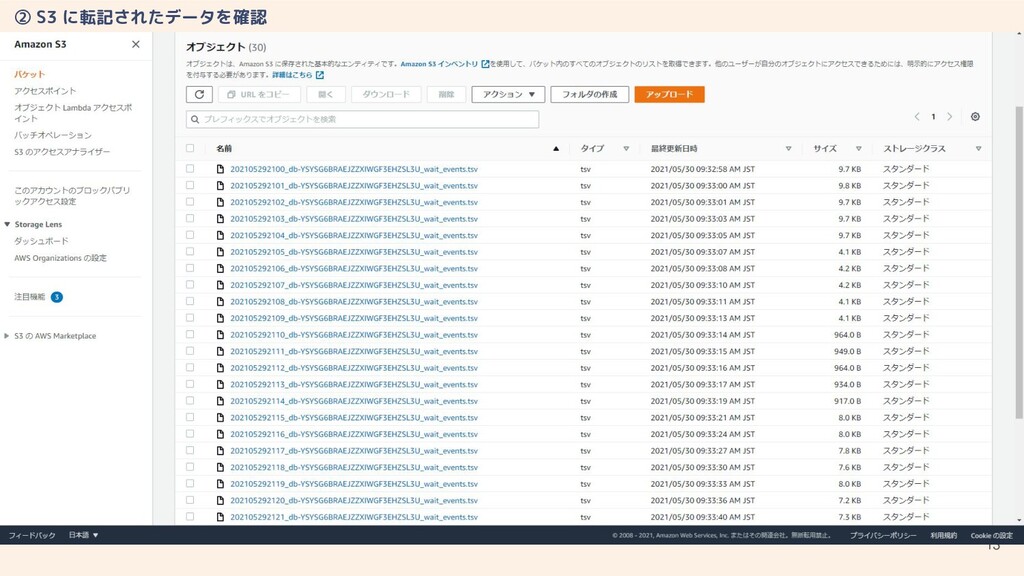
13 ② S3 に転記されたデータを確認
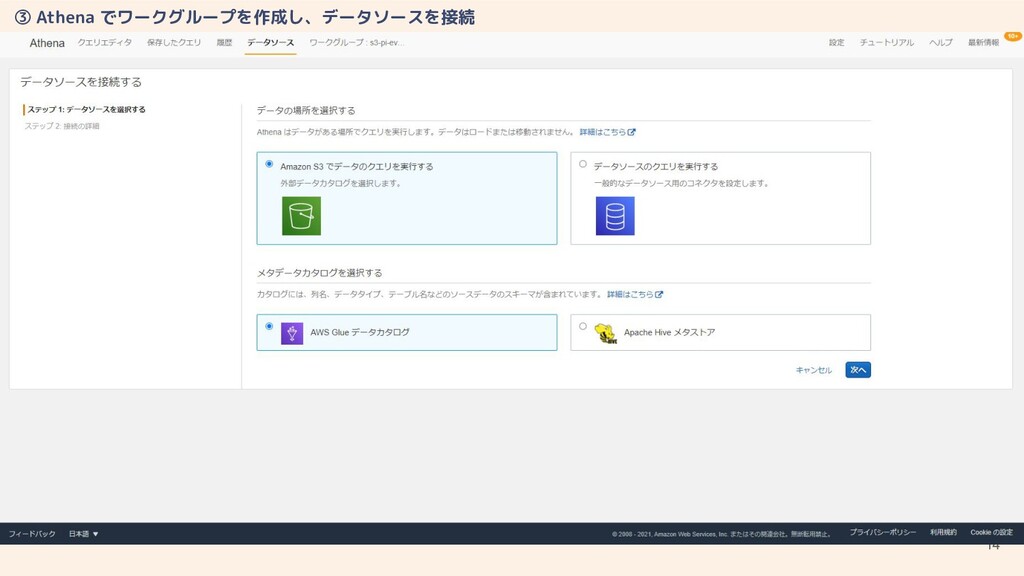
14 ③ Athena でワークグループを作成し、データソースを接続
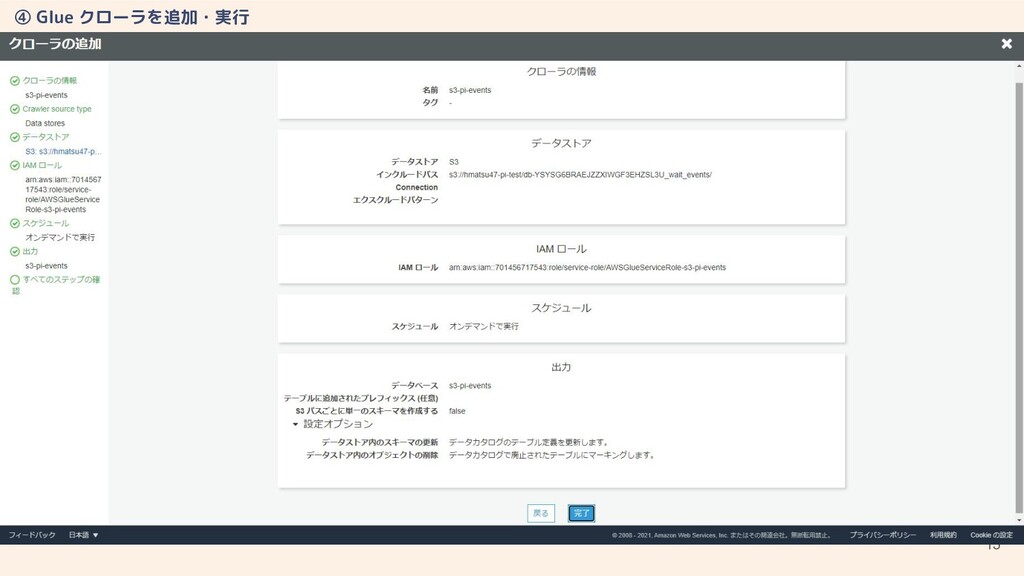
15 ④ Glue クローラを追加・実行
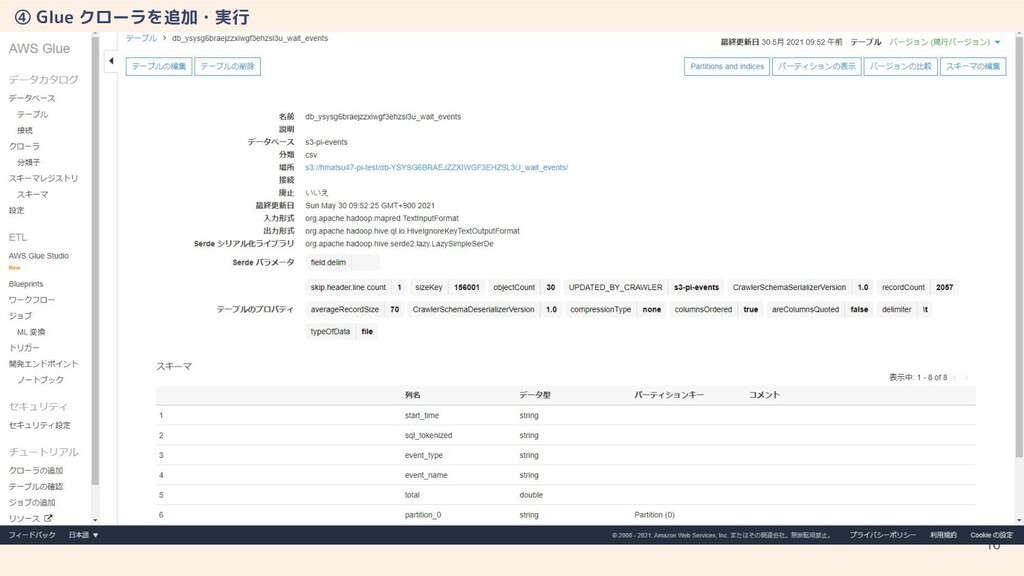
