Share
【福岡】GMOペパボ × Sansan合同勉強会 「歴史ある大規模サービスがまだなお成長する秘訣」 - connpass https://sansan.connpass.com/event/71727/ で発表した資料です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
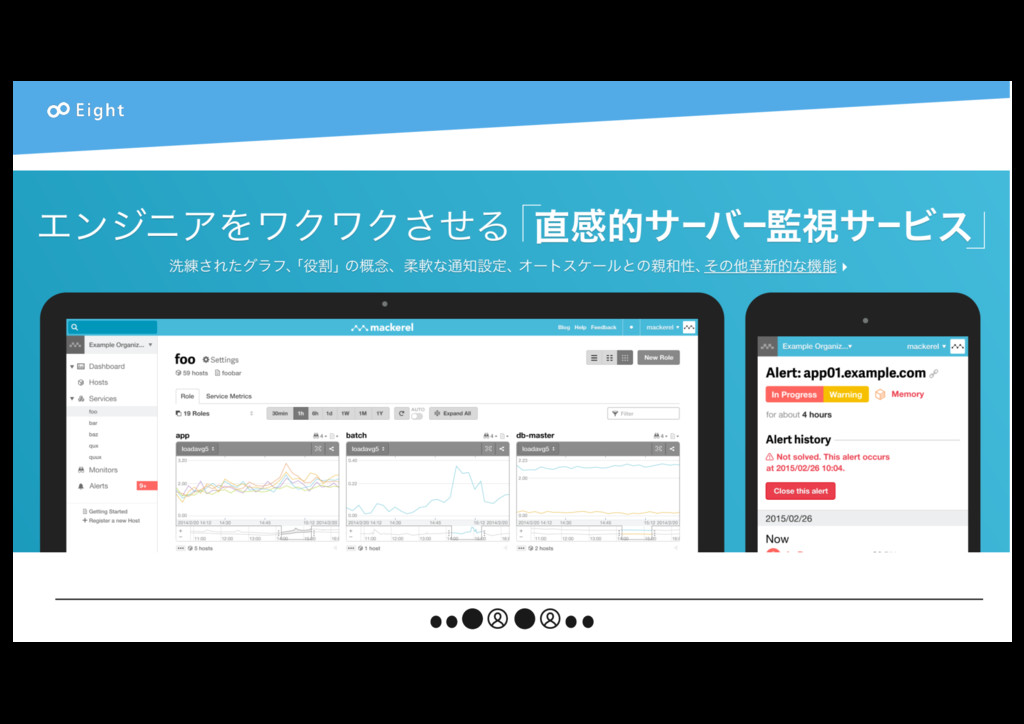{kind=link}
