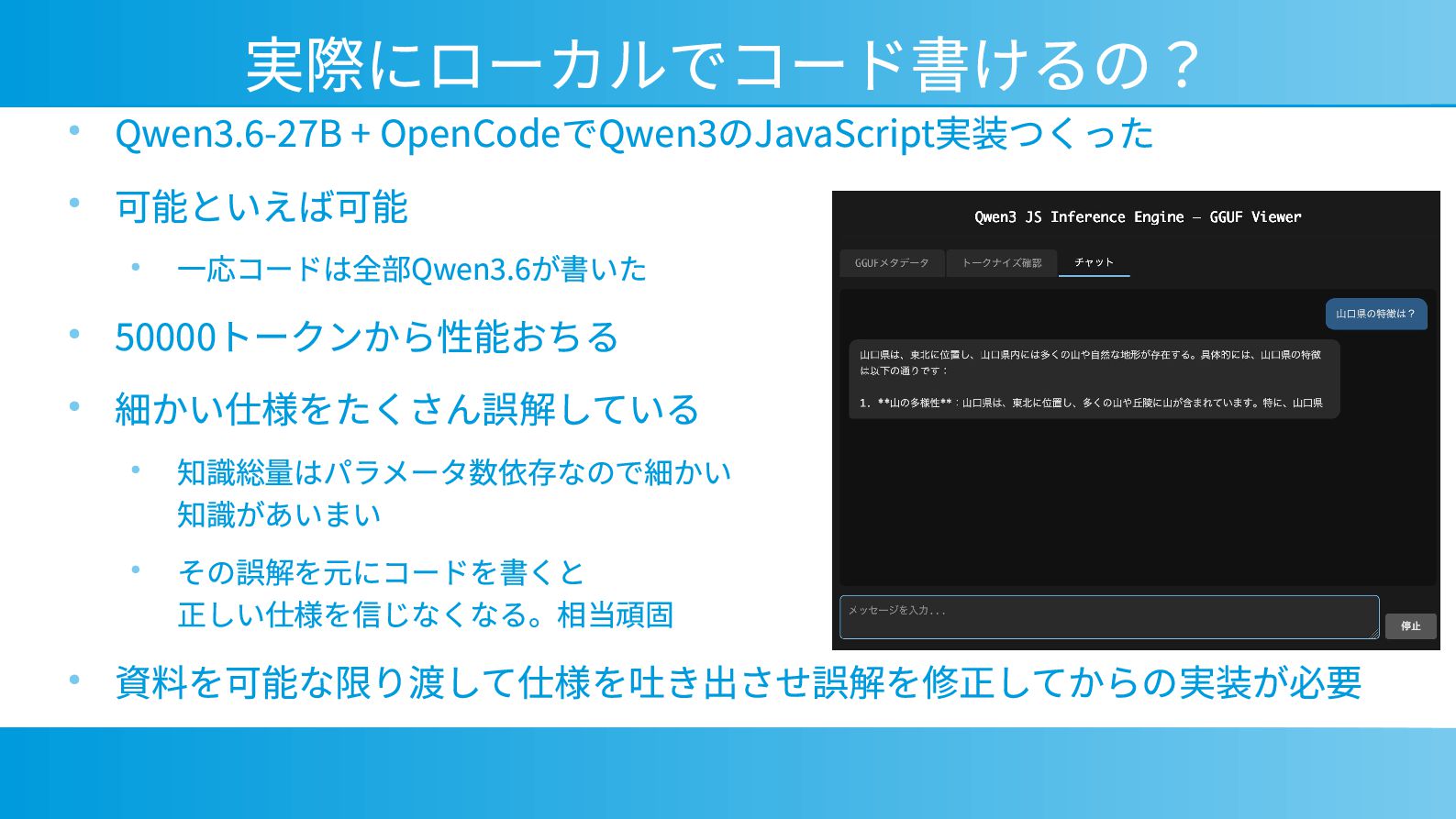
• A MD R yz en AI Max+ 39 5– EVO -X2:1 28 GB/48 万円 • I ntel C ore U ltra 7 – EVO -T 2 64GB / 32万円 • NVI DIA GB1 0 – A scent GX1 0: 1 28 