16 ④ Glue クローラを追加・実行
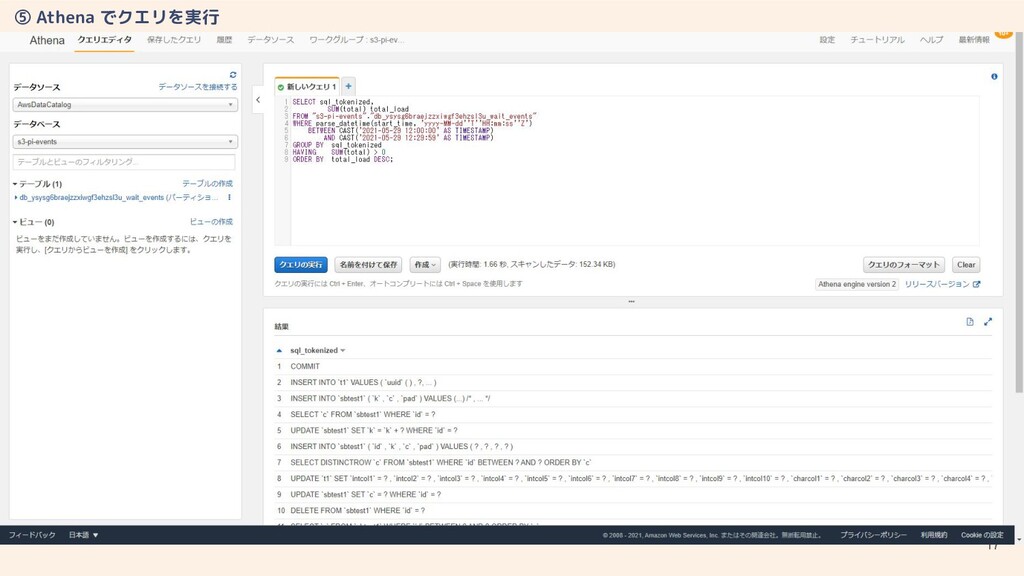
17 ⑤ Athena でクエリを実行
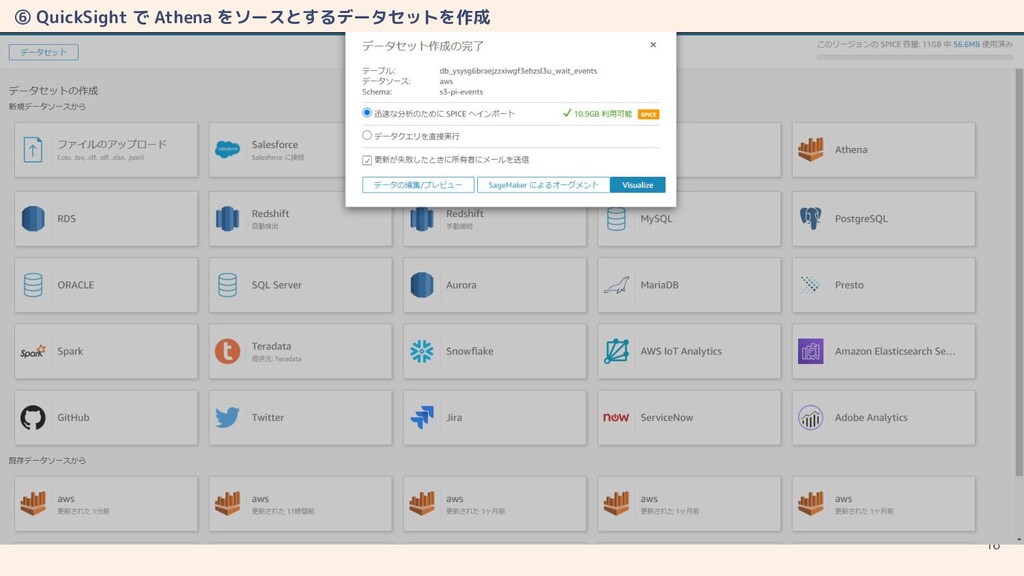
18 ⑥ QuickSight で Athena をソースとするデータセットを作成
19 ⑦ QuickSight でデータセットを編集