{kind=link}
{kind=link}
{kind=link}
![例: DynamoDBのキャパシティ消費率計算、監視 CloudWatch APIを叩き、Read/Write Capacityの使⽤率を計算 Mackerelに consumed_[read/write]_ratio としてメトリクスを投稿し、監視を設定](https://files.speakerdeck.com/presentations/b8d5980f96a144d597894b0bb5f98904/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
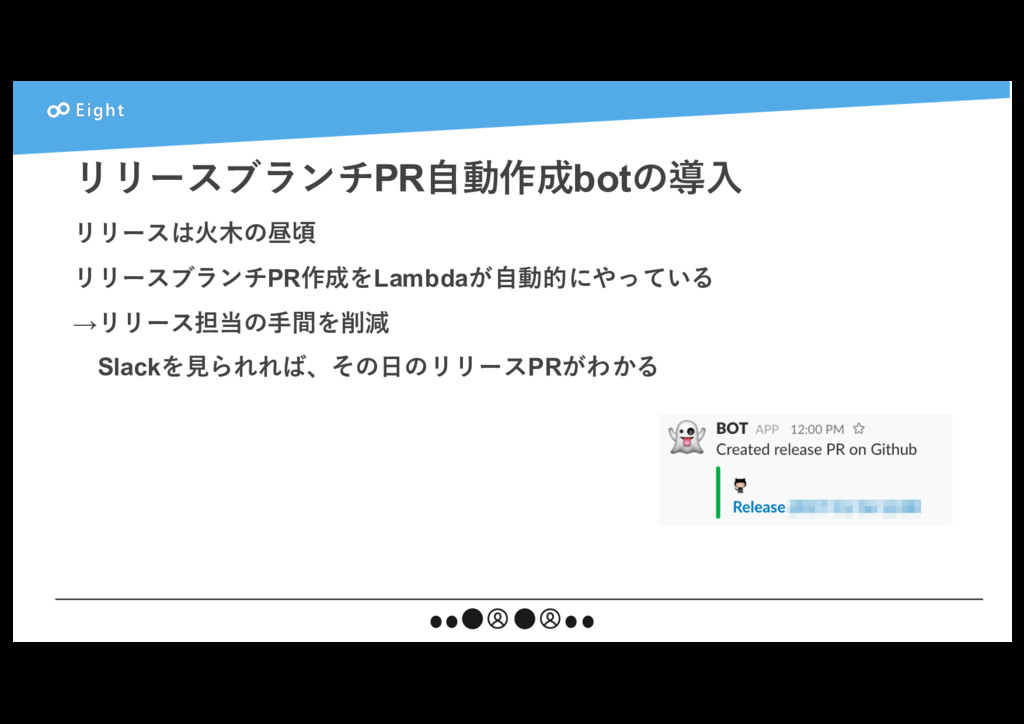{kind=link}
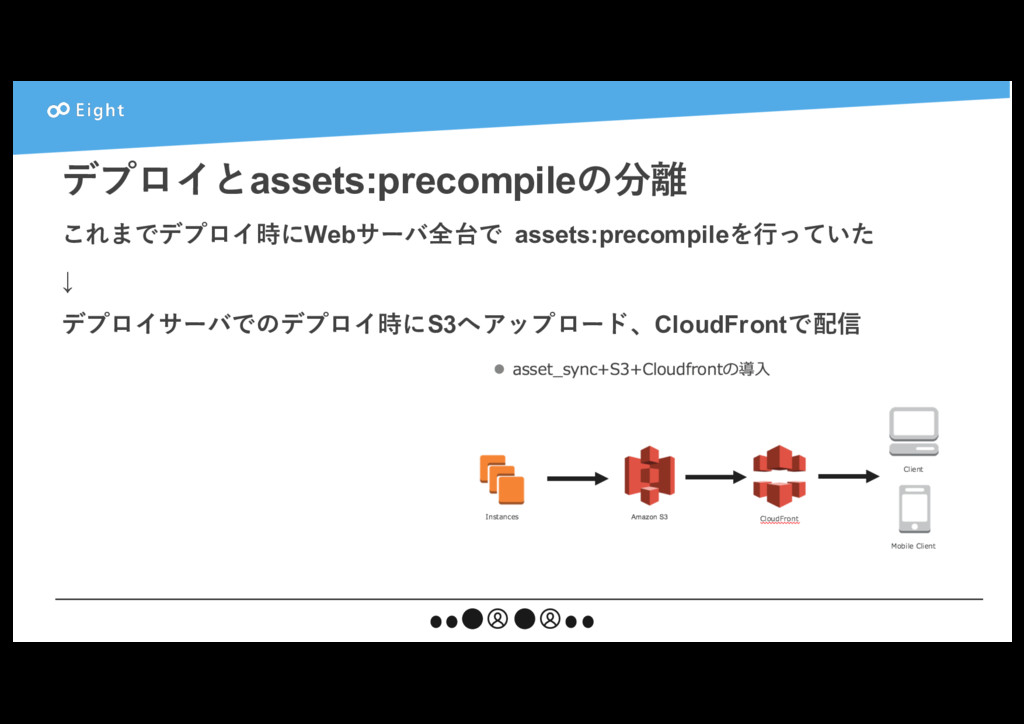{kind=link}
{kind=link}