GB / 58 万円 • NVI DIA RT X S park ?? (きっとGB1 0と同じ ) • A pple S ilicon – Mac S tud io: 9 6GB / 60万円 • GPU (32GB) • RT X 5060 T i 1 6GB x2 / 20万円 • I ntel A rc P ro B70 / 22万円 • R ad eon AI P ro R9 700 / 25万円 • RT X 509 0 / 60万円~ • RT X PRO 4500 / 60万円 GPUで動かそうとすると高いのでCPU+GPU一体型で
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
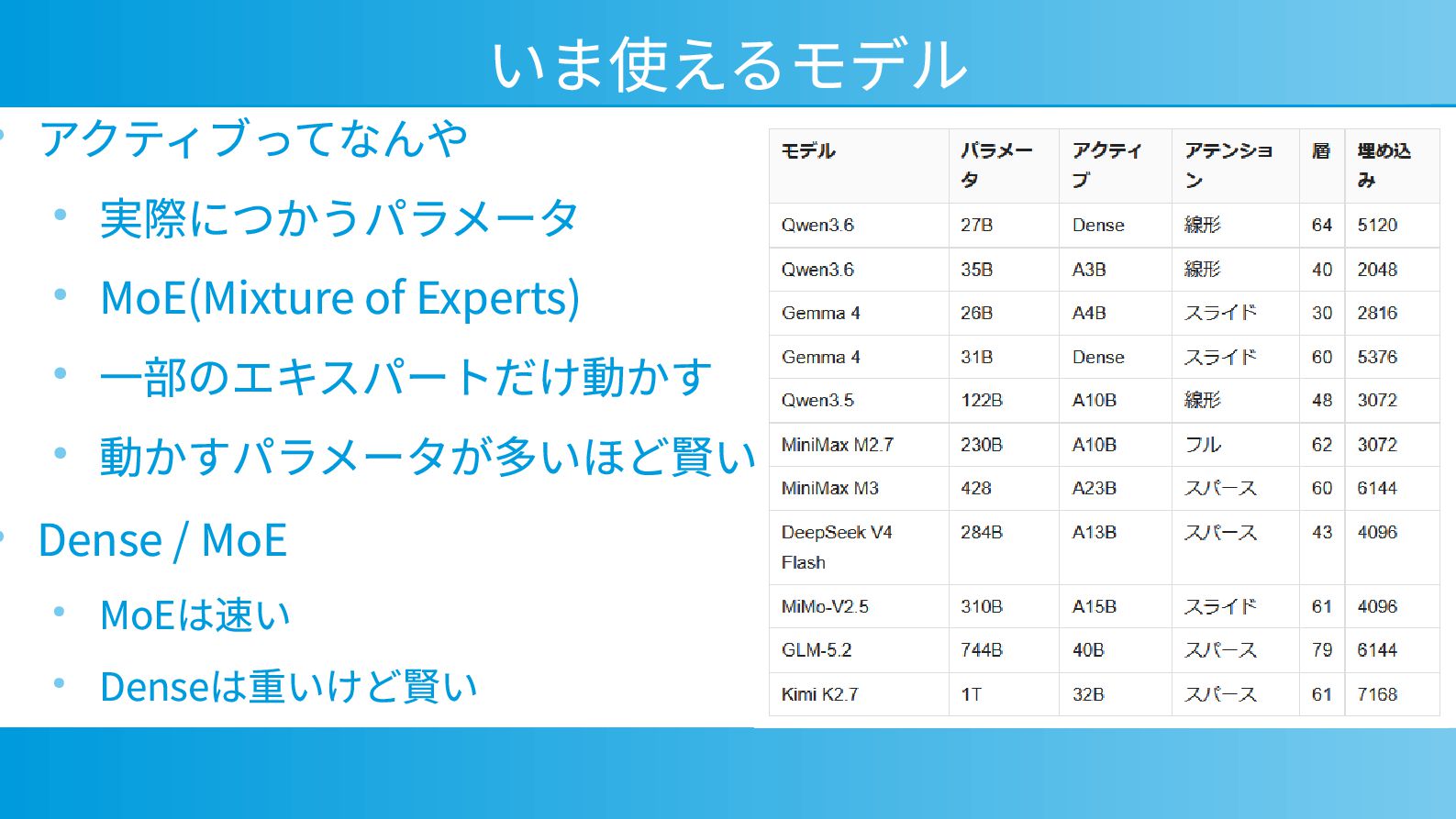{kind=link}
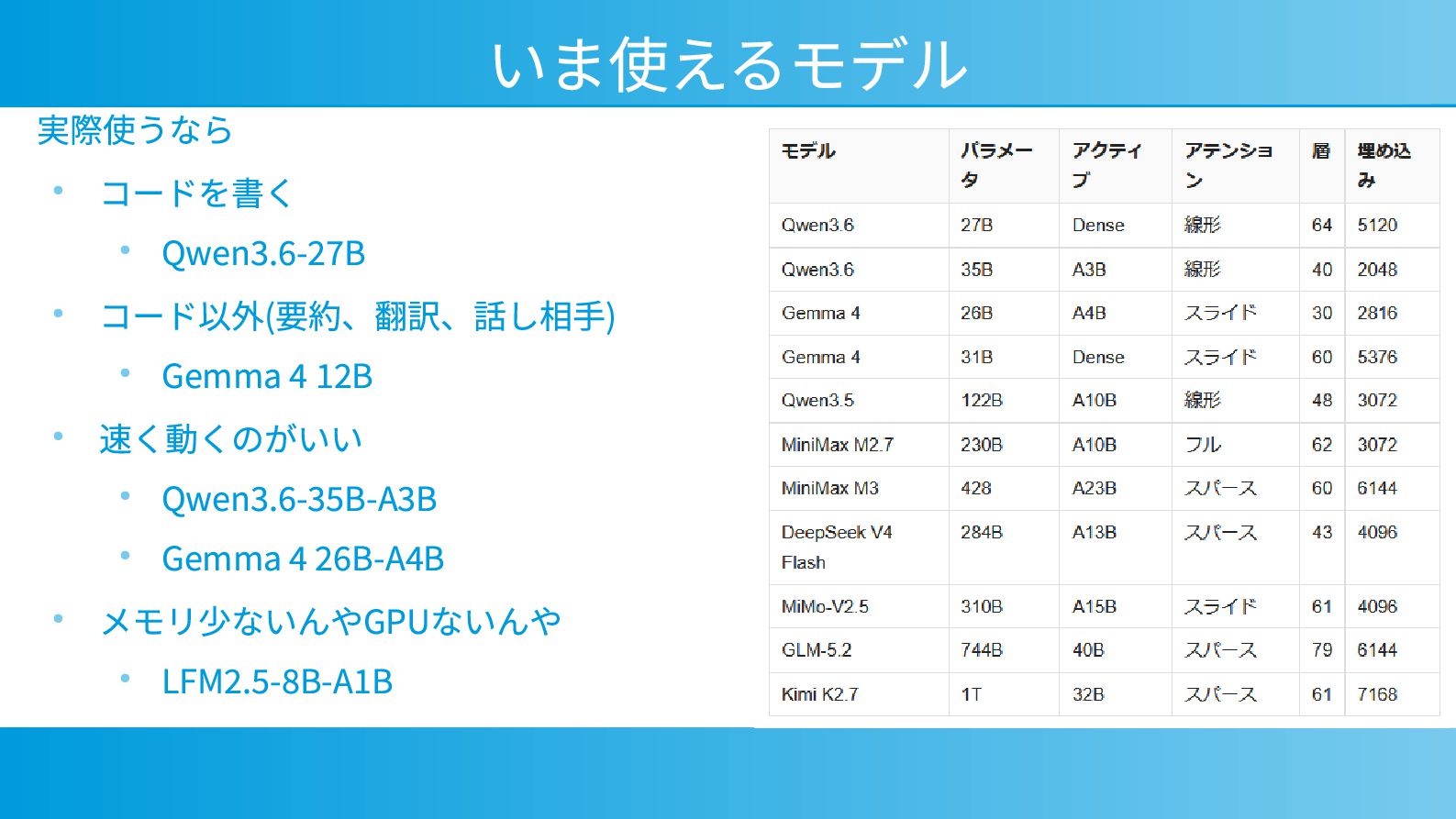{kind=link}
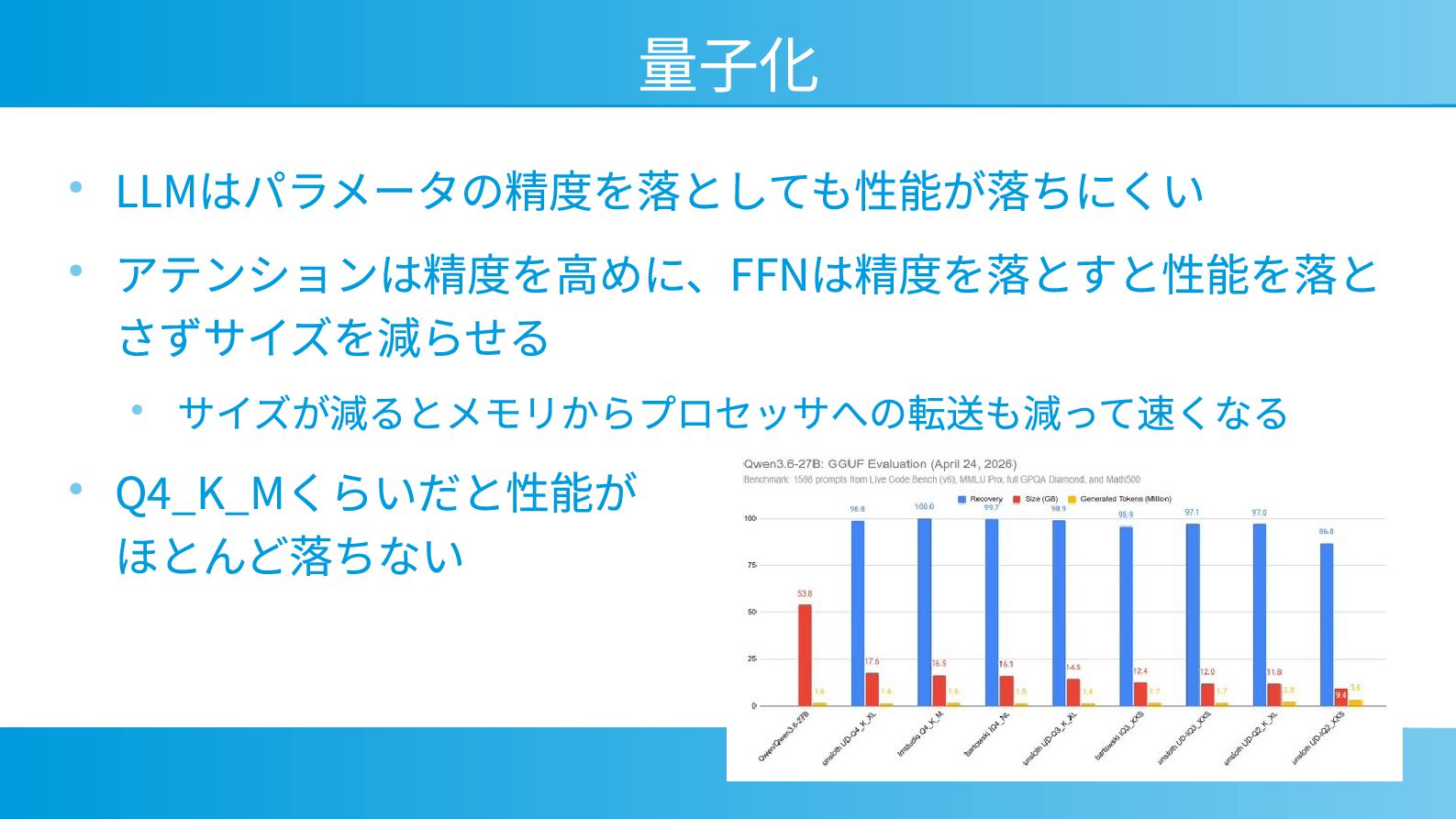{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}