20 ⑦ QuickSight でデータセットを編集(日付フィールドが文字列のままだと都合が悪いので編集して日付形式へ)
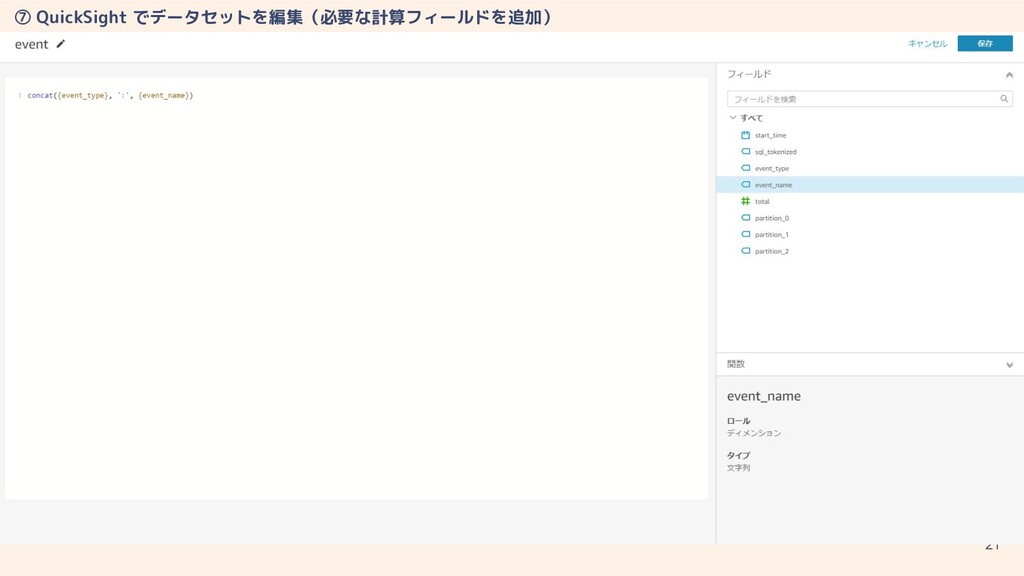
21 ⑦ QuickSight でデータセットを編集(必要な計算フィールドを追加)
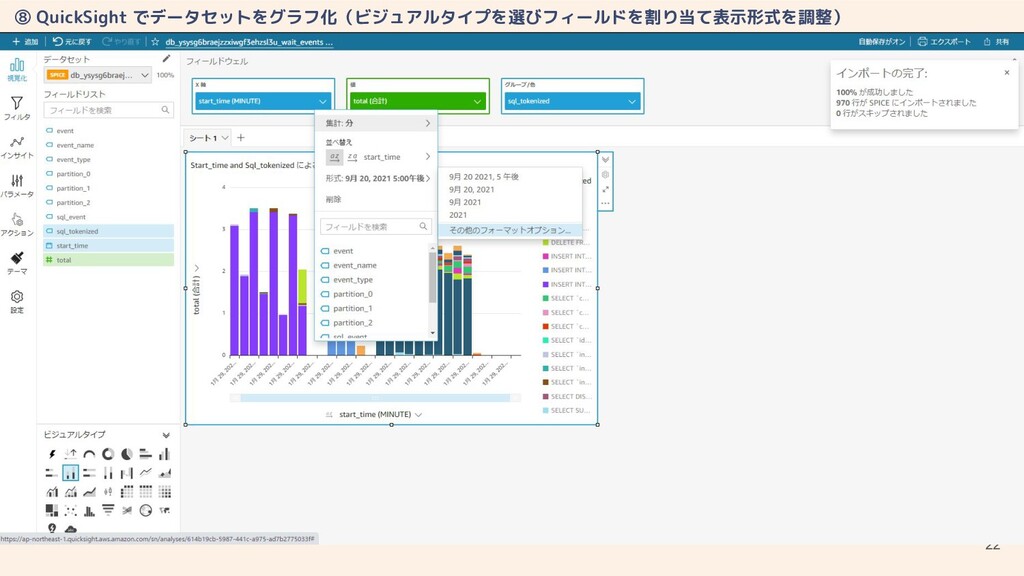
22 ⑧ QuickSight でデータセットをグラフ化(ビジュアルタイプを選びフィールドを割り当て表示形式を調整)
