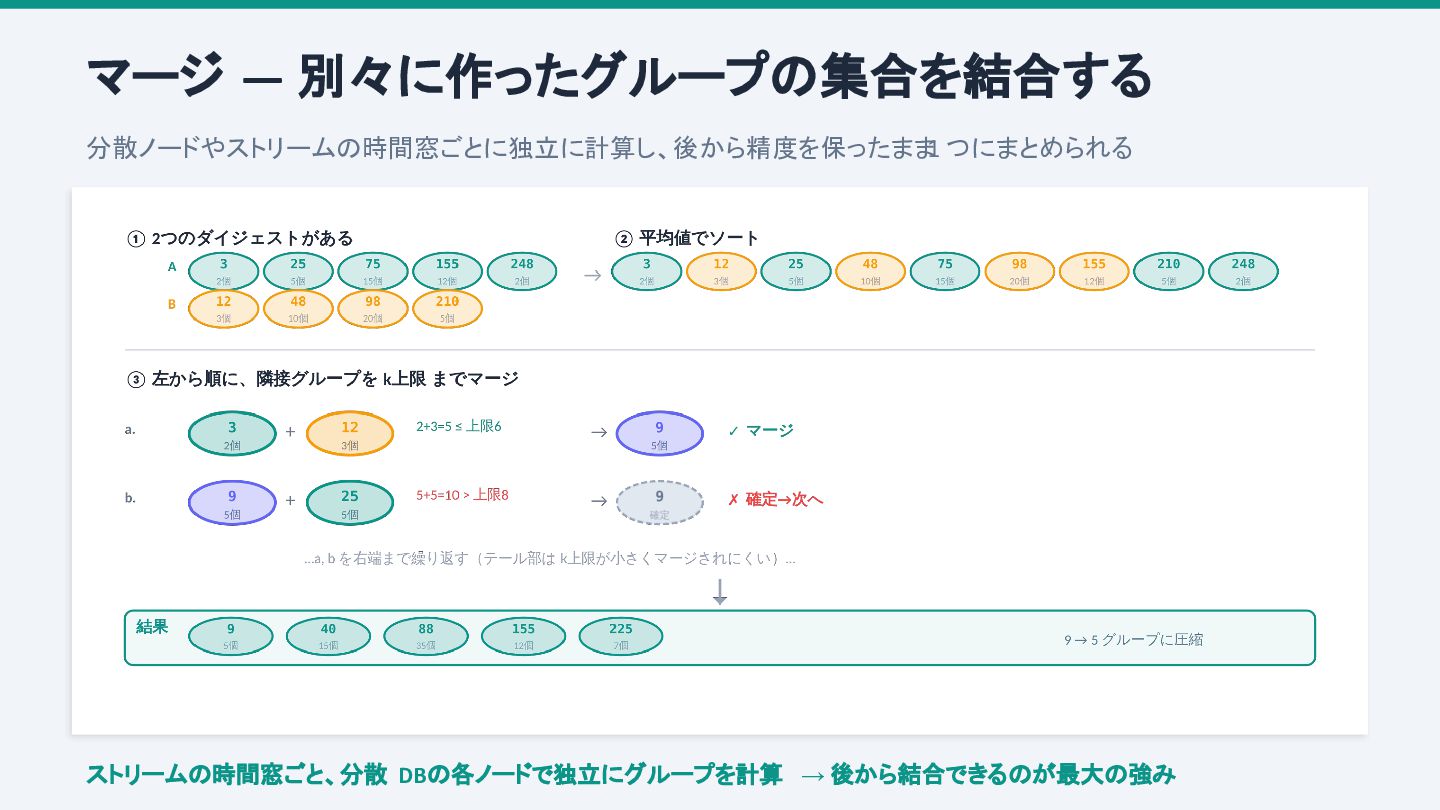
CREATE TABLE daily_digest AS SELECT dt, CAST(tdigest_agg(val) AS VARBINARY) AS digest FROM metrics GROUP BY dt; 後から任意期間の分位数を高速に取得 SELECT value_at_quantile(merge(CAST(digest AS tdigest)), 0.99) AS p99 FROM daily_digest WHERE dt BETWEEN '2025-01-01' AND '2025-03-31'; merge() は保存済みのグループの集合を結合する関数。前述のマージ処理を SQL から呼び出せる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}