DevOps x SRE, mais um nome da moda? A evolução do gerenciamento de infra 2.0 e as práticas que caracterizam a cultura e a engenharia de confiabilidade (Site Reliability Engineering). Em um mundo de cloud e micro serviços, práticas como as que serão apresentadas são primordiais para alinhar a necessidade do negócio ao comportamento das aplicações.
{kind=link}
![2 Victor Silveira Bogo SRE @ @B0go @victorbogo [email protected]](https://files.speakerdeck.com/presentations/07ca9143840f4429a2cd13cfebdfe65d/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
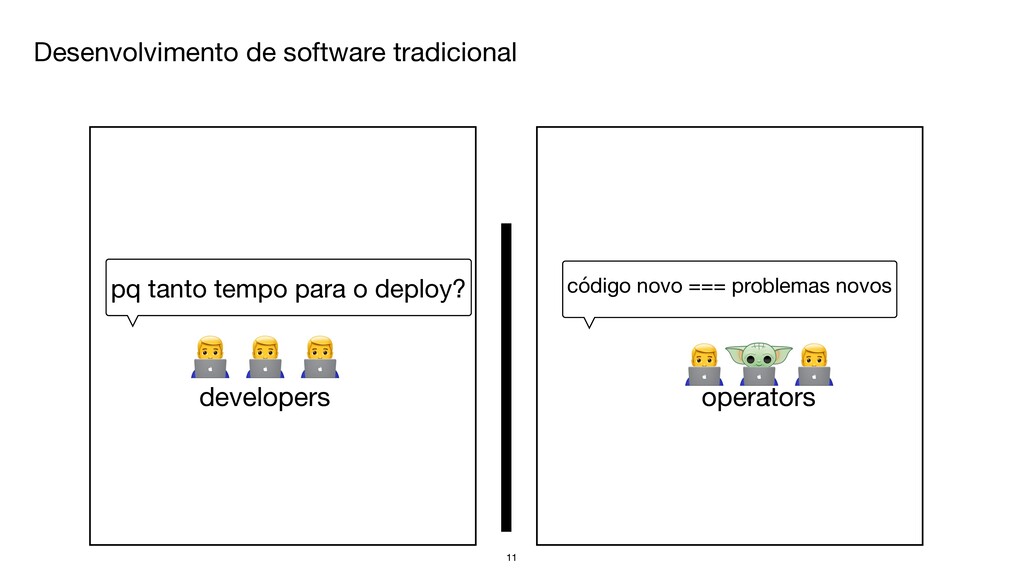{kind=link}
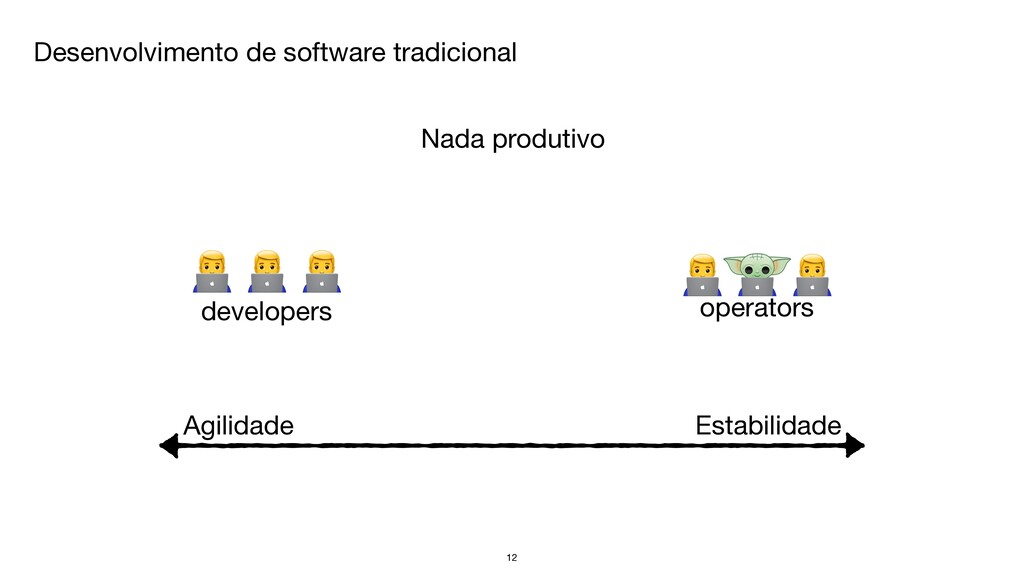{kind=link}
{kind=link}
{kind=link}
{kind=link}
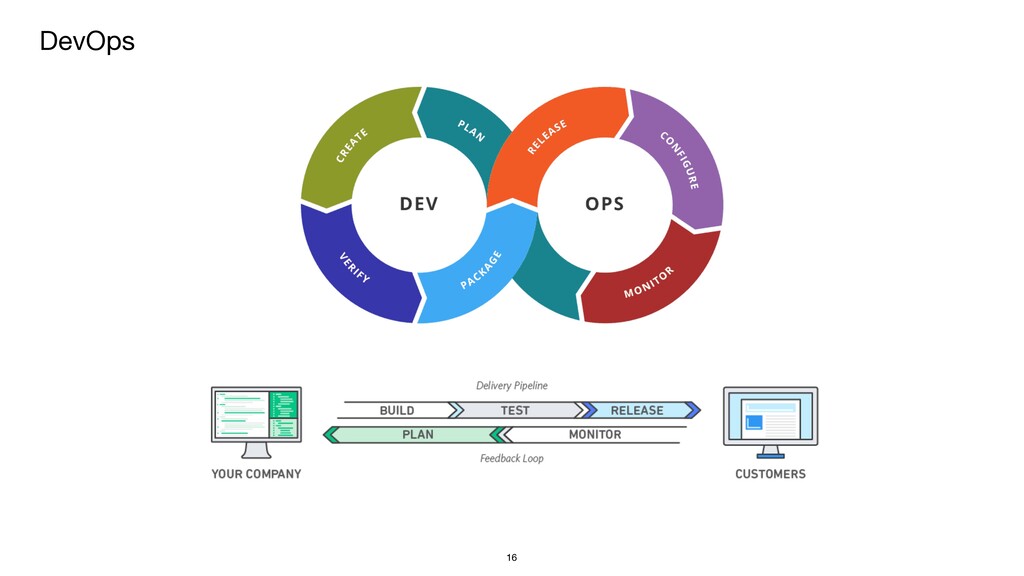{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
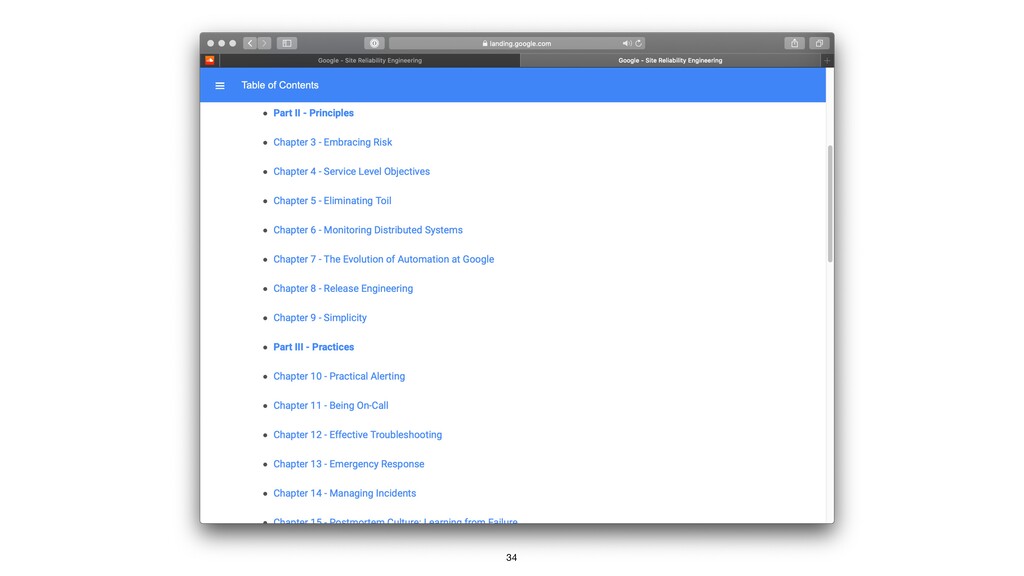{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
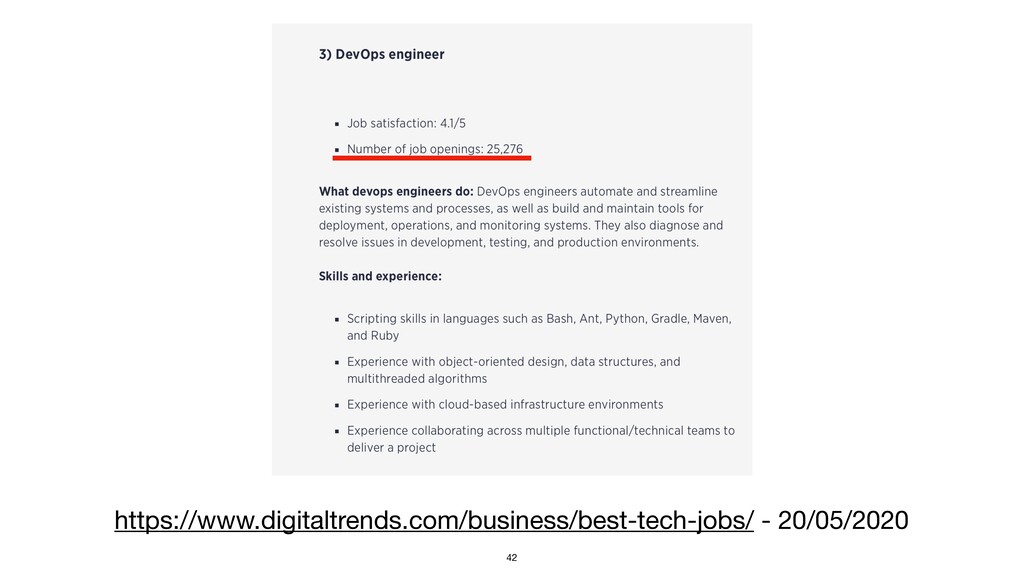{kind=link}
{kind=link}