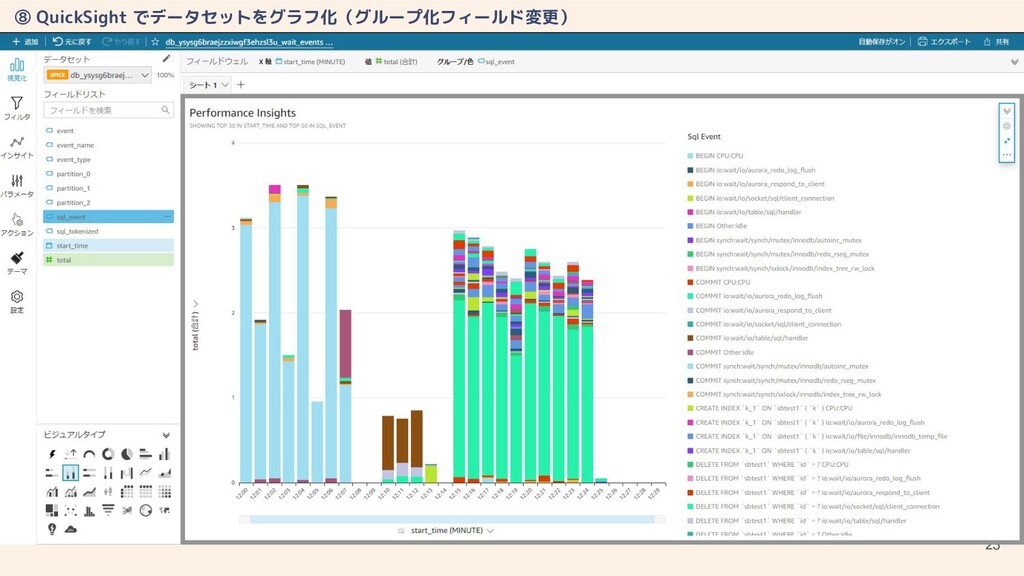
23 ⑧ QuickSight でデータセットをグラフ化(グループ化フィールド変更)
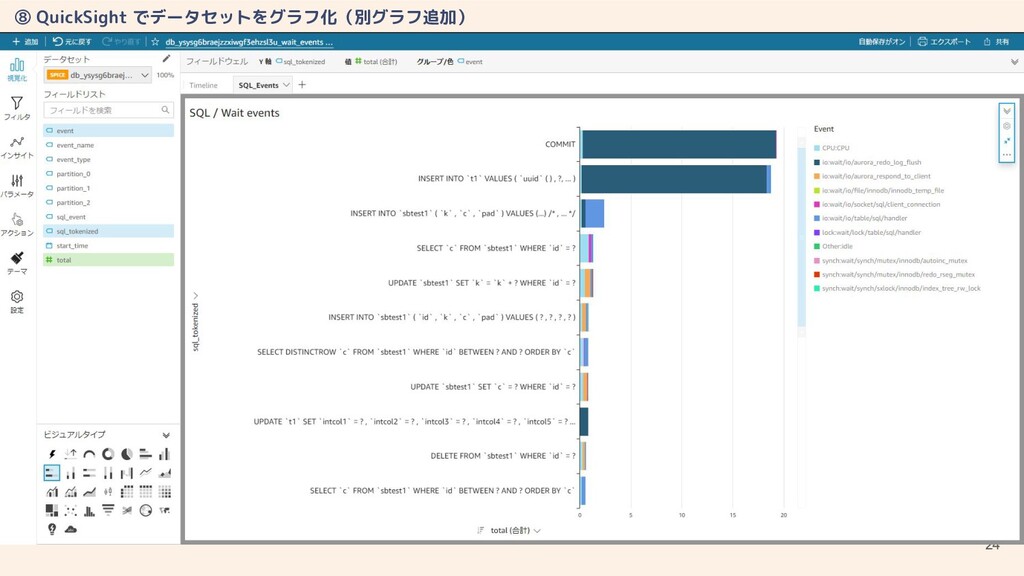
24 ⑧ QuickSight でデータセットをグラフ化(別グラフ追加)
まとめ • API で書き出したデータを使うと細部を可視化可能 ◦ RDS のマネジメントコンソールでは表示できない部分も • ただし限界はある ◦
負荷が高い SQL(文)の抽出とチューニングにはある程度使える ◦ 遅い原因が不明な SQL(文)では待機イベントの抽出が必要だ が、SQL(文)を特定してその待機イベントを調査…のような使 い方がしづらい ▪ 多くのケースで秒単位のデータが必要だが、書き出しの負担が大きい ◦ API にはレートリミットがある 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}