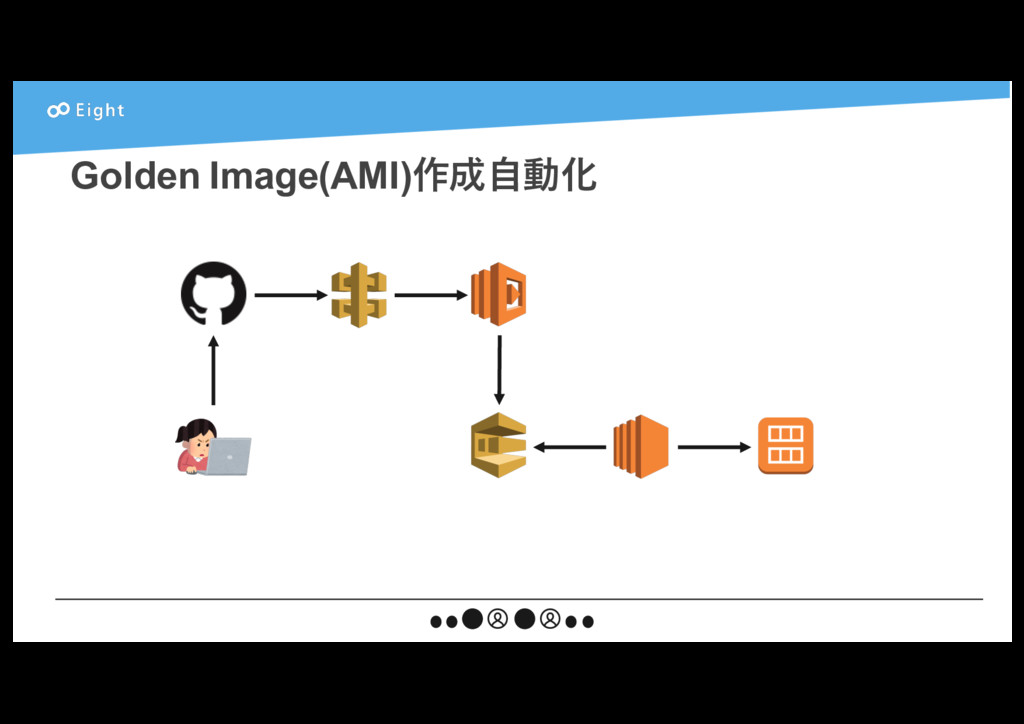{kind=link}
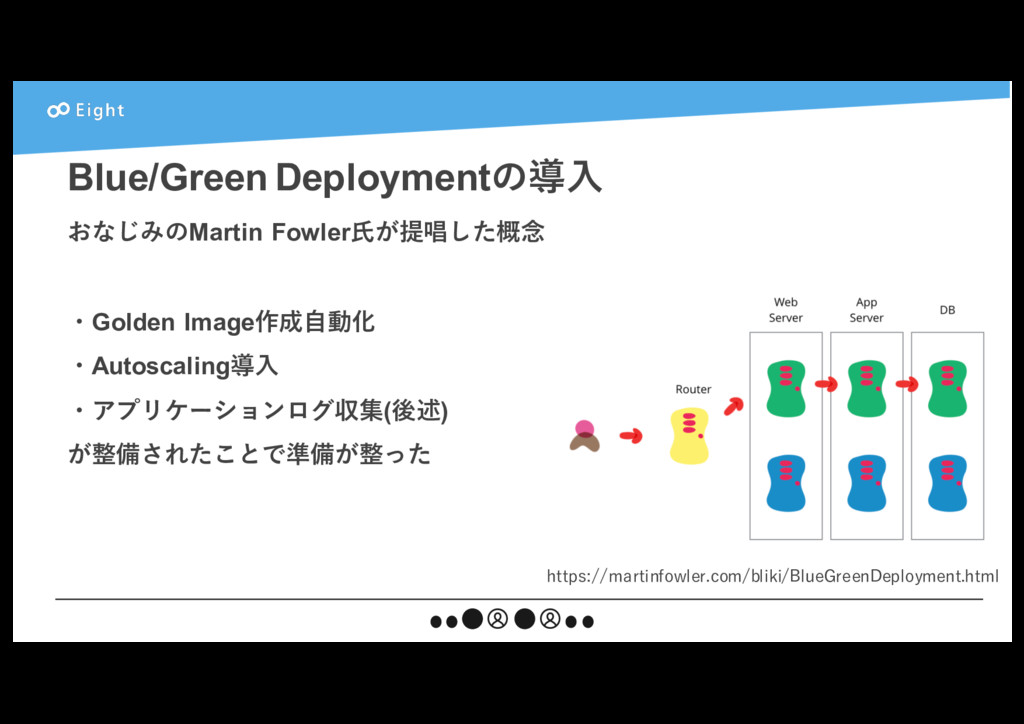{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
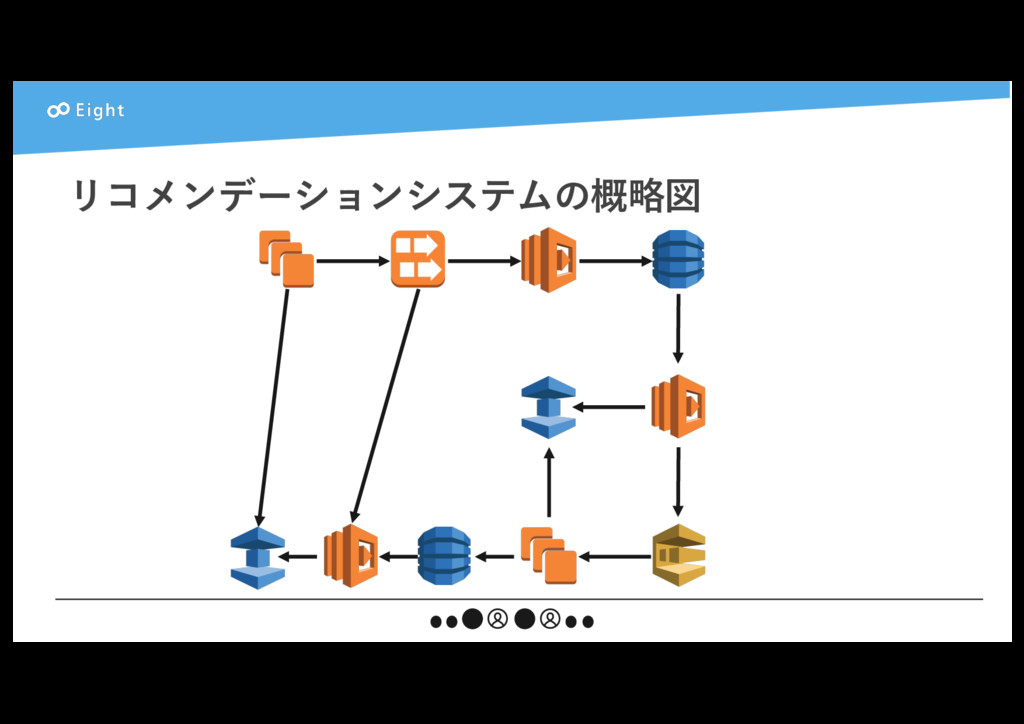{kind=link}
{kind=link}
