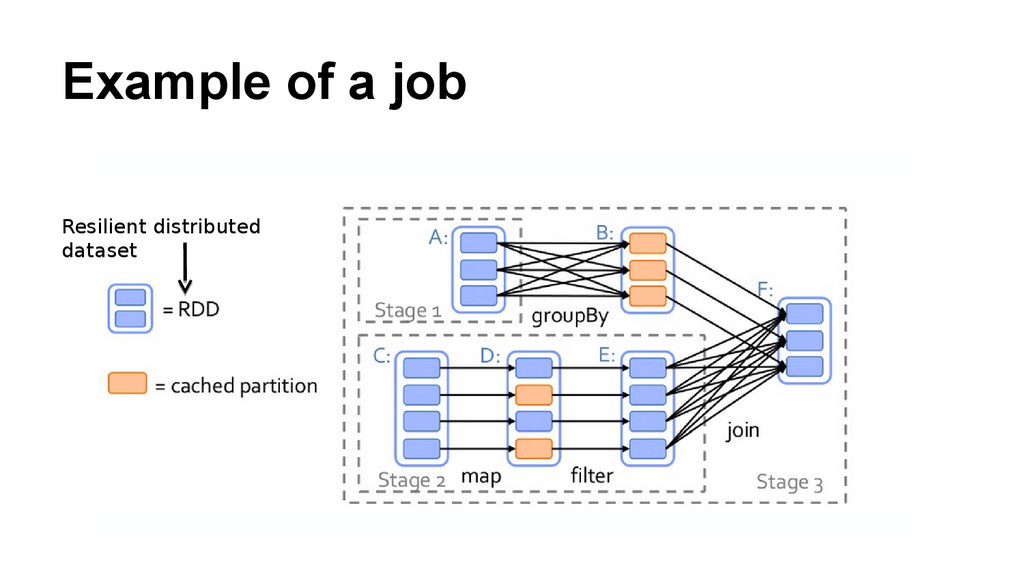
lambda x: x.replace(',', ' ') .replace('.',' ') .replace('-',' ') .lower()) \ .flatMap(lambda x: x.split()) \ .map(lambda x: (x, 1)) \ .reduceByKey(lambda x,y:x+y) input: [‘So wise so young, they say, do never live long.’] map: [‘so wise so young they say do never live long’] flatMap: [‘so’, ‘wise’, ‘so’, ‘young’, ‘they’, ‘say’, ‘do’, ‘never’, ‘live’, ‘long’] map: [(‘so’, 1), (‘wise’, 1), (‘so’, 1), (‘young’, 1), (‘they’, 1), …, (‘long’, 1)] output: [(‘so’, 2), (‘wise’, 1), (‘young’, 1), (‘they’, 1), …, (‘long’, 1)]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Code: result = sc.textFile(‘s3n://very_large_dataset’)\ .filter(lambda x: x[‘page_visited’] == ‘url1’)\ .map(lambda](https://files.speakerdeck.com/presentations/c87b8e10053b01323bb06e666dae31c4/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![result = sc.textFile(‘s3://very_large_file’)\ .filter(lambda x: x[‘page_visited’] == ‘url1’)\ .map(lambda x:](https://files.speakerdeck.com/presentations/c87b8e10053b01323bb06e666dae31c4/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}