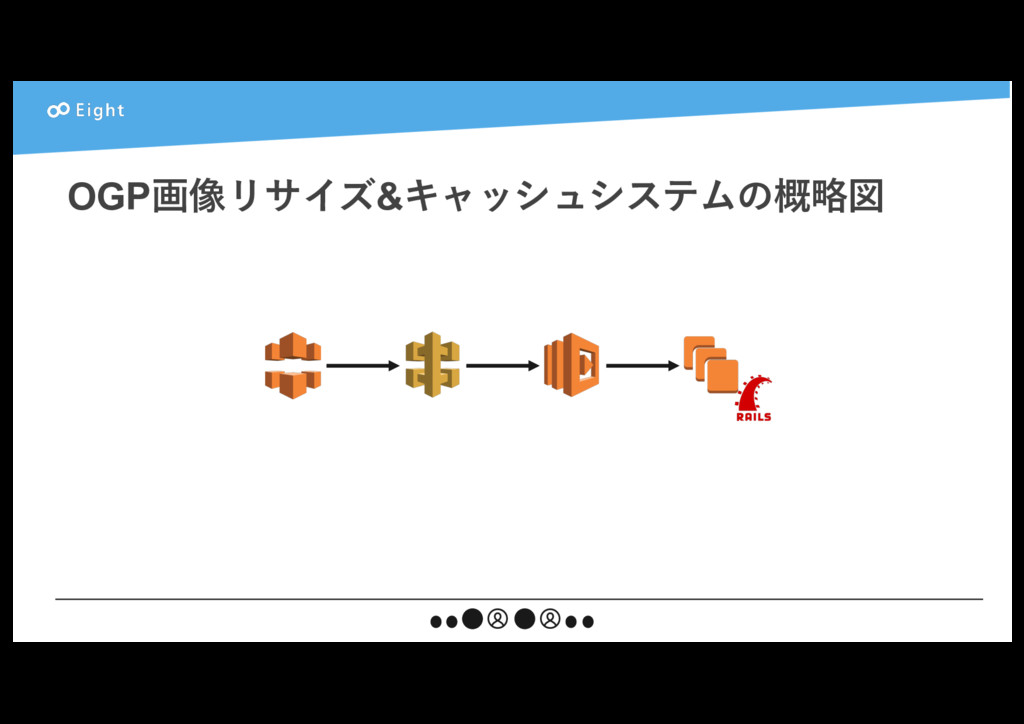{kind=link}
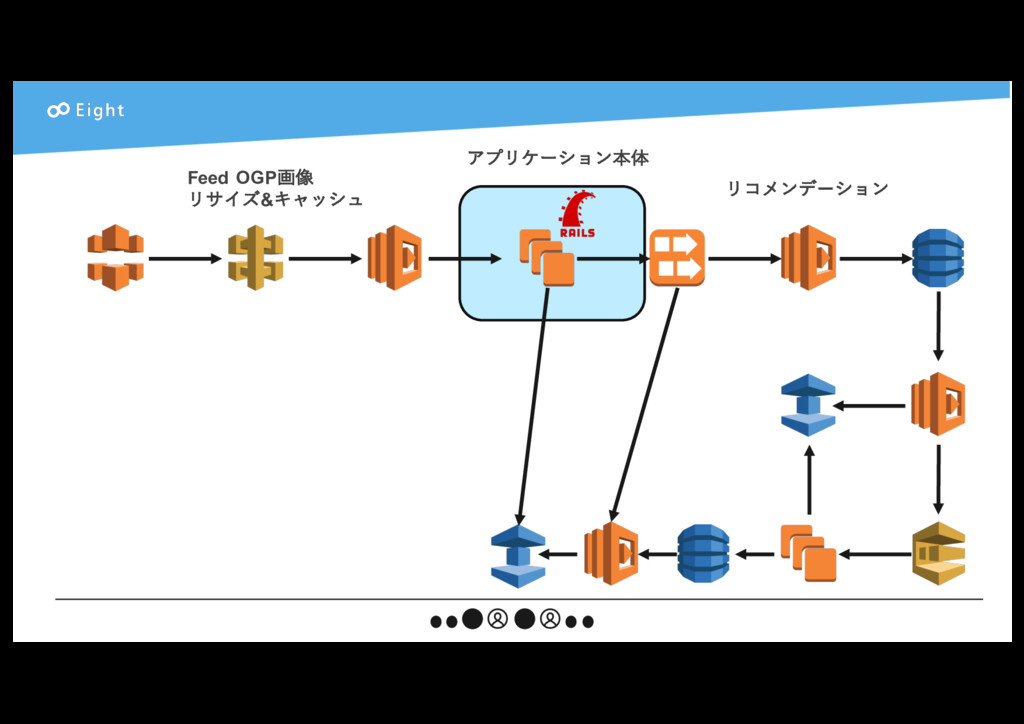{kind=link}
{kind=link}
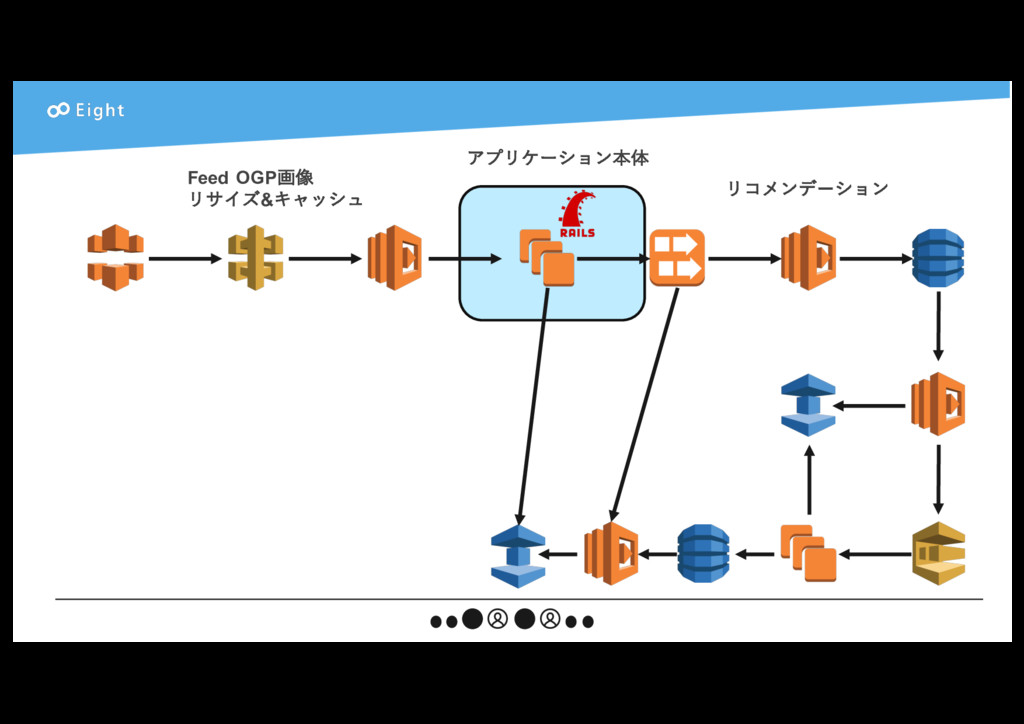{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}